点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
说在前面的话
标题:Multimodal Object Detection via Probabilistic Ensembling
链接:https://arxiv.org/abs/2104.02904
我相信大家不多不少都会看过我自己做的一些工作,同时也还有我解读RGB-Thermal系列的一些工作,所以这一期我想讨论一下RGB-T目标检测的工作!
RGB-T与目标检测
目标检测是大家的老朋友了,随着端到端模型的不断优化,像1 stage的Yolo系列,还有2 stages的RCNN系列以及各种基于FPN衍生出来的后起之秀,都在帮助目标检测生态变得更加的成熟。当前也有越来越多的目标检测框架从Paper中出来,落地到安全生产领域当中。自动驾驶(autonomous vehicles(AVs))就是其中之一,但是普通的基于RGB数据的目标检测方案在自动驾驶领域中经常会遇到一些比较棘手的问题,比如在夜间可视情况差,或者遇到目标物体遮挡的情况,在这种情况下RGB数据往往无法捕获有用的特征信息供模型学习,所以我们就引入了Thermal数据来帮助AVs进行日夜交替的目标检测的工作!
RGB-T目标检测的挑战(1)数据
现阶段的大规模数据集以及大规模预训练模型都是基于单模态(RGB)进行研究的,但是结合Thermal的多模态数据的工作却比较少。那为什么RGB-T数据会这么少呢?主要还是两个方面的困难
1、数据的配准难度大
因为RGB和Thermal这两个镜头是分开独立的,所以成像的角度是很难做到直接统一,从而无法直接对齐RGB和Thermal两个模态的之间的像素位置信息。
一般而言要想使得两个模态进行配准,我们在硬件上可以选择使用分束器(Beam splitter)如下图,通过分束器,直接校准RGB图像在Thermal图像同一时空下的成像畸变(成像在同一平面上的位置),对齐两模态的信息。

或者是使用一个固定的支架,这种支架也是可以从物理成像的角度上,采用无目标校准方法来对齐图像

还有一种办法是使用GPS时钟同步器进行时间校准。通过计算时间差,找到RGB相机和Thermal相机在同一位置的成像信息,并将同一位置的信息进行配准,这种方法也广泛的运用在多机机器人的方法互联上。
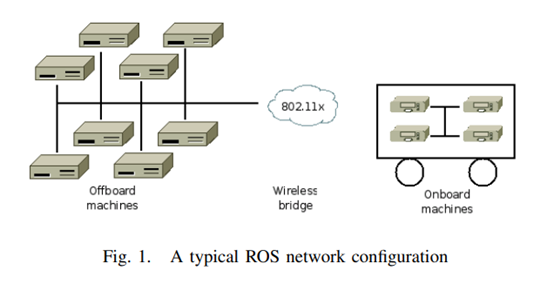
2、标注成本上升
现阶段的数据标注工作量是原来的两倍,因为每个模态都需要单独的注释,这无疑是增加了总体标注成本。
因为存在着上述的两种问题给RGB-T的普及带来了一定的难度,那么如果我们可以做出一组方法,能够使得RGB和Thermal不对齐的情况下也能够使用,会不会就能给RGB-Thermal带来一定的工作便利呢?所以文章会着手从模型融合的方式上,打破着两个问题的桎梏,使得RGB-T的工作更加的简单和易于普及。
模型的设计
多模态检测的核心问题是如何融合不同模态的信息。以往的研究已经探索了不同阶段的融合策略,从一个大的方向上划分通常分为前融合、中期融合(特征融合)和后融合。早期融合构建一个四通道的RGB-T的输入,然后直接输入到一个Backbone进行处理。相比之下,中期融合(特征融合)会保持将RGB和Thermal输入独立讨论,然后在网络的下游融合它们的特征。过去绝大多数的工作都会集中在如何合理化的进行结构融合,但是这篇文章希望从另一个角度上探索融合的可能性,一种特别后的融合的极端情况。
从下图上看,融合模型放弃了特征融合的部分,专注于优化后融合部分,结构虽然看上去简单,但是会遇到的问题却非常的不简单。
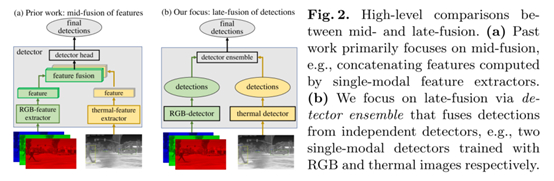
首先我觉得我们需要了解的一个地方是为什么这篇文章会用这样一个结构,它的优势是什么?
如果要使用中(特征)/前融合,其实最担心的问题是模态融合过程的不稳定性还有模态之间的相干性。常见的情况就是强模态抢占弱模态。而且在使用中(特征)融合的方法的情况下,我们其实不知道在高维度特征高度不可解释的情况下怎样的融合和决策方式是合理的。我其实看了很多论文,大家都会有自己的一套方法来进行决策和融合,但是这样的决策和融合基本都是黑箱。很难去解释为啥要这样融合,最多就是在一些宏观角度上去解释一些不太能扎到我心里的废话概念。那么在前/中融合都不争气的情况下,我们能不能考虑不依赖特征提取阶段的后融合?而且后融合参与的对象都是黑箱来的结果,那么可解释性多少会更加的强,那么就可以不再依赖深度学习模型的玄学了!
当然,后融合方法本身的问题也很多,比如不充分结合特征信息。因为引入Thermal模态的信息本身就是为了解决RGB模态信息缺失的问题,但是在以往的后处理方法都是在最后一个阶段进行组合的,这样就会出现差+差=Double差的局面了,所以为了更好的优化后融合模型,我们需要对后处理的信息,进行一些操作。
为什么是ensemble
有人会问,这样一个刷榜的结构或者说是技巧,贡献点在哪?值得被我们称赞为有趣的工作的点在哪?
首先文章证明了精确的模型融合的技术很重要,并且之前的方法,如score- average或max-voting,都不如ProbEn有效,特别是在处理模态信息交互的场景中。虽然ProbEn很简单,但它非常有效,有可能是多模态融合工作的又一个新范式!
Naive Pooling
最简单的策略是直接将多种模式的检测结果直接叠加在一起,这样的做法会导致框堆叠(多次检测到同一个目标物体),实际上并没有任何的融合决策操作,简单来说就是一种无效的后融合策略。
Non-Maximum Supression (NMS)
NMS中文名字也叫非极大抑制值,它是当前目标检测模型的一个关键部分,用于筛选重叠的框,具体来说,当来自两种不同模式的两个检测重叠时(例如IoU>0.5), NMS只是保持较高分数的检测,抑制另一个。
它在以往的RGB模态下的目标检测场景下表现优异,虽然NMS广范的被用于RGB模态检测器中,但我们并不建议将其使用在多模态检测器融合的任务上。其实原因非常简单
由于RGB和Thermal对于光照信息的依赖程度不相同,如下图可见,当RGB在夜间光照不足的情况下无法捕获有效的特征信息,因此识别出来的检测框的得分会偏低,而Thermal模态因为自身的物体性质,在可视环境较差的情况下也能捕获特征信息,所以检测出来的框得分会更高一些。
如果在NMS的作用下,我们就只会保留偏高分的框(Thermal模态下的框),也就是说,NMS不会融合RGB和Thermal模态的信息,从全局的特征信息上判断怎样的检测框才是所需要的更接近GT的,而是简单的在玩一个二选一的游戏。在某种意义上,NMS并不能将来自多个模态的信息“融合”在一起,只是一个择优录取的玩法,并没有融合决策,只是单一的决策而已。
Average Fusion.
为了真正融合多模态信息,一个简单的方法就是将NMS修改为不同模态重叠检测的平均置信度,而不是单纯的抑制较弱的模态。这样的平均已经在以前的工作中就已经被提出。然而,平均分数必然会降低报告重叠检测集的最大值的NMS分数,我们的实验表明,平均产生的结果比NMS更差。直观上,如果两种模式达成一致认为区域内存在目标,那理论的上相互融合后的总体置信分数应该增加而不是减少。
Probabilistic Ensembling (ProbEn)
从上面的方法逐步的走来,我们明确我们需要做的事情是,有效的融合不同模态之间检测框的信息,使得融合后的预测框置信度分数上升。
假设我们有带标签的识别对象(例如,一个“人”)和来自两种模态的预测信息:x1(RGB)和x2(Thermal)。
如果只是写出单一模态的预测概率(分数),我们可以很容易的写出来
p(x1|y)和 p(x2|y),那么如果我要叠加预测呢?
答案是p(x1,x2|y)
根据我们的概率论知识,把这上面这三个式子直接写成
p(x1,x2|y) = p(x1|y)p(x2|y)
我们再进一步思考,如果我们x1(RGB)的预测结果不会影响x2(Thermal)的预测结果时,也就是当x1和x2彼此条件独立的时候,我们会有p(x1,x2)=1,所以所以我们的得到文中的式子2
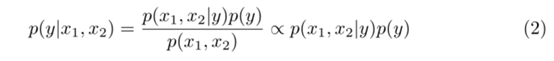
当我们把上面的p(x1,x2|y) = p(x1|y)p(x2|y) 与式子2结合就可以得到式子3和式子4了,式子4就是我们的ProbEn的算式原理了。
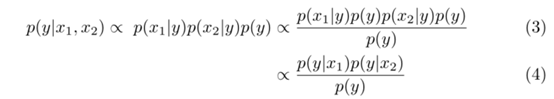
上述的数学推理其实,要说明的一件事情是当x1和x2彼此独立的时候结果最优
具体把公式思想转化为实验步骤需要分为两步
1、单独训练独立的各自模态的检测器,然后得到x1(RGB)和x2(Thermal)的输出,之后计算p(y|x1)和p(y|x2)的分布概率。
2、通过将两个分布相乘,再除以类先验分布(y),并将最终得到的结果进行归一化生成最终分数。
之后再把这个预测的结果扩展到各个预测类别的预测当中去。
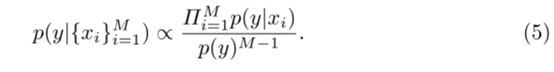
Independence assumptions.
再给出了x1和x2的相互独立的假设(RGB关注的地方和Thermal关注的地方完全不一致)下,我们得到的计算概率最优等价算式。尽管这种假设很理想化,在实际上其实完全不会成立,但是并不影响它的指导效果。(这里可以重点看文章的消融试验部分!)


Relationship to prior work.
之前的工作会比较偏向于使用logit分数进行评估,但是在这篇文章中,我们对于单模态模型重新使用softmax计算类别的分数,主要是为了能够更好的优化后续的算式。这里主要是一个小技巧,可以通过简单的对数的转化技巧,节省一笔计算量!
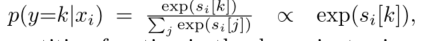
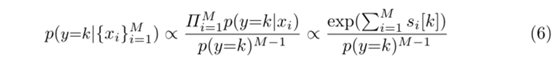
因此,ProbEn的公式就可以等价为对数求和的操作,除以先验类并通过softmax进行规范化。令人惊讶的是统一先验的操作十分有效,即使在不平衡的数据集上,不过这种情况仅限于实验的两个数据集,不一定具有普遍性!
Missing modalities
重要的是,我们希望两个模态之间相互补充信息时,利用求和的方法和取平均的方法会存在很大的不同点。通常来说,不同模态在同一目标对象上也很难做到统一,如果取平均的会降级整体阈值。如果单一模态识别出来但是另一模态没有识别出,那么取平均后,这一模态的值就直接相当于除以2,就有可能会因此低于阈值,从而无法被检测出。如果相加的情况下,也同理,如果发生错误识别的情况下,就极有可能会出现低置信分数*2的情况,从而把背景的内容当前景对象识别出来了。如果,我们真要想合理的处理这种问题就需要将融合多模态检测框与单模态的检测得分进行比较。不要降低了有效目标的置信分数,也不要提升了无效目标的置信分数。通过理论和实验的证明,我们发现ProbEn优雅地处理了模态信息交互的情况,概率归一化的多模态后验p(y|x1, x2)也可以直接与单模态后验p(y|x1)进行比较,能够保留优秀得分,去除无效得分。
Bounding Box Fusion
现在将还可以将ProbEn的方法扩展到帮助(bbox)坐标完成对于重叠的筛选检测。
对此重新定义公式,我们将上文的ProbEn的算式改为连续的bbox的标签
具体来说,我们用z(检测相关的边界框(由其质心、宽度和高度))组成的连续随机变量来代替之前的y。
我们假设单一模态分支的检测提供了一个后验p(z| xi ),
其形式为高斯分布,方差为单一σi2,即p(z| xi ) = N(μi, σi2)
其中, μi是由模态i预测的框坐标。我们同样会假设p(z)上存在一致性的先验,这意味着可以位于接收来自平面的任何位置框坐标信息。
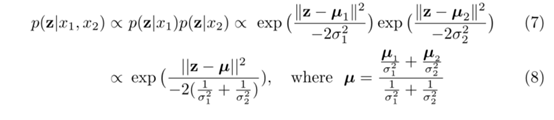
文中探索了三种 σi2 的设置方法。第一种方法avg修复了σi2 =1,相当于简单地平均边界框坐标。第二个s-avg近似于σi2≈1 p(y=k| xi ),这意味着在融合盒坐标时,具有更高置信分数的检测框会具有更高的权重。这比一开始简单的平均边界框的性能略好。第三个v-avg使用GNLL损失和框回归损失训练检测器预测检测的不确定性。
GNLL损失和框回归损失的组合不仅可以产生更准确的回归方差,还有助于模态间的相互信息融合,而且还提高了训练器的检测性能(这里推荐看补充实验的说明,会更加的详细)!

实验部分
文章在两个数据集上验证了不同的融合方法:KAIST和FLIR之间的差距。这两个数据集包含人脸和车牌等个人身份信息,同时使用了Detectron2的Faster RCNN作为预训练模型进行辅助推理优化,只在单个Nvidia GTX 2080上就可以完成工作!
Multimodal Pedestrian Detection on KAIST

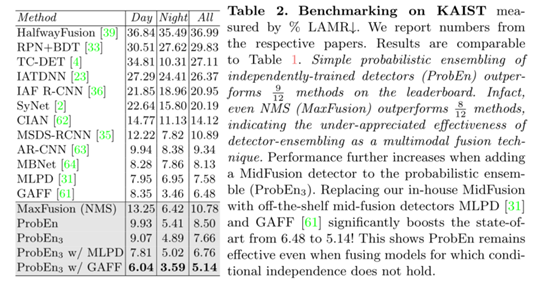
ProbEn++的性能显著优于所有现有的方法,将性能从现有的6.48提高到5.14!这清楚地表明,当条件独立性假设不成立时,ProbEn也可以工作得相当好,ProbEn作为一种不用经过学习就可以直接使用的解决方案,我认为它应该成为未来多模态检测研究的一个新的思考方向
Multimodal Object Detection on FLIR

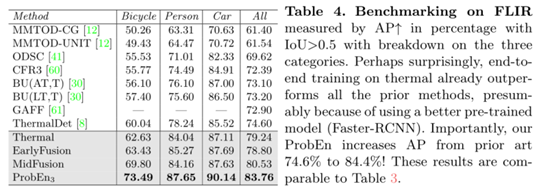
值得注意的是,我们的融合方法提高了在融合阶段中对自行车的检测能力也得到了提高。自行车是不会散发热量来传递强烈的热信号,所以在RGB中的信息会更明显,将两者模态进行融合在一起可以大大提高自行车的检测能力。
总结
ProbEn,显著优于先前的方法。其强大性能的关键原因是
通过对NMS在多模态后处理融合的问题进行了修改,结合以往工作的经验,文章与之前的工作相比,ProbEn无论是在对齐和非对齐的多模态的数据集中都获得了相当不错相对改善。
这篇文章其实与我之前看得RGB-Thermal的文章不同,是一个后处理流派的文章,而我本人是一个坚定的中(特征)融合的信徒,所以读这篇文章的时候内心多少有点带着敌意。仔细阅读下来,其实文章会画更多笔墨在结果的决策与融合的上面,全过程都可以直观的可视化。这个过程,没有黑箱,只有数学理论的推倒,不需要训练,只需要整理不同模态分支的结果,然后提出新的融合方案。打破黑箱,拥抱数学,这是我很想和大家分享的一个点,所以有了这篇文章。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
