点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自AI新媒体量子位(公众号 ID: QbitAI)
搞AI,谁又没有“GPU之惑”?
张量核心、显存带宽、16位能力……各种纷繁复杂的GPU参数让人眼花缭乱,到底怎么选?
从不到1000元1050 Ti到近30000元的Titan V,GPU价格的跨度这么大,该从何价位下手?谁才是性价比之王?
让GPU执行不同的任务,最佳选择也随之变化,用于计算机视觉和做NLP就不太一样。
而且,用云端TPU、GPU行不行?和本地GPU在处理任务时应该如何分配,才能更省钱?
最合适的AI加速装备,究竟什么样?
现在,为了帮你找到最适合的装备,华盛顿大学的博士生Tim Dettmers将对比凝练成实用攻略,最新的模型和硬件也考虑在内。
到底谁能在众多GPU中脱颖而出?测评后马上揭晓。
文末还附有一份特别精简的GPU选购建议,欢迎对号入座。

最重要的参数
针对不同深度学习架构,GPU参数的选择优先级是不一样的,总体来说分两条路线:
卷积网络和Transformer:张量核心>FLOPs(每秒浮点运算次数)>显存带宽>16位浮点计算能力
循环神经网络:显存带宽>16位浮点计算能力>张量核心>FLOPs
这个排序背后有一套逻辑,下面将详细解释一下。
在说清楚哪个GPU参数对速度尤为重要之前,先看看两个最重要的张量运算:矩阵乘法和卷积。
举个栗子🌰,以运算矩阵乘法A×B=C为例,将A、B复制到显存上比直接计算A×B更耗费资源。也就是说,如果你想用LSTM等处理大量小型矩阵乘法的循环神经网络,显存带宽是GPU最重要的属性。
矩阵乘法越小,内存带宽就越重要。
相反,卷积运算受计算速度的约束比较大。因此,要衡量GPU运行ResNets等卷积架构的性能,最佳指标就是FLOPs。张量核心可以明显增加FLOPs。
Transformer中用到的大型矩阵乘法介于卷积运算和RNN的小型矩阵乘法之间,16位存储、张量核心和TFLOPs都对大型矩阵乘法有好处,但它仍需要较大的显存带宽。
需要特别注意,如果想借助张量核心的优势,一定要用16位的数据和权重,避免使用RTX显卡进行32位运算!
下面Tim总结了一张GPU和TPU的标准性能数据,值越高代表性能越好。RTX系列假定用了16位计算,Word RNN数值是指长度<100的段序列的biLSTM性能。
这项基准测试是用PyTorch 1.0.1和CUDA 10完成的。
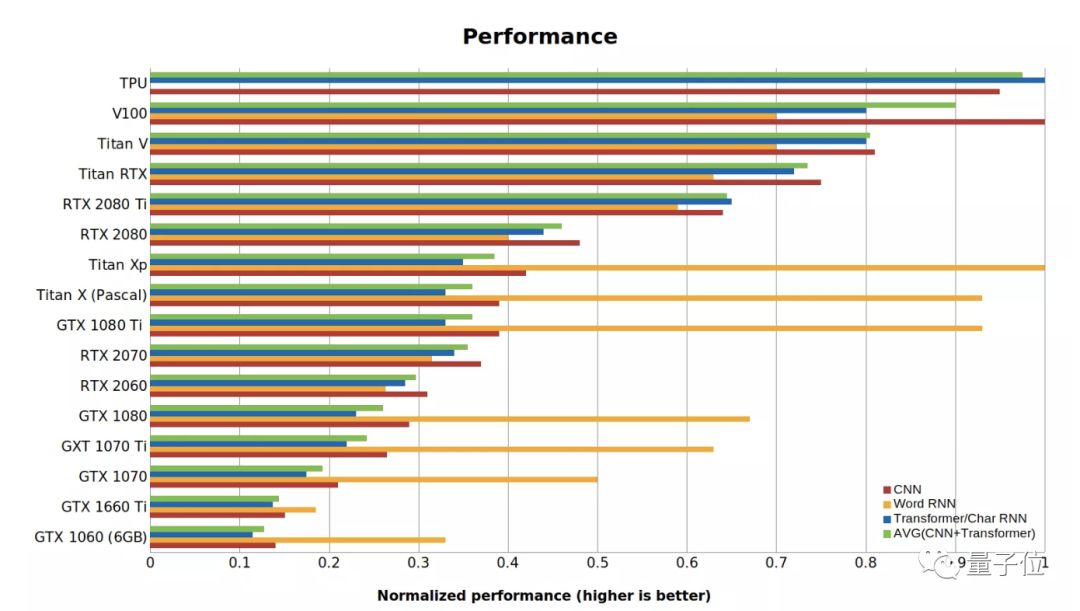
△ GPU和TPU的性能数据
性价比分析
性价比可能是选择一张GPU最重要的考虑指标。在攻略中,小哥进行了如下运算测试各显卡的性能:
用语言模型Transformer-XL和BERT进行Transformer性能的基准测试。
用最先进的biLSTM进行了单词和字符级RNN的基准测试。
上述两种测试是针对Titan Xp、Titan RTX和RTX 2080 Ti进行的,对于其他GPU则线性缩放了性能差异。
借用了现有的CNN基准测试。
用了亚马逊和eBay上显卡的平均售价作为GPU的参考成本。
最后,可以得出CNN、RNN和Transformer的归一化性能/成本比值,如下所示:
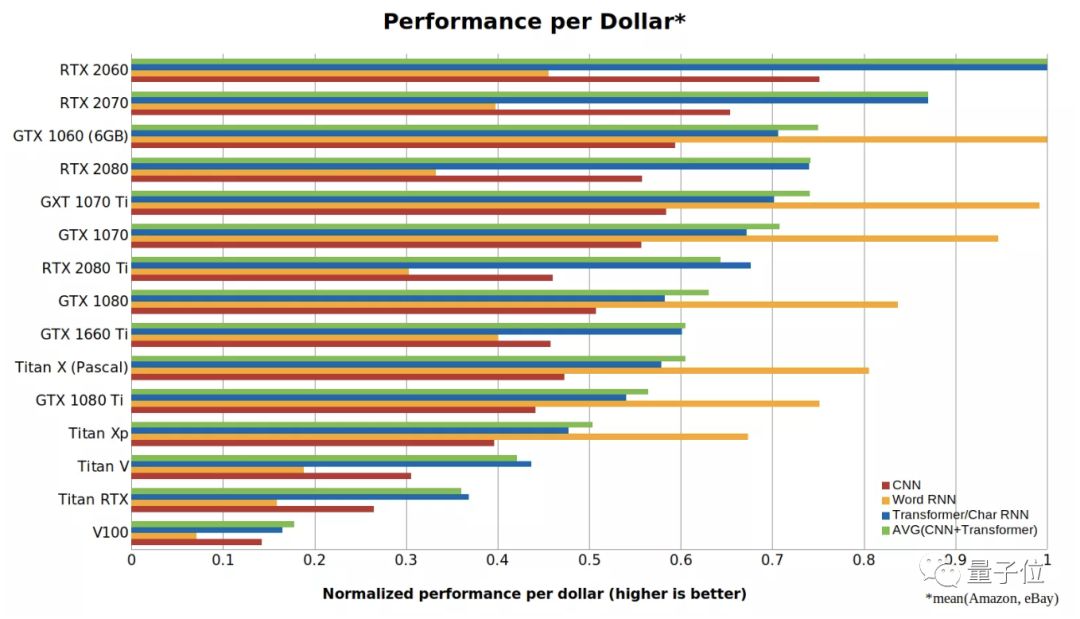
△ CNN、RNN和Transformer的每美元性能
在上面这张图中,数字越大代表每一美元能买到的性能越强。可以看出, RTX 2060比RTX 2070,RTX 2080或RTX 2080 Ti更具成本效益,甚至是Tesla V100性价比的5倍以上。
所以此轮的性价比之王已经确定,是RTX 2060无疑了。
不过,这种考量方式更偏向于小型GPU,且因为游戏玩家不喜欢RTX系列显卡,导致GTX 10xx系列的显卡售价虚高。此外,还存在一定的单GPU偏差,一台有4个RTX 2080 Ti的计算机比两台带8个RTX 2060的计算机性价比更高。
所需显存与16位训练
GPU的显存对某些应用至关重要,比如常见的计算机视觉、机器翻译和一部分NLP应用。可能你认为RTX 2070具有成本效益,但需要注意其显存很小,只有8 GB。
不过,也有一些补救办法。
通过16位训练,你可以拥有几乎16位的显存,相当于将显存翻了一倍,这个方法对RTX 2080和RTX 2080 Ti同样适用。
也就是说,16位计算可以节省50%的内存,16位 8GB显存大小与12GB 32位显存大小相当。
云端or本地?TPU or GPU?
搞清楚了参数,还有更眼花缭乱的选项摆在面前:
谷歌云、亚马逊AWS、微软的云计算平台都能搞机器学习,是不是可以不用自己买GPU?
英伟达、AMD、英特尔、各种创业公司……AI加速芯片也有不少品牌可选。
面对整个行业的围攻,Tim分析了各家平台的优缺点。
英伟达
英伟达无疑是深度学习硬件领域的领导者,大多数深度学习库都对英伟达GPU提供最佳支持。而AMD的OpenCL没有这样强大的标准库。

软件是英伟达GPU非常强大的一部分。在过去的几个月里,NVIDIA还在为软件注入更多资源。例如,Apex库对PyTorch中的16位梯度提供支持,还包括像FusedAdam这样的融合快速优化器。
但是英伟达现在有一项非常坑爹的政策,如果在数据中心使用CUDA,那么只允许使用Tesla GPU而不能用GTX或RTX GPU。
由于担心法律问题,研究机构和大学经常被迫购买低性价比的Tesla GPU。然而,Tesla与GTX和RTX相比并没有真正的优势,价格却高出10倍。
AMD:
AMD GPU性能强大但是软件太弱。虽然有ROCm可以让CUDA转换成可移植的C++代码,但是问题在于,移植TensorFlow和PyTorch代码库很难,这大大限制了AMD GPU的应用。

TensorFlow和PyTorch对AMD GPU有一定的支持,所有主要的网络都可以在AMD GPU上运行,但如果想开发新的网络,可能有些细节会不支持。
对于那些只希望GPU能够顺利运行的普通用户,Tim并不推荐AMD。但是支持AMD GPU和ROCm开发人员,会有助于打击英伟达的垄断地位,将使每个人长期受益。
英特尔:
Tim曾经尝试过至强融核(Xeon Phi)处理器,但体验让人失望。英特尔目前还不是英伟达或AMD GPU真正的竞争对手。

至强融核对深度学习的支持比较差,不支持一些GPU的设计特性,编写优化代码困难,不完全支持C++ 11的特性,与NumPy和SciPy的兼容性差。
英特尔曾计划在今年下半年推出神经网络处理器(NNP),希望与GPU和TPU竞争,但是该项目已经跳票。
谷歌:
谷歌TPU已经发展成为一种非常成熟的云端产品。你可以这样简单理解TPU:把它看做打包在一起的多个专用GPU,它只有一个目的——进行快速矩阵乘法。

如果看一下具有张量核心的V100 GPU与TPUv2的性能指标,可以发现两个系统的性能几乎相同。
TPU本身支持TensorFlow,对PyTorch的支持也在试验中。
TPU在训练大型Transformer GPT-2上取得了巨大的成功,BERT和机器翻译模型也可以在TPU上高效地进行训练,速度相比GPU大约快56%。
但是TPU也并非没有问题,有些文献指出在TPUv2上使用LSTM没有收敛。
TPU长时间使用时还面临着累积成本的问题。TPU具有高性能,最适合在训练阶段使用。在原型设计和推理阶段,应该依靠GPU来降低成本。
总而言之,目前TPU最适合用于训练CNN或大型Transformer,并且应该补充其他计算资源而不是主要的深度学习资源。
亚马逊和微软云GPU:
亚马逊AWS和Microsoft Azure的云GPU非常有吸引力,人们可以根据需要轻松地扩大和缩小使用规模,对于论文截稿或大型项目结束前赶出结果非常有用。

然而,与TPU类似,云GPU的成本会随着时间快速增长。目前,云GPU过于昂贵,且无法单独使用,Tim建议在云GPU上进行最后的训练之前,先使用一些廉价GPU进行原型开发。
初创公司的AI硬件:
有一系列初创公司在生产下一代深度学习硬件。但问题在于,这些硬件需要开发一个完整的软件套件才能具有竞争力。英伟达和AMD的对比就是鲜明的例子。
小结:
总的来说,本地运算首选英伟达GPU,它在深度学习上的支持度比AMD好很多;云计算首选谷歌TPU,它的性价比超过亚马逊AWS和微软Azure。
训练阶段使用TPU,原型设计和推理阶段使用本地GPU,可以帮你节约成本。如果对项目deadline或者灵活性有要求,请选择成本更高的云GPU。
最终建议
总之,在GPU的选择上有三个原则:
1、使用GTX 1070或更好的GPU;
2、购买带有张量核心的RTX GPU;
3、在GPU上进行原型设计,然后在TPU或云GPU上训练模型。
针对不同研究目的、不同预算,Tim给出了如下的建议:
最佳GPU:RTX 2070
避免的坑:所有Tesla、Quadro、创始人版(Founders Edition)的显卡,还有Titan RTX、Titan V、Titan XP
高性价比:RTX 2070(高端),RTX 2060或GTX 1060 (6GB)(中低端)
穷人之选:GTX 1060 (6GB)
破产之选:GTX 1050 Ti(4GB),或者CPU(原型)+ AWS / TPU(训练),或者Colab
Kaggle竞赛:RTX 2070
计算机视觉或机器翻译研究人员:采用鼓风设计的GTX 2080 Ti,如果训练非常大的网络,请选择RTX Titans
NLP研究人员:RTX 2080 Ti
已经开始研究深度学习:RTX 2070起步,以后按需添置更多RTX 2070
尝试入门深度学习:GTX 1050 Ti(2GB或4GB显存)
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~