由于Linux是一个多任务操作系统,能够支持远大于CPU数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是由CPU进行调度,将时间分片,每个任务占用1个时间片,通过轮流的方式运行,但由于时间片粒度非常小,而CPU速度非常高,造成多任务同时运行的错觉。实际上,对于单个CPU核,其处理数据是串行的,就比如做核酸检测,只有一个检测口,组织人员会在检测口排几个队列,每个队列头部数出10个人构成一组。检测口就相当于CPU,无论怎么排队,所有人都得经过检测口,它的工作量一点没有变。但是各队列中的10人小组是轮换的,这样稍微增加一些效率(减少了数10个人的时间),保证了公平性(每个队列都是等同的,大家随便排到哪个队列里),如果检测速度非常快,那么单个队列里的各10个人小组可能并不觉得有另外几个队列的存在。对于多队列多CPU核的情况就复杂了,这里不讨论了。
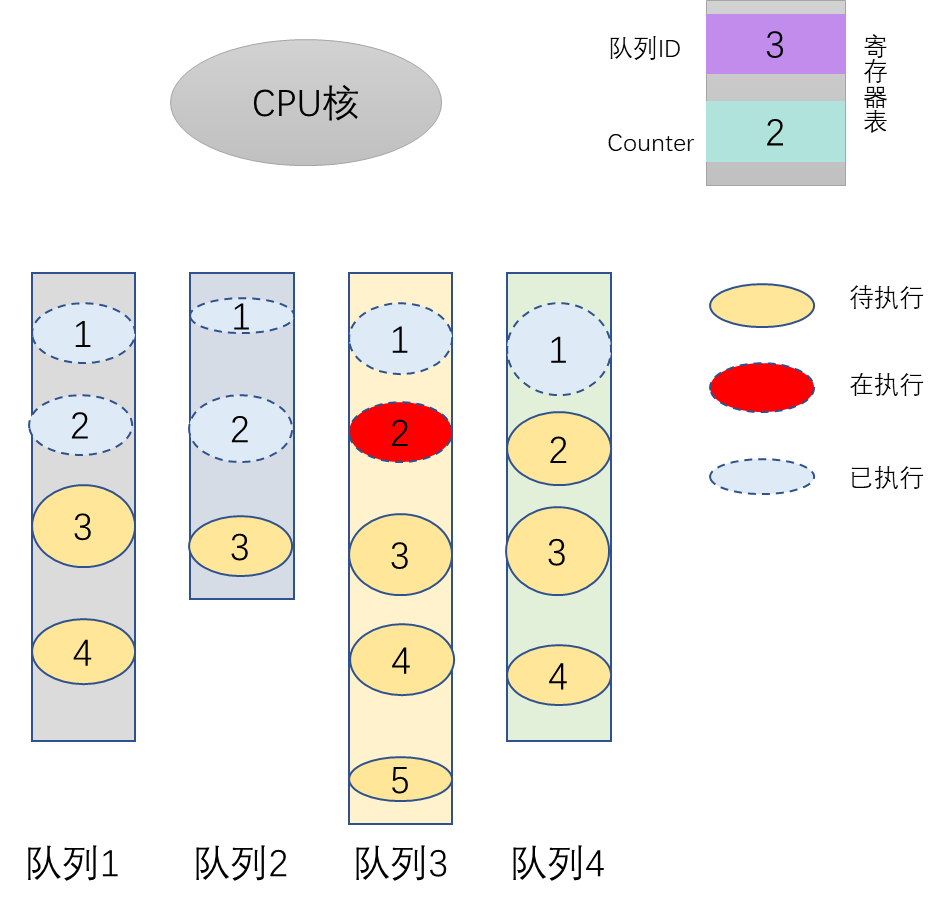
在每个任务(进程、线程、中断)运行前,CPU都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU寄存器和程序计数器。以核酸检测为例,每个队列都有一个编号,从1-N;每个队列里的人都有一个号码,从1到K,但每个人胖瘦不同、检测耗时不同;核酸检测的时候,组织人员得知道下一次到了那个队列的哪个人员(这里假设做完核酸的人员还回到队列里)。如果组织人员不维护队列号码和队列内部的人员编号,那么整个过程将会混乱不堪。而组织人员做的事情就是给CPU的各寄存器装订正确的参数。这里面,队列就相当于任务,人员就相当于指令。
什么是CPU上下文
CPU寄存器和程序计数器(也是一个寄存器)就是CPU上下文,因为它们都是CPU在运行任何任务前,必须的依赖环境。也就是上面的队列ID和人员编号。
- CPU寄存器是CPU内置的容量小、但速度极快的内存。
- 程序计数器则是用来存储CPU正在执行的指令位置、或者即将执行的下一条指令位置。
什么是CPU上下文切换
就是先把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务的过程。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
CPU上下文切换的类型
根据任务的不同,可以分为以下三种类型:
进程上下文切换
Linux按照特权等级,把进程的运行空间分为内核空间和用户空间,CPU特权等级的Ring0和Ring3。
- 内核空间(Ring0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
系统调用
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用open()打开文件,然后调用read()读取文件内容,并调用write()将内容写到标准输出,最后再调用close()关闭文件。
在这个系统调用的执行过程中就发生了CPU上下文切换,整个过程是这样的:
- 保存CPU寄存器里原来用户态的指令位置(这部分代码是用户写的,通俗地讲就是下一个要执行的用户代码行号);
- 为了执行内核态代码,(这部分代码不是用户写的,而是linux内核中的代码)CPU寄存器需要更新为内核态指令的新位置(内核代码的行号?);
- 跳转到内核态运行内核任务;
- 当系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。
所以,一次系统调用的过程,其实是发生了两次CPU上下文切换。(用户态-内核态-用户态)
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:进程上下文切换,是指从一个进程切换到另一个进程运行;而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。系统调用属于同进程内的CPU上下文切换。但实际上,系统调用过程中,CPU的上下文切换还是无法避免的。
发生进程上下文切换的场景
为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
进程上下文切换
进程上下文切换可以描述为kernel执行下面的操作:
- 挂起一个进程,并储存该进程当时寄存器和程序计数器的状态;
- 从内存中恢复下一个要执行的进程,恢复该进程原来的状态到寄存器,返回到其上次暂停的执行代码然后继续执行。
进程上下文切换只能发生在内核态,所以还会触发用户态与内核态切换。

上图中,我个人觉得右边的两次上下文切换中间没有写清楚。应该是A进程的用户模式--A进程的内核模式--B进程的内核模式--B进程的用户模式--B进程的内核模式--A进程的内核模式--A进程的用户模式。
所谓进程上下文切换应该是指的是从A进程的用户态切换到B进程的用户态的过程,这中间需要内核来帮忙。内核相当于沟通所有进程的桥梁,每个进程都有一个门可以穿越到这个桥上,想从一个进程跳到另外一个进程,都得先走到桥上,然后找到另外一个进程的门,这就完成了内核态的转移,然后穿出这个门,就到了另外一个进程的用户态。这个是我个人理解,不一定对。
进程上下文切换跟系统调用又有什么区别呢
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存内核态资源(当前进程的内核状态和CPU寄存器)之前,需要先把该进程的用户态资源(虚拟内存、栈等)保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。总的来说就是进程的切换涉及到进程的内核栈和用户栈的保存与恢复,这比单个进程内部的系统调用造成的用户栈和内核栈复杂。这主要是因为时间片是定长的,A进程即时是在内核态运行,时间一到,也得切到别的进程。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在CPU上运行才能完成。

进程上下文切换潜在的性能问题
根据Tsuna的测试报告,每次上下文切换都需要几十纳秒到数微秒的CPU时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致CPU将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是导致平均负载升高的一个重要因素。
另外,我们知道,Linux通过TLB(TranslationLookasideBuffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
线程上下文切换
线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
所以,对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
发生线程上下文切换的场景
前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
中断上下文
什么是中断机制?
中断机制是现代计算机系统中的基本机制之一,它在系统中起着通信网络的作用,以协调系统对各种外部事件的响应和处理,中断是实现多道程序设计的必要条件,中断是CPU 对系统发生的某个事件作出的一种反应。
- 引起中断的事件称为中断源。
- 中断源向CPU 提出处理的请求称为中断请求。
- 发生中断时被打断程序的暂停点称为断点。
- CPU暂停现行程序而转为响应中断请求的过程称为中断响应。
- 处理中断源的程序称为中断处理程序。
- CPU执行有关的中断处理程序称为中断处理。
- 返回断点的过程称为中断返回。
- 中断的实现由软件和硬件综合完成,硬件部分叫做硬件装置,软件部分称为软件处理程序。
- 中断机制包括硬件的中断装置和操作系统的中断处理服务程序。
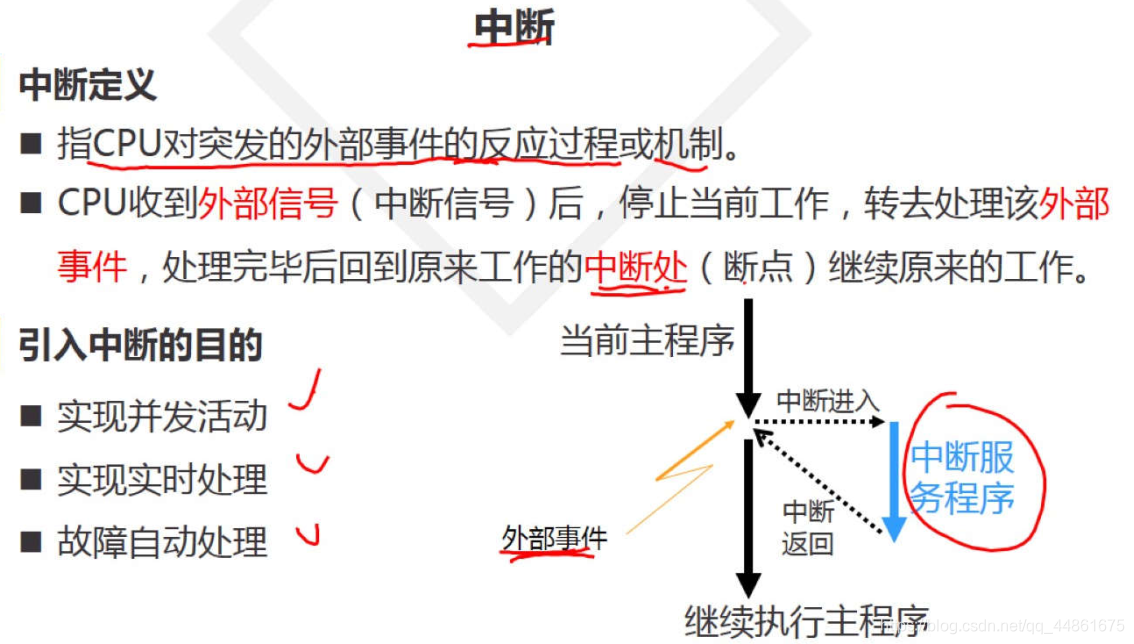
中断的一个例子
在你敲打键盘的时候,键盘控制器(控制键盘的硬件设备)会发送一个中断,通知操作系统有键按下。中断本质是一种特殊的电信号,由硬件设备发向处理器。处理器接受到中断后,会马上向操作系统反映此信号的到来,然后就由os负责处理这些新到来的数据。硬件设备生成中断的时候并不考虑与处理器的时钟同步——换句话说就是中断随时可以产生。因此,内核随时可能因为新到来的中断而被打断。



虽然人们在谈到中断(Interrupt)时,总会拿轮询(Polling)来做“反面”例子,但中断和轮询并不是完全对立的两个概念,它们是对立统一的。
“CPU执行完每条指令时,都会去检查一个中断标志位”,这句话是所有关于中断长篇大论的开场白,但很容易被人忽略,其实,这就是中断的本质。
举个例子,CPU老板是一家公司的光杆司令,所有的顾客都要他亲自跑去处理,还要跟有关部门打点关系,CPU觉得顾客和公关这两样事它一个人搞不来,这就是轮询;终于这家公司升级发展了,CPU老板请了一个秘书,所有的顾客都先由秘书经手,CPU心情好的时候就去看一下,大部分时间都忙着去公关了,这时它觉得轻松了很多,这就是中断了~~
也就是说,中断和轮询是从CPU老板的角度来看的,不管怎样,事件都还是有人来时刻跟踪才能被捕获处理,不过是老板还是秘书的问题。所有的中断(或者异步,回调等)背后都有一个轮询(循环,listener)。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
总结一下,不管是哪种场景导致的上下文切换,你都应该知道:
CPU 上下文切换是保证 Linux 系统正常工作的核心功能之一,一般情况下我们无需特别关注。- 过多的上下文切换,会把
CPU 时间消耗在寄存器、内核栈、虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
如何查看系统的上下文切换
我们可以通过 vmstat 工具来查看系统的上下文切换情况。vmstat 主要用来分析系统内存使用情况,也常用来分析 CPU 上下文切换和中断的次数。
# 每隔 5 秒输出 1 组数据
$ vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st
1 0 246028 1651576 110600 1045176 0 3 31 30 117 189 2 2 96 0 0
0 0 246028 1631976 110608 1047904 10 0 42 5 1642 1619 1 3 96 0 0
0 0 246028 1630000 110616 1050440 0 0 0 158 707 563 0 1 99 0 0
0 0 246028 1627632 110624 1052808 0 0 0 3102 748 711 0 1 99 0 0
我们需要重点关注下列内容:
- cs(context switch) 是每秒上下文切换的次数。
- in(interrupt) 是每秒中断的次数,次数过高说明中断也可能是潜在问题。
- r(Running or Runnable) 是就绪队列的长度,也就是正在运行和等待 CPU 的进程数,如果远大于 CPU 个数,就会有大量的 CPU 竞争
- b(Blocked) 是处于不可中断睡眠状态的进程数。
- us 和 sys 列:这两列加一起是系统CPU占用率,sys 列是内核使用CPU情况。
- id列:CPU空闲率。id列的值和us、sys加到一起是100.
想要查看每个进程的详细情况,需要使用 pidstat,给它加上 -w 选项,就可以查看每个进程上下文切换的情况。(sudo apt install sysstat 安装pidstat工具)
# 每隔 5 秒输出 1 组数据
$ pidstat -w 5
Linux 5.13.0-40-generic (u20) 2022年05月20日 _x86_64_ (4 CPU)
11时13分30秒 UID PID cswch/s nvcswch/s Command
11时13分35秒 0 1 0.20 0.00 systemd
11时13分35秒 0 12 0.20 0.00 ksoftirqd/0
11时13分35秒 0 13 15.14 0.00 rcu_sched
11时13分35秒 0 14 0.20 0.00 migration/0
11时13分35秒 0 19 0.20 0.00 migration/1
11时13分35秒 0 21 10.56 0.20 kworker/1:0-events
11时13分35秒 0 25 0.20 0.00 migration/2
11时13分35秒 0 31 0.20 0.00 migration/3
11时13分35秒 0 39 6.77 0.00 kworker/0:2-events
11时13分35秒 0 45 1.99 0.00 kcompactd0
11时13分35秒 0 51 5.98 0.00 kworker/2:1-events_freezable
11时13分35秒 0 105 0.20 0.00 kworker/2:1H-kblockd
11时13分35秒 0 146 4.98 0.00 kworker/3:2-events
11时13分35秒 0 151 2.19 0.00 kworker/u256:3-events_power_efficient
11时13分35秒 0 197 0.40 0.00 kworker/1:1H-kblockd
11时13分35秒 0 309 0.40 0.00 kworker/u256:28-events_power_efficient
11时13分35秒 0 319 0.20 0.00 kworker/0:1H-kblockd
11时13分35秒 0 348 0.60 0.20 jbd2/sda6-8
上述结果有两列是我们重点关注的对象,一个是 cswch,表示每秒自愿上下文切换的次数;另一个是 nvcswch,表示每秒非自愿上下文切换的次数。
- 自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如,IO、内存等系统资源不足时,就会发生自愿上下文切换。
- 非资源上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在抢占 CPU 时,就容易发生非自愿上下文切换。
如果由于系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。我们可以使用 pidstat 继续分析到底是哪个进程导致了这些问题!(下述内容是在只有2核cpu的虚拟机上执行的)
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
# -w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标
$ pidstat -w -u 1
08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command
08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench
08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2
08:06:33 UID PID cswch/s nvcswch/s Command
08:06:34 0 8 11.00 0.00 rcu_sched
08:06:34 0 16 1.00 0.00 ksoftirqd/1
08:06:34 0 471 1.00 0.00 hv_balloon
08:06:34 0 1230 1.00 0.00 iscsid
08:06:34 0 4089 1.00 0.00 kworker/1:5
08:06:34 0 4333 1.00 0.00 kworker/0:3
08:06:34 0 10499 1.00 224.00 pidstat
08:06:34 0 26326 236.00 0.00 kworker/u4:2
08:06:34 1000 26784 223.00 0.00 sshd
可以发现,CPU 使用率的升高是 sysbench 导致的,但上下文切换则来自其他进程,包括非自愿上下文切换频率最高的 pidstat,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd。
默认 pidstat 显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
# 每隔 1 秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出线程的上下文切换指标
$ pidstat -wt 1
08:14:05 UID TGID TID cswch/s nvcswch/s Command
...
08:14:05 0 10551 - 6.00 0.00 sysbench
08:14:05 0 - 10551 6.00 0.00 |__sysbench
08:14:05 0 - 10552 18911.00 103740.00 |__sysbench
08:14:05 0 - 10553 18915.00 100955.00 |__sysbench
08:14:05 0 - 10554 18827.00 103954.00 |__sysbench
...
虽然 sysbench 进程的上下文切换次数不多,但它的子线程的上下文切换次数非常多,可以判定上下文切换罪魁祸首的是 sysbench 进程。还没完,记得我们通过 vmstat 看到的中断次数到了 1 万,到底是什么类型的中断上升了呢?
我们可以通过 /proc/interrupts 来读取中断的使用情况,通过运行下面的命令:
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interrupts
CPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
可以发现,变化速度最快的是重调度中断(RES),表示唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务队列到不同 CPU 的机制,通常也被称为处理器间中断。根本原因还是因为过多任务的调度问题,跟前边分析结果是一致的。
每秒上下文切换多少次算正常
这个数值其实取决于系统本身的 CPU 性能。如果系统的上下文切换次数比较稳定,从数百到一万以内,都应该算是正常的。如果当上下文切换次数超过一万次,或者切换次数出现数量级增长时,很可能已经出现了性能问题。
这时,你还需要根据上下文切换的类型,再做具体分析,比方说:
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了
IO 等其他问题 - 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢
CPU,说明 CPU 的确成了瓶颈。 - 中断次数变多了,说明
CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
另外,本版内容被我改了好几次,主要是里面有不少内容还没有说清楚,我也一直在查资料。比如进程上下文切换为什么必须在内核空间发生?我会再写一篇解释这些问题。实际上上下文切换的内容还是很多的,光靠一两篇文档也解释不全。
参考链接:
https://blog.csdn.net/qq_44861675/article/details/107736922
深入理解Linux的CPU上下文切换 - 云+社区 - 腾讯云
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)