关于PnP(pespective-n-point)的一些方法
最小PnP问题
P3P问题中假设没有噪声,使用几何约束,可以解得相机的位姿。不具有唯一解。
P4P问题中分为线性方法和基于P3P的方法。
最小二乘的观点
- 迭代最小化一个代价函数(平方误差)。这些方法相对于之前的方法更加准确,在一定的噪声的情况下,返回一个最大似然估计。
- 直接最小二乘方法DLS
常用方法
- NPL: The N-Point Linear (NPL) method of Ansar and Daniilidis [1].
- EPnP: The approach of Lepitit et al. [16].
- SDP: The Semi Definite Program (SDP) approach of Schweighofer and Pinz [23].
- DLS: The Direct Least-Squares (DLS) solution presented in this paper. An open source implementation of DLS is available at www.umn.edu/ ̃joel
- DLS-LM: Maximum-likelihood estimate, computed using iterative Levenberg-Marquardt (LM) minimization of the sum of the squared reprojection errors, initialized with DLS.
1 solvePnP里有三种解法:P3P, EPnP,迭代法(默认)(opencv3里多了DLS和UPnP解法)
OpenCV提供了三种方法进行PNP计算,三种方法具体怎么计算的就请各位自己查询opencv documentation以及相关的论文了,我看了个大概然后结合自己实际的测试情况给出一个结论,不一定正确,仅供参考:
| 方法名 | 说明 | 测试结论 |
| CV_P3P | 这个方法使用非常经典的Gao方法解P3P问题,求出4组可能的解,再通过对第四个点的重投影,返回重投影误差最小的点。 论文《Complete Solution Classification for the Perspective-Three-Point Problem》 | 可以使用任意4个特征点求解,不要共面,特征点数量不为4时报错 |
| CV_ITERATIVE | 该方法基于Levenberg-Marquardt optimization迭代求解PNP问题,实质是迭代求出重投影误差最小的解,这个解显然不一定是正解。 实测该方法只有用4个共面的特征点时才能求出正确的解,使用5个特征点或4点非共面的特征点都得不到正确的位姿。 | 只能用4个共面的特征点来解位姿 |
| CV_EPNP | 该方法使用EfficientPNP方法求解问题,具体怎么做的当时网速不好我没下载到论文,后面又懒得去看了。 论文《EPnP: Efficient Perspective-n-Point Camera Pose Estimation》 | 对于N个特征点,只要N>3就能够求出正解。 |
注意点1:solvePnP里有三种解法:P3P, EPnP,迭代法(默认);opencv2里参数分别为CV_P3P,CV_EPNP,CV_ITERATIVE (opencv3里多了DLS和UPnP解法)。
注意点2:solvePnP需要至少3组点:P3P只使用4组点,3组求出多个解,第四组确定最优解;EPnP使用大于等于3组点;迭代法调用cvFindExtrinsicCameraParams2,进而使用SVD分解并调用cvFindHomography,而cvFindHomography需要至少4组点。
2方法简说
solvePnP里有三种解法:P3P, EPnP,迭代法(默认);opencv2里参数分别为CV_P3P,CV_EPNP,CV_ITERATIVE (opencv3里多了DLS和UPnP解法)。
注意点2:solvePnP需要至少3组点:P3P只使用4组点,3组求出多个解,第四组确定最优解;EPnP使用大于等于3组点;迭代法调用cvFindExtrinsicCameraParams2,进而使用SVD分解并调用cvFindHomography,而cvFindHomography需要至少4组点。
具体过程如下
- 将空间点和图像点齐次化,得到图像点矩阵
m
空间点矩阵
M
,求取矩阵M的平均值
Mc
,
- 计算另外一个矩阵
mm=(M−Mc)T(M−Mc)
- 对空间点矩阵
mm
进行SVD分解,
mm=UWV
-
Rt=V
-
Tt=−McRt
-
Mxy=VtMT+Tt
- find homography between (
m
和
Mxy
)得到矩阵
H
-
H=[h1,h2,t]
,然后归一化
-
h1=h1∥h1∥
-
t=t∥h1∥+∥h2∥
-
h3=h1×h2
-
H:=[h1,h2,h3]
- 最终结果
Rf=H∗Rt
-
tf=H∗Tt+t
其他
R的第i行 表示摄像机坐标系中的第i个坐标轴方向的单位向量在世界坐标系里的坐标;
R的第i列 表示世界坐标系中的第i个坐标轴方向的单位向量在摄像机坐标系里的坐标;
t 表示世界坐标系的原点在摄像机坐标系的坐标;
-R的转置 * t 表示摄像机坐标系的原点在世界坐标系的坐标。(原理如下图,t表示平移,T表示转置)

DLS
- http://onlinelibrary.wiley.com/doi/10.1002/rob.21620/epdf
- http://www.voidcn.com/blog/abc20002929/article/p-2288889.html
- http://blog.csdn.net/aptx704610875/article/details/48915149
- https://github.com/gaoxiang12/rgbd-slam-tutor2/blob/master/src/pnp.cpp
转载
POSIT算法的原理--opencv 3D姿态估计
3D姿态估计-POSIT算法
POSIT算法,Pose from Orthography and Scaling with Iterations, 比例正交投影迭代变换算法:
用于估计物体的3D姿态(相对于镜头的平移和旋转量)。算法正常工作的前提是物体在Z轴方向的“厚度”远小于其在Z轴方向的平均深度,比如距离镜头10米远的一张椅子。
算法流程:
假设待求的姿态,包括旋转矩阵R和平移向量T,分别为
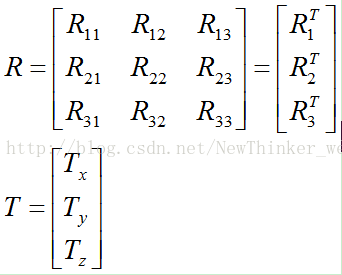
透视投影变换为:

上式中的f是摄像机的焦距,它的具体值并不重要,重要的是f与x和y之间的比例,根据摄像头内参数矩阵的fx和fy可以得到这个比例。实际的运算中可直接令f=1,但是相应的x和y也要按照比例设定。比如,对于内参数为[fx,fy,u0,v0]的摄像头,如果一个像素的位置是(u,v),则对应的x和y应为
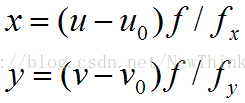
设世界坐标系中的一点为(Xw,Yw,Zw),则

有必要再解释一下旋转矩阵R和平移向量T的具体意义:
R的第i行表示摄像机坐标系中的第i个坐标轴方向的单位向量在世界坐标系里的坐标;
R的第i列表示世界坐标系中的第i个坐标轴方向的单位向量在摄像机坐标系里的坐标;
T正好是世界坐标系的原点在摄像机坐标系的坐标,特别的,Tz就代表世界坐标系的原点在摄像机坐标系里的“深度”。
根据前面的假设,物体在Z轴方向的‘厚度’,即物体表面各点在摄像机坐标系中的Z坐标变化范围,远小于该物体在Z轴方向的平均深度。一定要注意,“厚度”和“深度”都是相对于摄像机坐标系的Z轴而言的。当世界坐标系的原点在物体的中心附近时可以认为平均深度就是平移向量T中的Tz分量,即各点的Zc的平均值是Tz,而Zc的变化范围相对于Tz又很小,因此可以认为,Zc始终在Tz附近,Zc≈Tz。
根据这个近似关系,可得
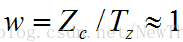
这就是我们的迭代初值。在这种初始状态下,我们假设了物体的所有点在同一个深度上,这时的透视变换就退化为了一个比例正交投影POS。也就是,我们的迭代开始于一个比例正交投影,这也是POSIT算法名字的由来。
我们前面得到了:
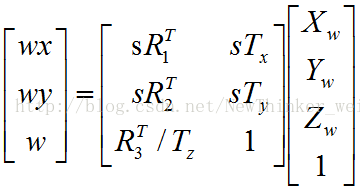
由于我们给了w一个估计值,因此可以先将其看做已知量,删掉第三行(这样方程中就少了4个未知量,更方便求解),得到
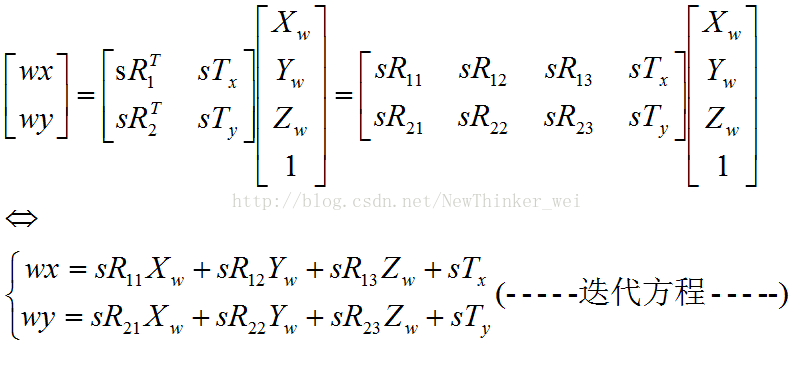
由于w被看做已知,因此上面的迭代方程可以看做有8个未知量,分别是

给定一对坐标后(一个是世界坐标系的坐标,一个是图像坐标系的坐标,它们对应同一个点),我们就可以得到2个独立的方程,一共需要8个独立方程,因此至少需要给定4对坐标,而且对应的这4个点在世界坐标系中不能共面。为什么不能共面?如果第4个点与前三个点共面,那么该点的“齐次坐标”就可以被其他三个点的“齐次坐标”线性表示,而迭代方程的右侧使用的就是齐次坐标,这样由第四个点得到的方程就不是独立方程了。这里之所以强调“齐次坐标”是因为,只要三个点不共线,所有其他点(即使不共面)的“常规坐标”都可以被这三个点的“常规坐标”线性表示,但“齐次坐标”则要求共面。
OK,假如我们获得了4个不共面的点及其坐标,并通过迭代方程求出了8个未知量。这时我们就可以算出向量sR1和sR2的模长。而由于R1和R2本身都是单位向量,即模长为1。因此我们可以求出s,进而求得R1和R2以及Tz=f/s:

有了R1和R2就可以求出R3,后者为前两个向量的叉积(两两垂直的单位向量)。
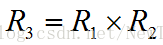
至此,整个旋转矩阵R和平移向量T,共12个未知量,就都求出来了。不过,这只是近似值,因为我们一开始时假设了w=1(或Zc=Tz),即物体上所有的点的深度都是Tz。现在我们有了一个近似的转换矩阵,可以利用它为各点计算一个新的深度,这个深度比Tz更准确。新的深度Zc和新的迭代系数w等于:
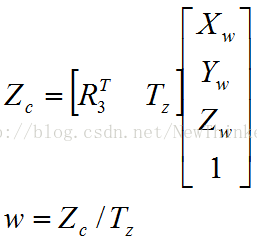
这时,由于每个点的有不同的深度,他们也就有了不同的迭代系数w。接着,将每个点的新w值代入迭代方程中,重新得到8个方程。由于这一次每个点的w(表征了深度信息)都比上一次迭代时更准确,因此会得到更精确的转换矩阵,而更精确的转换矩阵反过来又能让我们求得各点更精确的深度信息和w。如此往复循环反馈,就可逐步逼近精确解。
openCV里用cvPOSIT()函数实现POSIT迭代,具体的函数用法网上有很多介绍不再重复了。顺带提一下openCV里的另两个函数solvePNP()和cvFindExtrinsicCameraParams2(),这两个函数功能与POSIT类似,也是在已知一组点对应的图像坐标和世界坐标以及摄像头内参数的情况下计算物体的3D姿态,不过与POSIT不同的是,它们不是求近似解,而是直接求精确解。既然可以直接求精确解了,那POSIT估计算法还有什么意义呢?
其实理论上,只要获得3个点的信息,就可以得出旋转矩阵R和平移向量T了:
R和T共有12个未知量,每个点的坐标代入前面的“---原始方程--”中,消去w,可得到2个独立的方程,3个点就可以得到6个线性方程,再加上R自身的正交矩阵特征(每行、每列都是单位向量,模长为1)又可以得到6个独立的方程(非线性),共12个方程。
但实际中,解非线性方程很麻烦,所以openCV中应该是用了其他的优化方法。最无奈地,我们可以找6个点,每个点用“---原始方程--”消去w得到2个线性方程,最终也能得到12个方程,不过由于这种方法的求解过程中直接无视了正交矩阵R本身的特征,最后得到的结果会由于点坐标的测量误差和计算误差而稍微违反R自身的正交矩阵约束,当然这可以通过迭代弥补,但会增加算法的复杂度。可能有人会疑惑,同样是从3行的“---原始方程--”转化成2行的方程,为什么POSIT方法只需要四个点就可以求解,而这里却需要6个点?要知道,这里只是利用线性关系消去了w,但保留了原来第三行中的未知量,因此未知量的数量保持12不变;而POSIT方法中,直接为w选取了一个估计值,并删去了“---原始方程--”的第3行,这样方程中才少了4个未知量只剩下8个,所以利用4个点的坐标才得以求解。
于是,我们大概就能猜到既然有精确求解的算法却还要保留POSIT估计算法的原因了:如果只有少数点的信息(比如4个),又不想求解非线性方程,那就该POSIT上了。
转载
Pose estimation algorithm 之 Robust Planar Pose (RPP)algorithm
The RPP algorithm gives a more stable tracking (less jitter) than ARToolKit's pose estimation algorithm.
The robust pose estimator algorithm has been provided by G. Schweighofer and A. Pinz (Inst.of l.Measurement and Measurement Signal Processing, Graz University of Technology). Details about the algorithm are given in a Technical Report: TR-EMT-2005-01, available here. Thanks go to Thomas Pintaric for implementing the C++ version of this algorithm.
计算机视觉
1. 内参数标定
2. 外参数标定即姿态估计问题。从一组2D点的映射中估计物体的3D姿态。
3. 从三个对应点中恢复姿态,需要的信息是最少的,称为“三点透视问题”即P3P。同理,扩展到N个点,就称为“PnP”。
4. 基于视觉的姿态估计根据使用的摄像机数目分为单目视觉和多目视觉。根据算法又可以分为基于模型的姿态估计和基于学习的姿态估计。
5. OpenCV中有solvePnP以及solvePnPRansac用来实现已知平面四点坐标确定摄像头相对世界坐标系的平移和旋转。cvPOSIT基于正交投影,用仿射投影模型近似透视投影模型,不断迭代计算出估计值。此算法在物体深度相对于物体到相机的距离比较大的时候,算法可能不收敛。
6. 从世界坐标系到相机坐标系的转换,需要矩阵[R|t],其中R是旋转矩阵,t是位移向量。如果世界坐标系为X,相机坐标系对应坐标为X‘,那么X' = [R|t]*X。从相机坐标系到理想屏幕坐标系的变换就需要内参数矩阵C。那么理想屏幕坐标系L = C*[R|t]*X。如何获得[R|t],大致是已知模板上的几个关键点在世界坐标系的坐标即X已知,然后在摄像头捕获的帧里获得模板上对应点在屏幕坐标系的坐标即L已知,通过求解线性方程组得到[R|t]的初值,再利用非线性最小二乘法迭代求得最优变换矩阵[R|t]。
7. 大多数情况下,背景是二维平面,识别的物体也是二维平面。对于ARToolkit,识别的Targets就是平面的(但是这种方法鲁棒性不好)。如果内参数矩阵是已知的,那么知道4个或者更多共面不共线的点就可以计算出相机的姿态。
8. 相机姿态估计的问题就是寻找相机的外参数,即是最小化误差函数的问题。误差函数有的基于image-space,有的基于object-space。
9. RPP算法基于object-space为误差函数提供了一种可视化的方法。误差函数有两个局部极小值。在无噪声条件下,第一个局部极小值跟正确的姿态对应。另外的误差函数的极小值就是标准姿态估计算法为什么会抖动的原因。由于姿态估计算法最小化误差函数总是要使用迭代算法,因此需要一个初值。如果初值接近第二个局部极小值,那么迭代算法就收敛到错误的结果。
10. 估计第一个姿态,RPP算法使用任何已知的姿态估计算法,在这里里,使用迭代算法。从第一个姿态使用P3P算法估计第二个姿态。这个姿态跟误差函数的第二个局部极小值接近。使用估算的第二个姿态作为初值,使用迭代算法获得第二个姿态。最终正确的姿态是有最小误差的那个。
11. 这类问题最终都是解线性方程组AX=b的问题。当b∈R(A)时,x=A的广义逆*b;当b∈不R(A)时,能否是Ax接近b呢,即是否有x使||Ax-b||最小,习惯上用2-范数即欧式范数来度量。最小二乘解常存在,然后这样的解未必是唯一的。当在方程无解的情况下,要找到最优解。就是要最小化所有误差的平方和,要找拥有最小平方和的解,即最小二乘。最小化就是把误差向量的长度最小化。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)