1.虚拟机环境准备:
1.0)首先准备好一台已经安装好了的虚拟机(我这里用的是Centos)
2.0)安装 vim 编辑器 使用 yum -y install vim,也可以直接用vi
注意:安装好了vim,一定要执行yum -y update来更新数据源,之后重启reboot虚拟机。
3.0)配置静态 IP 前,先关闭虚拟机,在编辑里找到虚拟网络编辑器并点击。
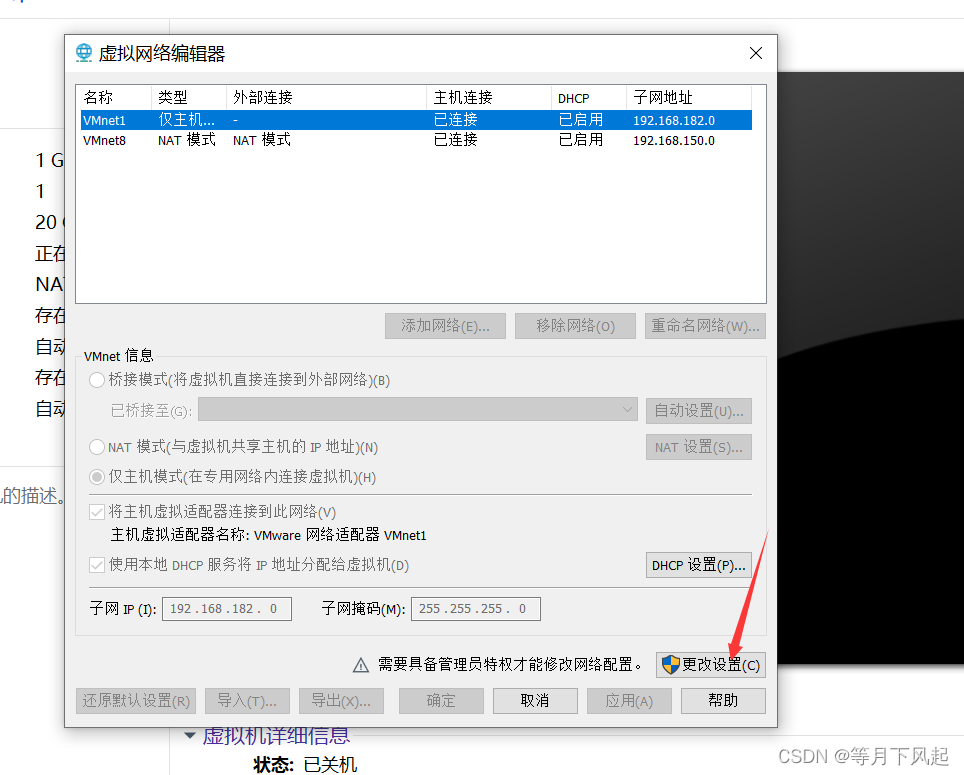

需要记住这两个值,后面可以要用。
4.0)开机进入终端查看ip,①可以通过ip addr查看,②用ifconfig,但前提你要先执行载 yum -y install net-tools,否则会出现这个情况
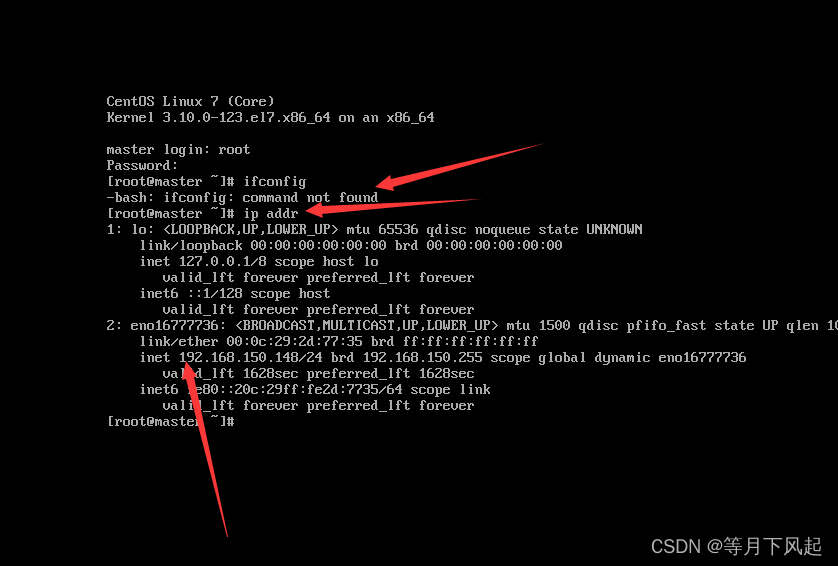
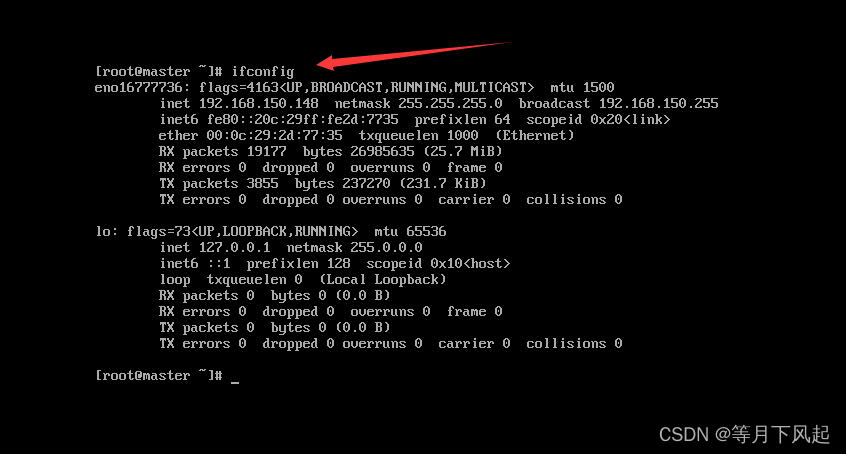
这里看到了ip,但是却是动态的,接下来我们开始配置它。
在终端进入cd /etc/sysconfig/network-scripts/,用ls查看我们要配置的文件名字.(一般是第一个且后面带有很多数字)
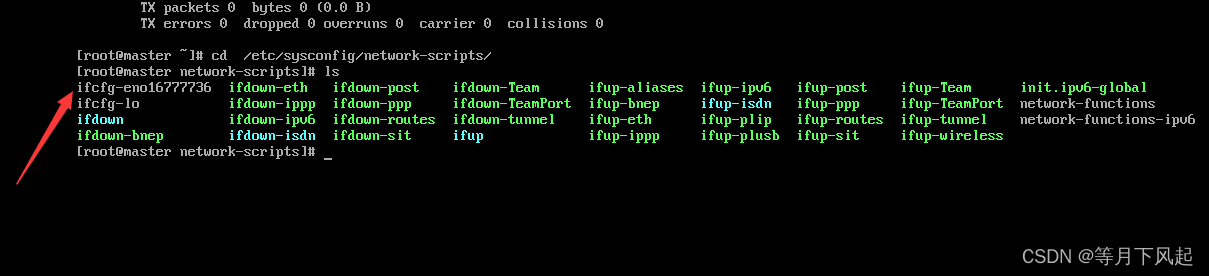
接着输入vim ifcfg-eno16777736, 可以输入ifcfg-e用旁边的Tab键补齐。
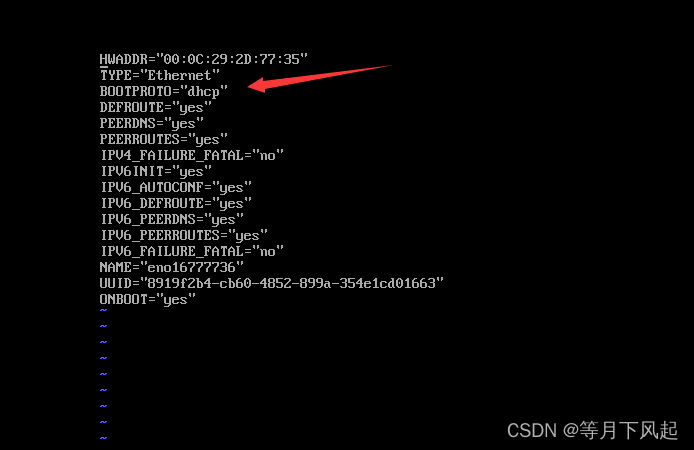
这个dhcp是动态ip,即每次进去都可能会不一样,我们把它改成static静态的。 接着添加下面代码:
BOOTPROTO="static"
#之前记住的ip,后面是128,设置为主机 IP在128至254之间即可
IPADDR=192.168.150.130
#此处与 netmask=255.255.255.0 等效
PREFIX=24
#网关设置
GATEWAY=192.168.150.2
#域名解析器 默认与网关相同
DNS1=192.168.150.2
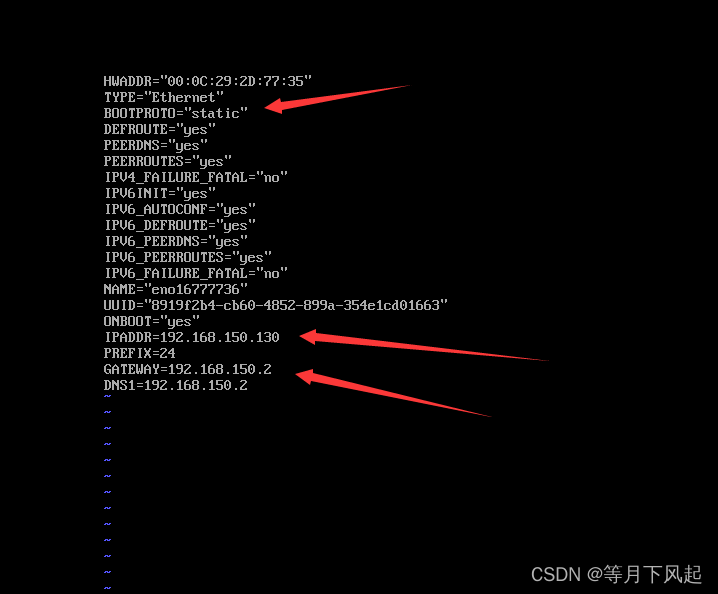
编辑完后,先点击电脑的Esc键后使用Shift和:组合键,再输入wq!保存并退出编辑vim。然后输入source ifcfg-eno16777736后并输入reboot达到重启虚拟机。
5.0)这里为了方便后面上传文件和编辑用Xshell和Xftp进行。这里我把这两个文件和jdk,hadoop都放在这里,有需要的小伙伴可以下载。
链接:https://pan.baidu.com/s/1Zw72OdkNej6cdOVU6GRo2A?pwd=gabw
提取码:gabw
用Xshell连接先在终端关闭防火墙,指令systemctl stop firewalld,然后在进入Xshell创建一个
会话。
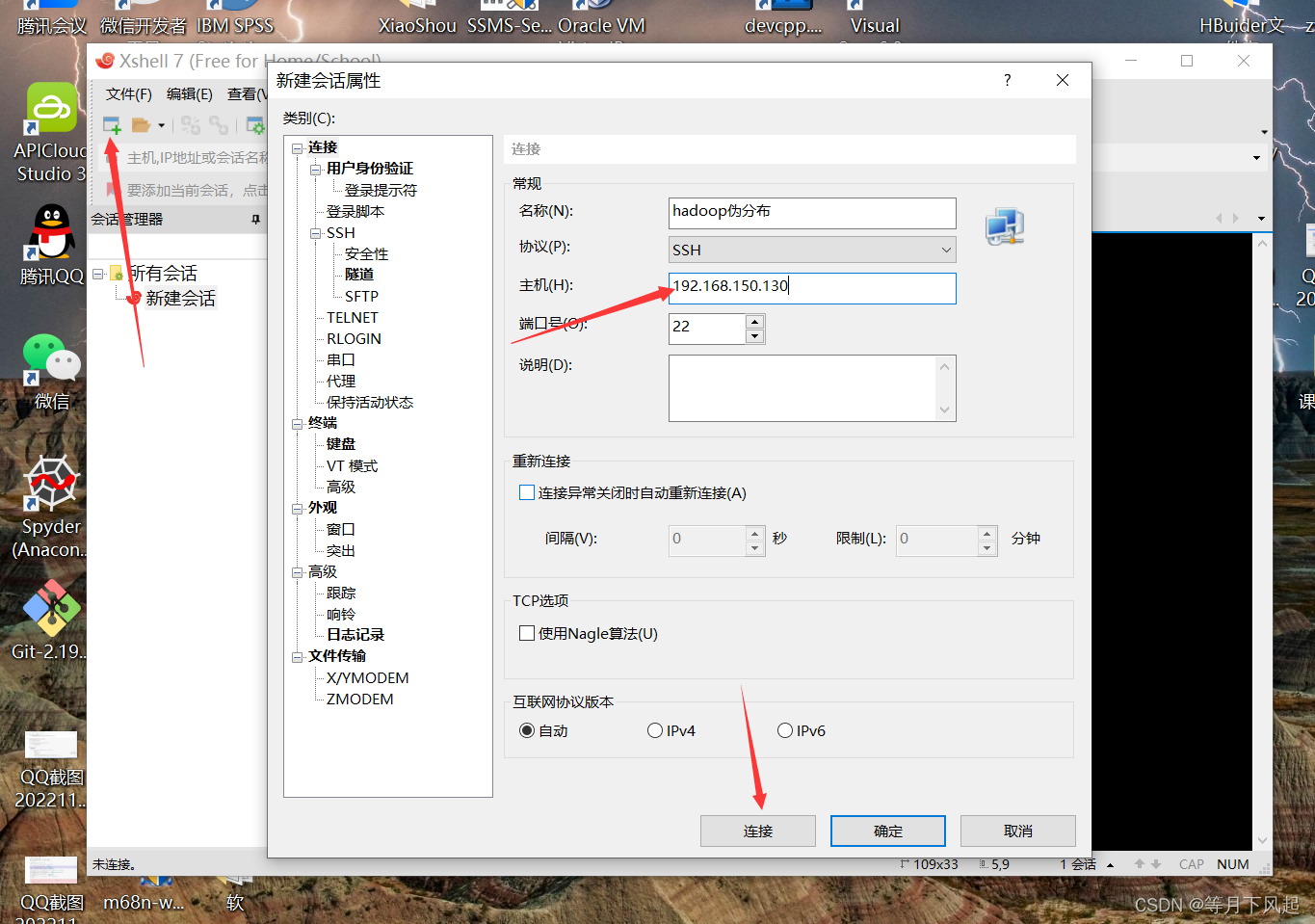
主机就是你刚刚设置的ip,然后直接点击连接。 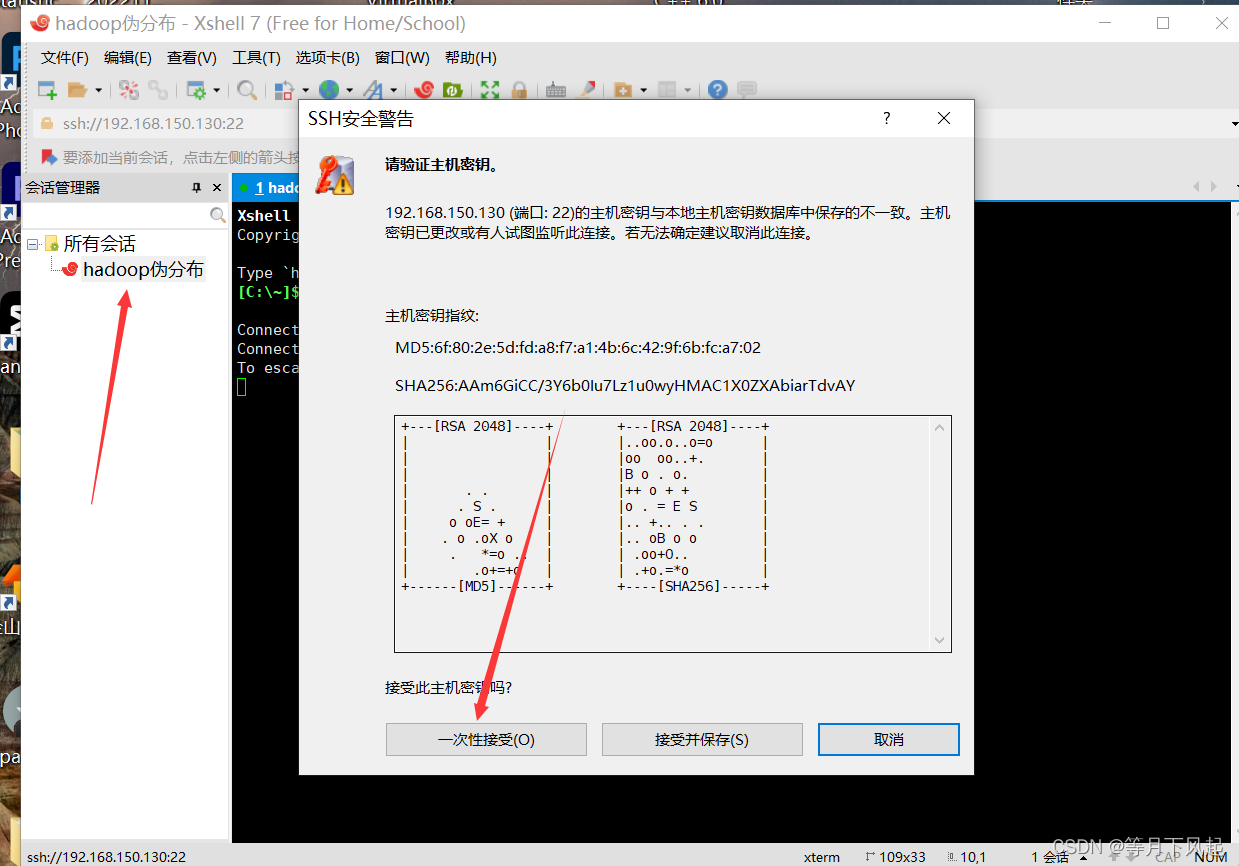
双击新建的会话并选择接受并保存(这里箭头错了)
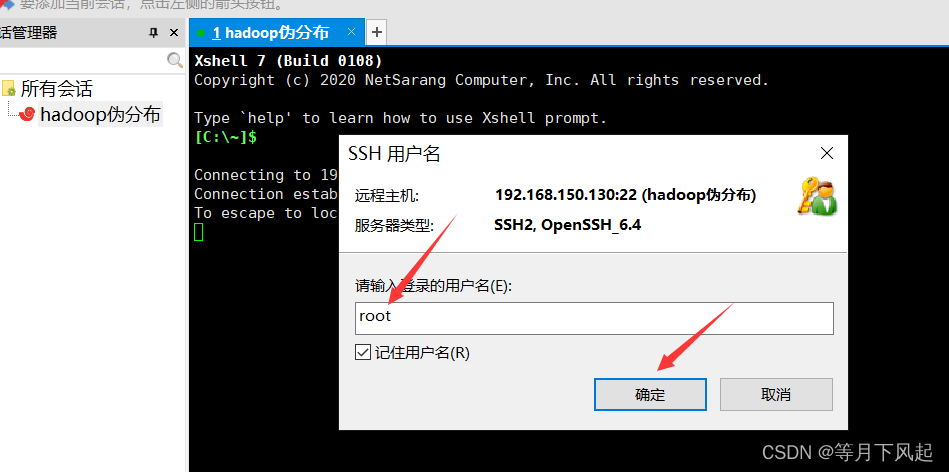
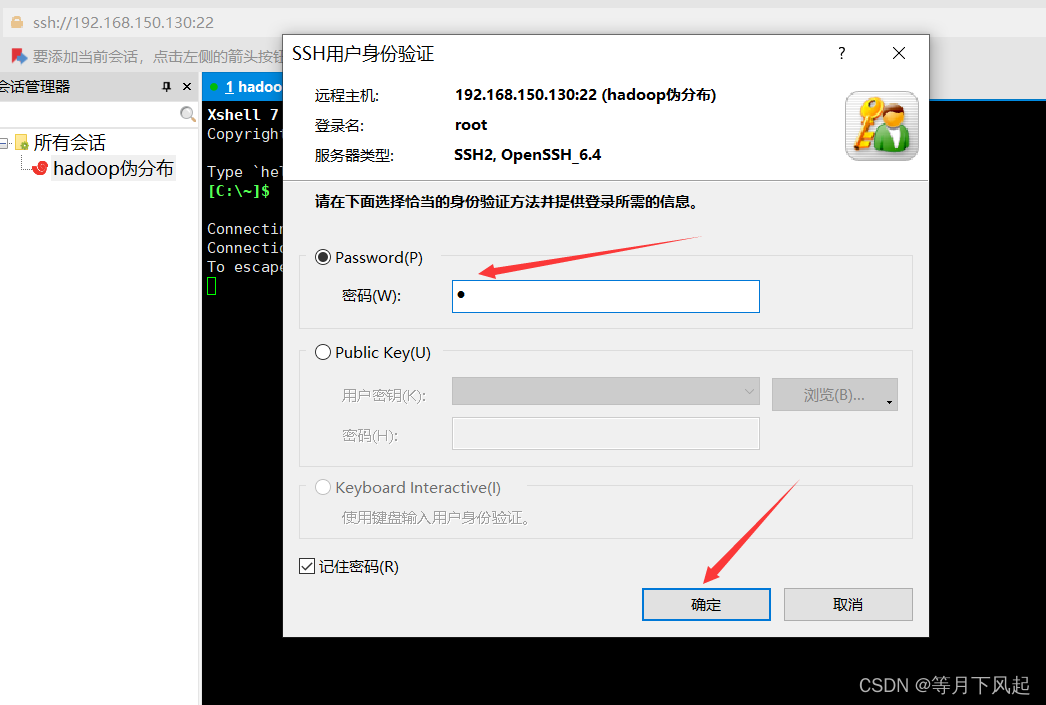
这里用户名统一是root,密码则是你自己设置的开机进入登录密码,最好两个都选择记住,为了下次登录方便。
6.0)安装好了Xshell和Xftp才可以点击这个绿色的图标
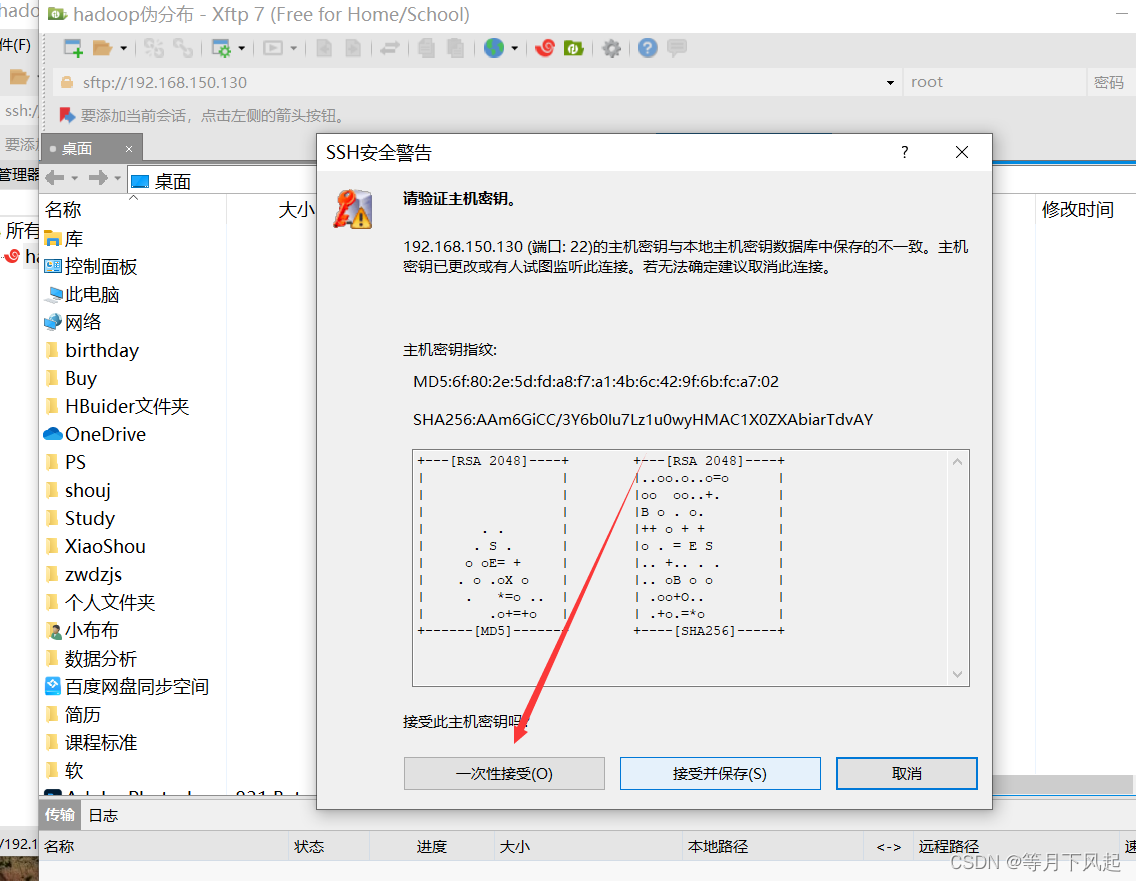
这个也应该是点击接受并保存,其实这两种都差不多。
2 .开始安装jdk和hadoop:
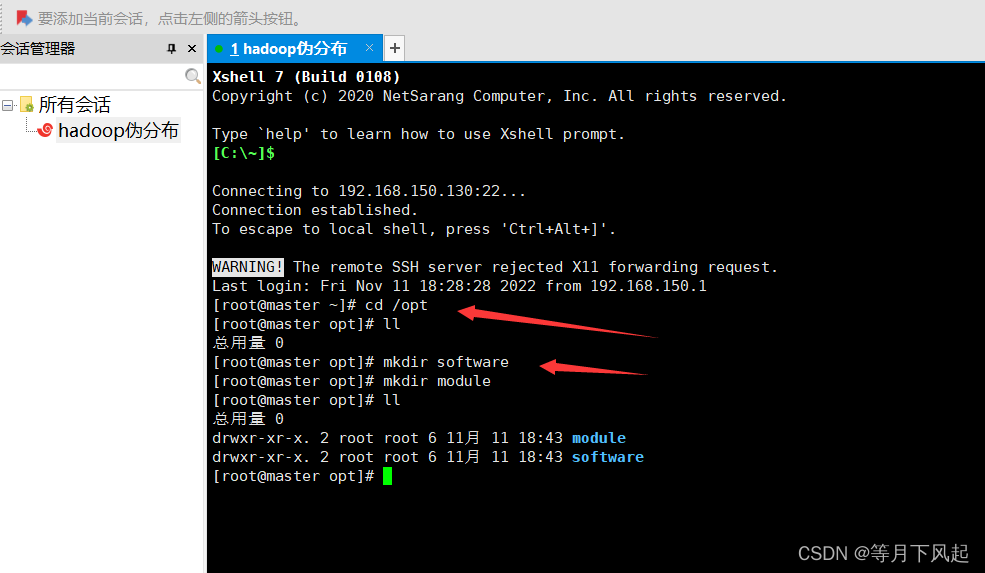
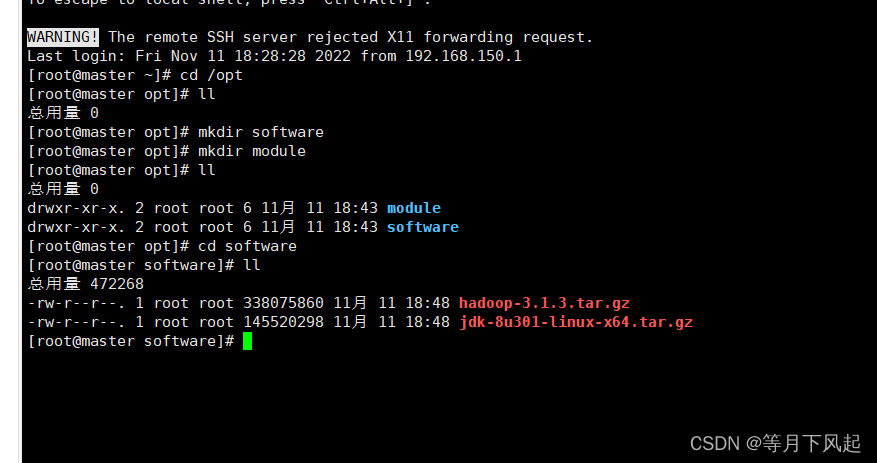
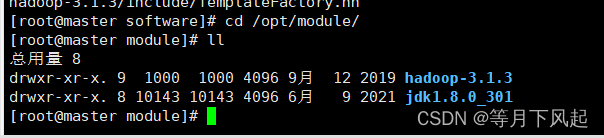
1.0)首先新建两个空目录来放置它们,这里我进入在/opt 目录下创建 software、module
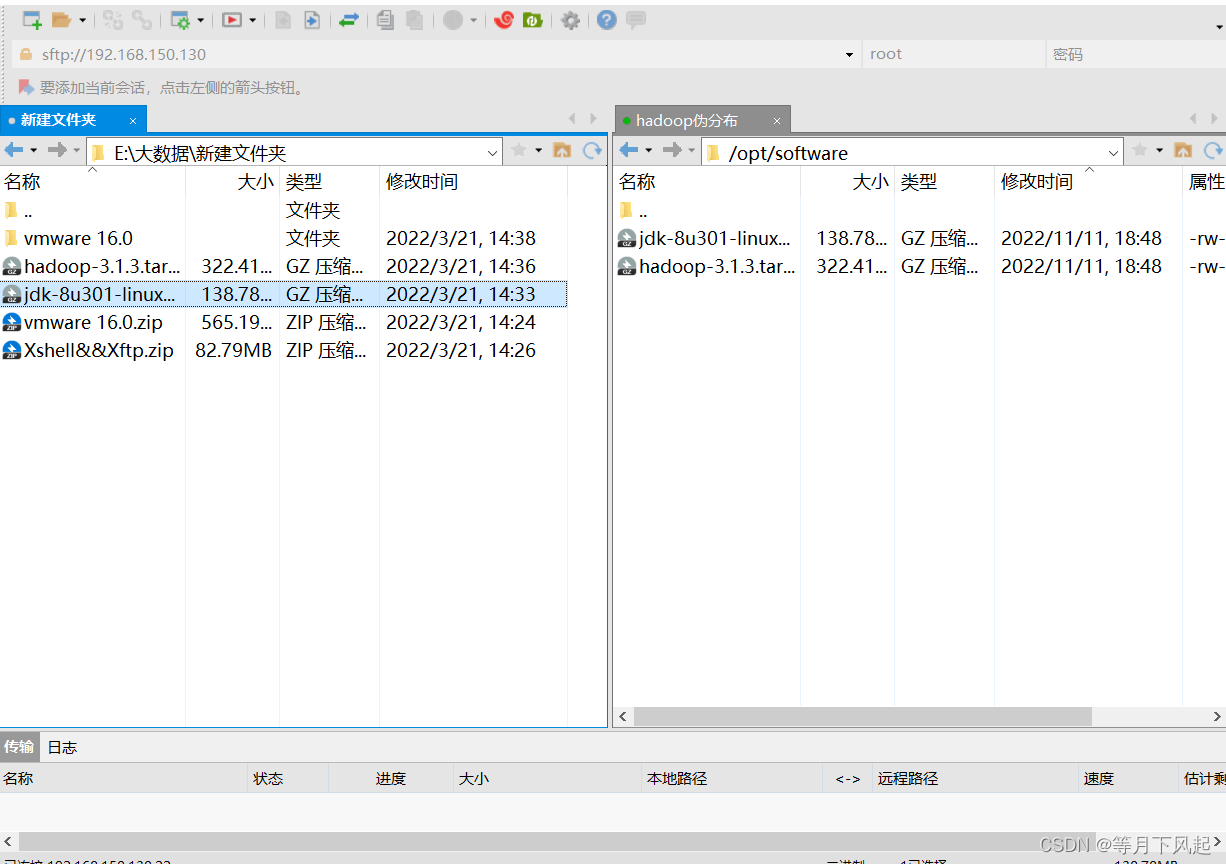
2.0)把软件把上传到 software 目录下

3.0)检测是否安装jdk及其配置
#解压 JDK并检验jdk,这里解压到/opt/module下
tar -zxvf jdk-8u301-linux-x64.tar.gz -C /opt/module/

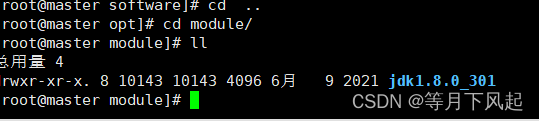
#配置环境变量,使其生效并检查 。新建 my_path.sh 文件,因为后期我们的环境比较多,所以单独放在一个文件中
# vim /etc/profile.d/my_path.sh
#JAVA_HOME
export
JAVA_HOME=/opt/module/jdk1.8.0_301
export
PATH=$PATH:$JAVA_HOME/bin


编辑完后,先点击电脑的Esc键后使用Shift和:组合键,再输入wq!保存并退出编辑vim
#使配置生效,并检查
使用source /etc/profile后输入java -version来检验其版本
#使配置生效,并检查
source /etc/profile
java -version
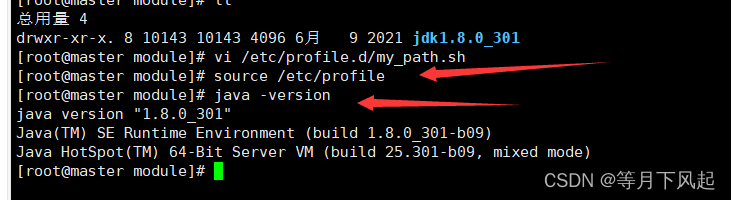
4.0)安装hadoop并配置
进入 Hadoop 安装包所在路径 cd /opt/software/
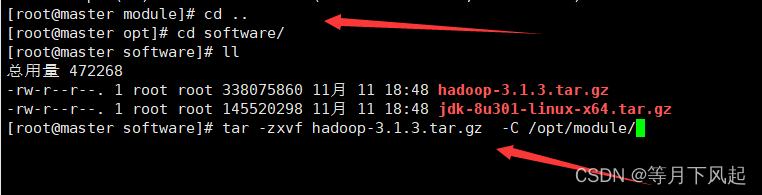
解压安装,并检查(建议小伙伴记一下解压命令,这是经常要用的)
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
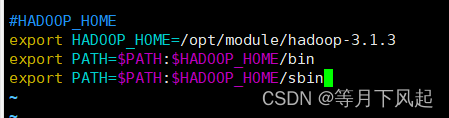
添加到环境变量,使配置生效并测试
#vim /etc/profile.d/my_path.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
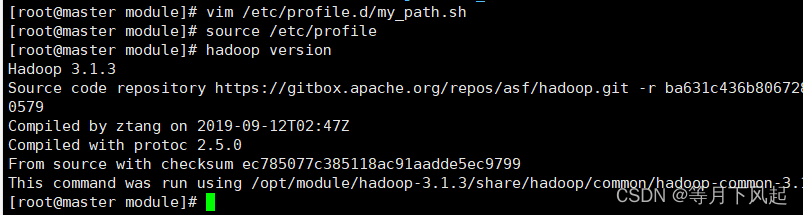
#使配置生效,并测试是否安装成功
source /etc/profile和hadoop version来检验其版本
#使配置生效,并检查
source /etc/profile
hadoop version
3.0伪分布 运行模式配置:伪分布式只需要修改 2 个配置文件即可运 行,core-site.xml 和 hdfs-site.xml
1.0)SSH 免密登录
#yum -y install openssh-server
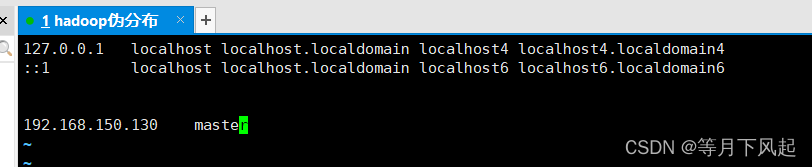
#vim /etc/hosts
192.168.150.130 master #前面是自己本机ip,后面是你的hostname
[root@master hadoop]#ssh master #其中 master 是主机名 此时 localhost 与其等效 #第一次登录会询问是否继续连接,输入 yes 即可,然后输入密码
[root@master ~]#exit #退出
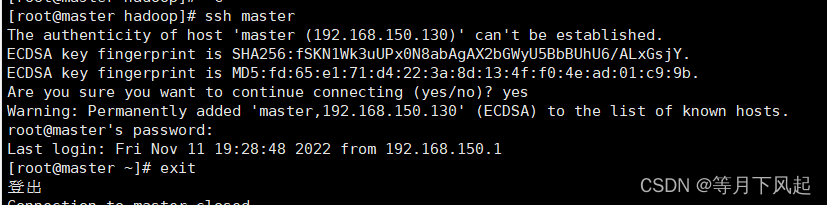
然后在,用户家目录下会生成一个.ssh目录,进入.ssh目录下
[root@master ~]#cd /root/.ssh
#生成密钥对(公钥和私钥)
[root@master .ssh]#ssh-keygen -t rsa #按 3 下回车
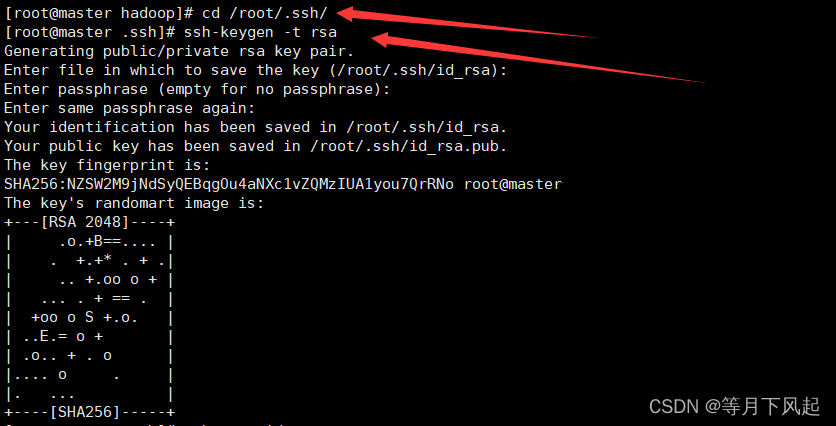
#把公钥拷贝到需要免密登录的机器上
[root@master .ssh]#ssh-copy-id master
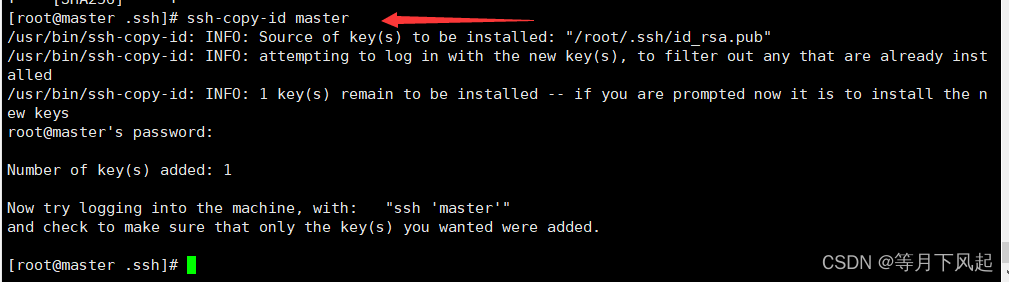
2.0) 修改配置文件
[root@master .ssh]#cd /opt/module/hadoop-3.1.3/etc/hadoop/
[root@master hadoop]#vim core-site.xml
#修改 core-site.xml 为以下内容
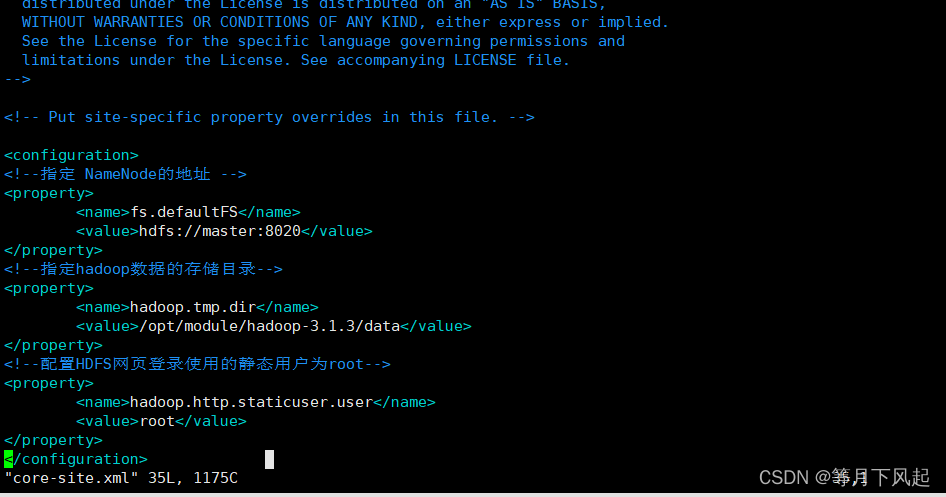
<!--指定 NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!--指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!--配置HDFS网页登录使用的静态用户为root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
[root@master hadoop]#vim hdfs-site.xml
#修改 hdfs-site.xml 为以下内容
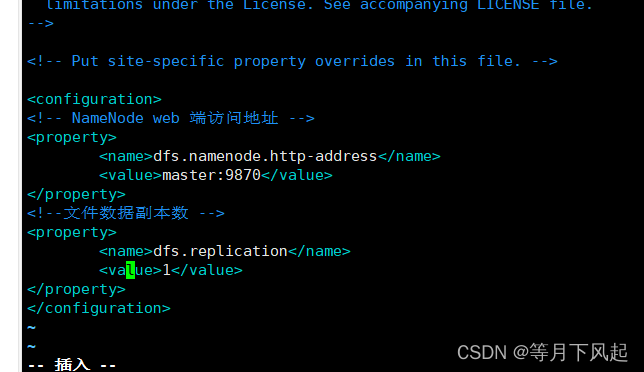
<!-- NameNode web 端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!--文件数据副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3.0)Hadoop 配置文件说明: Hadoop 的运行方式是由配置文件决定的,运行 hadoop 时会读取配置文件,因此如果需 要从伪分布式切换回单机模式,则需要删除配置文件中的配置项
首先把hadoop环境变量加入/etc/profile
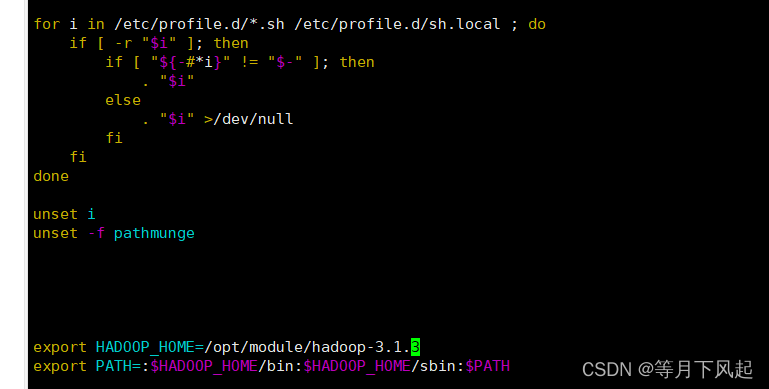
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
NameNode 格式化
[root@master hadoop]#hdfs namenode -forma
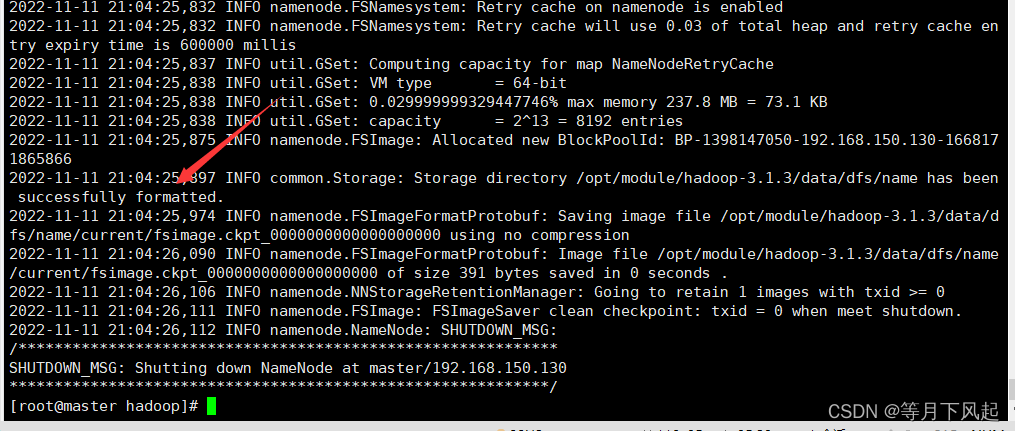
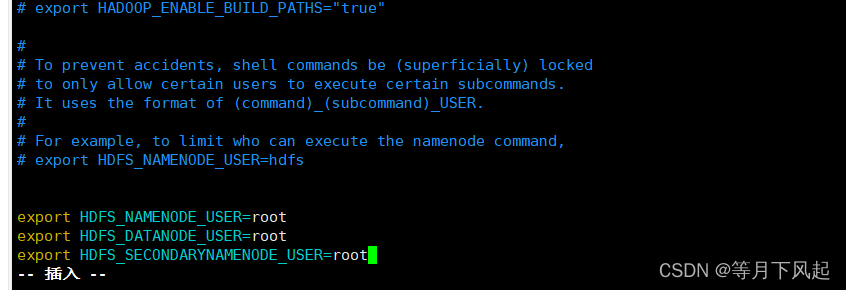
vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
#在 hadoop-env.sh 文件末尾加入以下内容 :
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
使用Shif+G可以直接跳至最后一行第一个
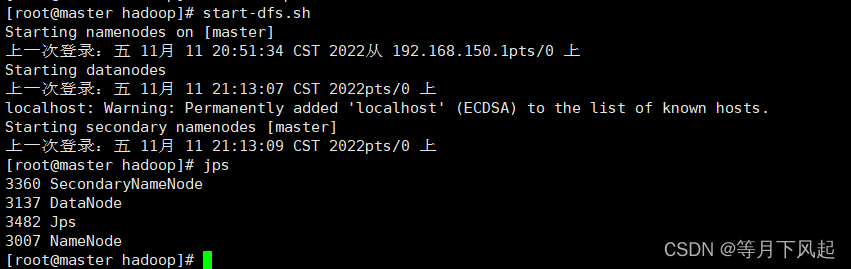
启动 NameNode 和 DataNode
[root@master hadoop]#start-dfs.sh
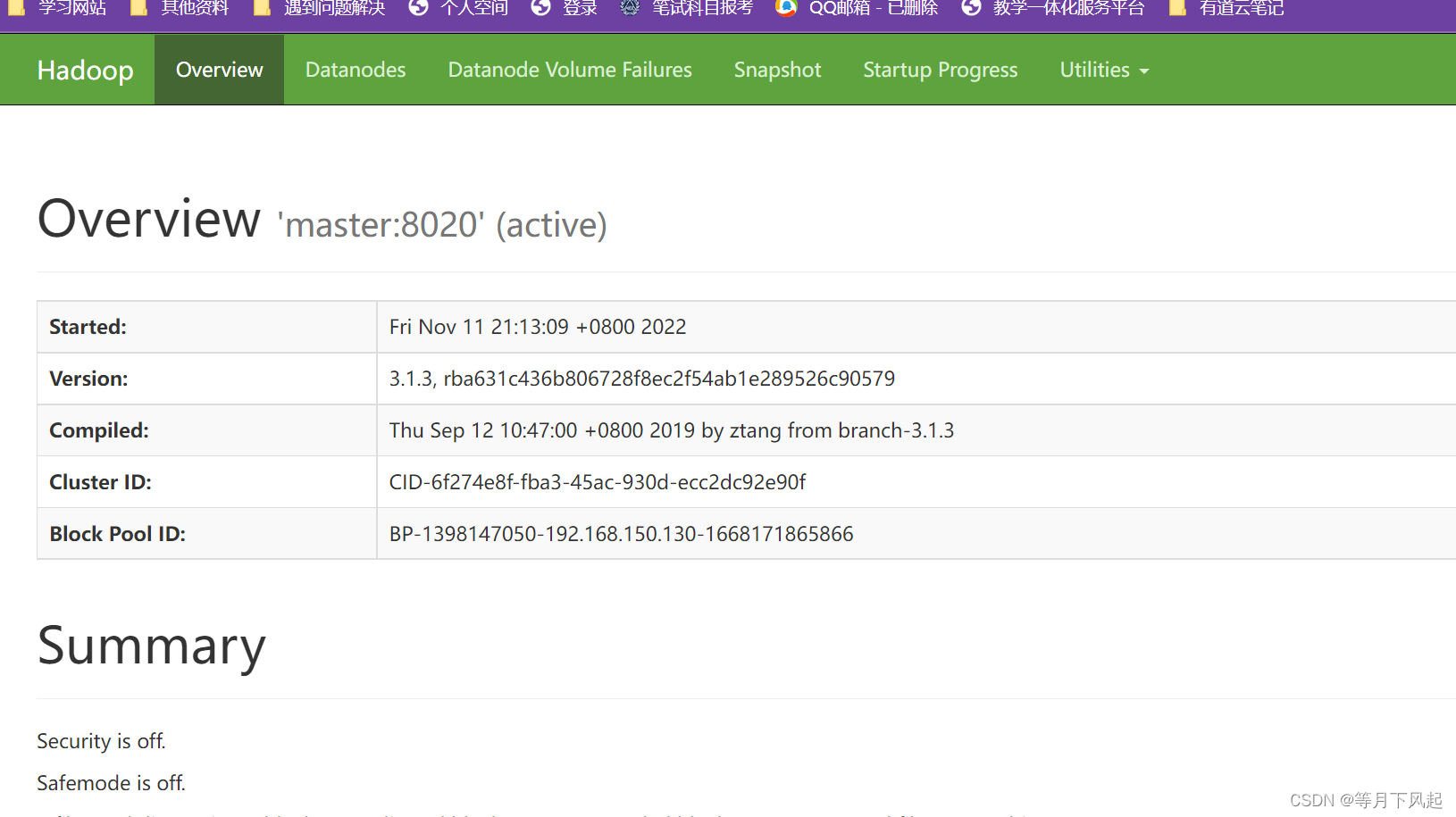
4.0)在浏览器地址栏输入http://192.168.150.130:9870/ 其中 192.168.150.130 为 主机 IP 地址,9870 为端口号
注意:在这一步之前必须关闭防火墙systemctl stop firewalld

5.0)配置 Yarn 有些人可能注意到了,怎么没有 ResourceManager 和 NodeManager 即 Yarn,Yarn 是 Hadoop2.X 才有的,从 1.X 的 MapReduce 中分离出来的,负责资源管理与任务调度, Yarn 运行于 MapReduce 之上,提供了高可用性、高扩展性。 因为 Yarn 主要是为集群提供更好的资源管理和资源调度,在单个机器上体现不出价 值,而且 Yarn 很吃内存,所以伪分布式是否开启 Yarn 看个人兴趣 操作如下:修改 yarn-site.xml
[root@master hadoop-3.1.3]#vim etc/hadoop/yarn-site.xml
#添加以下内容
<!-- Site specific YARN configuration properties -->
<!--指定 mapreduce 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value> #这里的hostname就是master
</property>
修改 mapred-site.xml
[root@master hadoop-3.1.3]#vim etc/hadoop/mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
在这里还需要指定用户,要不然会出错
#vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-env.sh ,在这里添加下面代码:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
启动Yarn
[root@master hadoop-3.1.3]#start-yarn.sh

检查进程
[root@master hadoop-3.1.3]#jps
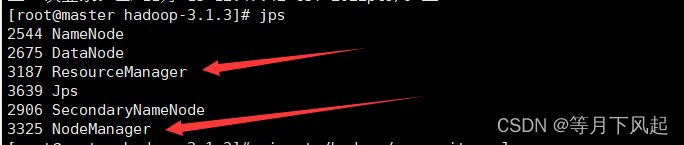
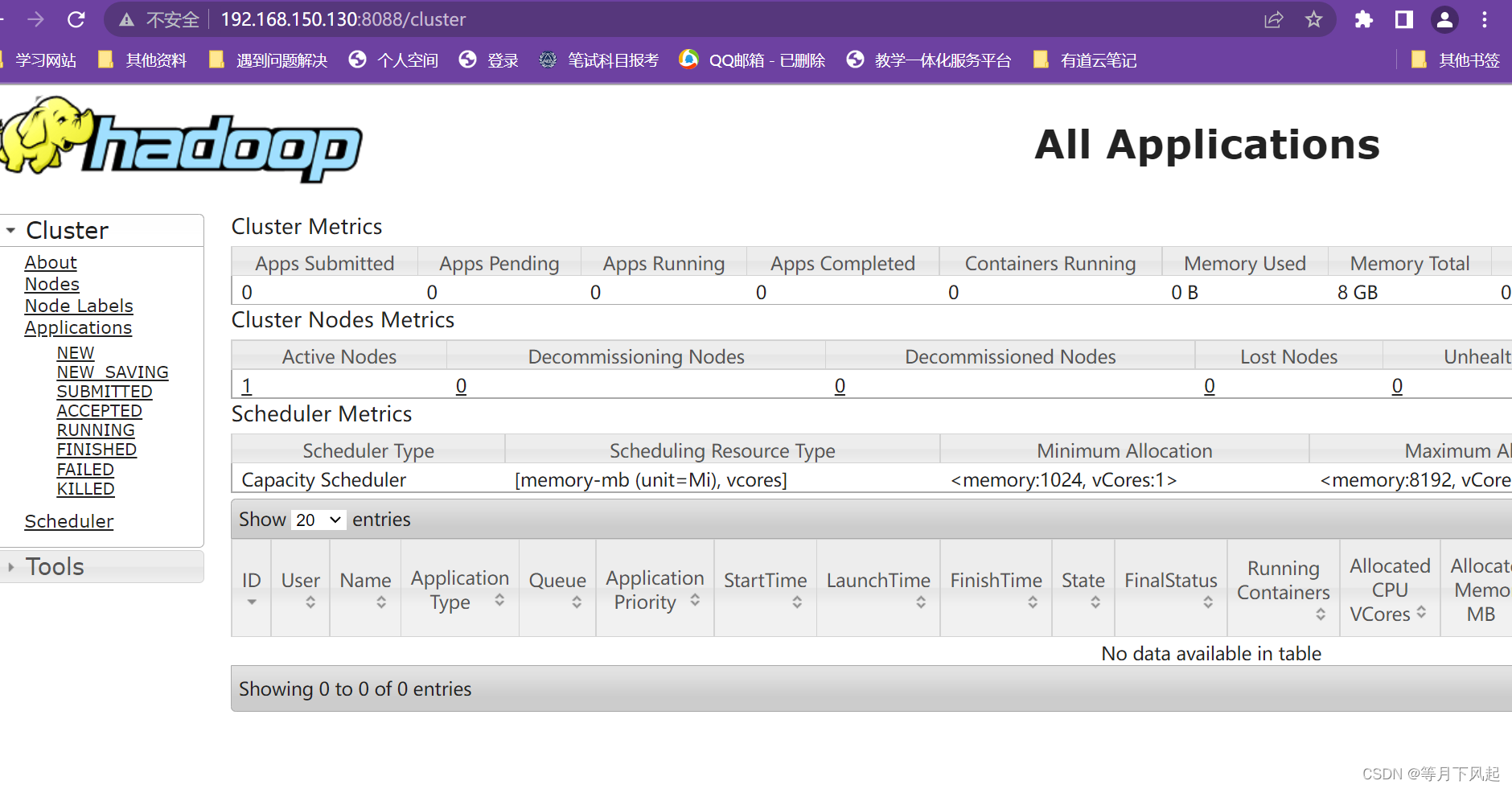
不过可以在 ResourceManager 的 Web 端看到任务运行情况 http://192.168.150.130:8088/ 主机 IP+8088 端口号
注意:这里我们之前是关闭了防护墙,如果没关闭是打不开的,当然我们这里是可以直接看到的
配置好 Yarn 后运行实例时,需要在 yarn-site.xml 加入以下内容:
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOM E</value>
</property>
不配置会报错找不到或无法加载主类,还可以用第二种方法解决。在命令行输入 hadoop classpath ,把输出的值添加到 yarn-site.xml 文件对应属 性 yarn.application.classpath 下面:
<property>
<name>yarn.application.classpath</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/hadoop-3.1.3/share/hadoop/c ommon/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3 1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/ hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/ lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/s hare/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hado op-3.1.3/share/hadoop/yarn/*</value>
</property>
两种配置等效,第二种有点冗余,自由选择。
修改配置后需要重启 Yarn
[root@master hadoop-3.1.3]#stop-yarn.sh
[root@master hadoop-3.1.3]#start-yarn
6.0)配置历史服务器
但是一旦重新启动 YARN 就无法看到之前运行过的程序的运行情况(输出结果依然 在),配置历史服务器就可以解决这一问题 ,操作如下 :
修改 mapred-site.xml
[root@master hadoop-3.1.3]#vim etc/hadoop/mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
启动历史服务器:
[root@master hadoop-3.1.3]#mapred --daemon start historyserver
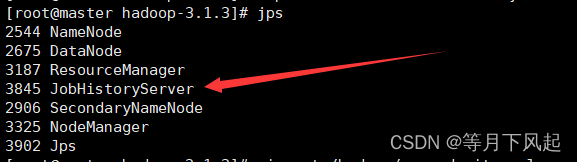
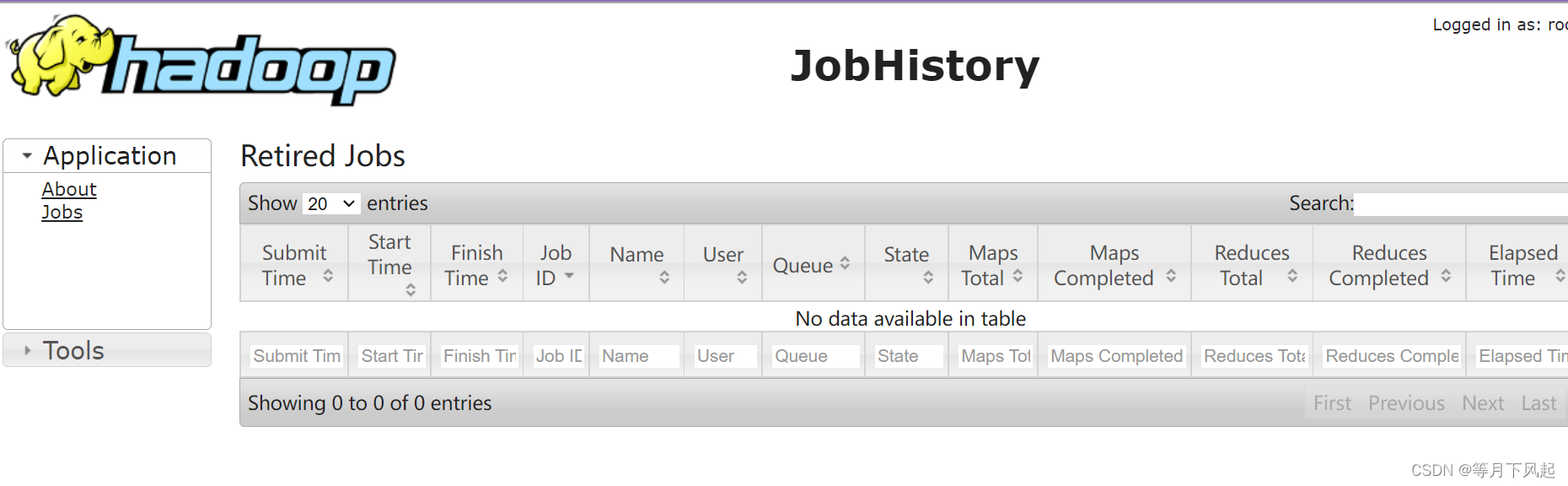
访问 http://192.168.150.130:19888/ 即主机 IP+19888 端 ,可以看到历史任务情况。
至此 hadoop伪分布就完成了,当然这个只是个开端,真正的集群是不会只在一台虚拟机上的,应该是多台虚拟机共同完成,提高了效率和可修复性。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)