融合人体姿态估计和目标检测的学生课堂行为识别_参考网














摘要: 在課堂教学中 , 人工智能技术可以帮助实现学生行为分析自动化 , 让教师能够高效且直观地掌握学生学习行为投入的情况 , 为后续优化教学设计与实施教学干预提供数据支持.构建了学生课堂行为数据集 , 为后续研究工作提供了数据基础;提出了一种行为检测方法及一套可行的高精度的行为识别模型 , 利用 OpenPose 算法提取的人体姿态全局特征 , 融合 YOLO v3算法提取的交互物体局部特征 , 对学生行为进行了识别分析 , 提高了识别精度;改进了模型结构 , 压缩并优化了模型 , 降低了空间与时间的消耗. 选取与学习投入状态紧密相关的4 种行为:正坐、侧身、低头和举手进行识别 , 该检测与识别方法在验证集上的精度达到了95.45%, 在课堂上玩手机和书写等常见行为的识别精度较原模型有很大的提高.
关键词:学习行为识别; 人体姿态估计;目标检测; 计算机视觉; 深度学习
中图分类号: TP391.1 文献标志码: ADOI:10.3969/j.issn.1000-5641.2022.02.007
Recognition of classroom learning behaviors based on the fusion of human pose estimation and object detection
WANG Zejie1,2 , SHEN Chaomin1,2 , ZHAO Chun3,4 , LIU Xinmei1,2 , CHEN Jie1,2
(1. School of Computer Science and Technology, East China Normal University, Shanghai 200062, China;2. Shanghai Key Laboratory of Multidimensional Information Processing, East China Normal University,Shanghai 200241, China;3. Information Technology Service, East China NormalUniversity, Shanghai 200062, China;4. Department of Education InformationTechnology, East China Normal University, Shanghai 200062, China)
Abstract: As a result of ongoing advances in artificial intelligence technology, the potential for learning analysis in teaching evaluation and educational data mining is gradually being recognized. In classrooms, artificial intelligence technology can help to enable automated student behavior analysis, so that teachers can effectively and intuitively grasp students’ learning behavior engagement; the technology, moreover, can provide data to support subsequent improvements in learning design and implementation of teaching interventions. The main scope of the research is as follows: Construct a classroom student behavior dataset that provides a basis for subsequent research; Propose a behavior detection method and a set of feasible, high-precision behavior recognition models. Based on the global features of the human posture extractedfrom the Openpose algorithm and the local features of the interactive objects extracted by the YOLO v3 algorithm, student behavior can be identified and analyzed to help improve recognition accuracy; Improve the model structure, compress and optimize the model, and reduce the consumption of computing power and time. Four behaviors closely related to the state of learning engagement: listening, turning sideways, bowing, and raising hands are recognized. The accuracy of the detection and recognition method on the verification set achieves 95.45%. The recognition speed and accuracy of common behaviors, such as playing with mobile phones and writing, are greatly improved compared to the original model.
Keywords: learning behavior recognition; pose estimation; object detection; computer vision; deep learning
0 引言
随着政府、教育部门与学术认证机构开始鼓励学校塑造以证据为本的决策与革新制度 , 学习分析技术在决策辅助与教学评估等层面都展现出了很大的优势. 在融入了人工智能、机器学习中的相关算法与技术后 , 学习分析达到了更高的分析精度.
学生的学习投入度能够帮助学校更好地认识学生学习的质量. 评价一所大学教育质量的核心要素就是学生的学习投入程度[1]. 学生课堂行为作为学习投入的重要组成部分 , 一直以来备受研究者的关注.传统的学生课堂行为评价是以人工观察记录实现的 , 效率低下.在人工智能蓬勃发展的今天 , 尝试着借助人工智能技术来改善这一现状. 了解学生在课堂学习过程中的学习行为、学习状态已成为目前教育发展的重要课题 , 将推动教育分析系统智能、高效、全面发展.
为了推动学生课堂行为数据采集方法的创新 , 本研究选取安装了摄像设备的6 间教室 , 在计算机视觉技术的支撑下分析课堂教学视频 , 为教师掌握学生的学习投入状态、优化教学设计、实施教学干预提供数据支撑.
鉴于目前尚无公开的学生课堂行为数据集 , 本文采集了6 间教室的视频数据 , 并对该数据进行处理 , 制作数据集.基于计算机视觉技术 , 提出了一套多阶段的学生课堂行为识别方法.因为学生的课堂行为动作幅度变化不大 , 且在视频图像中 , 学生与学生之间会产生重叠遮挡现象 , 这都给行为识别造成了不小的困难. 利用 OpenPose[1]人体关键点检测算法 , 获取学生关键点数据 , 输入卷积神经网络进行学习 , 得到姿态分类器 , 能够实现对学生低头、正坐、侧身和举手行为的识别分类. 另外 , 学生课堂行为常常与交互物体紧密相关 , 例如玩手机、书写行为. 这2 种行为提取的人体关节图相似, 无法直接使用骨骼关键点来判断 , 所以在进行这2种行为识别时 , 将手部区域作为行为识别最关键的语义信息.现有模型加载和处理速度较慢 , 难以实现对学生课堂行为的实时检测 , 本文利用模型剪枝的 YOLO v3[2]算法进行手部检测 , 融合人体姿态信息后进行级联分类网络 , 实现对玩手机和书写行为的实时检测 .本文实验基于学生在课堂教学中表现的真实视频数据 , 对算法模型的准确性和处理速度进行了评估, 得到了较好的结果.
1 文献综述
人体行为按照复杂程度可分为4 类 , 分别是姿态、个体动作、交互动作和团体活动[3]. 姿态是人体基础部分的移动 , 如举手、站立.此类行为复杂程度最低.个体动作是多个姿态的组合, 如跑步、跳高等行为[1]. 交互动作包括人和人之间以及人和物体之间 , 如玩手机、握手等.团体活动是指在一个场景中包含多个人和多个物體的活动 , 如会议室开会、马拉松比赛等.课堂场景下学生的行为不仅包括与姿态有关的基础动作 , 例如举手、侧身、低头等;而且涵盖了人与物体之间的交互动作 , 例如写字、玩手机等. 对视觉的行为识别通常包括对行为的表征和对目标的检测. 人体关节行为表征方法是通过姿态估计获取人体各个关节点的位置信息和运动信息 , 然后对人体行为进行表征.多人二维关键点检测算法按照检测人体和检测人体关键点的先后顺序 , 分为自上而下和自下而上2 种. 自下而上最经典的方法 OpenPose 首先根据热力最大值检测身体部位的关节点 , 连接后得到人体姿态骨架 , 并且提出了人体亲和力场 , 实现对关节点的快速连接.在图像中人数增加的情况下 , OpenPose 算法依然能够保持高效率、高质量产生人体姿态检测的结果 , 具有很强的鲁棒性.
目标检测算法能够定位图像物体的位置 , 并给出分类结果 , 如图 1所示. R-CNN (Region with CNN features)[4]系列算法将候选区域与卷积神经网络相结合 , 由此衍生出处理速度更快、精度更高的算法 Fast R-CNN[5]和 Faster R-CNN[6]. 这类算法优势在于精度较高 , 但是检测速度较慢 , 满足不了实时性. Redmon 等[7]将生成候选框与回归合为1 个步骤, 提出一系列代表性的算法如 YOLO v2、YOLO v3算法.本文对 YOLO v3模型进行剪枝处理 , 在保证精确度的情况下 , 进一步减少模型参数 , 提升处理速度, 减少计算资源和时间消耗 , 方便模型的部署.
Saneiro 等[8]利用深度卷积神经网络分析学生课堂表情 , 将学生的情绪分为悲伤、快乐、中性、愤怒、厌恶、惊讶、恐惧. Saneiro 等[8]利用 Cohn-Kanade (CK+)[9]面部图像数据库进行深度网络模型预训练 , 然后针对自己的应用场景迁移网络. Lei 等[10]提出了一种多特征的学生动作识别方法 , 该方法由局部对数欧氏多元高斯(L2EMG)[11]和尺度不变特征变换(SIFT)[12]组成.林灿然等[13]利用人体关键点信息和 RGB (Red-Green-Blue)图像对学生举手、起立和端坐这3 种行为进行识别. Li 等[14]收集真实的智能课堂环境视频数据 , 制作学生课堂动作识别数据库 , 利用传统机器学习方法和卷积神经网络对数据库进行了基准实验. Sun 等[15]针对自建的课堂学习数据库 , 利用 C3D (Convolution 3D)[16]网络实现了对学生的动作识别. 这类方法没有利用姿态信息和交互物体信息 , 行为识别的种类并不多 , 精度普遍较低 , 处理速度较慢 , 深度网络模型随着网络层数的增加还容易造成过拟合现象 , 计算资源的消耗较大.
2 本文方法
本文利用 H 大学所采集的视频数据 , 建立了学生课堂行为数据集 E-action.该数据集包含了在6 间标准教室的高清摄像头所采集的课堂视频数据 , 视频分辨率为(4096× 2160)像素.基于此数据库 , 本研究将行为分析分为2 个阶段. 第1 阶段 , 利用 OpenPose 人体姿态估计算法提取人体关键点 , 对举手、正坐、侧身和低头4 种主要行为进行识别. 第2 阶段, 考虑到学生玩手机时手与手机有交互行为 , 书写时手与笔有交互行为 , 基于“人-物交互”的方法, 使用 YOLO v3算法训练手部检测模型, 并进行剪枝操作 , 对学生手部区域进行目标检测. 所提取的手部区域信息融合第1 阶段的姿态信息后 , 输入卷积神经网络进行训练 , 从而识别学生玩手机和书写行为. 该方法同时具备速度快和准确率高 , 具有较好的适应性. 整体流程如图 2所示.
2.1 E-action 行为数据集
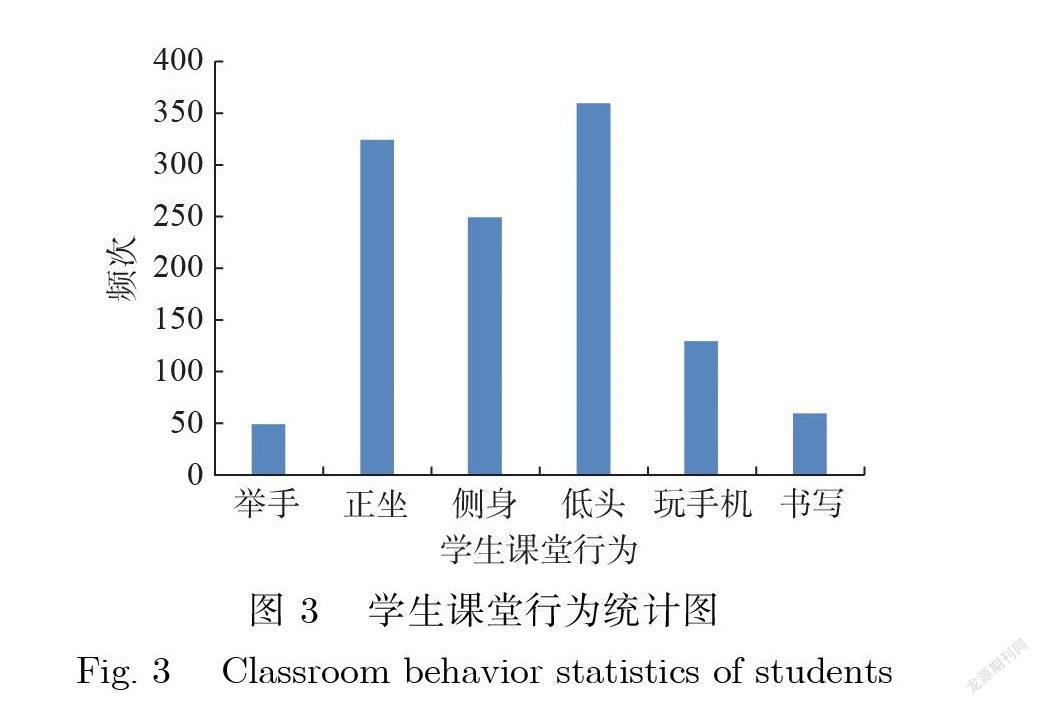
对 H 大学的6 间标准化教室所收集的视频总计容量超过200 GB.对在校大学生的课堂行为进行抽样调查 , 课堂行为所出现的频次如图 3所示 , 发现举手、正坐、侧身、低头、玩手机、书写是较高频率出现的学生课堂行为.
首先 , 定位视频中每个学生的位置 , 记录矩形框中最左上角和最左下角的位置坐标 x 和y .然后 , 把单个学生从整个场景中切割出来 , 得到单人视频. 对于每一个学生的单人视频 , 都需要标注出分类动作的开始时间和结束时间. 整个数据集包含6 个文件夹 , 分别代表每一类行为的视频集合.最后 , 对视频进行抽帧处理 , 把视频转化为图片 , 由图片集合和图片标注组成数据集供后续实验使用.
2.2 学生课堂关键点检测
由于骨骼构造的特点 , 人体姿态丰富多样. 一般地 , 关节的改变会带来姿态动作的变化 , 这对姿态估计和动作检测有很大的帮助.但是在现实应用场景中 , 从视频图像中获取信息还受到各种环境因素的影响 , 例如光照、物体遮挡、背景干扰、识别角度等.通常学生坐在自己的位置上 , 腿部和脚部的关键点对于本文所需要识别的常见课堂行为不产生直接影响 , 学生在课堂教学中的人体关键点的示意图如图4所示.
OpenPose 作为自下而上的人体姿态估计算法 , 在处理速度和精度上都有明显的优势. 它利用人体亲和力场 , 实现同场景下多人人体姿态估计. 由于在课堂场景下 , 学生座位相邻会出现肢体遮挡的现象 , 这对动作检测有一定的干扰 , 相比自上而下的检测算法 , OpenPose 算法还具有更高的鲁棒性和准确率 , 适用于真实教室场景下的视频处理.本文选择 OpenPose 算法对课堂视频中的学生进行人体姿态估计.
将训练集输入 OpenPose 网络 , 得到人体关键点图( 图5). 图5是学生课堂姿态信息的反映 , 姿态主要可以分为正坐、侧身、低头和举手. 正坐和举手姿态可认为是认真听课的表现 , 低头和侧身通常同不专心的行为产生联系, 例如低头玩手机、交头接耳等行为. 给这4 种姿态的图片加上标签 , 形成骨架关键点的学生动作数据集.
在完成分类任务上 , VGGNet[17]网络和 ResNet[18]网络均有明显的优势 , 但是此类网络在设计的过程中朝着深度和复杂度提高的方向发展, 使得网络规模复杂且参数量庞大, 严重影响算法的处理效率.本文在人体姿态估计的基础上增加了一个小型的6 层网络 , 对正坐、侧身、低头和举手这4 类动作进行分类. 它有3 个卷积网络和3 个完全连接层 , 无需预训练 , 在不影响实时性的基础上有效提高了动作分类的精度 , 卷积层表示为(卷积核个数 , 行数 , 列数 , 通道数), 网络结构如图 6所示.
2.3 学生手部动作检测
利用骨架关键点的信息识别学生课堂行为 , 虽然排除了背景冗余信息对识别效果的影响 , 但同时也可能误删关键的语义信息. 例如 , 玩手机和书写等行为的交互对象(手机和笔等)對学生课堂行为识别具有决定性的作用.通过 YOLO v3算法提取手部区域 , 将行为识别的注意力集中在手部区域 , 对手部区域进行检测 , 结合人体姿态估计的分类标签和手部区域目标检测图的特征进行识别. 这不但能够减少相似行为的错误分类 , 也能够排除身体其他部位或者学生之间互相遮挡的影响. YOLO v3算法作为目标检测器 , 实现对手部区域的快速检测 , 如图 7所示.
YOLO v3对中小目标的检测效果突出, 它在特征提取上选择图片的全局区域进行训练 , 加快速度的同时能够更好地区分目标和背景.不同卷积核的功能不同 , 多个卷积核交错进行 , 实现降维和对特征的提取.
2.4 手部区域检测模型压缩
手部检测要求较好的检测效果和较快的检测速度 , 本文方法针对学生课堂行为进行检测 , 反馈学生学习的投入度 , 对检测手部区域进行分类的算法要求网络具有有较高的实时性 , 因此采用模型剪枝的方法对手部区域检测模型进行压缩 , 能提高算法运行速度.
在使用深度学习算法时 , 预测结果通过参数计算和推理得出. 由于许多参数是冗余的 , 所以可以实现在保持最优参数的同时 , 压缩参数空间 , 达到和原始参数空间相同的效果.这有助于在没有影响精度的前提下 , 通过压缩模型来缩短处理时间和减小所占体积. 首先 , 对 YOLO v3模型进行稀疏训练 .稀疏训练的想法是为每个通道引入缩放因子g, 并将其与通道输出相乘.然后 , 联合训练网络权重和缩放因子g.最后, 将缩放因子较小的通道直接移除, 微调剪枝后的网络. 整个框架的目标函数定义为
式(1)中:(x; y )代表训练数据和标签; W 是网络的可训练参数; l 是 CNN 的训练损失函数; f 为预测标签; 是平衡因子; g () 是缩放因子的惩罚项; 是函数空间域.
在 YOLO v3稀疏训练的过程中需要利用 Batch Normalization (BN)[19]层加速模型收敛 , BN 层批量标准化公式为
式(2)中: 和分别是输入特征和方差;2 是可训练的缩放因子和偏差;" 是为避免0 除而设置的较小数 , 能够让整个网络模型计算的额外开销尽可能小; 参数是 BN 层的缩放因子. BN 层的剪枝示意图如图 8所示.
剪枝结束后的轻量级网络模型需要通过微调来提升网络的精度.在不影响精度的情况下 , YOLO v3算法能够对在课堂教学中学生的手部区域实现更快速的检测 , 通过训练所得到的模型体积更小 , 方便模型的部署.
2.5 姿态融合的手部动作分类
将目标检测模块定位到手部坐标位置后 , 截取原图中手部局部图片 , 输入上文所提到的小型分类网络 , 提取手部局部图片的特征, 将模型的注意力集中在手部位置, 再结合OpenPose 人体姿态估计算法的处理结果, 添加学生的姿态信息, 对检测的行为进行约束, 提高了对学生在课堂教学中玩手机、书写等行为的识别精度.本文人体姿态估计模块和手部区域检测模块是并行处理的 , 在融合2 者特征后分类的时间是线性相加的 , 分类模块的处理速度也同样影响到总体框架的速度. YOLO 系列作为经典的目标检测算法 , 其本身就拥有目标分类算法部分.在本实验中 , 因为全局图片的信息对于行为分类会产生冗余作用, 所以只针对手部区域信息对学生课堂行为进行分析, 同时对关键点信息做姿态检测. 因而仍然采用2.2节中所提到的小型网络进行分类 , 在保证实时性的前提下, 最大限度地提高分类效率.
3 实验结果与分析
3.1 实验准备
采集6 间教室每天的课堂视频作为数据源.后台对超过200 G 的数据进行筛选统计 , 总共采集数据 300人次(男生173人次 , 女生127人次 , 含大學生) , 对视频中具有识别分类的动作进行人工筛选和数据标注.以 10 s 为单位, 对原始视频进行剪辑 , 生成原始视频数据集.考虑到课堂场景下学生的常见姿态可以分为低头、侧身、正坐和举手 , 从原始视频数据库里挑选出这4类视频并按帧进行切分 , 每张图片的分辨率为(4096× 2160)像素. 考虑到训练数据的平衡性 , 对视频库进行筛选 , 最终得到的图片共5 500张 , 其中正坐1 600张、侧身1 400张、低头1 400张、举手1 100张 .姿态数据集的样例如图9所示.
手部动作数据集所采集的图片合计4 000张 , 其中训练集3 200张、测试集800张 .为实现手部动作分类 , 手部动作数据集分成3 个子类 , 其中常规行为图片2 400张、玩手机动作800张、书写动作800张 .手部动作数据集如图 10所示.
为了扩充课堂场景下学生手部区域数据集、提高对不同姿态的手部识别的鲁棒性 , 将数据集进行了几何增强.所采用的方式是平移、翻转、旋转、镜像等 , 效果如图 11所示.
人工智能技术可以帮助研究者拓展学生行为数据收集的渠道并提升数据收集及处理的效率. 用 FFmpeg 将实际所采集的学生课堂视频截取成视频帧图像 , 然后采用 OpenPose 人体姿态估计算法得到每个学生的人体骨骼关键点(x; y )并记录. 针对其中一个学生的所有人体关键点进行分析 , 将关键点的横坐标和纵坐标进行排序 , 得到横坐标的最大值xmax 和最小值xmin 以及纵坐标的最大值ymax 和最小值ymin , 再按单个学生的人体区域大小占总场景图像的比例进行扩充 , 从而能够在整个课堂场景的视频帧中截取得到单个学生区域的图像 , 以便对单个学生检测定位和行为识别分析 , 如图12所示.通过这种方式能从整个教室场景的视频数据中获取大量的单个学生的图片数据.
本实验的操作系统为 Ubantu 16, GPU 为 titian V, 显存为36 G, 深度网络模型框架基于 Pytorch 框架实现.
3.2 在课堂教学中动作姿态检测与分类
利用 OpenPose 算法处理人体动作数据集 , 获取低头、侧身、正坐和举手4类动作的人体骨架图 , 具体示意图如表1所示.
将该数据集输入上述的小型 CNN (Convolutional Neural Network)分类网络进行训练 , 模型在测试集(骨架图)上的准确率与本文所采集的图像直接训练(原图)的准确率、利用 IDT (Improved Dense Trajectories)[20]算法处理后的图像准确率和利用 C3D 算法处理后的图像准确率作对比 , 结果如表2所示.
IDT 基于人工选取特征的方法 , 取密集轨迹点的 HOG (Histogram of Oriented Gradient)特征、 HOE (Histogram of spatiotemporal Orientation Energy)特征、 MBH (Motion Boundary Histograms)等局部特征进行分类 , 效率较低. C3D 首先关注前几帧的外观 , 并跟踪后续帧中的显著运动 , 但是学生课堂行为幅度较小 , 很难捕捉到运动信息 , 并且只关注了颜色特征 , 并没有关注骨骼特征 , 所以精度偏低.利用所提取的骨架图判别原图动作的方法 , 消除了背景和人物重叠信息的干扰 , 提高了分类精度. 在测试数据集上动作分类网络的最高测试精度达到95.45%.
3.3 手部检测实验
利用 YOLO v3算法对手部区域进行提取 , 考虑到运行速度和模型的部署 , 在此模型基础上做剪枝 .首先对手部数据集做正常训练 , 得到平均准确精度 mAP (mean Average Precision)为 0.8195.然后采用全局稀疏训练 , 在总的周期的0.7和 0.9阶段进行学习率为0.1的衰减 , scale 参数默认为0.001.
根據稀疏的 BN 层的 g 权重对网络进行剪枝 , 直连层和相关的前2 层的 CBL (Conv + BN + Leaky Relu)层会被剪枝 , 因此总共剪掉48层 , 相应层的 ID 为 [66, 67, 68, 69, 70, 71, 72, 73, 74, 63, 64, 65, 38, 39, 40, 50, 51, 52, 47, 48, 49, 44, 45, 46, 13, 14, 15, 53, 54, 55, 41, 42, 43, 16, 17, 18, 6, 7, 8,19, 20, 21, 56, 57, 58, 22, 23, 24].
稀疏训练后进行通道剪枝 , 通道剪枝的阈值设置为0.85, 每层最低保持通道数比例为0.01, 再对剪枝后的模型进行微调 , 提高精度.
表 3表明 , 在该数据集上对 YOLO v3网络进行剪枝操作后 , 各项性能大幅提升.模型的参数量为原先的17.72%, 模型压缩率为82.2%, 在titian V 上处理时间缩短了49.40%, 同时各类别的 mAP 基本保持不变. 因此剪枝后的模型可作为本文算法框架中动作分类模块的基准网络.
3.4 手部动作分类实验
筛选目标检测处理后的手部区域, 得到玩手机、书写的图片, 构建训练数据集.将手部行为分为玩手机、空手和书写3 个分类 , 输入上文所提到的 CNN 卷积神经网络进行训练得到手部动作分类器.训练的参数学习率设置为10–4 , 时期设置为200, 批大小设置为128, 整个网络使用随机梯度下降进行训练而得到.最终在测试集上 , 对玩手机和书写这2种行为的检测准确率分别为92.9%和 87.9%, 如表 4所示.
得到手部区域的动作分类后 , 用学生的姿态信息进行约束 , 从而将全局特征和局部特征相结合 , 排除拿笔和拿手机听课这些行为的干扰 , 从而提高识别学生低头玩手机和低头书写行为的精度, 如表 5所示.
为了验证结合手部区域特征和全局动作特征后的学生课堂行为识别的准确率和运算效率 , 证明本文所提出方法的有效性 , 选取新录制普通教学班的课堂视频数据集 , 进行200组实验 , 其最终识别的实验结果如表6所示, FPS (Frames Per Second)表示模型平均每秒能处理的图像帧数.
实验表明 , 融合姿态信息后的行为识别的精度相比手部区域图片分类有所提升 , 所采用的学生课堂行为识别算法完全达到准确率和运算效率的要求.
课堂行为识别的数据标签有可能会出现歧义性 , 给模型训练过程中的收敛带来很大的问题. 损失函数表示模型对某个样本的预测标签和真实标签的差异 , 可以衡量模型对该样本的学习情况. 对损失函数 loss 的排序情况进行检查 , 如果 loss 值较大 , 则该样本标签有可能出现错标或者本身图片的行为带有歧义性, 对于这种数据最好的处理方式是手工剔除.从而排除相似行为的干扰 , 提高识别的准确率.
4 结论
本文利用深度学习与计算机视觉技术 , 研究了学生课堂行为识别的方法.创建了在真实场景下的学生课堂行为数据集 , 通过全局姿态识别和局部姿态识别 , 获得学生行为分类的模型 , 并且对模型进行了压缩 , 得到一个高效且高精度的行为识别系统. 经测试 , 系统得到了较好的结果 , 可以实现课堂行为的自动化检测. 这对于衡量学生学习投入、教师优化教学设计与实施教学干预 , 以及学生开展自适应学习都具有重要意义. 未来将利用图卷积神经网络在视频的时间和每一帧的图片空间维度上进行处理 , 进一步提高学生课堂行为分类的准确率.
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)