以下均为自己对这些算法的理解:
fitst-fit算法
First-fit算法:连续物理内存分配算法的一种,将空闲内存块按照地址从小到大的方式连起来,具体实现时使用了双向链表的方式。当分配内存时,从链表头开始向后找,这意味着从低地址向高地址查找,一旦找到可以满足要求的内存块,即将该内存块分配出去即可。在此处为了避免内部碎片问题,具体实现时我们将该可用内存块分为两部分:前一部分大小与所需内存相同,这样我们只需要将前一部分分配出去,然后将后一部分继续插入到链表中即可。通过这个方式我们实现了一定程度上的任意大小分配,但是这个算法不可避免的产生了较多的外部碎片。同时,我认为该算法有一个缺陷,那就是会在低地址部分产生很多小碎片,这些碎片不但浪费内存,同时会导致每次从低地址向高地址查找时都要遍历一遍,会使得算法的性能大大下降,查找的开销会逐渐上升。
具体实现时的一些细节以及一些优化策略:
- 用双向链表存储可用内存块,这样的好处在于插入删除结点时较为容易
- 找到可用块后,如果可用块大小大于所需(通常情况下均为此情况),则将可用块分配前部分使得正好满足所需,而后半部分继续插入到可用块的链表中,可以避免内部碎片的产生,当然会产生外部碎片。
- 释放内存块时,需要查看要释放的内存块是否和相邻的块可以合并,如果可以合并,则将其合并为一个大块并放入可用内存块队列。判断较为容易,因为是按照地址排序的,所以只需要查看地址排列是否首位相接即可。
- 实际上,可以用二叉搜索树对该算法进行优化。通过二叉搜索树排序可用内存块,根据地址排序,通过保证二叉树的任意节点的左节点的地址值小于自身地址值,右节点的地址值大于自身地址值,通过此方法优化,我们可以实现O(n)的复杂度进行内存的分配,但是可以O(logn)的复杂度进行内存的释放。
best-fit和worst-fit算法
由于best-fit和worst-fit在实现上与first-fit较为相似,故先对二者进行介绍。
best-fit算法和worst-fit算法均为连续内存分配算法,仅在分配时选择块的依据上有差别。best-fit总是选择可以满足条件的最小的内存块,而worst-fit总是选择可以满足条件的最大块。实际上我们可以认为它们均为一种特殊的first-fit,best-fit实际上就是将可用内存块从小到大排序,将第一个可以用的内存块分配;而worst-fit实际上是将可用内存块从大到小排序,将第一个可用的内存块分配。不能被名字误导而认为best-fit就是优秀而worst-fit就是很差。二者主要使用环境不同,很容易认为best-fit上很优秀,但宏观上,在实际操作中会发现会产生很多难以利用的内部碎片(因为该算法几乎每次分配都会产生很小的难以利用的碎片)。而worst-fit更适合于中小作业较多的情况,如果大作业较多,则worst-fit性能很差。
具体实现时的一些想法:
- 可以用双向链表存储可用内存块。但对于best-fit来说链表项的顺序按照块的大小从到大排序,而worst-fit则将可用块按照从大到小排序。
- 对于这两种算法来说,由于是按照可用块的大小进行排序的,故当释放内存块时,必须对整个可用内存块链表进行一次完整的扫描以确定能否合并,故释放时效率较为低下。
- worst-fit并不是总是太糟糕的,它每次分配后,通常不会使得剩下的空闲块太小,这是非常优秀的方面。
buddy-system算法:
伙伴分配算法将总内存设为2的n次幂,并将内存按照2的n次幂的格式进行分发。
需要分配内存的时:核心就是分配出不小于所需的最小2次幂大小的内存(如果需要25,就分配32;如果需要63,就分配64),具体分配时,如果有符合的内存块,直接分配即可;如果当前的空闲块没有满足要求的,就将大块进行二等分,继续重复分配过程
需要释放内存时:首先将该内存块释放,然后看其相邻的块(可以进行合并的相邻块,即在分配时由一个内存块分成的两个等大内存块)是否释放,如果相邻块没有释放,则结束即可;如果相邻块释放,则将两个块合并,重复释放过程,对合并后的块进行释放。对相邻块做一个更容易实现的解释:相邻块不仅地址相邻,且二者中的低地址块的地址必须为2的整数幂。
引用一张清华大学学堂在线上的一张图,理解该图足以理解该算法:
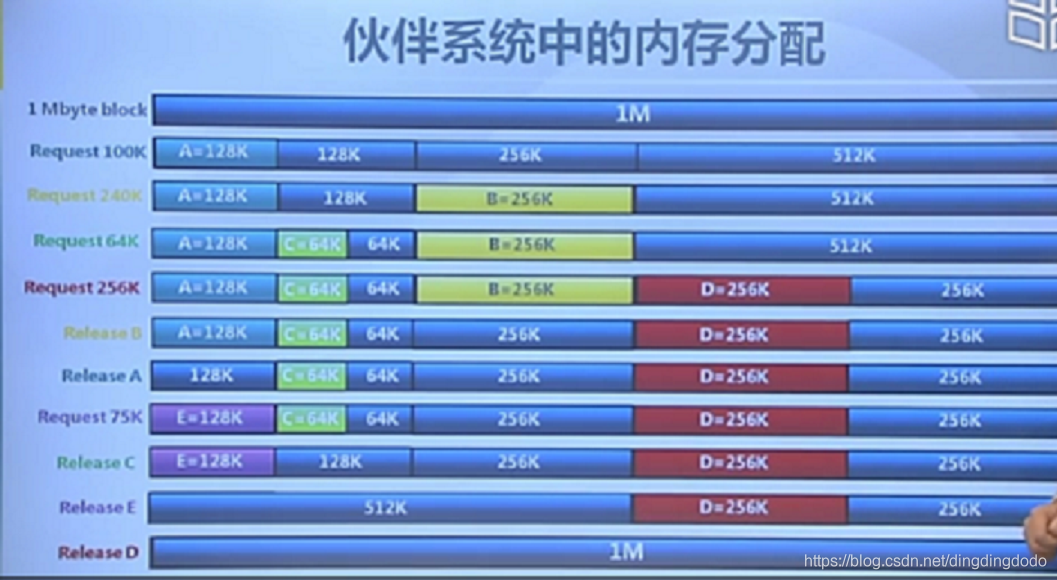
buddy-system算法的优缺点:其优点是快速搜索合并(O(logN)时间复杂度)以及低外部碎片(最佳适配best-fit);其缺点是内部碎片,因为按2的幂划分块,如果碰上65单位大小,那么必须划分128单位大小的块。实际上存储结点信息也会占用一小部分内存,但该算法总体上来看性能还是比较优越的。
主要问题就是内部碎片问题,这也是相较于之前三种内存分配算法所特有的(主要因为以上三种算法均可以在实现时通过一些技巧消除内部碎片问题)。
buddy-system具体实现时的一些细节和优化策略:
- 利用满二叉树的数据结构实现buddy system。分配器的整体思想是,通过一个数组形式的完全二叉树来监控管理内存,二叉树的节点用于标记相应内存块的使用状态,高层节点对应大的块,低层节点对应小的块,在分配和释放中我们就通过这些节点的标记属性来进行块的分离合并。需要强调的是,由于这里均为满二叉树,故仅需要通过数学关系即可找到子结点、父结点,因此用数组存储即可
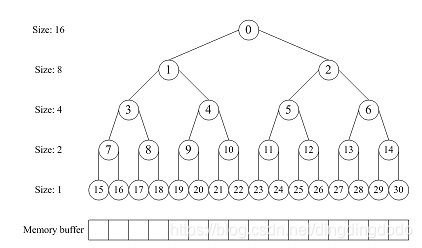
-
- 有效提高内存利用率的思想:由于实际物理内存通常不是2的倍数,故在此处我使用可用于分配的内存(虚拟的内存)可能会大于具体物理内存,但在存储节点信息时将多出的部分进行了标记,也就是将虚拟的内存对应的实际不存在的物理内存部分标为已用即可。也就意味着我们虚拟管理的部分内存可能是不存在的,但是通过将其标记为不可用即可。
- alloc过程为自上而下进行判定,找到最适合用于分配地空间,并对相关的结点信息进行刷新。free过程需要判断用递归判断是否两个节点可以合并,如果可以则合并后继续判断,并对相关结点信息进行刷新。
slab算法
slab以内存池为思想,解决内部碎片问题,专门解决小内存问题。提供一种可分配任意大小的内存分配机制。
slab分配器是基于对象进行管理,将相同类型的对象归为一类,每当要申请这样一个对象时,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片。slab分配器并不丢弃已经分配的对象,而是释放并把它们保存在内存中。slab分配对象时,会使用最近释放的对象的内存块,因此其驻留在cpu高速缓存中的概率会大大提高。
slab算法在buddy-system分配大内存的基础上,对小内存区域进行了有效的管理。可以解决内部碎片问题,提供一种可分配任意大小的内存分配机制,slab 分配器还支持通用对象的初始化,从而避免了为同一目的而对一个对象重复进行初始化。slab算法最大的缺点就是复杂,包括队列管理较为复杂、缓冲区管理较为复杂,以及实现起来非常复杂。
slab算法的框架: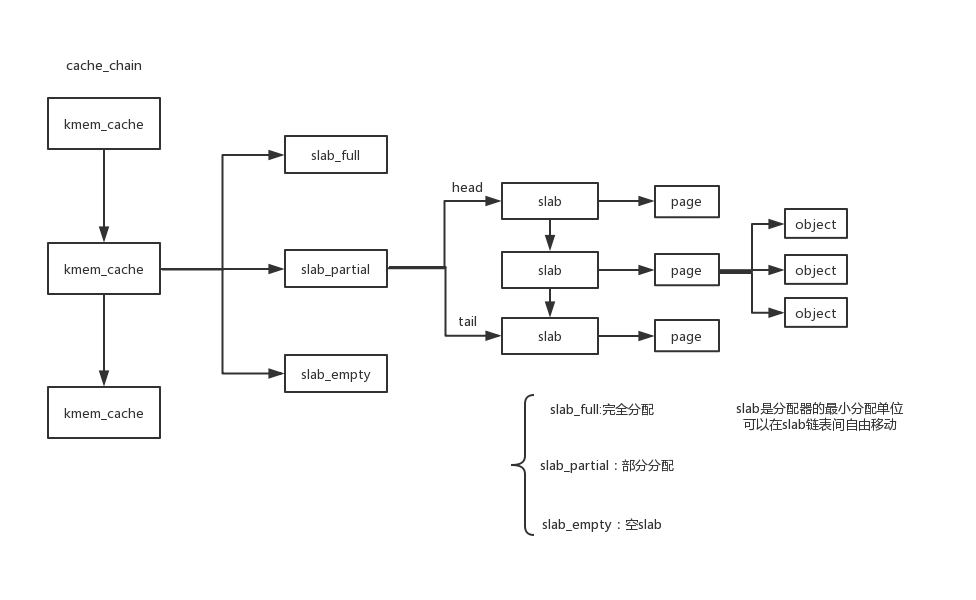
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)