原文首发于个人站点:基于变分自编码器重构概率的异常检测模型
个人公众号:「DreamHub」
文章链接:Variational Autoencoder based Anomaly Detection using Reconstruction Probability
源码链接: https://github.com/Michedev/VAE_anomaly_detection
论文总体结构
Abstract 提出了一种基于重构概率的异常检测方法可变自动编码器。
- Introduction
- Backgroud
2.1 Anomaly detection:介绍异常检常用几个方法。
2.2 Autoencoder and anomaly detection: 介绍自编码器(autoencoder) 如何进行异常检测。
2.3 Variational Autoencoder:介绍 VAE 的核心内容、VAE 与 AE 的区别 以及 VAE 训练算法。 - Proposed method
3.1 Algorithm: 总体介绍基于 VAE 模型的异常检测算法。
3.2 Reconstruction Probability:介绍上述算法中用的 reconstruction probability。
3.3 Difference from an autoencoder based anomaly detection: 介绍两种算法的区别。 - Experimental Results
实验部分用到了两个数据集 KDD cup 1999 与 MNIST,并与其他算法进行的比较。
1. Introduction
内容包括:
- 三两句介绍异常的定义、异常检测的意义。
- 从光谱异常检测技术中引出基于重构误差的检测方法,并指出基于 PCA 的方法属于这种方法。
- 从降维的角度引出自编码器(Autoencoder),并说明这样的好处:更好提取特征、更高的隐藏层能够获取一些抽象特征。
- 提出基于 VAE 的异常检测算法,并说明其优点:与自动编码器和PCA相比,VAE的优势在于它提供了一个概率度量,而不是作为异常分数的重建误差,我们称之为重建概率。概率比重建误差更具原则性和客观性,不需要模型特定的阈值来判断异常。
2 Background
2.1 Anomaly detection
异常检测方法总的分类:
- 统计异常检测假设数据是从指定的概率分布建模的。参数模型(如高斯混合模型)或非参数模型(如核密度估计)可用于定义概率分布。如果从模型中生成数据点的概率低于某个阈值,则将其定义为异常。这种模型的优点是给出了概率作为判断异常的决策规则,具有客观和理论上的合理性。
- 基于邻近度的异常检测假设异常数据与大多数数据隔离。用这种方法对异常进行建模有三种方法,即基于聚类的、基于密度的和基于距离的。对于基于聚类的异常检测,将聚类算法应用于数据,以识别数据中存在的密集区域或簇。对每一个异常点的关系进行评估,形成每一个异常点的关系。这些标准包括到星团质心的距离和最近的星团的大小。如果到簇质心的距离高于阈值或最近的簇的大小低于阈值,则数据点被定义为异常。基于密度的异常检测将异常定义为位于数据稀疏区域的数据点。例如,如果数据点的局部区域内的数据点数量低于阈值,则将其定义为异常。基于距离的异常检测使用与给定数据点的相邻数据点相关的测量。K近邻距离可用于这样一种情况,即具有较大K近邻距离的数据点被定义为异常。
- 基于偏差的异常检测主要基于光谱异常检测,以重建误差作为异常分数。第一步是使用降维方法(如主成分分析或自动编码器)重建数据。利用k-最显著主成分对输入进行重构,并测量其原始数据点与重构数据点的差值,从而产生重构误差,作为异常评分。将重建误差较大的数据点定义为异常。
2.2 Autoencoder and anomaly detection
-
Autoencoder 是通过无监督训练得到的网络,包括编码 (encoder) 和解码(decoder) 两部分。encoder 过程对应公式 (1) ,decoder 过程对应公式 (2),而公式 (3) 用于结算编码与解码过程对应原始数据造成的误差。称为重构误差(reconstruction error),训练的目的就是最小化重构误差。
h
=
σ
(
W
x
h
x
+
b
x
h
)
(
1
)
h = \sigma ( W_{xh} x + b_{x h}) ~~~~~~~ (1)
h=σ(Wxhx+bxh) (1)
z
=
σ
(
W
h
x
h
+
b
h
x
)
(
2
)
z = σ ( W_{h x} h + b_{h x} ) ~~~~~~~~ ( 2 )
z=σ(Whxh+bhx) (2)
∣
∣
x
−
z
∣
∣
(
3
)
∣∣x−z∣∣ ~~~~~~~~~ (3)
∣∣x−z∣∣ (3)
-
其中的
h
h
h 称为隐藏层,隐藏层的维度比输入层低,decoder 过程需要根据
h
h
h 重现输入数据
x
x
x 。这使得自动编码器对具有白噪声的数据具有鲁棒性,并且只捕获数据的有意义的模式。
自编码器的训练算法大致如下:

-
基于 AE 的异常检测是一种基于偏差的半监督学习算法,把重构误差 (reconstruction error) 作为异常值(anomaly score)。只把正常数据投入训练,完成训练后再对数据进行编码和解码操作,如果解码后数据与原始数据相近的数据是正常数据;当某数据的重构误差值高,我们认为是异常数据。
基于 AE 的异常检测算法如下:

2.3 Variational Autoencoder
VAE 模型参考 自编码器变形和变分自编码器理论介绍及其 PyTorch 实现
3 Proposed method
3.1 Algorithm

请务必结合上图理解下面的算法步骤:
- 使用正常数据进行训练,训练过程中 decoder 和 encoder 共同确定隐变量的参数(即多个正态分布的
σ
\sigma
σ 和
μ
\mu
μ)。
- 对于
N
N
N 个测试数据循环遍历,对于每个测试数据
x
i
x_i
xi 操作如下:
- 对于每个测试数据
x
i
x_i
xi,通过训练好的 VAE 模型得到
μ
z
(
i
)
\mu_z(i)
μz(i) 和
σ
(
i
)
\sigma(i)
σ(i)。
- 根据
μ
z
(
i
)
\mu_z(i)
μz(i) 和
σ
(
i
)
\sigma(i)
σ(i) 得到关于
z
z
z 的正态分布
N
(
μ
z
(
i
)
,
σ
z
(
i
)
)
N(\mu_z(i),\sigma_z(i))
N(μz(i),σz(i)),从中抽取样本
L
L
L。
- 对于抽取样本
L
L
L 中的每一个数据
z
(
i
,
l
)
z^{(i, l)}
z(i,l),关于
l
l
l 的循环:
- 进行 decode 操作,得到
x
^
\hat x
x^,这里可能是为了表示
μ
(
l
)
\mu (l)
μ(l)、
σ
(
l
)
\sigma(l)
σ(l) 与
x
^
(
i
)
\hat x(i)
x^(i) 的关系,记作
μ
x
^
(
i
,
l
)
\mu_{\hat x}{(i,l)}
μx^(i,l)和
σ
x
^
(
i
,
l
)
\sigma_{\hat x}{(i,l)}
σx^(i,l)
- 循环结束后得到多个
μ
x
^
(
i
,
l
)
\mu_{\hat x}{(i,l)}
μx^(i,l) 和
σ
x
^
(
i
,
l
)
\sigma_{\hat x}{(i,l)}
σx^(i,l). 其实就是多个
x
^
\hat x
x^;
- 通过多个
x
^
i
\hat x_i
x^i 与训练好的 VAE 模型生成原来的测试数据
x
i
x_i
xi,并计算重构概率(reconstruction probability)。这里计算的重构概率是对
E
q
φ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
E_{q_φ(z|x)}[log p_\theta(x|z)]
Eqφ(z∣x)[logpθ(x∣z)] 的 蒙特卡罗估计(Monte Carloe stimate),当数据的重构概率很低时被归类为异常。
- 重构概率(reconstruction probability) 由随机隐变量计算,这些隐变量可以输出原始输入变量分布的参数,而不是输入数据本身。从本质上讲,这是从后验分布中提取的确定的隐变量生成数据的概率。由于从隐变量分布中提取了大量样本,这使得重构概率能够考虑隐变量空间的可变性,这是该方法与基于自动编码器的异常检测方法的主要区别之一。可以使用适合数据的输入变量空间的其他分布。对于连续数据,正态分布可以用在算法4中。对于二进制数据,可以使用伯努利分布。在隐变量空间分布的情况下,一个简单的连续分布,如各向同性正态分布是首选。这可以通过谱异常检测的假设来证明,隐变量空间比输入变量空间简单得多。
3 Difference from an autoencoder based anomaly detection
VAE的重构概率与自动编码器的重构误差不同之处包括:
- 隐变量是随机变量。AE的隐变量由确定性映射定义,但 VAE 使用概率编码器来模拟隐变量的分布,而不是隐变量本身,因此可以从采样过程中考虑隐变量空间的可变性。VAE 相对 AE 而言扩展了表达能力,因为即使正常数据和异常数据可能共享相同的平均值,可变性也可能不同。据推测,异常数据的方差较大,重构概率较低。由于 AE 的确定性映射可以看作是到
δ
\delta
δ 分布平均值的映射,所以 AE 缺乏处理变化的能力。(通俗来说讲,AE 太实诚了,不懂得变通)
- 重构的是随机变量。重构概率不仅考虑了重构与原始输入的差异,而且考虑了分布函数的方差参数对重构结果的影响。这一特性使得对根据变量方差重构的选择性敏感。方差较大的变量可以容忍重构过程中与原始数据之间的较大差异,而方差较小的变量将显著降低重构概率。这也是 AE 由于其确定性映射关系缺少的特性。
- 重构是概率度量。基于 AE 的异常检测使用重构误差作为异常值,如果输入变量是异构的,则很难计算出异常值。为了总结异构数据的差异,需要加权求和。但没有一种通用的客观方法来确定合适的权重,因为权重会因数据而异。而且,即使在权值确定之后,确定重构误差的阈值也很麻烦。没有明确的客观门槛。相比之下,重构概率的计算不需要对异构数据的重建误差进行加权,因为每个变量的概率分布允许它们根据自身的可变性分别计算。对于任何数据,1% 的概率总是 1%。因此,与重构误差阈值的确定相比,重构误差阈值的确定更为客观、合理、易于理解。
参考源码
- PyTorch: https://github.com/cross32768/VAE_anomaly/blob/master/VAE.ipynb
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
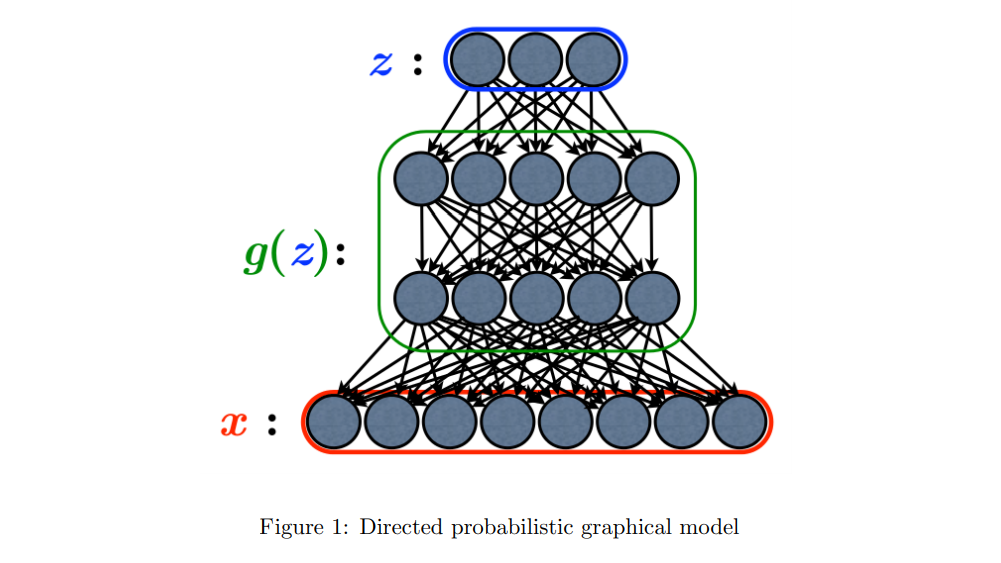 编码与解码过程如图二所示:
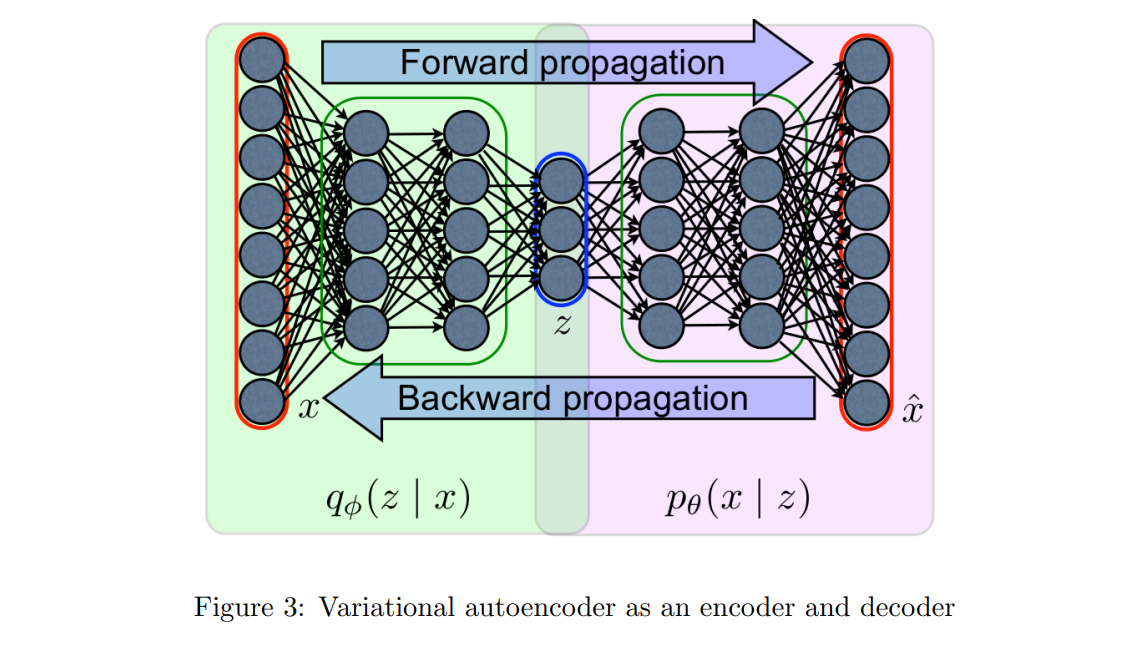
编码与解码过程如图二所示: 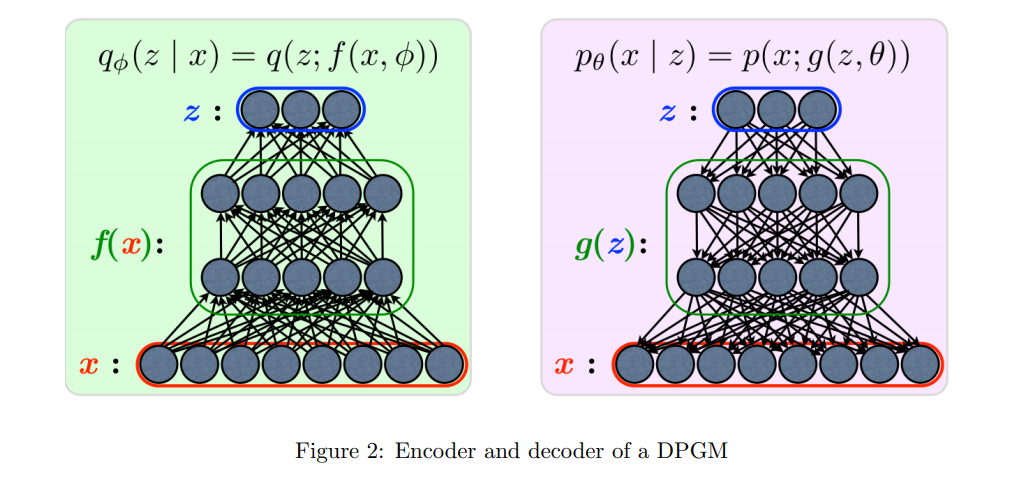 编码与解码过程分别交给两个神经网络完成,VAE 的整体结构如图三所示:
编码与解码过程分别交给两个神经网络完成,VAE 的整体结构如图三所示: