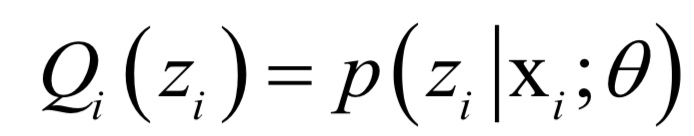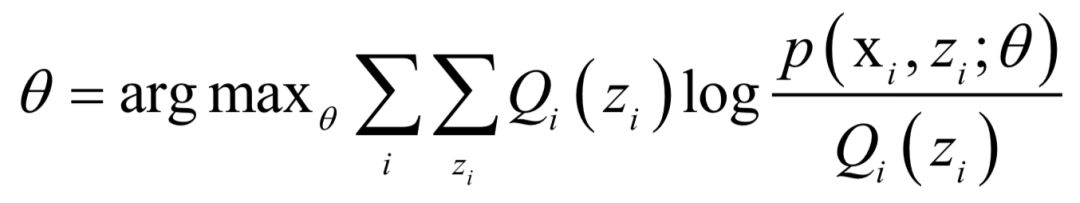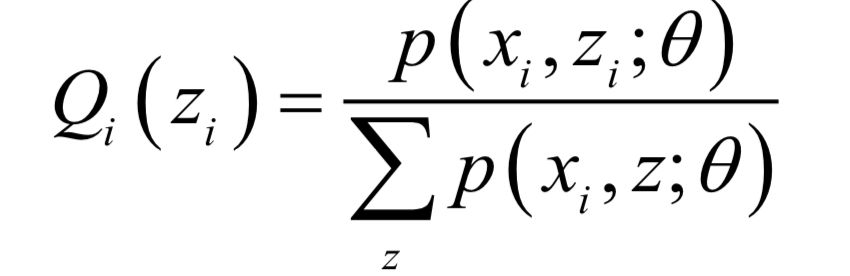支持向量机的核心思想是最大化分类间隔。简单的支持向量机就是让分类间隔最大化的线性分类器,找到多维空间中的一个超平面。它在训练是求解的问题为:
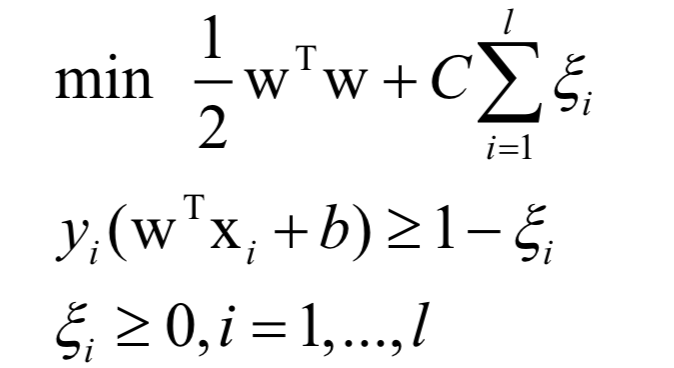
这从点到超平面的距离方程导出,通过增加一个约束条件消掉了优化变量的冗余。可以证明,这个问题是凸优化问题,并且满足Slater条件。这个问题带有太多的不等式约束,不易求解,因此通过拉格朗日对偶转换为对偶问题求解:
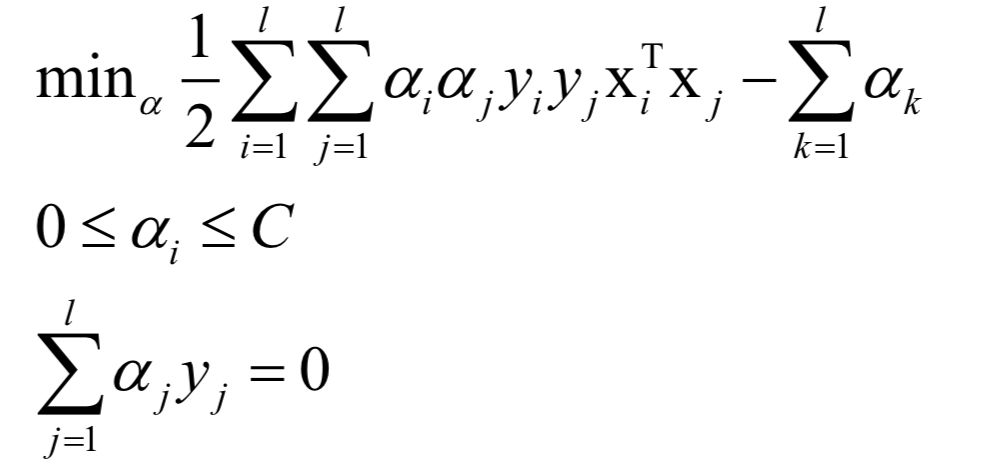
同样的,这个问题也是凸优化问题。此时支持向量机并不能解决非线性分类问题,通过使用核函数,将向量变换到高维空间,使它们更可能是线性可分的。而对向量先进行映射再做内积,等价于先做内积再做映射,因此核函数并不用显式的对向量进行映射,而是对两个向量的内积进行映射,这是核函数的精髓。要理解核函数,可以阅读
加入核函数K之后的对偶问题变为:
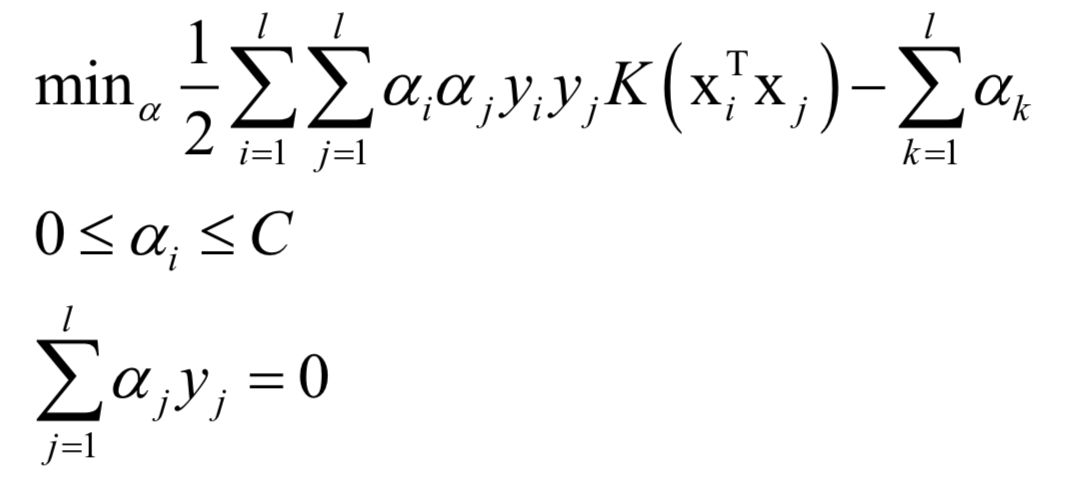
预测函数为:
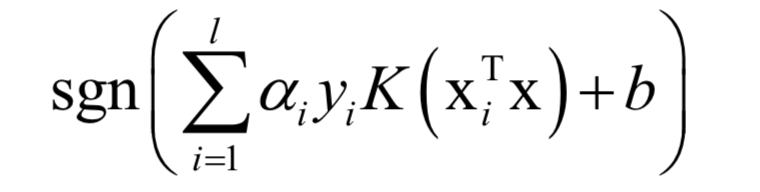
其中b通过KKT条件求出。如果使用正定核,这个问题也是凸优化问题。求解采用了SMO算法,这是一种分治法,每次挑选出两个变量进行优化,其他变量保持不动。选择优化变量的依据是KKT条件,对这两个变量的优化是一个带等式和不等式约束的二次函数极值问题,可以直接得到公式解。另外,这个子问题同样是一个凸优化问题。
标准的支持向量机只能解决二分类问题。对于多分类问题,可以用这种二分类器的组合来解决,有以下几种方案:
1对剩余方案。对于有k个类的分类问题,训练k个二分类器。训练时第i个分类器的正样本是第i类样本,负样本是除第i类之外其他类型的样本,这个分类器的作用是判断样本是否属于第i类。在进行分类时,对于待预测样本,用每个分类器计算输出值,取输出值最大那个作为预测结果。
1对1方案。如果有k个类,训练Ck2个二分类器,即这些类两两组合。训练时将第i类作为正样本,其他各个类依次作为负样本,总共有k (k − 1) / 2种组合。每个分类器的作用是判断样本是属于第i类还是第j类。对样本进行分类时采用投票的方法,依次用每个二分类器进行预测,如果判定为第m类,则m类的投票数加1,得票最多的那个类作为最终的判定结果。
除了通过二分类器的组合来构造多类分类器之外,还可以通过直接优化多类分类的目标函数得到多分类器。
SVM是一种判别模型。它既可以用于分类问题,也可以用于回归问题。标准的SVM只能支持二分类问题,使用多个分类器的组合,可以解决多分类问题。如果不使用核函数,SVM是一个线性模型,如果使用非线性核,则是非线性模型,这可以从上面的预测函数看出。如果想更详细的了解支持向量机,可以阅读
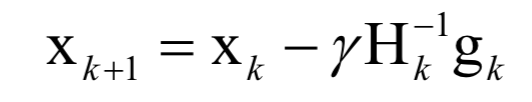
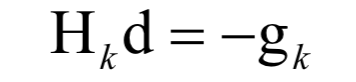
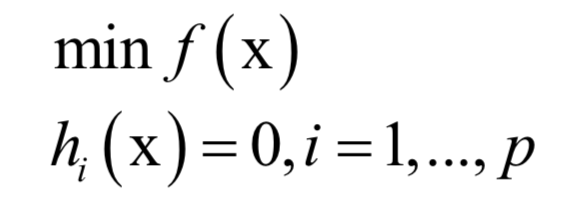
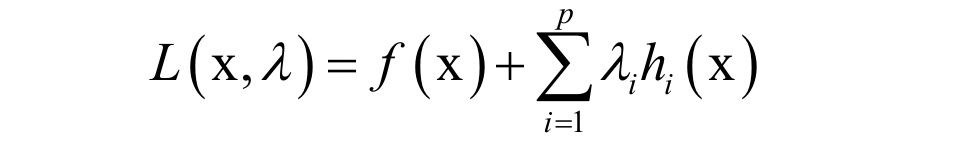
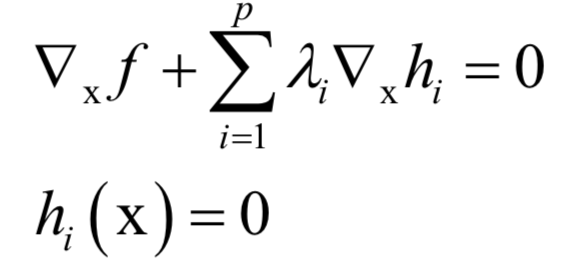
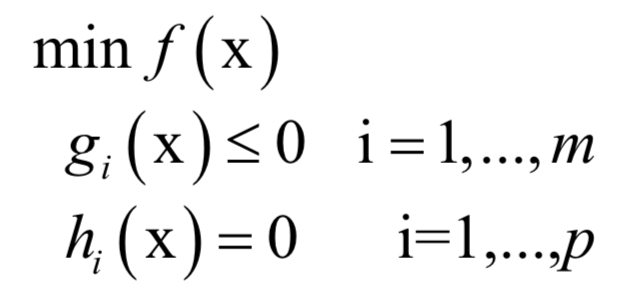
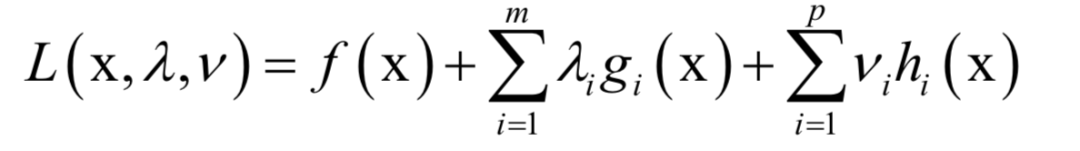
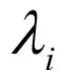 必须满足
必须满足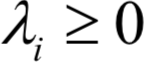 的约束。原问题为:
的约束。原问题为: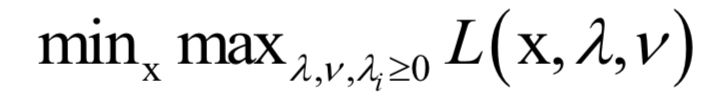
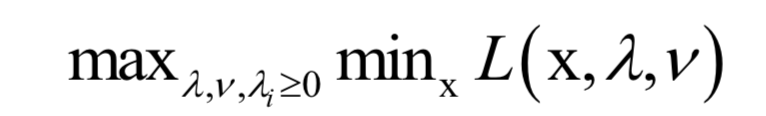
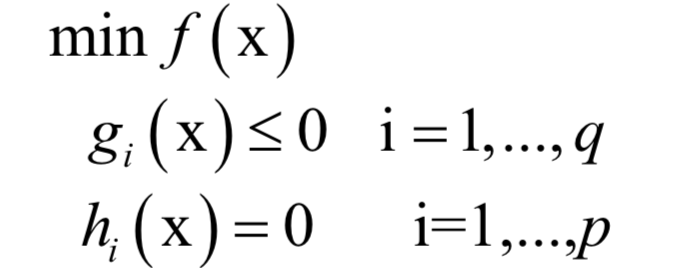
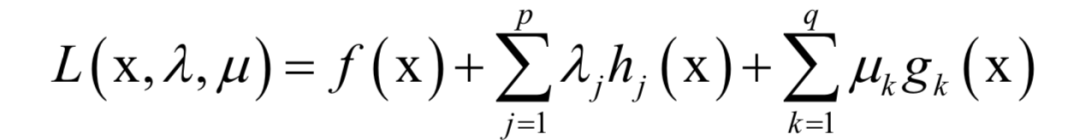
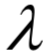 和
和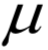 称为KKT乘子。在最优解处
称为KKT乘子。在最优解处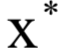 应该满足如下条件:
应该满足如下条件: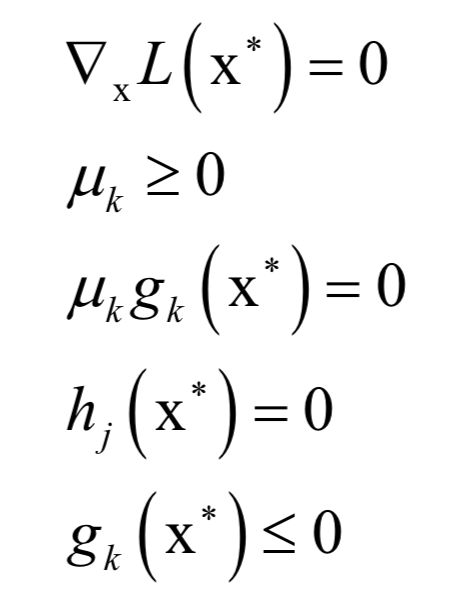
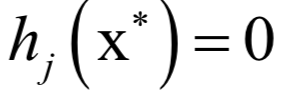
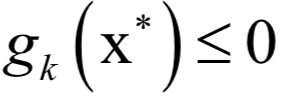
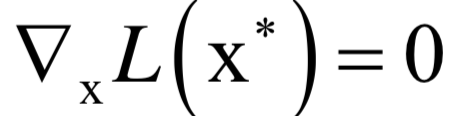 和之前的拉格朗日乘数法一样。唯一多了关于gi (x)的条件:
和之前的拉格朗日乘数法一样。唯一多了关于gi (x)的条件: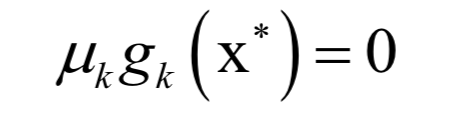
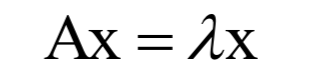
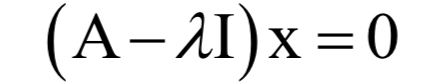
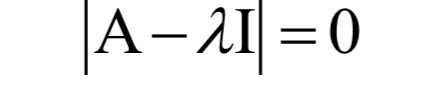
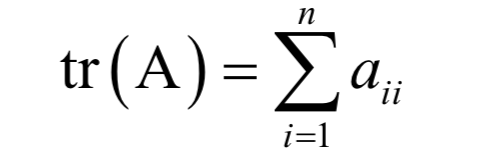
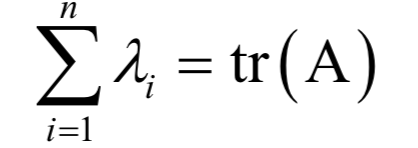
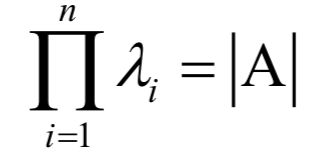
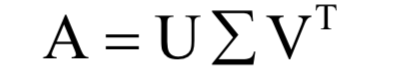
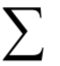 为m x n的对角矩阵,除了主对角线
为m x n的对角矩阵,除了主对角线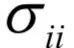 以外,其他元素都是0;V为n x n的正交矩阵,其行称为矩阵A的右奇异向量。U的列为AAT的特征向量,V的列为AT A的特征向量。
以外,其他元素都是0;V为n x n的正交矩阵,其行称为矩阵A的右奇异向量。U的列为AAT的特征向量,V的列为AT A的特征向量。 ,确定这些参数常用的一种方法是最大似然估计。
,确定这些参数常用的一种方法是最大似然估计。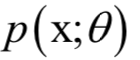 ,其中X为随机变量,
,其中X为随机变量,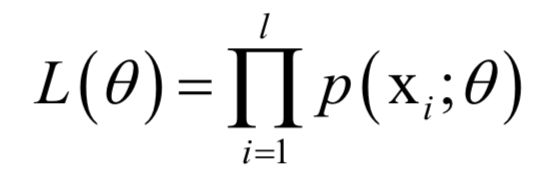
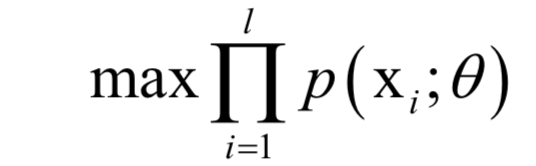
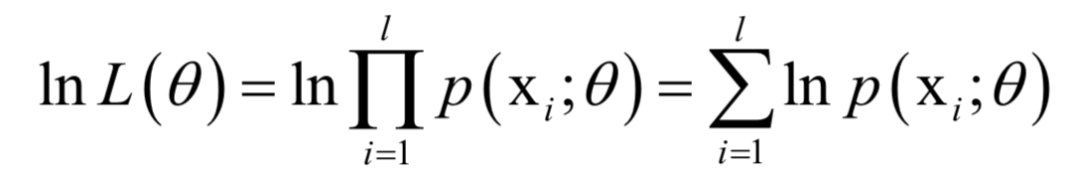
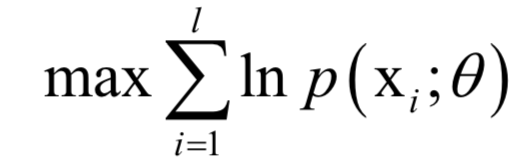
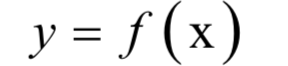
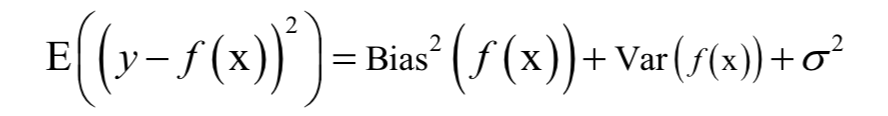

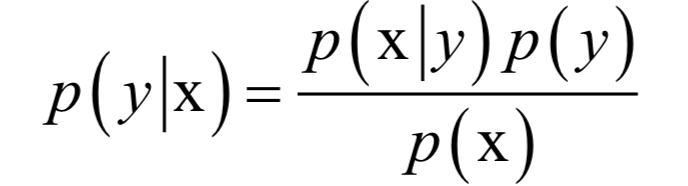
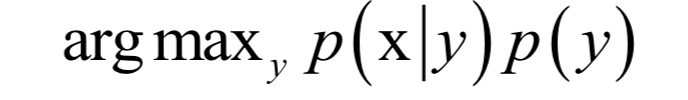
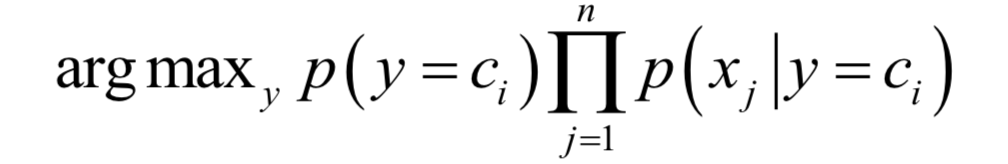
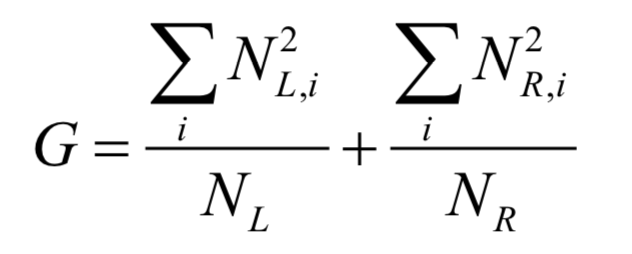
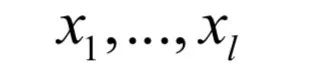
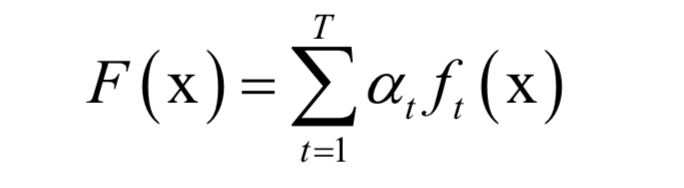
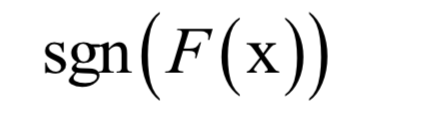

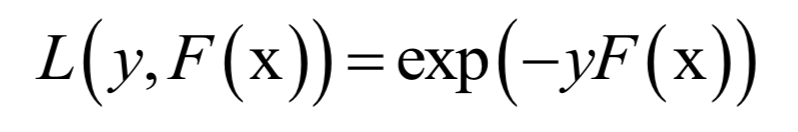
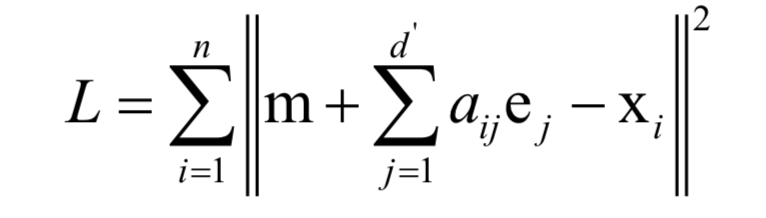
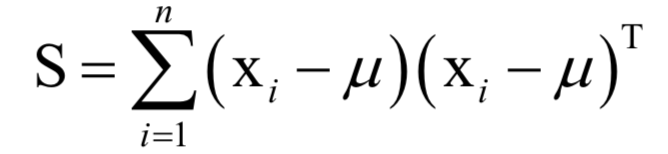
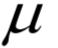 为所有样本的均值向量。则上面的重构误差最小化等价于求解如下问题:
为所有样本的均值向量。则上面的重构误差最小化等价于求解如下问题: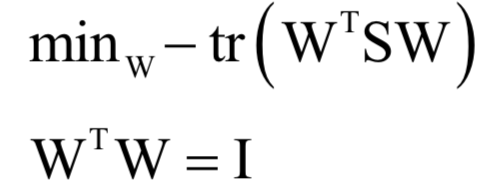
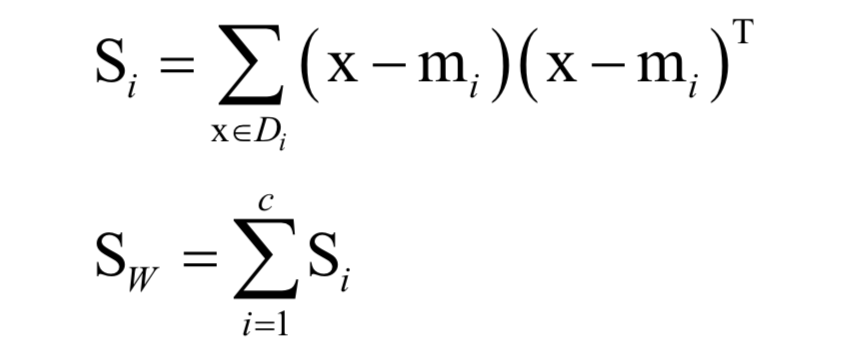
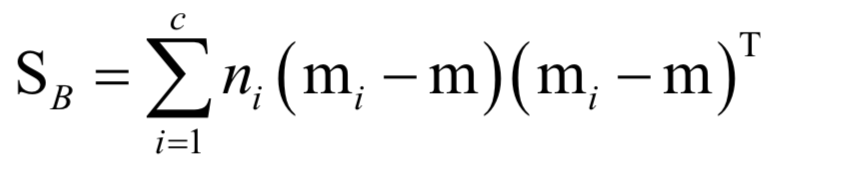

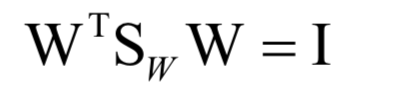
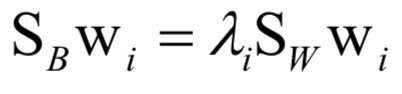
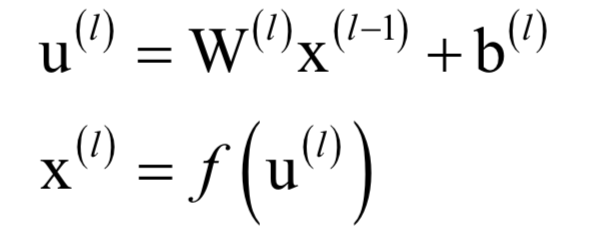
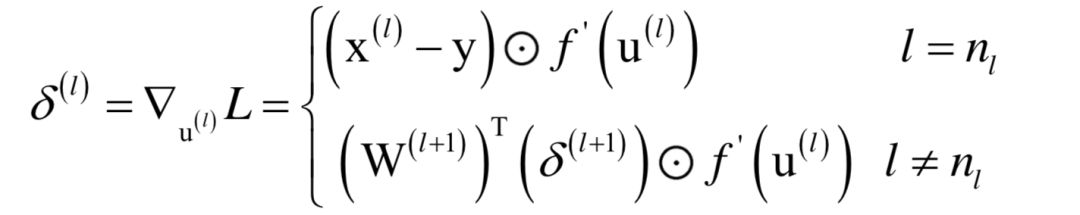
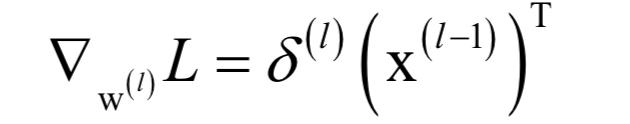
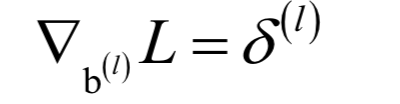
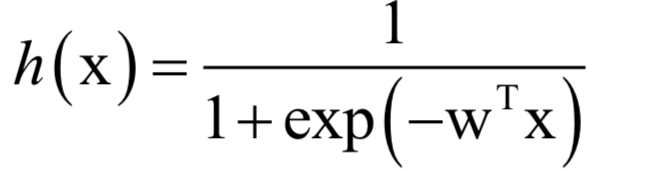
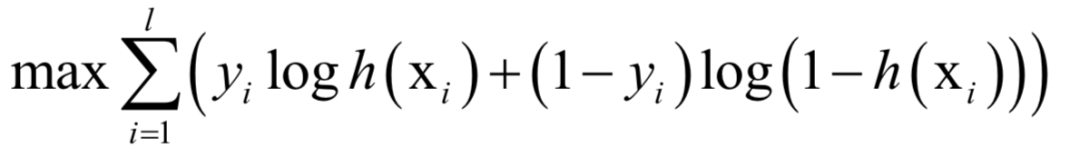
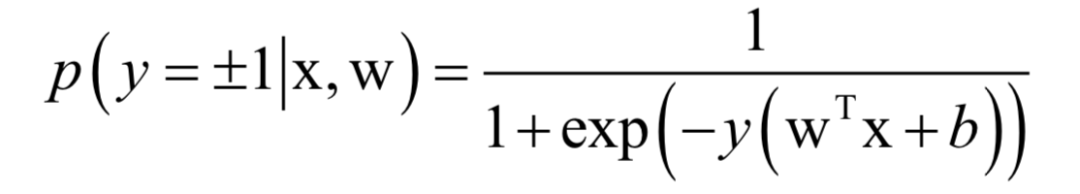
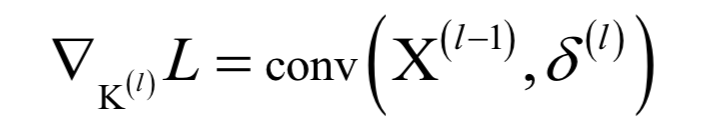
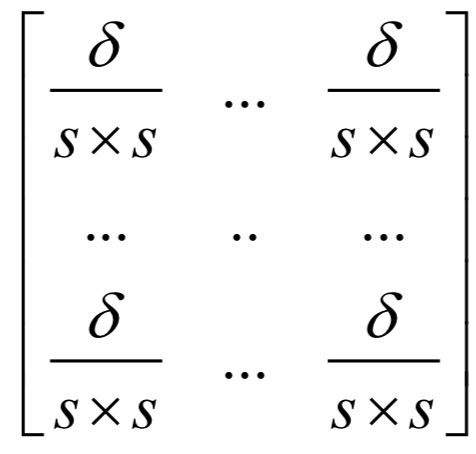
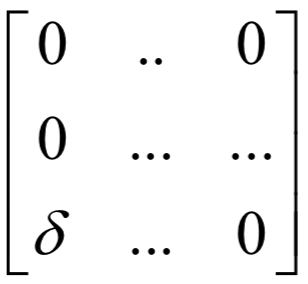
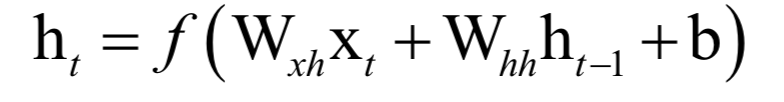
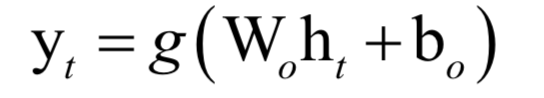
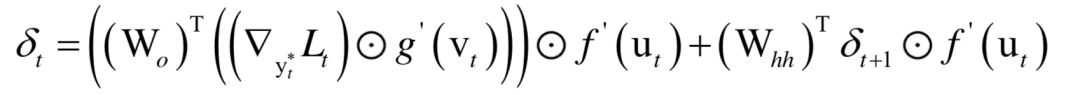
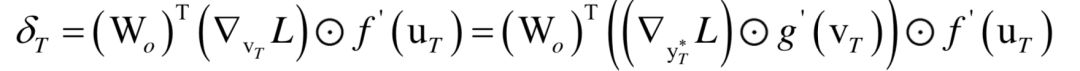
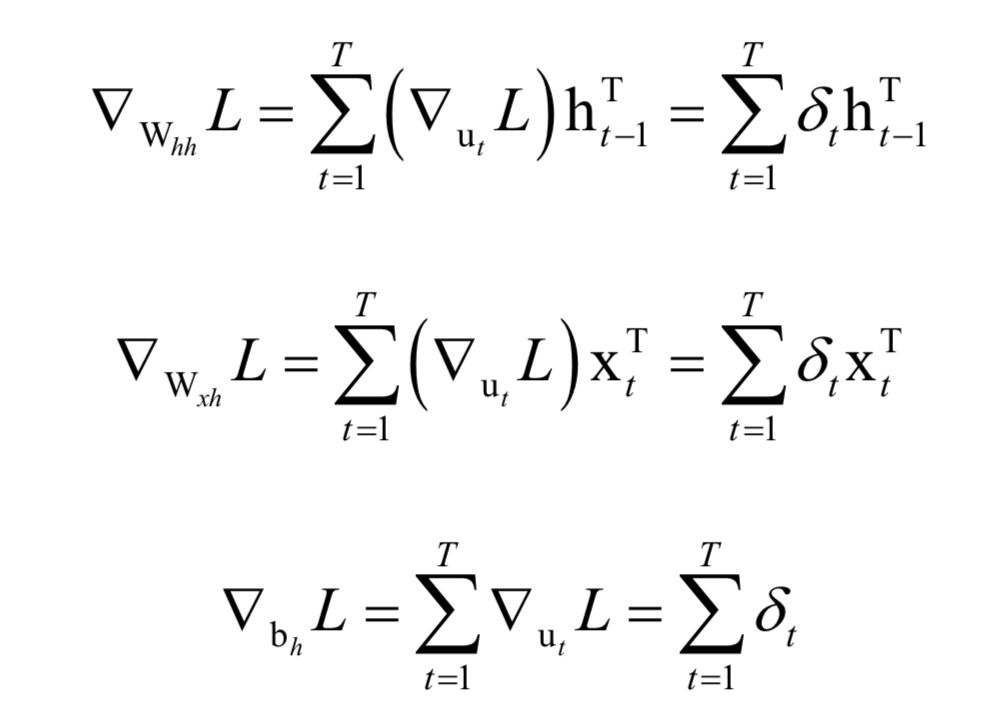
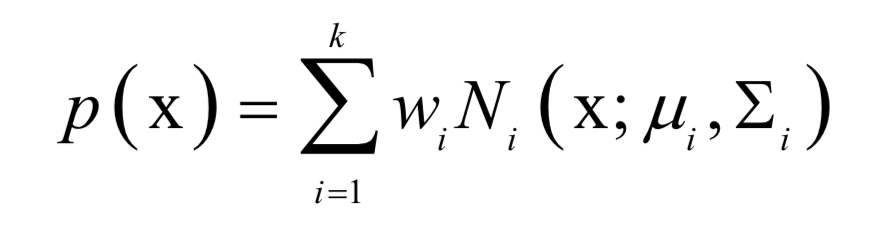
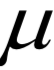 为高斯分布的均值向量,
为高斯分布的均值向量,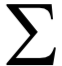 为协方差矩阵。所有权重之和为1,即:
为协方差矩阵。所有权重之和为1,即: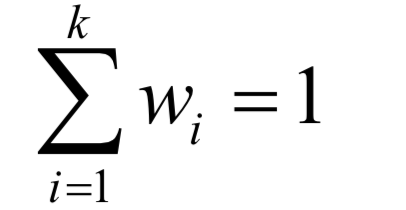
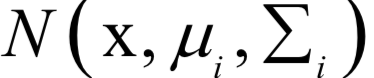 产生出这个样本数据x。高斯混合模型可以逼近任何一个连续的概率分布,因此它可以看做是连续性概率分布的万能逼近器。之所有要保证权重的和为1,是因为概率密度函数必须满足在
产生出这个样本数据x。高斯混合模型可以逼近任何一个连续的概率分布,因此它可以看做是连续性概率分布的万能逼近器。之所有要保证权重的和为1,是因为概率密度函数必须满足在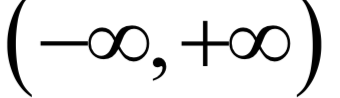 内的积分值为1。
内的积分值为1。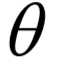 的值,接下来循环迭代,每次迭代时分为两步:
的值,接下来循环迭代,每次迭代时分为两步: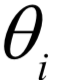 ,计算在给定x时对z的条件概率的数学期望:
,计算在给定x时对z的条件概率的数学期望: