消息中间件RabbitMq工作模型
- 什么是MQ?为什么要用MQ?
- 为什么不用TCP、HTTP、RPC、WebService,为什么要用mq?
- 使用消息队列带来的问题
- 什么是AMQP协议?
- RabbitMQ简介
- RabbitMQ工作模型
-
- RabbitMq的应用
- 怎么实现订单延迟关闭
- 队列的属性Message TTL(Time To Live)
- 死信
- 死信会去哪里?
- 死信队列和死信交换机如何使用?
- 延迟队列的其它实现
- 除了消息过期,还有什么情况会变成死信?
- RabbitMQ流量控制
-
- Spring AMQP
- Spring Boot集成RabbitMq
什么是MQ?为什么要用MQ?
mq定义:
“用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。”
基于mq的定义描述,mq具有几个主要特点:
1、是一个独立运行的服务。生产者发送消息,消费者消费消息需要先和Mq服务器建立连接。
2、采用队列的数据结构,有先进先出的特点。
3、具有发布订阅的模型,消费者可以获取自己需要的消息。
我们可以把mq比作邮局和邮差,它是用来帮我们存储和转发消息的。
为什么不用TCP、HTTP、RPC、WebService,为什么要用mq?
因为mq可以异步、解耦、削峰,mq具备传统协议所不具备的,在一些特殊场景下更有优势。
1、实现异步通信
同步的通信是什么样子的? 发出一个调用请求之后,在没有得到结果之前,就不返回。由调用者主动等待这个调用的结果。
而异步通信是相反的,调用在发出去之后,这个调用就直接返回了,所以没有返回结果。也就是说,当一个异步调用发出后,调用者不会马上得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或者通过回调函数处理这个调用。eg:例如转账过程中,出现的延迟到账。
2、实现系统解耦
引入mq后。实现了系统之间依赖关系的解耦,系统的可扩展性和可维护性得到了提升。
3、实现流量削峰
如果要保护高峰流量时刻我们的数据库和服务器,限流也是可以的,但是这样会导致业务订单的丢失。为了解决这个问题,我们可以引入mq。mq既然是queue,一定有队列特性。
队列是先进先出的排队模型,我们可以先把所有的请求流量承接下来,转换成MQ消息发送到消息队列服务器上,业务层就可以根据自己的消费速率去处理这些消息,处理后再返回结果通知到客户端。
如果要处理快一点,大不了多增加几个消费者。就像火车站春运多开几个窗口处理购票请求。
4、实现广播通信
实现一对多通信。以订单退货为例,如果新增了积分系统,需要获取订单状态变化的信息,只需要增加队列监听就可以了,生产者代码没有任何修改。
比如你买了保时捷,如果让村里所有人知道,只要跟一个大妈说一下就行了。
总结起来:
1)对于数据量大或者处理耗时长的操作,我们可以引入MQ实现异步通信,减少客户端的等待,提升响应速度,优化客户端体验。
2)对于改动影响大的系统之间,可以引入MQ实现解耦,减少系统之间的直接依赖,提升可维护性和可扩展性。
3)对于会出现瞬时的流量峰值的系统,我们可以引入MQ实现流量削峰,到达保护应用和数据库的目的
4)一对多的广播通信
使用消息队列带来的问题
打个比方,以前你直接和女友对话,现在通过小舅子传话女朋友,肯定还是会出现一些问题。
第一,运维成本的增加。既然要用mq,必须要分配资源部署MQ,还要保障它时刻正常运行。
第二,系统的可用性降低。原来是2个节点的通信,现在需要独立运行一个服务。虽然一般的MQ都有很高的可靠性和低延迟特性,但是一旦网络或者MQ服务器出现问题,就会导致请求失败,严重影响业务。
第三,系统复杂性提高。为什么说复杂?作为开发,要使用MQ,首先必须要理解相关模型和概念,才能正确使用和配置MQ。其次,使用MQ发送消息必须要考虑消息的丢失和消息重复消费的问题。一旦消息没有正确的消费,就会带来数据一致性问题。
所以,我们做系统架构的时候,选择通信方式一定要根据实际情况来分析,不要盲目引入MQ。
什么是AMQP协议?
AMQP全程是:Advanced Message Queuing Protocol,本质上是一种进程间传递异步消息的网络协议,只要遵循AMQP协议,就可以实现消息的交互。
AMQP是一个工作于应用层的协议。既然他是一种协议和规范,不是专门为RabbitMQ设计的,市面上还有许多实现了AMQP协议的消息中间件。
RabbitMQ简介
为什么要用Erlang语言呢?因为Erlang是作者Matthis最擅长的开发语言,第二Erlang是为电话交换机编写的语言,天生适合分布式和高并发。
RabbitMQ和Spring家族属于同一家公司:pivotal
当然,除了AMQP之外,RabbitMQ支持多种协议,HTTP,websockets。
RabbitMQ工作模型
由于RabbitMQ实现了AMQP协议,所以RabbitMQ的工作模型也是基于AMQP的。

Broker
我们使用RabbitMq收发消息,必须要安装一个RabbitMQ的服务,安装到windows或linux上面,默认端口是5672.这台RabbitMq服务器我们把它叫做Broker,中文翻译是代理/中介,因为MQ服务器帮助我们做的事就是存储、转发消息。
Connection
无论生产者发送消息,还是消费者接受消息,都需要跟Broker之间建立一个连接,这个连接是一个TCP的长连接。
Channel
如果所有生产者发送消息和消费者接受消息,都直接创建和释放TCP长连接的话,对于Broker来说肯定会造成很大的性能损耗。
所以在AMQP里面引入了Channel的概念,它是一个虚拟的连接。我们把它翻译成通道,或者消息通道。这样我们就可以在保持TCP长连接里面去创建和释放Channel,大大的减少了资源的消耗。
不同的Channel是相互隔离的,每个Channel都有自己的编号。对于每个客户端线程来说,Channel就没必要共享了,各自用自己的Channel。
需要注意的是,Channel是RabbitMQ原生API里面的最重要的编程接口,也就是说我们定义交换机、队列、绑定关系、发送消息、接受消息,调用的都是Channel接口上的方法。
Queue
连接到Broker以后,就可以收发消息了。
在Broker上有一个对象用来存储消息,在RabbitMq里面这个对象叫做Queue。实际上RabbitMq是用数据库来存储消息的,这个数据库跟RabbitMq一样是用Erlang开发的,名字叫Mnesia。
队列也是生产者和消费者的纽带,生产者发送的消息到达队列,在队列中存储。消费者从队列消费消息。
Consumer
消息到底是Broker推送给消费者?还是消费者主动拉取的?消费者消费消息有两种模式。
一种是Pull模式,对应方法是basicGet。消息存放在服务端,只有消费者主动拉取才可以拿到消息。如果每隔一段时间获取一次消息,消息的实时性就会降低。但是好处是可以根据自己的消费能力决定获取消息的频率。
一种是Push模式,对应方法是basicConsume,只要生产者发送消息到服务器,就可以马上推送给消费者,消息保存在客户端,实时性很高,如果消费不过来就有可能造成消息积压。Spring AMQP是push方式,通过时间机制对队列进行监听,只要有消息到达队列,就会触发消费消息的方法。
RabbitMq中pull和push都有实现。kafka和RocketMq只有pull。
由于队列有FIFO(先进先出)的特性,只能确定前一条消息被消费者接收之后,Broker才会把这条消息从数据库删除,继续投递下一条消息。
一个消费者是可以监听多个队列,一个队列也可以被多个消费者监听。
但是在生产环境中,我们一般建议一个消费者只处理一个队列的消息。如果需要提升处理消息的能力,可以增加多个消费者。
Exchange
思考一个问题,如果要把一条消息发送给多个队列,被多个消费者消费,应该怎么做?生产者是不是必须要调用多次basicPublish方法,依次发送给多个队列?就像这种消息推送场景,有成千上万个队列的时候,对生产者来说压力太大了。
有没有更好的办法呢?其实,RabbitMq已经考虑到这一点,她设计了一个帮我们路由消息的组件,叫做Exchange。
也就是说,不管有多少个队列需要接收消息,我都只需要发送到Exchange就ok了,由他来帮我们分发,Exchange是不会存储消息的,它只做一件事情,就是根据规则分发消息。
那么,Exchange和这些需要接收消息的队列必须建立一个绑定关系,并且为每个队列指定一个特殊的标识。
Exchange和队列之间是多对多的绑定关系,也就是说,一个交换机的消息可以路由给多个队列,一个队列也可以接收来自多个交换机的消息。
建立绑定关系后,生产者发送消息到Exchange,会携带一个特殊的标识。当这个标识跟绑定的标识匹配的时候,消息就会发给一个或者多个符合规则的队列。
Vhost
我们基于RabbitMq实现的异步通信的系统,都需要在Broker上创建自己要用的交换机、队列和它们的绑定关系。如果某个业务系统不想跟别人混用一个Broker,怎么办?再购买一台硬件服务器单独安装一个RabbitMq服务?这种方式成本太高了。在同一个服务器上安装多个RabbitMq服务呢?比如在运行一个5673的端口?
没有必要这样做,因为RabbitMq也考虑到这一点,设计了虚拟主机Vhost。
Vhost可以实现资源的隔离和权限的控制。它的作用类似于编程中的namespace和package,不同的VHOST中可以有同名的Exchange和Queue,它们是完全透明的。
这个时候,我们可以为不同的业务系统创建专属于它们自己的Vhost,然后再为它们创建专属的用户,给用户分配对应的VHOST的权限。比如给风控系统分配风控系统的VHOST的权限,这个用户可以访问里面的交换机和队列。给超级管理员分配所有的VHOST的权限。
我们安装RabbitMQ的时候会自带一个默认的Vhost,名字是“/”。
路由方式
我们说到RabbitMq引入Exchange是为了实现消息的灵活路由,到底有哪些路由方式?
RabbitMq中一共有四种类型的交换机,Direct、Topic、Fanout、Headers。其中Headers不常用。交换机类型可以在创建的时候指定,网页或者代码中。
Driect直连
一个队列于直连类型交换机绑定,需要指定一个明确的绑定键(binding key)
生产者发送消息时会携带一个路由键(routing key)
当消息的路由键与某个队列的绑定键完全匹配时,这条消息才会从交换机路由到这个队列上。多个队列也可以使用相同的绑定键。
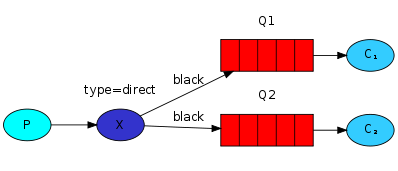
多重绑定:同一个绑定键可以绑定到不同的队列上去,在上图中,我们也可以增加一个交换器X与队列Q2的绑定键,在这种情况下,直连交换器将会和广播交换器有着相同的行为,将消息推送到所有匹配的队列。一个路由键为black的消息将会同时被推送到队列Q1和Q2。
在我们之前的日志系统中,所有的消息被广播给所有的消费者,但是本章的需要是希望有一个程序可以只接收error级别的日志并保存到磁盘中,而不用浪费空间去存储那些info、warning级别的日志。
我们正在用的广播模式的交换器并不够灵活,它只是不加思索地进行广播。因此,需要使用direct exchange来代替。直连交换器的路由算法非常简单:将消息推送到binding key与该消息的routing key相同的队列。
为了说明这点,请看下图:
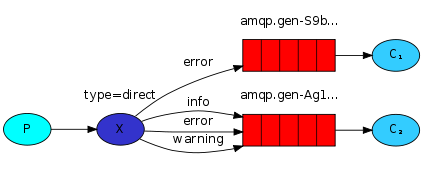
在该图中,直连交换器X上绑定了两个队列。第一个队列绑定了绑定键error,第二个队列有3个绑定键:error和info、warning。
在这种场景下,一个消息在布时指定了路由键为error将会只被路由到队列Q1和Q2,路由键为info和warning的消息都将被路由到队列Q2。其他的消息都将被丢失。
Topic主题
一个队列和主题类型交换机绑定时,可以在绑定键中使用通配符。支持2个通配符:
#代表0个或者多个单词
*代表不多不少一个单词
单词指的是用英文的点“.”隔开的字符。例如a.bc,def是3个单词
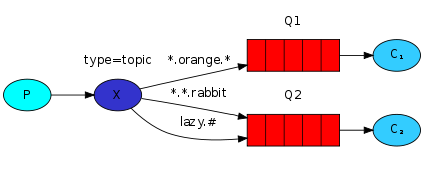
解释:
在这个例子中,我们将会发送一些描述动物的消息。Routing key的第一个单词是描述速度的,第二个单词是描述颜色的,第三个是描述物种的:“..”。
这里我们创建三个Binding:Binding key为”.orange.”的Q1,和binding key为”..rabbit”和”lazy.#”的Q2。
这些binding可以总结为:
Q1对所有橘色的(orange)的动物感兴趣;
Q2希望能拿到所有兔子的(rabbit)信息,还有比较懒惰的(lazy.#)动物信息。
一条以” quick.orange.rabbit”为routing key的消息将会推送到Q1和Q2两个queue上,routing key为“lazy.orange.elephant”的消息同样会被推送到Q1和Q2上。
但如果routing key为”quick.orange.fox”的话,消息只会被推送到Q1上;routing key为”lazy.brown.fox”的消息会被推送到Q2上,routing key为"lazy.pink.rabbit”的消息也会被推送到Q2上,但同一条消息只会被推送到Q2上一次。
如果在发送消息时所指定的exchange和routing key在消费者端没有对应的exchange和binding key与之绑定的话,那么这条消息将会被丢弃掉。例如:“orange"和"quick.orange.male.rabbit”。但是routing为”lazy.orange.male.rabbit”的消息,将会被推到Q2上一次。
Topic类型的exchange:
Topic类型的exchange是很强大的,也可以实现其它类型的exchange。
当一个队列被绑定为binding key为”#”时,它将会接收所有的消息,此时和fanout类型的exchange很像。
当binding key不包含”*”和”#”时,这时候就很像direct类型的exchange。
Fanout广播
广播类型的交换机与队列绑定时,不需要指定绑定键。因此生产者发送消息到广播类型交换机上,也不需要携带路由键。消息到达交换机时,所有与之绑定了的队列,都会收到相同的消息的副本。
RabbitMq的应用
怎么实现订单延迟关闭
业务场景:超过30分钟未付款的订单自动关闭,这个功能应该怎么实现?
思路:发一条跟订单相关的消息,30分钟后被消费,在消费者的代码中查询订单数据,如果支付状态是未付款,那就关闭订单。
问题来了,如何实现在指定的时候之后消息才发给消费者呢?
RabbitMq本身不支持延迟投递,总的来说有2种实现方案:
1、先存储到数据库,再用定时任务扫描。
2、利用RabbitMQ的死信队列(Dead Letter Queue)实现
定时任务比较容易实现,比如每隔1分钟扫描一次,查出来30分钟之前未付款的订单,把状态改为关闭。但是如果瞬时要处理的数据量过大,比如10万条,把这些全部的数据查询到内存中逐条处理,也会给服务器带来很大压力,影响业务的正常运行。
利用死信队列如何实现?
这里我们可以借助rabbitMq消息的过期时间特性实现。
队列的属性Message TTL(Time To Live)
首先,队列有一个消息过期属性。就像蜂巢超过24小时就收费一样,通过设置这个属性,超过了指定时间的消息将会被丢弃。
这个属性叫:x-message-ttl
所有队列中的消息超过时间未被消费,都会过期。
//声明延迟队列
Map<String,Object> map = new HashMap<String,Object>();
map.put("x-message-ttl",10000);
channel.queueDeclare(QUEUE_NAME,false,false,false,map);
但是这种方式不是那么灵活,所以RabbitMq的消息也有单独的过期时间属性。
问题:如果队列msg TTL是6秒过期,消息的msg TTL是10秒过期,这个消息会在什么时候被丢弃?
如果同时指定了Message TTL和Queue TTL,则小的那个时间生效。
有了过期时间还不够,这个消息不能直接丢弃,不然就没办法消费了。最好的是丢到一个容器里面,这样就可以实现延迟消费了。
我们来了解一下死信概念。
死信
消息过期以后,如果没有任何配置,是会被直接丢弃的。我们可以通过配置让这样的消息变成死信(Dead Letter),在别的地方存储。
死信会去哪里?
队列在创建的时候可以指定一个死信交换机DLX(Dead Letter Exchange)。死信交换机绑定的队列称为死信队列DLQ(Dead Letter Queue),DLX实际上也是普通的交换机,DLQ也是普通的队列。

也就是说,如果消息过期了,队列指定了DLX,就会发送到DLX,而不会丢弃。如果DLX绑定了DLQ,就会路由到DLQ。路由到DLQ之后,我们就可以消费了。
死信队列和死信交换机如何使用?
第一步,声明原交换机(original_exchange),原队列(original_queue),相互绑定。指定原队列的死信交换机(Dead_Letter_exchange).
第二步,声明死信交换机(Dead_Letter_exchange)和死信队列(Dead_Letter_queue),并且通过“#”绑定,代表无条件路由。
第三部,最终消费者监听死信队列,在这里实现检查订单状态逻辑
第四步,生产者发送消息测试,设置消息10秒过期。
延迟队列的其它实现
使用死信队列实现延时消息的缺点:
1)如果统一用队列设置消息的TTL,当梯度非常多的情况下,比如1分钟,2分钟,5分钟…需要创建多个交换机和队列来路由消息。
2)如果用单独设置消息的TTL,则可能会造成队列中的消息阻塞,前一条消息没有出队(没有被消费),后面的消息无法投递(比如第一条消息过期TTL是30分钟,第二条是10分钟。10分钟后第二条消息该投递了,但是由于第一条消息还未出队,所以无法投递)
3)可能存在一定时间差
在RabbitMQ 3.5.7 及以后的版本提供了一个插件(rabbitmq_delayed_message_exchange)来实现延迟队列功能。
Map<String,Object> args = new HashMap<String,Object>();
args.put("x-delayed-type","direct");
return new TopicExchange("Delay_exchange",true,false,args)
消息属性中指定x-delay参数
MessageProperties properties = new MessageProperties();
properties.setHeader("x-delay",delayTime.getTime()-now.getTime());
Message message = new Message(msg.getBytes(),properties);
rabbitTemplate.send("Delay_exchange","#",message);
除了消息过期,还有什么情况会变成死信?
1)消息被消费者拒绝并且未设置重回队列:
(NACK||Reject)&&requeue==false
2)队列达到最大长度,超过了Max length(消息数)或者(字节数)max length bytes,那么最先入队的消息会被发送到DLX
RabbitMQ流量控制
我们知道,RabbitMq的消息是存在磁盘上的,如果是内存节点,会同时存在磁盘和内存中。当RabbitMq生产MQ消息的速度远大于消费的速度时,会产生大量的消息堆积,占用系统资源,导致机器性能下降。我们想要控制服务端接受消息的数量,应该怎么做呢?
流量方面我们可以从2个方面控制,一个是服务端,一个是消费端。
服务端流控
队列长度
队列有两个控制长度的属性:
x-max-length:队列中最大存储最大消息数,超过这个数量,对头的消息会被丢弃。
x-max-length-bytes:队列中存储的最大消息容量,超过这个容量,队头消息会被丢弃。
需要注意的是,设置队列长度只在消息堆积的情况下有意义,而且会删除先入队的消息,不能真正的实现服务端限流。
有没有其它办法实现服务端限流?
内存控制
RabbitMQ会在启动时检测物理机器内存的数值。默认当MQ占用40%以上内存,MQ会抛出一个内存警告并阻塞所有连接。可以通过修改rabbitmq.config 文件来调整内存阈值,默认值是0.4,如果用动态命令设置为0,则所有消息都不能发布。
磁盘控制
当磁盘低于指定阈值,触发流控措施。
还有一种情况,虽然Broker消息存储的过来,但是在push模型下(consume,有消息就消费),消费者消费不过来了,这个时候也要进行流量控制。
消费端限流
默认情况下,如果不进行配置,RabbitMq会尽快把队列中的消息发送到消费者。因为消费者会在本地缓存消息,如果消息数量过多,可能会导致OOM或者影响其它进程的正常运行。
在消费者处理消息的能力有限,例如消费者数量太少,或者单条消息处理时间过长的情况下,我们希望在一定数量的消息消费完之前,不再推送消息过来,就要用到消费端的流量限制措施。
我们可以基于Consumer或者channel设置prefetch count的值,含义为Consumer端的最大的unacked messages数目。当超过这个数值的消息未被确认,RabbitMq会停止投递新的消息给该消费者。
channel.basicQos(2);
channel.basicConsume(Queue_Name,false,consumer);
Spring AMQP
Spring封装RabbitMq的时候,他做了什么事情?
1、管理对象(队列、交换机、绑定)
2、封装方法(发送消息,接收消息)
Spring Boot集成RabbitMq
为什么没有定义Spring AMQP的任何一个对象,也能实现消息的收发?Spring Boot做了什么?
RabbitAutoConfiguration.java
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)