目录
字节序
位序
常见位序的错误理解
以太网的大小端
以太网的字节序
以太网的位序
位域中的大小端
位域遇上大小端以太网通信
大端CPU发送
小端CPU发送
位域大小端问题的解决措施
大小端问题浪费了太多应用、驱动、逻辑工程师太多的时间,无时无刻都有人正在被大小端坑,正好比此时的我在浪费时间谈论大小端。
如果学过计算机原理、编程等知识,都知道课本里对大小端的一段描述:
小端模式:数据的高字节,存放在高地址中。计算机读取数据的方向,是从高地址开始读取的;
大端模式:数据的高字节,存放在低地址中。计算机读取数据的方向,是从低地址开始读取的;
注意这里只提到了字节序,并未提及到位序问题。
常见大小端CPU如下:
大端cpu:PowerPC
小端cpu:x86、arm(内核支持大端但从未见过大端)
注:
·MSB/LSB:
用于描述寄存器的各个位域含义时:MSB(Most Significant Bit 最高有效位),LSB(Least Significant Bit 最低有效位)。0b10010100,无论在大端还是小端机中,MSB为1,LSB为0。
用于描述整形数据时:指数学层面的高权重字节与低权重字节,如0x12345678,无论在大端还是小端机中,MSB都是指的0x12,LSB指0x78。
·Big Endian/Little Endian:指两种端序。
·用[a:b]的方式表示多个bit位,如:[3:0]表示bit3 bit2 bit1 bit0,[0:3]表示bit0 bit1 bit2 bit3。
·为了视觉效果会把0写成00,把1写成01。
·文章中提到的高位低位均指内存或寄存器的地址的高位与低位,如果是数字的高字节与低字节,会强调为数学概念高权重的位与低权重的位,以防止教科书上的数字字节、存储器字节傻傻分不清楚。
字节序
从字节序的视角一个多字节数0x12345678。
存放在大端CPU的RAM时:
Byte0 Byte1 Byte2 Byte3
0x12 0x34 0x56 0x78
存放在小端CPU的RAM时:
Byte3 Byte2 Byte1 Byte0
0x12 0x34 0x56 0x78
位序
从位序的视角看一个单字节数0x12。
存放在大端CPU的RAM时,[0:7] = 0x12(0b00010010):
bit0 bit1 bit2 bit3 bit4 bit5 bit6 bit7
0 0 0 1 0 0 1 0
存放在小端CPU的RAM时,[7:0] = 0x12(0b00010010):
bit7 bit6 bit5 bit4 bit3 bit2 bit1 bit0
0 0 0 1 0 0 1 0
从位序的视角看一个多字节数0x12345678。
存放在大端CPU的RAM时,[0:31] = 0x12345678(0b0001 0010 0011 0100 0101 0110 0111 1000)
bit: 00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
val: 0 0 0 1 0 0 1 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 0 0 0
存放在小端CPU的RAM时,[31:0] = 0x12345678(0b0001 0010 0011 0100 0101 0110 0111 1000)
bit: 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 09 08 07 06 05 04 03 02 01 00
val: 0 0 0 1 0 0 1 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 0 0 0
常见位序的错误理解
如果不知道位序这个概念,很可能会把多字节在RAM中存储的顺序弄错,如对多字节数0x12345678的错误理解
在大端系统中,存储顺序错理解为:
bit: 07 06 05 04 03 02 01 00 15 14 13 12 11 10 09 08 23 22 21 20 19 18 17 16 31 30 29 28 27 26 25 24
val: 0 0 0 1 0 0 1 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 0 0 0
在小端系统中,存储顺序错理解为:
bit: 24 25 26 27 28 29 30 31 16 17 18 19 20 21 22 23 08 09 10 11 12 13 14 15 00 01 02 03 04 05 06 07
val: 0 0 0 1 0 0 1 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 1 0 0 1 1 1 1 0 0 0
以太网的大小端
以太网的字节序
无论大端CPU还是小端CPU,一定是先收发低字节,再收发高字节。
以太网的位序
参考文章:Ethernet下字节序和bit序的总结_shaohui973的博客-CSDN博客_bit0和bit7的顺序,根据个人理解有所修改。(由于笔者未专门研究以太网物理层逻辑,若文章中存在错误,请一定要帮忙指出)
网络接口要遵从的一个原则:在发送bit数据的时候,先发送MSB,最后发送LSB,即最先发送数学层面上权重最大的位,即最左边的bit数据;接收bit数据的时候,先收到MSB,最后收到LSB,即将最先收到的bit数据,移位存储到数学层面上权重最大的位所在存储器中,即最左边的bit中。在计算机中表现如下:(注意此处提到的MSB和LSB并非存储意义上的大小端,而是数字层面上高位与低位,权重高的为高位,权重低的为低位。计算机的存储空间并不存在上下左右,此处的“左边”,指人类对数字或地址的书写习惯上的描述,如数字0x112233中,0x11就是该数字权重最高的字节,位于最左边)
在大端系统中,网卡发送bit数据bit[0:7] = 0x55(0b01010101)时,依次发送bit0, bit1, bit2, bit3, bit4, bit5, bit6, bit7,即发送01010101。
在小端系统中,网卡发送bit数据bit[7:0] = 0x55(0b01010101)时,依次发送bit7, bit6, bit5, bit4, bit3, bit2, bit1, bit0,即发送01010101。
在大端系统中,网卡收到bit数据时,依次存放在bit0, bit1, bit2, bit3, bit4, bit5, bit6, bit7,得到数据bit[0:7] = 0x55(0b01010101) 。
在小端系统中,网卡收到bit数据时,依次存放在bit7, bit6, bit5, bit4, bit3, bit2, bit1, bit0,得到数据bit[7:0] = 0x55(0b01010101)。
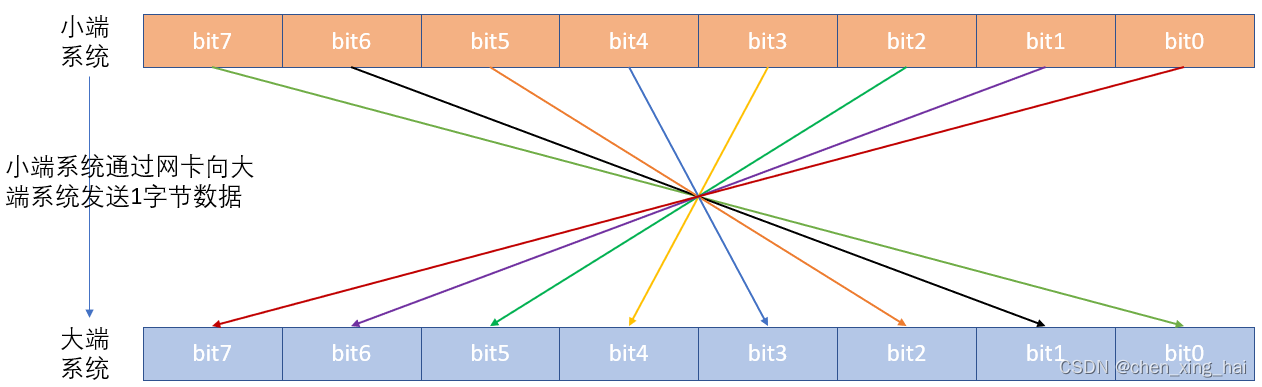
同样是以太网发送端口,在大端系统与小端系统中逻辑电路设计并不相同,才能满足大小端系统通信发送的数据和收到的数据值相同的基本要求。
不仅以太网接口原理如此,很多单通道串行通信都是如此,在大端系统与小端系统中收发的位序并不相同,在这些标准通信协议规范中提到的先发送高位中的“位”并不是指地址的位,而是数字含义中的位置,这里的高位指高权重的数字位,即左边的值。
位域中的大小端
在寄存器定义、通信协议中经常会看到位域定义,在C/C++的结构体中可定义与之对应的位域结构体,以方便解析及组包。位域定义方式如下:
struct 位域结构名
{
type [member_name] : width ;
};
本文为了方便,将存储到同一个标准数据类型的所有成员称为一个域,同一个域内的成员称为域成员。如下面的结构体中a1和a2属于同一个域,a1和a2是这个域的域成员;b1、b2、b3、b4属于同一个域,b1、b2、b3、b4是这个域的域成员;
有如下C/C++结构体struct st1及变量data:
struct st1
{
uint8_t a1 : 2;
uint8_t a2 : 6;
uint16_t b1 : 3;
uint16_t b2 : 4;
uint16_t b3 : 5;
uint16_t b4 : 4;
};
struct st1 data ={
.a1 = 0x1,
.a2 = 0x3,
.b1 = 0x4,
.b2 = 0x8,
.b3 = 0xb,
.b4 = 0x3
};
结构体成员.a1和.a2属于同一个域,域大小为8bit。.b1、.b2、.b3、.b4属于同一个域,域大小为16bit。
域的定义一般要遵循如下原则:域大小可以是8/16/32/64bit,域之间不可交叉,域的所有成员总大小必须等于所属域大小,必要时加入保留(reserved)位来填补。
C/C++的结构体有一个规定,无论大端还是小端,先定义的成员一定是低字节和低位。
在大端系统中,结构体变量及其成员的存储情况如下:
.a1 .a2 .b1 .b2 .b3 .b4
bit [00:01] [02:07] [08:10] [11:14] [15:19] [20:23]
data 01 000011 100 1000 01011 0011
.a1[0:1] = 0b01(0x1);
.a2[0:5] = 0b000011(0x3);
.b1[0:2] = 0b100(0x4);
.b2[0:3] = 0b1000(0x8);
.b3[0:4] = 0b01011(0xb);
.b4[0:3] = 0b0011(0x3);
在小端系统中,各个结构体成员的存储情况如下:
.a1 .a2 .b1 .b2 .b3 .b4
bit [01:00] [07:02] [10:08] [14:11] [19:15] [23:20]
data 01 000011 100 1000 01011 0011
.a1[1:0] = 0b01(0x1);
.a2[5:0] = 0b000011(0x3);
.b1[2:0] = 0b100(0x4);
.b2[3:0] = 0b1000(0x8);
.b3[4:0] = 0b01011(0xb);
.b4[3:0] = 0b0011(0x3)
位域&大小端&以太网通信
位域可以2bit、5bit等不规则的多个bit来描述一个成员,但单通道串行通信接口只能以8bit为单位进行逐位发送,且从高bit发送还是低bit发送取决于CPU的大小端模式,大端CPU先发送bit0,小端CPU先发送bit7.
使用上文提到的结构体struct st1 data进行网络发送时会出现如下有趣现象:
大端CPU发送
发送上述数据,网络端口发送的顺序将会是(从左到右的发):01 000011 100 1000 01011 0011(为方便区分字节,同一个byte的位背景颜色相同;为方便区分结构体成员,成员间用空格隔开)。
如果接收端为大端CPU,针对每个字节的接收,收到的第一个bit放到bit0,最后一个bit放到bit7,最终收到的数据将是:bit[0:23] 01 000011 100 1000 01011 0011。如果接收端程序定义的结构体与发送端完全相同,则每个成员刚好对应上,数据解析正确。
如果接收端为小端CPU,针对每个字节的接收,收到的第一个bit放到bit7,最后一个bit放到bit0,最终收到的数据将是:bit[23:0] 1011 00111 0010 000 010000 11。如果接收端程序定义的结构体与发送端完全相同,则由于发送位序颠倒,数据已经完全紊乱。根据C/C++的规定:无论大端还是小端CPU,先定义的结构体成员一定位于低位或低字节,解析出来的数据如下:
.a1[1:0] = 0b11(0x3);
.a2[5:0] = 0b010000(0x10);
.b1[2:0] = 0b000(0x0);
.b2[3:0] = 0b0010(0x2);
.b3[4:0] = 0b00111(0x7);
.b4[3:0] = 0b1011(0xb);
和源数据相比,已经面目全非了。
小端CPU发送
小端发送问题与大端发送原理相同,读者可自己分析,加深印象。
位域大小端问题的解决措施
问题原因:位序的颠倒使得域内部数据存储顺序颠倒;如果域大于1个字节,且域成员间存在跨字节情况,则位序颠倒及字节序不颠倒特性,会使得域成员存在数据出现重组情况,进一步加重数据的紊乱。分析起来比较烧脑。
笔者总结了一套解决此问题的方法:
1、大端CPU程序与小端CPU程序中的位域结构体中各个域间顺序相同;
2、大端CPU程序与小端CPU程序中的位域结构体中相同域内部的域成员顺序相反;
3、大端CPU或小端CPU在发送或收到数据时,任意一方做域的大小端字节序转换,如域为uint16_t则按照2字节大小端转换,为uint32_t则按照4字节大小端转换。
具体是大端CPU还是小端CPU做结构体定义修正及发送时域大小端转换,取决于项目定义的报文是大端模式还是小端模式。如果报文定义的文档规定使用大端定义,则大端CPU按照文档定义结构体既可,且发送时无需做大小端转换;而小端CPU的程序则需要根据上述解决方法来处理。
验证:
假若报文协议规定使用大端模式,则大端CPU的结构体定义如下:
struct st1
{
uint8_t a1 : 2;
uint8_t a2 : 6;
uint16_t b1 : 3;
uint16_t b2 : 4;
uint16_t b3 : 5;
uint16_t b4 : 4;
};
struct st1 data ={
.a1 = 0x1,
.a2 = 0x3,
.b1 = 0x4,
.b2 = 0x8,
.b3 = 0xb,
.b4 = 0x3
};
小端CPU的结构体定义如下:
struct st1
{
uint8_t a2 : 6;
uint8_t a1 : 2;
uint16_t b4 : 4;
uint16_t b3 : 5;
uint16_t b2 : 4;
uint16_t b1 : 3;
};
char buff[3];
struct st1 *p_data = (struct st1 *)buff;
大端CPU通过以太网发送数据顺序:01 000011 100 1000 01011 0011
小端CPU通过以太网收到数据:bit[23:0] 101100111001000001000011
数据用存入buff后做域大小端转换,得到数据bit[23:0] 100100001011001101000011
p_data进行解析解析得到数据bit[23:0] 100 1000 01011 0011 01 000011,各成员值如下:
.a1[1:0] = 0b01(0x1);
.a2[5:0] = 0b000011(0x3);
.b1[2:0] = 0b100(0x4);
.b2[3:0] = 0b1000(0x8);
.b3[4:0] = 0b01011(0xb);
.b4[3:0] = 0b0011(0x3);
解析得到的数据和发送端的数据完全一样,数据解析正确。
大端ARM
ARM Cortex-M3的端模式。
ARM的小端模式和前面所讲完全相同,但它的大端模式比较特殊,32bit的数据的位序并不是bit0-bit31,而是bit[7:0][15:8][23:16][31:24]。
CM3 同时支持小端模式和大端模式。但是,单片机其它部分的设计,包括总线的连接,内存控制器以及外设的性质等, 一定要先在单片机的数据手册上查清楚可以使用的端。在绝大多数情况下,基于 CM3 的单片机都使用小端模式——为了避免不必要的麻烦,在这里推荐读者清一色地使用小端模式。
CM3中对大端模式的定义还与ARM7的不同(小端的定义都是相同的)。在ARM7中,大端的方式被称为“字不变大端”,而在CM3中,使用的是“字节不变大端”。如表5.4所示。
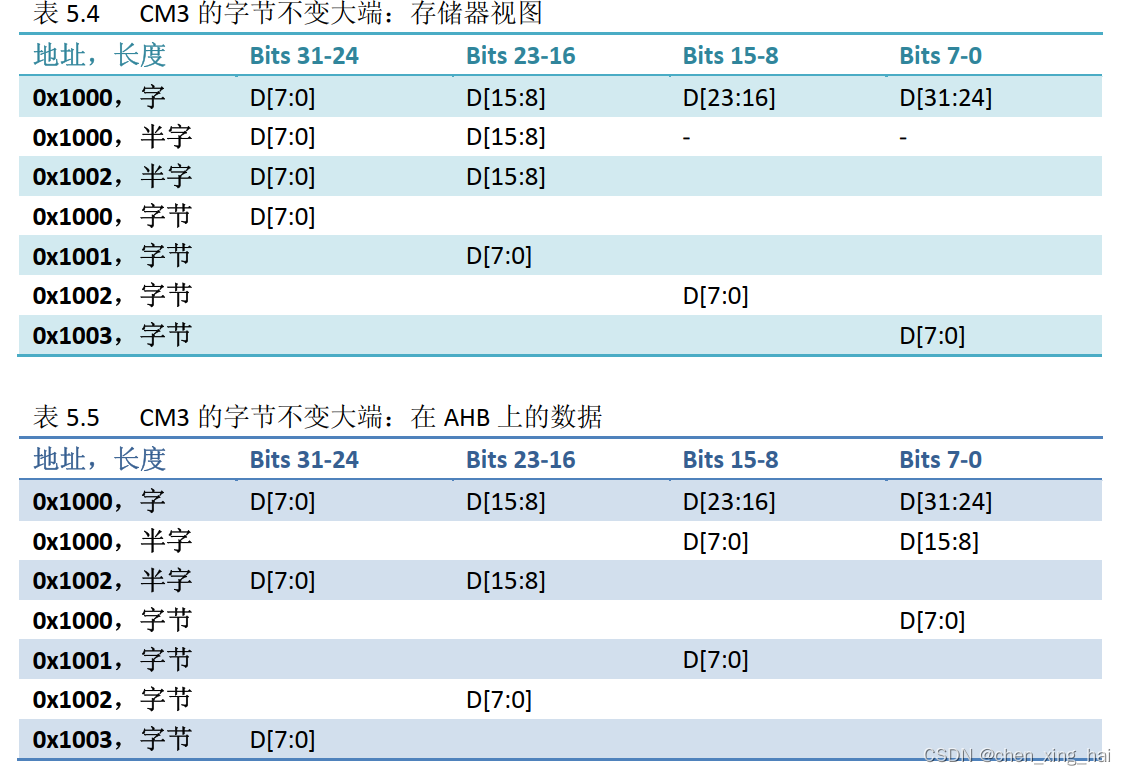
请注意:在 AHB 总线上的 BE‐8 模式下,数据字节 lane 的传送格式是与小端模式一致的。
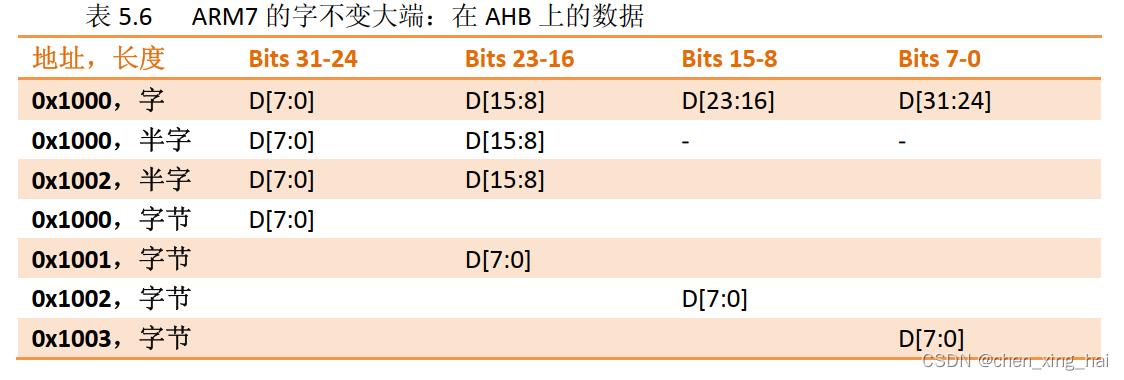
这是不同于 ARM7TDMI 的行为,它在大端模式下会有另一种总线 lane 安排,如表 5.6
所示。
在CM3中,是在复位时确定使用哪种端模式的,且运行时不得更改。指令预取永远使用小端模式,在配置控制存储空间的访问也永远使用小端模式(包括NVIC,FPB之流)。另外,外部私有总线地址区0xE0000000至0xE00FFFFF也永远使用小端模式。
当 SoC 设计不支持大端模式,却有一些外设包含了大端模式时,可以轻易地使用REV/REVH指令来完成端模式的转换。
对ARM的大端不理解也并不影响我们对大小端的理解与实际应用,因为我还没使用过大端ARM内核的芯片(个人能力有限)。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)