模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,这就是few shot learning 要解决的问题。
对比学习拉近同类样本的距离,拉远异类样本的距离。
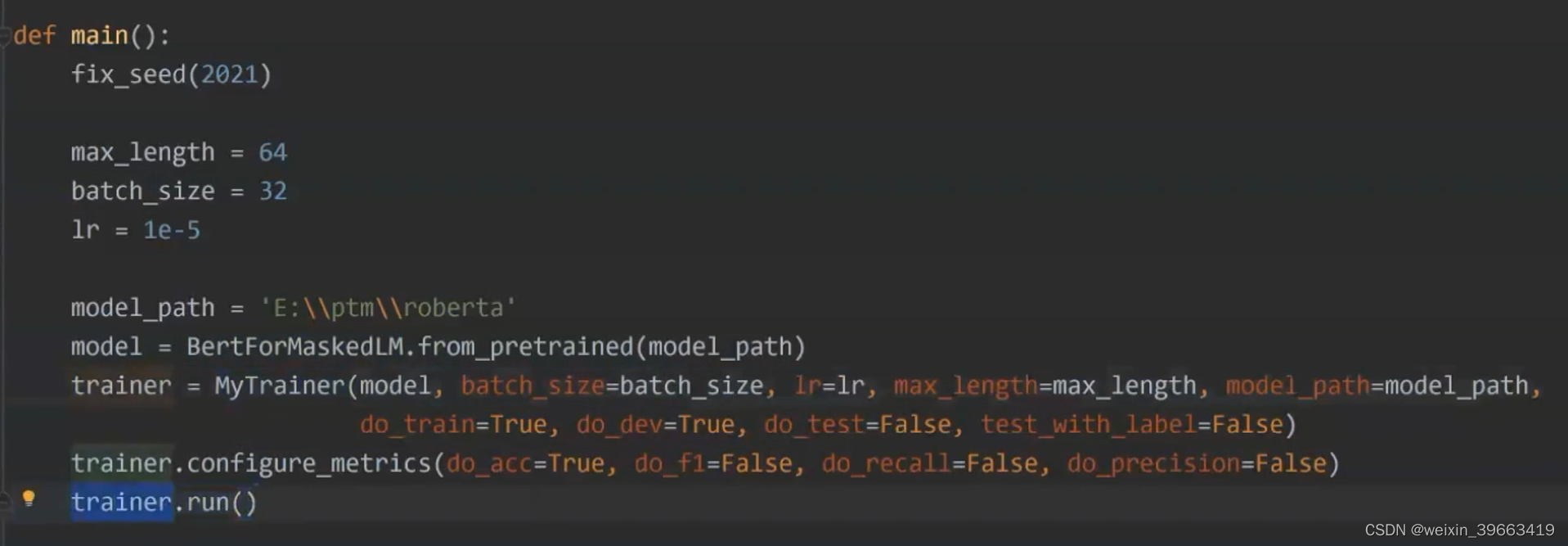
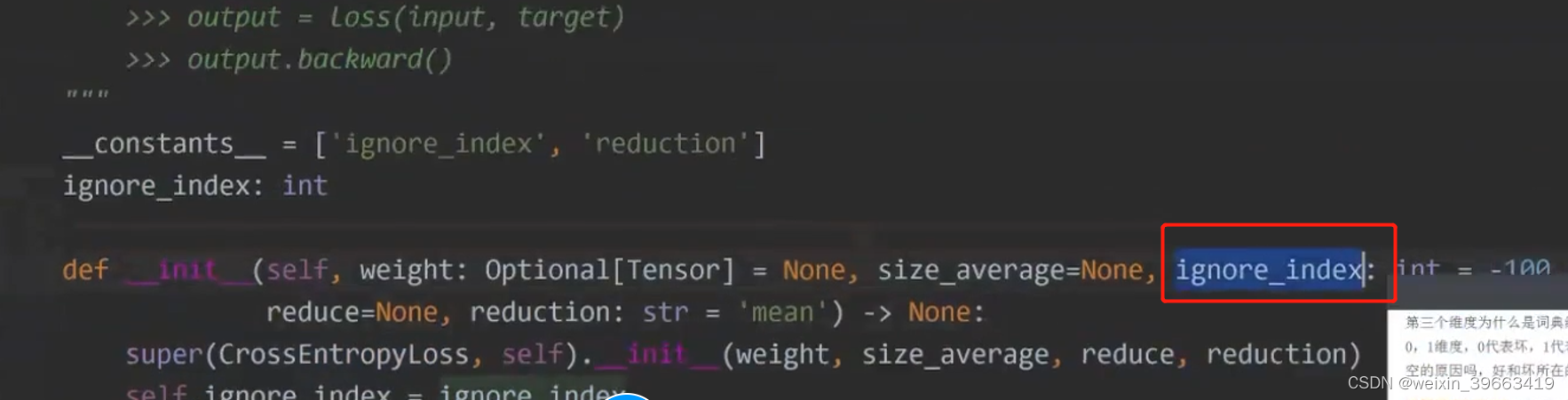
GPT3 基于transformer的encoder的模型。1600亿的参数。bert-base 一亿参数。 无法部署GPT3,但是可以借鉴思想。
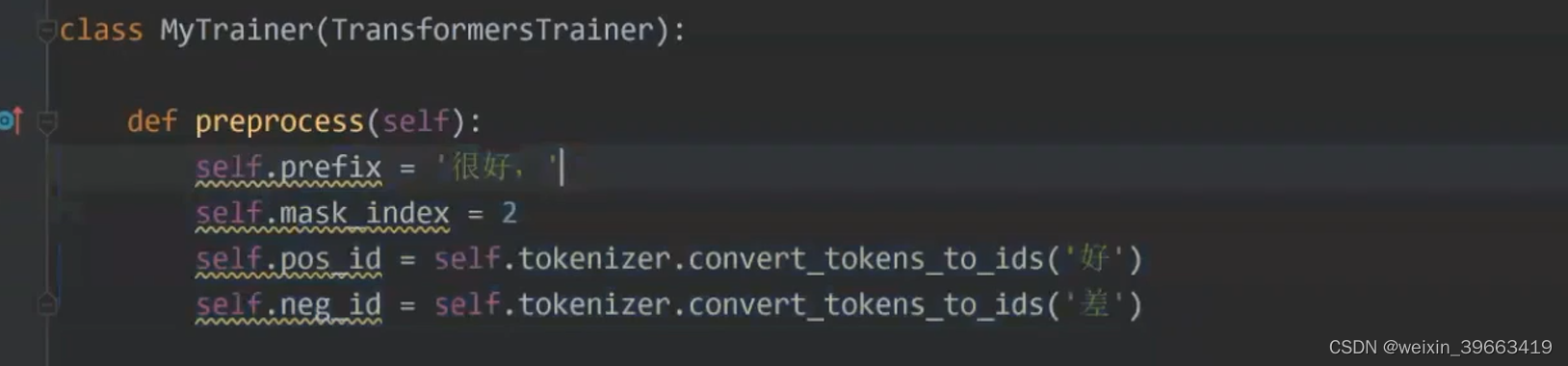
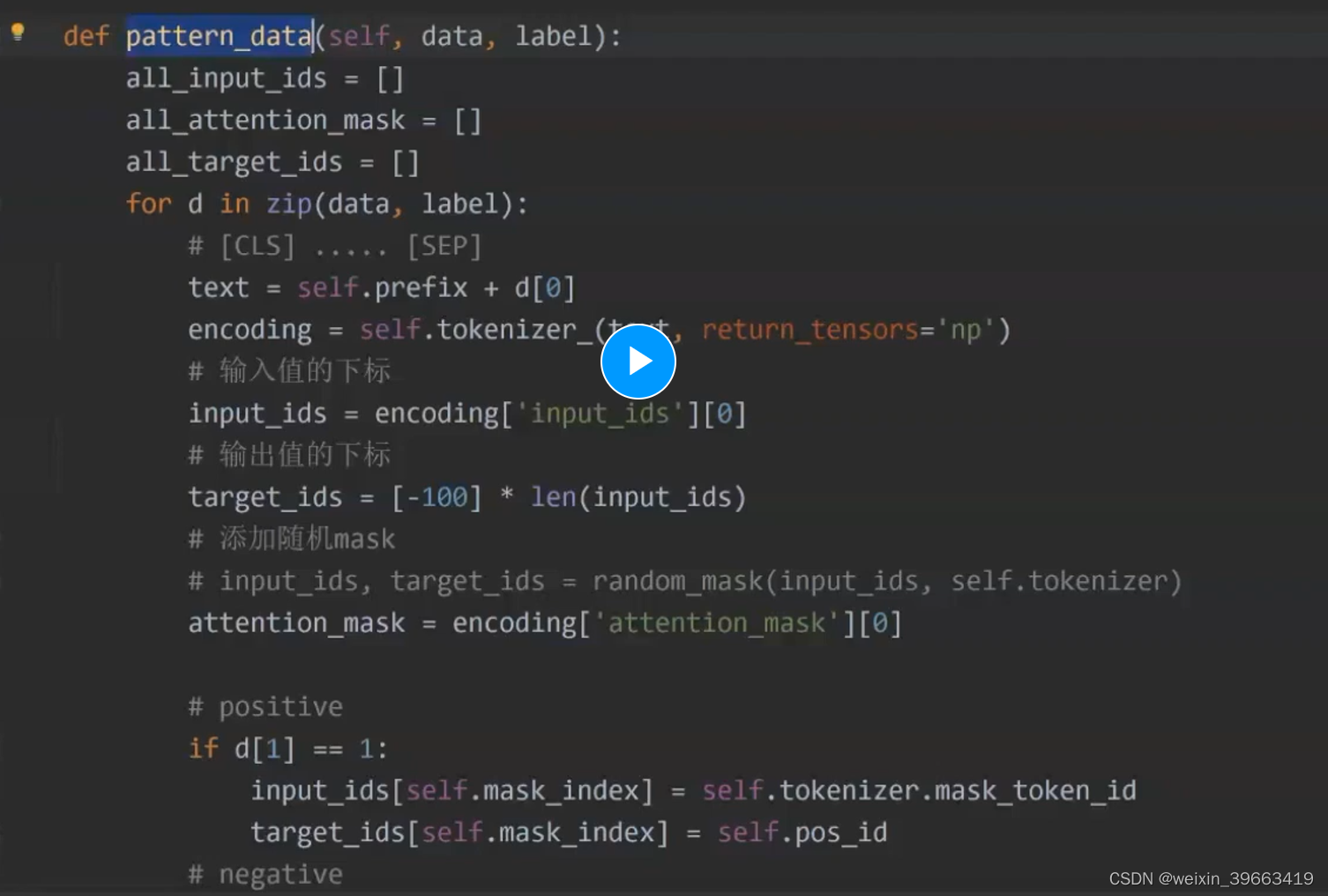
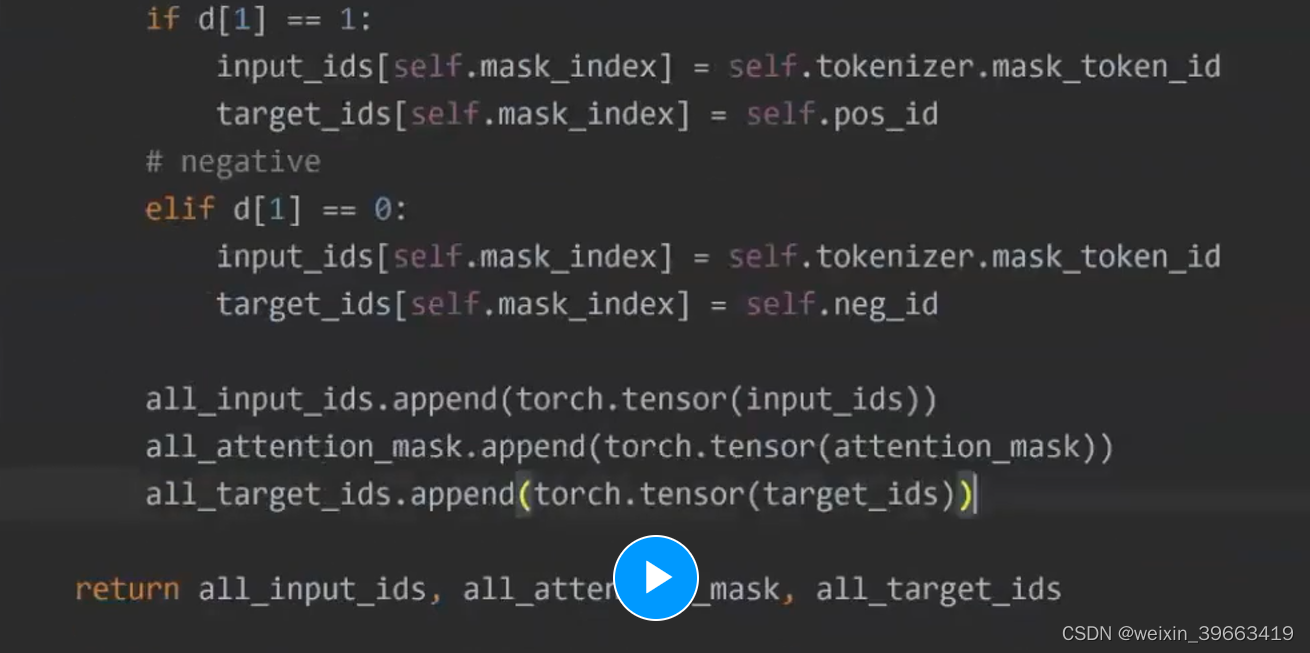
预训练的时候做的任务是MLM,那么我做预测任务的时候我仍然做MLM。 让P(sports | News:xxxxxx)概率值越大越好。 输入输出是这样的,完形填空。 prompt帮你节省很多人力成本
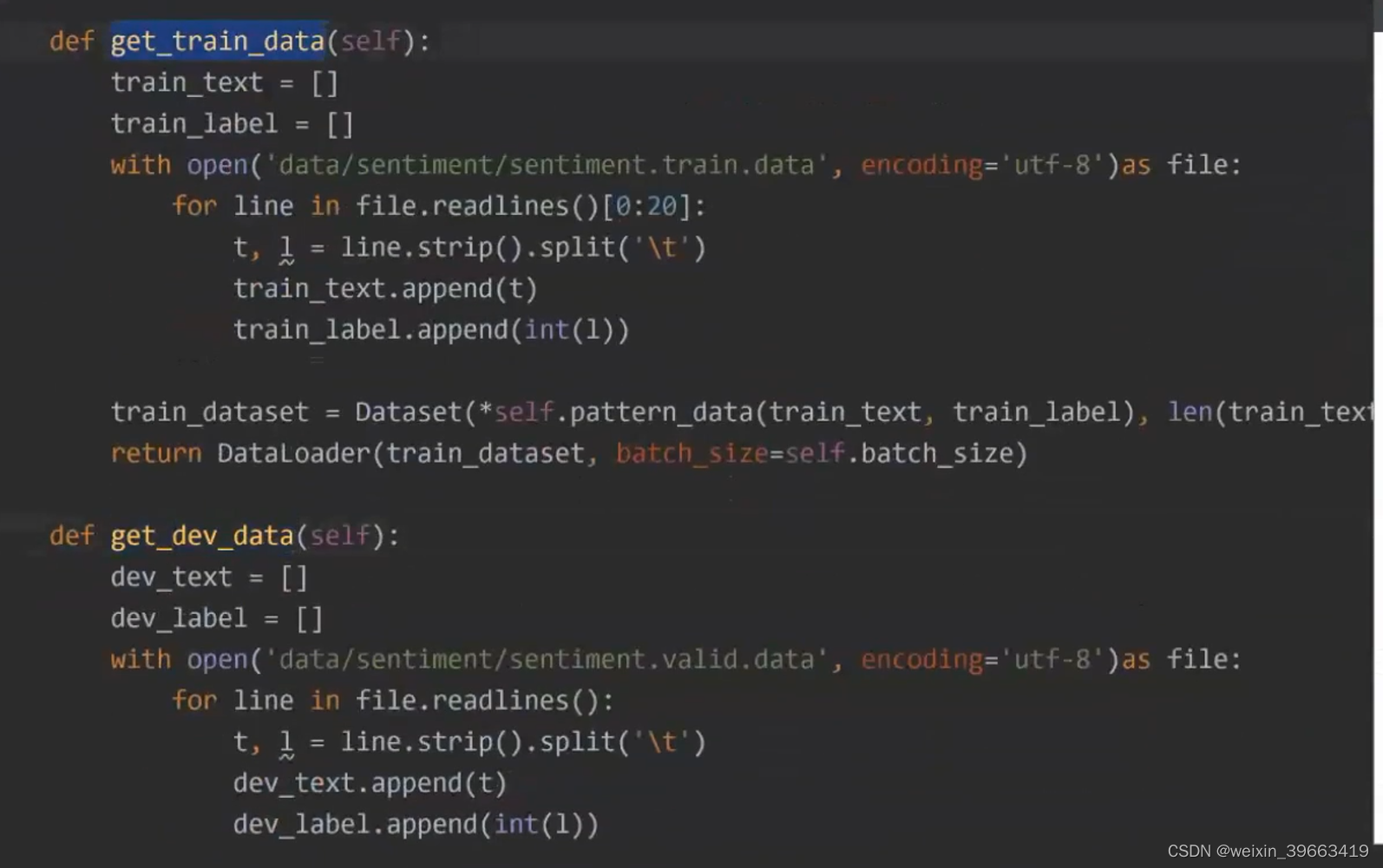
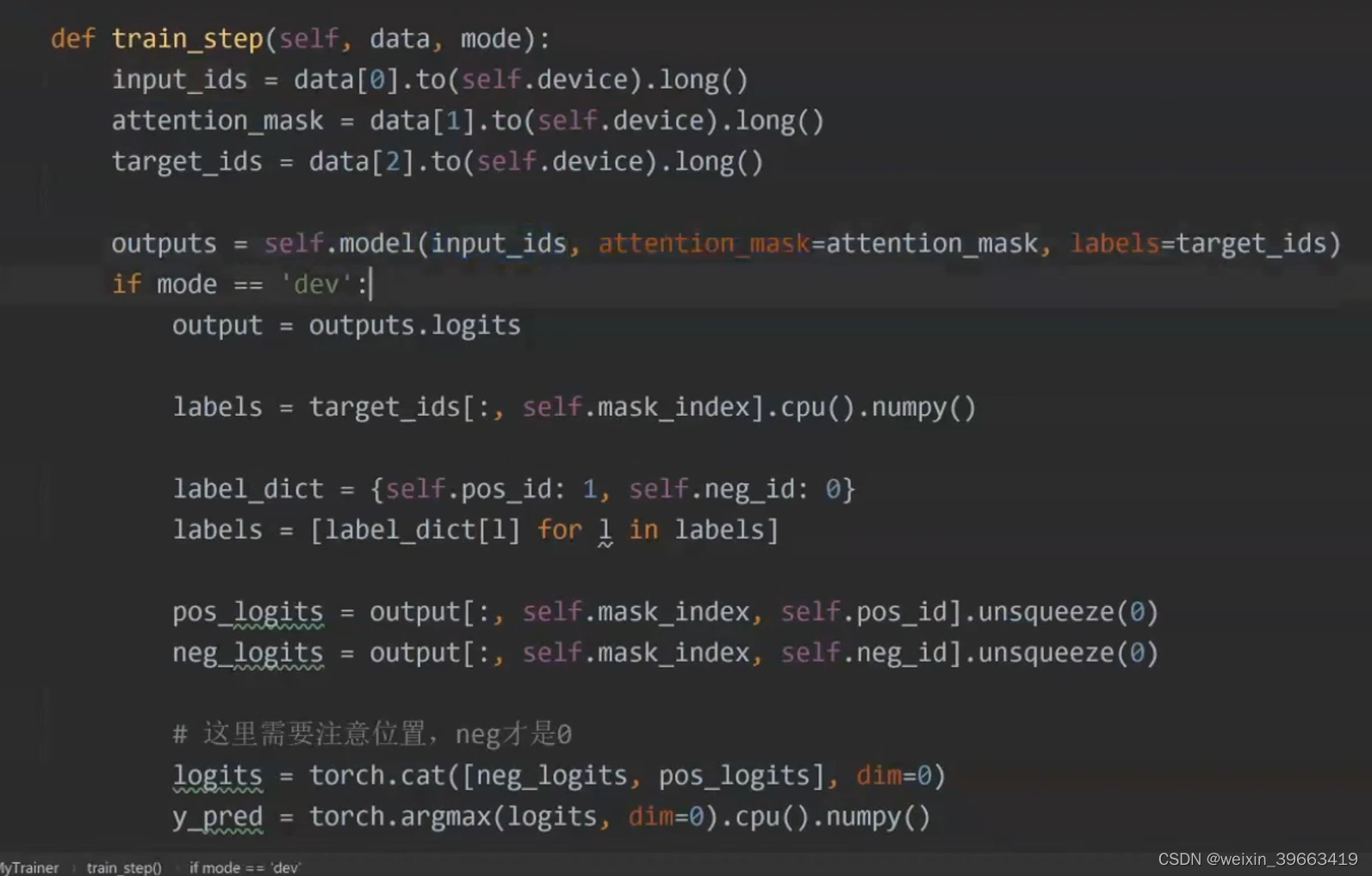
情感分类的例子 二分类 正类or负类 transformer这个库是预训练语言模型用的比较多的,比较成熟的库。


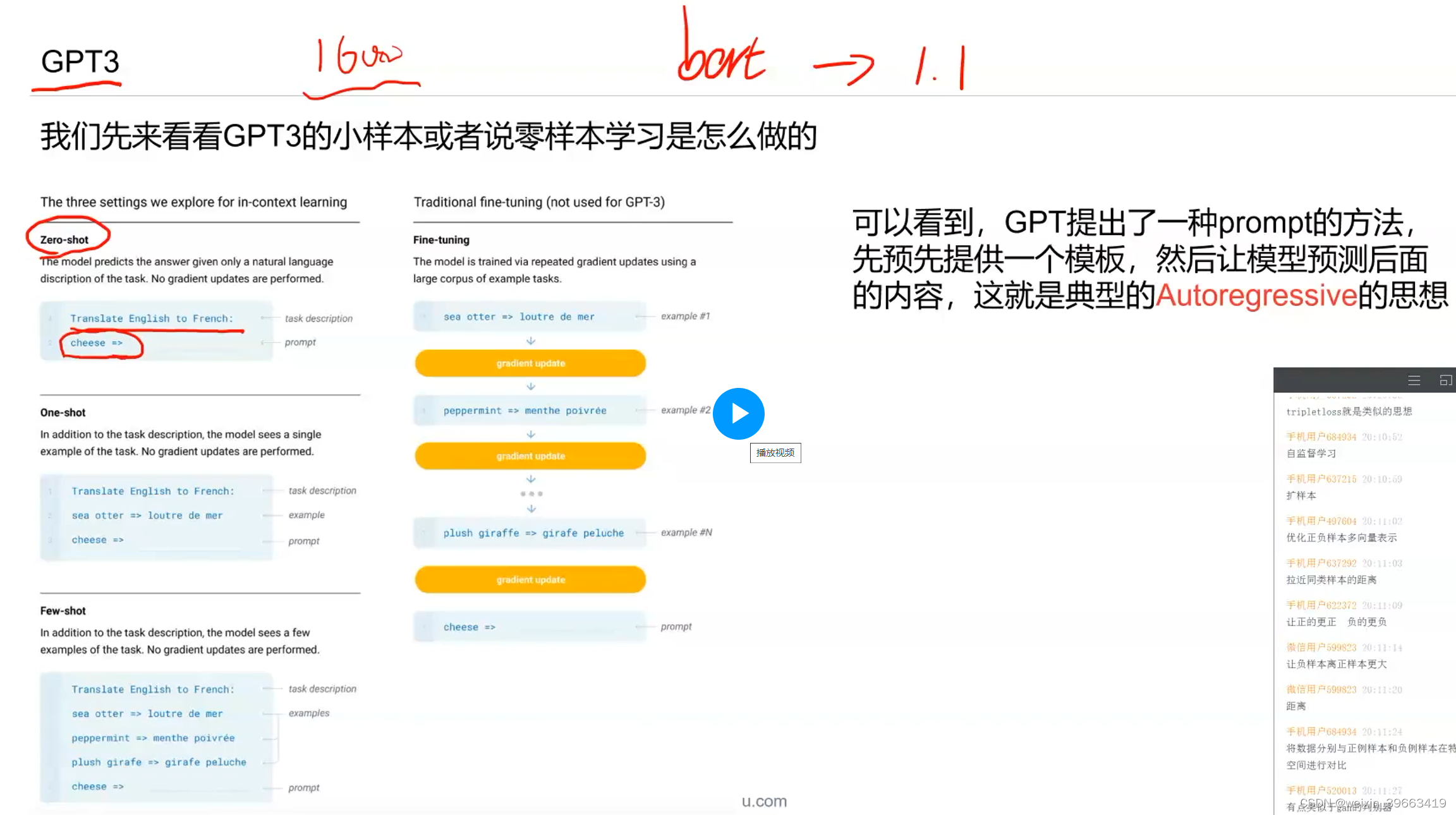

 预训练的时候做的任务是MLM,那么我做预测任务的时候我仍然做MLM。
预训练的时候做的任务是MLM,那么我做预测任务的时候我仍然做MLM。