深度学习推荐系统——深度学习时代
- AutoRec
- Deep Crossing
- NeuralCF
- PNN
- Wide&Deep
- FM与深度学习模型结合
-
- 注意力机制
-
- DIEN
- 总结
AutoRec
h
(
r
;
θ
)
=
f
(
W
⋅
g
(
V
r
+
μ
)
+
b
)
h ( \boldsymbol { r } ; \theta ) = f ( \boldsymbol { W } \cdot g ( \boldsymbol { V } \boldsymbol { r } + \mu ) + b )
h(r;θ)=f(W⋅g(Vr+μ)+b)
损失函数:
min
θ
∑
i
=
1
n
∥
r
(
i
)
−
h
(
r
(
i
)
;
θ
)
∥
O
2
+
λ
2
⋅
(
∥
W
∥
F
2
+
∥
V
∥
F
2
)
\min _ { \theta } \sum _ { i = 1 } ^ { n } \left\| \boldsymbol { r } ^ { ( i ) } - h \left( \boldsymbol { r } ^ { ( i ) } ; \theta \right) \right\| _ { O } ^ { 2 } + \frac { \lambda } { 2 } \cdot \left( \| \boldsymbol { W } \| _ { F } ^ { 2 } + \| \boldsymbol { V } \| _ { F } ^ { 2 } \right)
θmini=1∑n∥∥∥r(i)−h(r(i);θ)∥∥∥O2+2λ⋅(∥W∥F2+∥V∥F2)
其中
r
\boldsymbol {r}
r表示m个用户对它的评分,即共现矩阵中的列向量。
经过自编码器生成的输出向量,不会完全等同于输入向量,也因此具备了一定的缺失维度的预测能力。
以上是I-AutoRec,如果换做用户的评分向量,则得到U-AutoRec。优势在于输入一次就得到目标用户对所有物品的预测评分,劣势在于用户向量的稀疏性会影响模型的结果。
优点:具备一定泛化能力和表达能力
缺点:表达能力不足
Deep Crossing
主要包括4层:Embedding层,Stacking层,Multiple Residual Units层和Scoring层。
- Embedding层:Embedding层的作用是将稀疏的类别型特征转换成稠密的Embedding向量。一般来说Embedding向量的维度应远小于原始的稀疏特征向量。
- Stacking层:拼接Embedding特征。
- Multiple Residual Units层:主要结构是多层感知机,采用了多层残差网络(Multi-Layer Residual Network)
- Scoring层:对于CTR预估这类二分类问题,可用逻辑回归模型。对于多分类,可采用softmax模型。
优点:深度特征交叉
NeuralCF
“多层神经网络+输出层”替代“矩阵分解中的内积”

优点:
1、让用户向量和物品向量进行充分的交叉
2、引入更多的非线性特征
PNN
PNN和Deep Crossing模型的区别在于用Product层替代了Stacking层。分为内积操作和外积操作,但外积操作用于形成矩阵,因此可以考虑池化层来减少训练负担。
PNN在于强调特征向量之间的交叉方式是多样化的。
Wide&Deep
由单层的Wide部分和多层的Deep部分组成的混合模型。其中,Wide作用是让模型具有较强的“记忆能力”;Deep作用是让模型具有“泛化能力”。
“记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力。
“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。

Deeo部分的输入是全量的特征向量。Wide部分的输入仅仅是已安装应用和曝光应用两类特征。可以用Cross替代Wide,改进为Deep&Cross,增加特征间的交互。
优点:
能够融合传统模型记忆能力和深度学习模型泛化能力的优势
模型的结构不复杂,容易部署上线
FM与深度学习模型结合
FNN
由于Embedding层的输入极端稀疏化,参数量很大,导致Embedding层的收敛速度很慢,因此用FM的隐向量完成Embedding层初始化。FM数学形式:
y
F
M
(
x
)
:
=
sigmoid
(
w
0
+
∑
i
=
1
N
w
i
x
i
+
∑
i
=
1
N
∑
j
=
i
+
1
N
⟨
v
i
,
v
j
⟩
x
i
x
j
)
\boldsymbol { y } _ { \mathrm { FM } } ( x ) : = \operatorname { sigmoid } \left( w _ { 0 } + \sum _ { i = 1 } ^ { N } w _ { i } x _ { i } + \sum _ { i = 1 } ^ { N } \sum _ { j = i + 1 } ^ { N } \left\langle \boldsymbol { v } _ { i } , \boldsymbol { v } _ { j } \right\rangle x _ { i } x _ { j } \right)
yFM(x):=sigmoid(w0+i=1∑Nwixi+i=1∑Nj=i+1∑N⟨vi,vj⟩xixj)
DeepFM
DeepFM对Wide&Deep模型的改进之处在于,它用FM替代了原来的Wide部分,加强了浅层网络部分特征组合的能力。
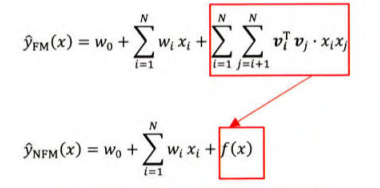
NFM
NFM模型的主要思路是用一个表达能力更强的函数替代原FM中二阶隐向量内积部门。
注意力机制
AFM
注意力网络的作用是为每一个交叉特征提供权重,也就是注意力得分。
f
A
t
t
(
f
P
I
(
ε
)
)
=
∑
(
i
,
j
)
∈
R
x
a
i
j
(
v
i
⊙
v
j
)
x
i
x
j
a
i
j
=
′
h
T
ReLU
(
W
(
v
i
⊙
v
j
)
x
i
x
j
+
b
)
a
i
j
=
exp
(
a
i
j
′
)
∑
(
i
,
j
)
∈
R
x
exp
(
a
i
j
′
)
f _ { \mathrm { Att } } \left( f _ { \mathrm { PI } } ( \varepsilon ) \right) = \sum _ { ( i , j ) \in \mathcal { R } _ { x } } a _ { i j } \left( v _ { i } \odot v _ { j } \right) x _ { i } x _ { j } \\ \begin{array} { c } a _ { i j = } ^ { \prime } \boldsymbol { h } ^ { \mathrm { T } } \operatorname { ReLU } \left( \boldsymbol { W } \left( \boldsymbol { v } _ { i } \odot v _ { j } \right) x _ { i } x _ { j } + \boldsymbol { b } \right) \\ a _ { i j } = \frac { \exp \left( a _ { i j } ^ { \prime } \right) } { \sum _ { ( i , j ) \in \mathcal { R } _ { x } } \exp \left( a _ { i j } ^ { \prime } \right) } \end{array}
fAtt(fPI(ε))=(i,j)∈Rx∑aij(vi⊙vj)xixjaij=′hTReLU(W(vi⊙vj)xixj+b)aij=∑(i,j)∈Rxexp(aij′)exp(aij′)
DIN
在计算一个用户是否点击一个广告 a 时,模型的输人特征自然分为两大部分:一部分是用户的特征组,另一部分是候选广告 a 的特征组。利用候选商品和历史行为商品之间的相关性计算出一个权重,这个权重就代表了注意力的强弱。表示如下:
V
u
=
f
(
V
a
)
=
∑
i
=
1
N
w
i
⋅
V
i
=
∑
i
=
1
N
g
(
V
i
,
V
a
)
⋅
V
i
\boldsymbol { V } _ { \mathrm { u } } = f \left( \boldsymbol { V } _ { \mathrm { a } } \right) = \sum _ { i = 1 } ^ { N } w _ { i } \cdot \boldsymbol { V } _ { i } = \sum _ { i = 1 } ^ { N } g \left( \boldsymbol { V } _ { i } , \boldsymbol { V } _ { \mathrm { a } } \right) \cdot \boldsymbol { V } _ { \boldsymbol { i } }
Vu=f(Va)=i=1∑Nwi⋅Vi=i=1∑Ng(Vi,Va)⋅Vi
其中,
V
u
V_u
Vu是用户的 Embedding 向量,
V
a
V_a
Va是候选广告商品的 Embedding 向量,
V
I
V_I
VI是用户
u
u
u的第
i
i
i次行为的 Embedding 向量。这里用户的行为就是浏览商品或店铺,因此行为的 Embedding 向量就是那次浏览的商品或店铺的 Embedding 向量。
因为加入了注意力机制,所以
V
u
V_u
Vu从过去
V
i
V_i
Vi的加和变成了
V
i
V_i
Vi的加权和,
V
i
V_i
Vi的权重
w
i
w_i
wi就由
V
i
V_i
Vi与
V
a
V_a
Va的关系决定,也就是中的
g
(
V
i
,
V
a
)
g(V_i,V_a)
g(Vi,Va)即“注意力得分”。
那么,
g
(
V
i
,
V
a
)
g(V_i,V_a)
g(Vi,Va)函数到底采用什么形式比较好呢?答案是使用一个注意力激活单元来生成注意力得分。这个注意力激活单元本质上也是一个小的神经网络。
DIEN
(1)它加强了最近行为对下次行为预测的印象。
(2)序列模型能够学习到购买趋势的信息。
兴趣进化网络分为三层,从下至上依次是:
(1)行为序列层:其主要作用是把原始的id类行为序列转换成Embedding行为序列。
(2)兴趣抽取层:其主要作用是通过模拟用户兴趣迁移过程,抽取用户兴趣。
(3)兴趣进化层:其主要作用是通过在兴趣抽取层基础上加入注意力机制,模拟与当前目标广告相关的兴趣进化过程。
总结


本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)