目录
- 如何将一张身份证图像的信息识别出来?
- 身份证识别点我
- 银行卡识别点我
- 第一步 目标检测
- 第二步 图像校正
-
- 第三步 文本检测
-
- 第四步 文本识别
-
- 最后 信息抽取
- 总结
如何将一张身份证图像的信息识别出来?
身份证识别点我
银行卡识别点我
目前,人社、金融、工商、公安等政府办事部门使用身份证OCR技术,可以快速识别用户身份信息,缓解政府部门办事压力,减少业务办理的等待时间,是智能识别产业在政务领域的一大突破。
百度、优图等互联网大厂纷纷建立智能识别开放平台。
那么我们不仅要问一张身份证图像信息是如何被精确的结构化识别和传递的呢?

本文将借助项目经验,以身份证信息识别为示例,着重将这一识别流程和框架总结介绍。
第一步 目标检测
毫无疑问我们第一步需要检测和定位我们感兴趣的区域,这是高精度识别的基础。
也就是说我们首先要找到身份证在图像上是否存在,如果存在那么它大概在什么图像坐标位置。

这一步可采用主流目标检测算法有YOLOv3,SSD,Faster RCNN等。
第二步 图像校正
实际应用场景中图像可能是多角度放置的。

需要通过透视变换将变形的目标校正到良好的俯瞰平面。向下面图示一样。。

如何获取匹配点对坐标
由透视变换原理,求解透视变换矩阵至少需要4点对映射。
也就是说我们需要获得至少包括身份证卡片的四个顶点,将其投影到一个标准的卡片尺寸大小。
我们可以根据行业标准获取卡片长宽比为1.6:1,可设置目标顶点坐标(0,0)(1024,0)(1024,640)(0,640)
那么问题来了,图像中身份证顶点坐标如何获取?
经验告诉我们身份证卡边都是直线,透视变换后基本也是直线,通过直线检测获取四条直线相交即可获得四个顶点坐标。直线检测可采用Hough Transform, LSD等。但这些方法鲁棒性较差,直线检测容易受背景干扰。
基于深度学习的关键点检测算法登场!!!
Cascaded Pyramid Network 来自face++2017年coco keypoint benchmark 数据集冠军的文章。主要提出了基于CPN(Cascaded PyramidNetwork)结构的人体关键点检测框架。
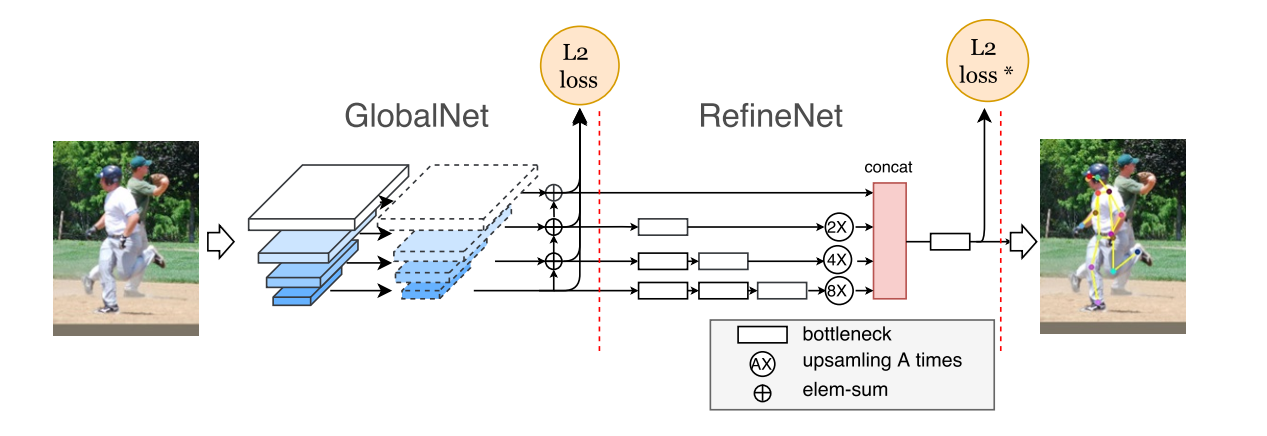
采用CPN方法获取关键点还有一大优点相较于传统方法,那就是关键点是有序的,再也不用面对180翻转怎么办的鸡肋问题了。。。
当然也有其他关键点检测算法例如 Mask RCNN。。。
求解透视变换矩阵
不满足四点对?基于四顶点扩增标签点数量。使用最佳子集来产生单应矩阵估计内点和异常值,提升校正效果的鲁棒性。

OpenCV cv2.findHomography()算法使用了RANSAC或者LEAST_MEDIAN(由标志决定)。最优化估计的好的匹配被叫做inliers,而其他的叫做outliers。返回一个掩图 mask 来指定inlier和outlier。如下:
M, mask = cv2.findHomography(pts0, pts1, cv2.LMEDS)
dst = cv2.warpPerspective(img, M, (WIDTH, HEIGHT))
第三步 文本检测
处理到目前为止我们得到了什么?一张张校正过的身份证图像。。。

接下来我们进行文本检测
文本检测不是一件简单的任务,尤其是复杂场景下的文本检测,非常具有挑战性。自然场景下传统行投影,梯度分割等算法局限性凸显。
例如,MSER(Robust wide-baseline stereo from maximally stable extremal regions) 最大稳定极值区域对文字形状变化的适应性和抗干扰性比较差。
文本检测本质上也是一种目标检测,可通对Faster-RCNN这类通用目标检测网络进行改进,设计出适合文本检测全新架构。
CTPN
采用基于faster rcnn等通用物体检测框架的算法都会面临一个问题?怎么生成好的text proposal?这个问题实际上是比较难解决的。因此在这篇文章中作者提供了另外一个思路,检测一个一个小的,固定宽度的文本段,然后再后处理部分再将这些小的文本段连接起来,得到文本行。

之所以选用CTPN这个文本检测框架是有原因的:
- 将文本检测任务转化为一连串小尺度文本框的检测;
- 引入RNN提升文本检测效果; 利用特征前后文信息提升鲁棒性;
- Side-refinement(边界优化)提升文本框边界预测精准度。
这里一些同学该反驳了,CTPN有个大缺点!对于非水平的文本的检测效果并不好!!
这个嘛 前面我们预处理对身份证图片进行了校正,文本位于水平方向的,完全可以与CTPN无缝衔接,充分发挥CTPN良好的工业化适用能力。
推荐一篇文本检测算法综述
再来一篇。。。
文本检测效果如下

第四步 文本识别
得到多个文本行图像后,就要进行字符识别
传统的方法比如投影分割出单字后进行通过模板匹配,浅层神经网路分类识别几乎已经没有市场。
现今基于深度学习的端到端OCR技术正大行其道。
主要有两大技术方向CRNN OCR和attention OCR。其实这两大方法主要区别在于最后的输出层(翻译层),即怎么将网络学习到的序列特征信息转化为最终的识别结果。这两大主流技术在其特征学习阶段都采用了CNN+RNN的网络结构,CRNN OCR在对齐时采取的方式是CTC算法,而attention OCR采取的方式则是attention机制, 本文将介绍应用更为广泛的CRNN算法。
CRNN
CRNN 网络结构由CNN + LSTM 两部分构成,LSTM的加持使它能够结合前后文信息,同时适用变长文本行的识别。
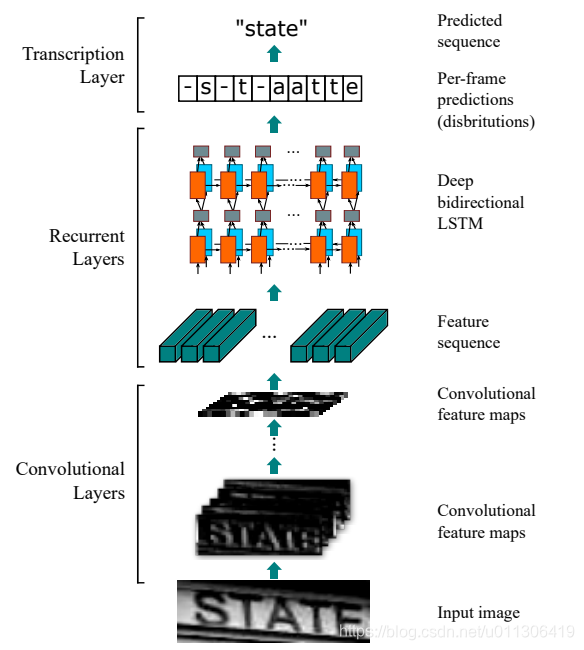
CRNN 具有以下优势
- (1)可以端到端训练;
- (2)可以识别任意长度的序列;
- (3)可以训练基于字典的模型和不基于词典的任意模型;
- (4)训练速度快,并且模型很小。
CRNN训练用样本如何获取?有限的身份证数据集仅包含部分字符样本,或者字符概率分布极不平衡。
因此需要机器生成训练用样本,通过透视变换,模糊,抖动,背景融合等增强样本数据。如下 Fake News。。。

最后 信息抽取
得到杂乱的文本识别结果后,就需要抽取关键身份证信息关键字段了,姓名,性别,住址,号码。。。等
八仙过海各显神通了,对于身份证信息来说格式相对固定,可通过关键字匹配,结合位置信息来编写抽取规则。
这部分重要吗?非常重要!!!结构化的输出识别信息才是客户的最终需求,它对精度影响是直接的。
一些有用的规则不能忽略,比如身份证号码符合国标校验的,,,
总结
以上是笔者在对身份证信息高精度识别流程的实践总结,可推广应用至银行卡,驾驶证,户口本等其他类似卡证智能识别场景。
当然有同学会觉得流程过于复杂,比如目标检测可以直接跳过,图像校正也可以跳过,直接进行文本检测。
本文提供的通用卡证信息识别流程框架,是充分考虑使用场景,保证识别精度,提升识别效率,建立在实践基础上的。。。
欢迎同学们访问如下链接,测试评估交流!!
Email:1161242024@qq.com
身份证信息识别服务
银行卡信息识别服务
通用卡证信息高精度识别流程
智能图像识别产品开发流程
如何设计一个开放平台
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)