#include "cuda_runtime.h"
#include "cublas_v2.h"
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <ctime>
using namespace std;
int main()
{
srand(time(0));
int M = 2; //矩阵A的行,矩阵C的行
int N = 3; //矩阵A的列,矩阵B的行
int K = 4; //矩阵B的列,矩阵C的列
float *h_A = (float*)malloc(sizeof(float)*M*N);
float *h_B = (float*)malloc(sizeof(float)*N*K);
float *h_C = (float*)malloc(sizeof(float)*M*K);
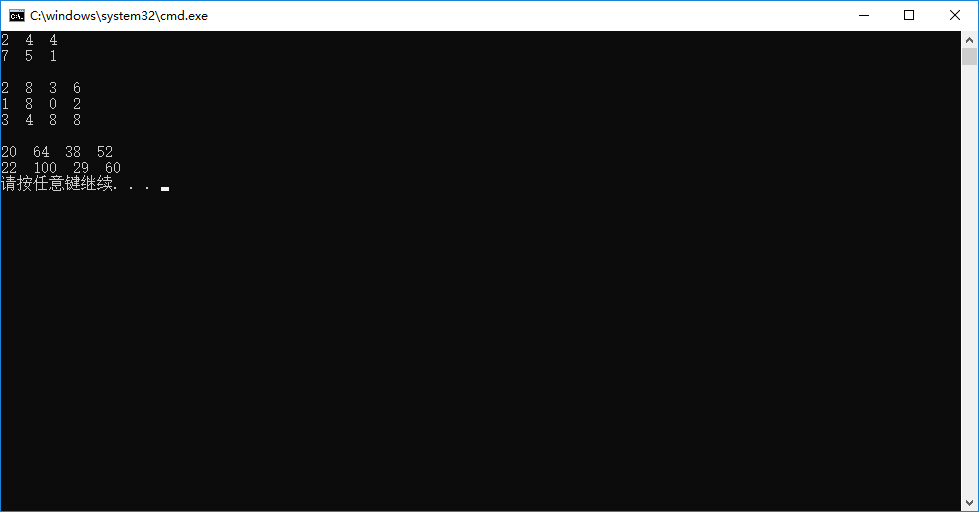
for (int i = 0; i < M*N; i++)
{
h_A[i] = rand() % 10;
cout << h_A[i] << " ";
if ((i + 1) % N == 0)
cout << endl;
}
cout << endl;
for (int i = 0; i < N*K; i++)
{
h_B[i] = rand() % 10;
cout << h_B[i] << " ";
if ((i + 1) % K == 0)
cout << endl;
}
cout << endl;
float *d_A, *d_B, *d_C,*d_CT;
cudaMalloc((void**)&d_A, sizeof(float)*M*N);
cudaMalloc((void**)&d_B, sizeof(float)*N*K);
cudaMalloc((void**)&d_C, sizeof(float)*M*K);
cudaMemcpy(d_A, h_A, M*N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, N*K * sizeof(float), cudaMemcpyHostToDevice);
float alpha = 1;
float beta = 0;
//C=A*B
cublasHandle_t handle;
cublasCreate(&handle);
cublasSgemm(handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
K, //矩阵B的列数
M, //矩阵A的行数
N, //矩阵A的列数
&alpha,
d_B,
K,
d_A,
N,
&beta,
d_C,
K);
cudaMemcpy(h_C, d_C, M*K * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < M*K; i++)
{
cout << h_C[i] << " ";
if ((i+1)%K==0)
cout << endl;
}
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}