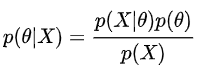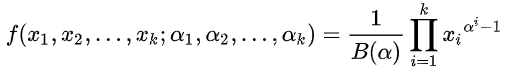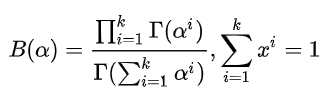在贝叶斯概率理论中,如果后验概率
P
(
θ
∣
x
)
P(θ|x)
P(θ∣x)和先验概率
p
(
θ
)
p(θ)
p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。狄利克雷(Dirichlet)分布是多项式分布的共轭分布。
5)LDA主题模型
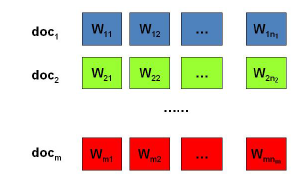
假设有
M
M
M篇文档,对应第d个文档中有有
N
d
N_d
Nd个词。
目标是找到每一篇文档的主题分布和每一个主题中词的分布。在LDA模型中,我们需要先假定一个主题数目
K
K
K,这样所有的分布就都基于
K
K
K个主题展开。
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档
d
d
d, 其主题分布
θ
d
\theta_d
θd为:
θ
d
=
D
i
r
i
c
h
l
e
t
(
α
⃗
)
\theta_d = Dirichlet(\vec \alpha)
θd=Dirichlet(α) 其中,
α
\alpha
α为分布的超参数,是一个
K
K
K维向量。
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题
k
k
k, 其词分布
β
k
\beta_k
βk为:
β
k
=
D
i
r
i
c
h
l
e
t
(
η
⃗
)
\beta_k=Dirichlet(\vec \eta)
βk=Dirichlet(η)
其中,
η
\eta
η为分布的超参数,是一个
V
V
V维向量。
V
V
V代表词汇表里所有词的个数。
对于数据中任一一篇文档
d
d
d中的第
n
n
n个词,我们可以从主题分布
θ
d
\theta_d
θd中得到它的主题编号
z
d
n
z_{dn}
zdn的分布为:
z
d
n
=
m
u
l
t
i
(
θ
d
)
z_{dn} = multi(\theta_d)
zdn=multi(θd)
而对于该主题编号,得到我们看到的词
w
d
n
w_{dn}
wdn的概率分布为:
w
d
n
=
m
u
l
t
i
(
β
z
d
n
)
w_{dn} = multi(\beta_{z_{dn}})
wdn=multi(βzdn) 理解LDA主题模型的主要任务就是理解上面的这个模型。这个模型里,我们有
M
M
M个文档主题的Dirichlet分布,而对应的数据有
M
M
M个主题编号的多项分布,这样(
α
→
θ
d
→
z
⃗
d
\alpha \to \theta_d \to \vec z_{d}
α→θd→zd)就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第d个文档中,第k个主题的词的个数为:
n
d
(
k
)
n_d^{(k)}
nd(k), 则对应的多项分布的计数可以表示为
n
⃗
d
=
(
n
d
(
1
)
,
n
d
(
2
)
,
.
.
.
n
d
(
K
)
)
\vec n_d = (n_d^{(1)}, n_d^{(2)},...n_d^{(K)})
nd=(nd(1),nd(2),...nd(K)) 利用Dirichlet-multi共轭,得到
θ
d
\theta_d
θd的后验分布为:
D
i
r
i
c
h
l
e
t
(
θ
d
∣
α
⃗
+
n
⃗
d
)
Dirichlet(\theta_d | \vec \alpha +\vec n_d)
Dirichlet(θd∣α+nd) 同样的道理,对于主题与词的分布,我们有
K
K
K个主题与词的Dirichlet分布,而对应的数据有
K
K
K个主题编号的多项分布,这样(
η
→
β
k
→
w
⃗
(
k
)
\eta \to \beta_k \to \vec w_{(k)}
η→βk→w(k))就组成了Dirichlet-multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。
如果在第k个主题中,第v个词的个数为:
n
k
(
v
)
n_k^{(v)}
nk(v), 则对应的多项分布的计数可以表示为
n
⃗
k
=
(
n
k
(
1
)
,
n
k
(
2
)
,
.
.
.
n
k
(
V
)
)
\vec n_k = (n_k^{(1)}, n_k^{(2)},...n_k^{(V)})
nk=(nk(1),nk(2),...nk(V)) 利用Dirichlet-multi共轭,得到
β
k
\beta_k
βk的后验分布为:
D
i
r
i
c
h
l
e
t
(
β
k
∣
η
⃗
+
n
⃗
k
)
Dirichlet(\beta_k | \vec \eta+\vec n_k)
Dirichlet(βk∣η+nk) 由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。
classParagraph:def__init__(self, txtname='', content='', sentences=[], words=''):
self.fromtxt = txtname
self.content = content
self.sentences = sentences
self.words = words
global punctuation
self.punctuation = punctuation
global stopwords
self.stopwords = stopwords
defsepSentences(self):
line =''
sentences =[]for w in self.content:if w in self.punctuation and line !='\n':if line.strip()!='':
sentences.append(line.strip())
line =''elif w notin self.punctuation:
line += w
self.sentences = sentences
defsepWords(self):
words =[]
dete_stopwords =1if dete_stopwords:for i inrange(len(self.sentences)):
words.extend([x for x in jieba.cut(
self.sentences[i])if x notin self.stopwords])else:for i inrange(len(self.sentences)):
words.extend([x for x in jieba.cut(self.sentences[i])])
reswords =' '.join(words)
self.words = reswords
X = docres
y =[data_list[i].fromtxt for i inrange(len(data_list))]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
svm_model = LinearSVC()# model = SVC()
svm_model.fit(X_train, y_train)
y_pred = svm_model.predict(X_test)
6.输出结果
输出:测试集真值与分类估计对比,输出每个主题主要词10个,绘制SVM三维三分类图片结果。
# show test resultprint('Topic real:','\t','Topic predict:','\n')for i inrange(len(y_test)):print(y_test[i],'\t', y_pred[i],'\n')# show LDA result
feature_names = cntVector.get_feature_names()
print_top_words(lda, feature_names,10)# show SVM result
draw_svm_result(X, y, svm_model)
运行结果
1.笑傲江湖/神雕侠侣/ 射雕英雄传
结果评估:
P
r
e
c
i
s
i
o
n
:
0.962
Precision:0.962
Precision:0.962