最近笔者在做GPU显存资源分配的研究,发现在tf中gpu一些实用的方法和接口,共享出来,供大家参考学习,如有问题,欢迎留言讨论。
1.运行程序时,控制台设置GPU运行参数,占用显存全部资源
$ CUDA_VISIBLE_DEVICES=0 python predict.py # 只使用gpu:0设备运行predict.py程序。

$ CUDA_VISIBLE_DEVICES=1 python predict.py # 只使用gpu:1设备运行predict.py程序。
$ CUDA_VISIBLE_DEVICES=0,1 python predict.py # 只使用gpu:0,1设备运行predict.py程序。
【PS】2017/8/23
注意: CUDA_VISIBLE_DEVICES=0,1 是存在设备的优先级的,[0,1]和[1,0]排列的设备是不同的,排在前面的设备优先级高,运行程序的时候会优先使用。如[0,1]则先使用0号设备的gpu资源,[1,0]则先试用1号设备的gpu资源
以上三个指令运行predict.py程序,都会占用GPU显存的全部资源。
2.在tensorflow代码中with tf.device(‘/gpu:x’)
在tensorflow代码中with tf.device(‘/gpu:0’)
在tensorflow代码中with tf.device(‘/gpu:1’)
在tensorflow代码中with tf.device(‘/gpu:0,1’)
上面三种设定效果与1中控制台输入CUDA_VISIABLE_DEVICES=x 的效果相同,运行程序,都会占用全部资源
3.在程序中,设置GPU设备的环境变量
os.environ[“CUDA_DEVICE_ORDER”] = “PCI_BUS_ID” # 按照PCI_BUS_ID顺序从0开始排列GPU设备
os.environ[“CUDA_VISIBLE_DEVICES”] = “0” #设置当前使用的GPU设备仅为0号设备
os.environ[“CUDA_VISIBLE_DEVICES”] = “1” #设置当前使用的GPU设备仅为1号设备
os.environ[“CUDA_VISIBLE_DEVICES”] = “0,1” #设置当前使用的GPU设备为0,1号两个设备
设定的效果与1和2相同。
4.session初始化时设定GPU_Config
gpuConfig = tf.ConfigProto()
gpuConfig.allow_soft_placement = config.getboolean(‘gpu’, ‘allow_soft_placement’)#设置为True,当GPU不存在或者程序中出现GPU不能运行的代码时,自动切换到CPU运行
【PS】2017/8/24
GPU切换CPU的条件
1.运算无法在GPU上执行
2.没有GPU资源(指定GPU device num 错误)
3.运算输入包含对CPU计算结果的引用
gpuConfig.gpu_options.allow_growth = config.getboolean(‘gpu’, ‘allow_growth’)#设置为True,程序运行时,会根据程序所需GPU显存情况,分配最小的资源
gpuConfig.gpu_options.per_process_gpu_memory_fraction = config.getfloat(‘gpu’, ‘rate’)#程序运行的时,所需的GPU显存资源最大不允许超过rate的设定值
【PS】当allow_growth和per_process_gpu_memory_fraction 同时设定的时候,两者为或的关系
GPU_config = utils.GPU_config()
sess = tf.Session(config=GPU_config) #设定一个自定义GPU配置的session
【PS】上面的自定义GPU_config只会指定GPU内存分配情况,而不会选定GPU具体的device_id,而如何指定GPU device_id还是要使用1,2,3指出的方法
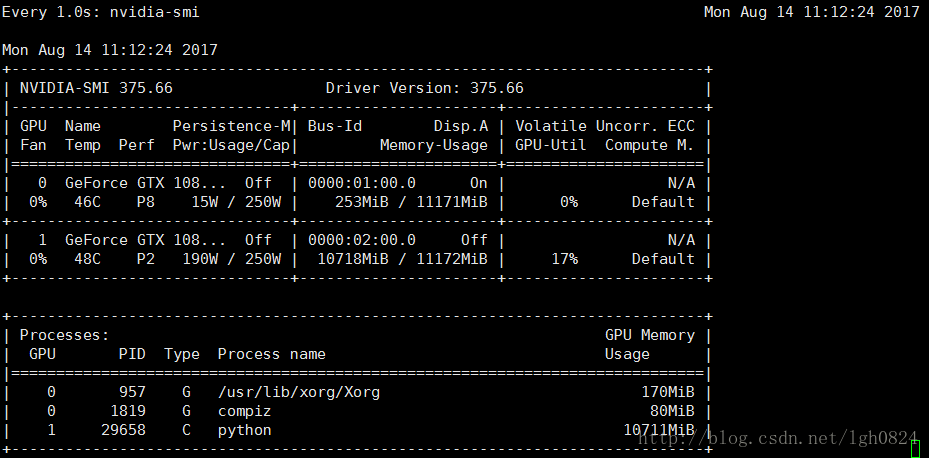
下面给出一个采用CUDA_VISIBLE_DEVICES=0,1两个gpu设备运行一段程序的显存占用情况,从下面这个运行结果来看,按照per_process_gpu_memory_fraction 自动占用最小分配显存的情况运行程序,两个GPU的资源并不是均匀分配,0号设备占用资源较多.
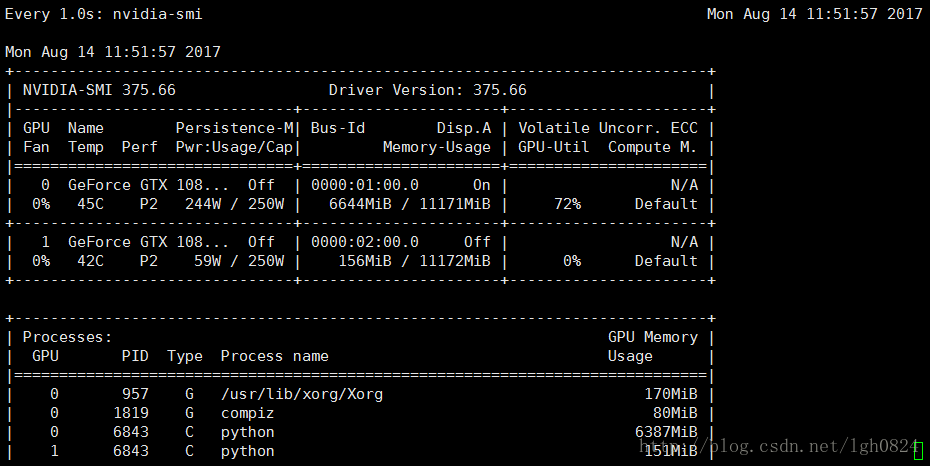
图1 CUDA_VISIBLE_DEVICES=0,1 python predict.py
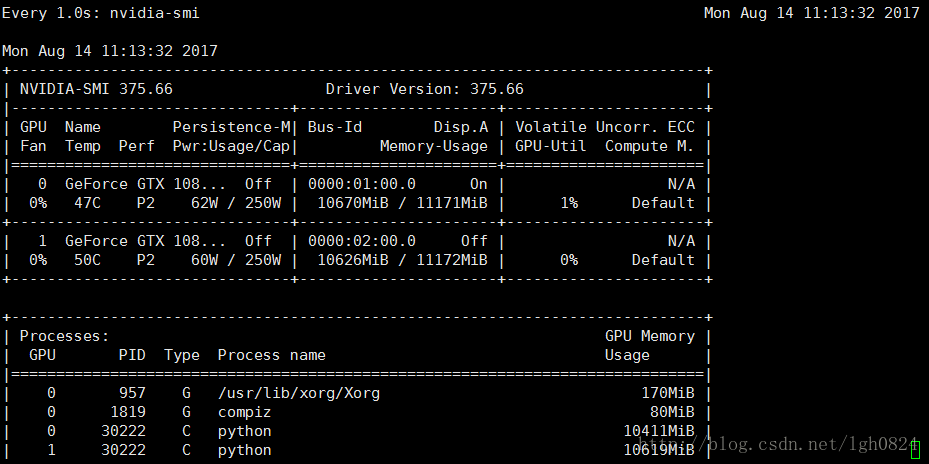
下面给出一个采用CUDA_VISIBLE_DEVICES=1,0两个gpu设备运行一段程序的显存占用情况,从下面这个运行结果来看,按照per_process_gpu_memory_fraction 自动占用最小分配显存的情况运行程序,两个GPU的资源并不是均匀分配,1号设备占用资源较多.

图2 CUDA_VISIBLE_DEVICES=1,0 python predict.py
以上两幅图反映了,根据gpu设备号的排列,存在使用的优先级问题,排在前面的优先级较高。
如果认真观察在运行程序的时候的两个gpu显存的变化,就会发现,程序运行其实只占用了优先级较高的设备了,这是因为1个gpu设备已经满足程序运行的需要了,而对于第二个设备也占用了显存资源,仔细发现,你能够看到,两个gpu在程序进行初始化的,并未进行session run的时候,出现显存占用情况,切优先级较低的设备在后续的程序运行过程中,显存占有并未增加。
参考博客:tensorflow gpu使用说明
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)