目录
- 一、概述
- 1.1 智能制造和飞桨
- 1.2 Paddle Inference工业级应用部署工具
- 二、算法训练和导出
- 2.1 任务概述和实现原理
- 2.2 训练和静态模型导出
- 三、部署环境准备
- 四、Windows下C++工程编译和运行
- 4.1 工程创建
- 4.2 配置OpenCV
- 4.3 配置Paddle Inference、cuda和tensorrt
- 4.4 核心代码分析
- 4.5 完整推理
- 五、MFC工程调用
- 5.1 基于C++的dll制作
- 5.2 MFC工程中调用
- 六、C#工程调用
- 6.1基于C++的dll制作
- 6.2 C#中调用dll
- 七、完整代码链接
一、概述
1.1 智能制造和飞桨
制造业作为国民经济主体,是国家创造力、竞争力和综合国力的重要体现。作为制造强国建设的主攻方向,智能制造发展水平关乎我国未来制造业的全球地位。与此同时,面对供应链环境不确定性的增加、人力等运营成本的逐渐攀升、“双碳”战略之下能源转型的迫切要求,制造业想要实现高质量发展,迈向中高端水平,不仅需要从低附加价值领域向高附加价值领域两端延伸,更重要是需要加快人工智能等核心技术规模化应用落地。在此背景之下,如何利用好人工智能这把利剑,加快新旧动能转换,实现传统生产方式的转型升级,也成为每个制造企业不得不思考的问题。目前,在AI工业大生产阶段,深度学习技术的通用性越来越强,深度学习平台的标准化、自动化和模块化特征越来越显著,深度学习应用越来越广泛且深入,已经遍地开花。
目前,以飞桨为代表的人工智能平台在制造业的落地主要集中在工业视觉、工业设备监控、数据智能和物流仓储等应用场景,在研发设计、优化生产工艺和排期、设备运维、智能供应链等环节发挥着“智眼”和“大脑”的支撑作用。工业视觉检测作为保障产品质量的重要环节,被广泛应用在钢铁、汽车、3C 电子、印染纺织等众多领域。在AI出现之前,往往是依赖人工检测或者使用传统图像处理算法。人工检测效率低,成本高,且容易收到认为主管因素影响,传统图像处理算法对于复杂场景鲁棒性差,而随着卷积神经网络为代表的AI算法出现,有效地解决在复杂场景检测的能力,在实际的项目过程中对目标识别具有更好的普适性。
1.2 Paddle Inference工业级应用部署工具
在工业级深度学习实践领域中,我们经常能听到一种说法——模型部署是打通AI应用的最后一公里!想要走通这一公里,看似简单,但是真正实践起来却困难重重。显卡利用率低、内存溢出、多线程调度奔溃、tensorrt加速算子不支持等等问题一直是深度学习模型最后部署的老大难问题。这时,我们就可以选择Paddle Inference部署工具。
Paddle Inference 是飞桨的原生推理库,可以提供高性能的工业生产级推理能力。一般的企业级部署通常会追求更极致的部署性能,且希望能够在生产环境安装一个不包含后向算子,且比主框架更轻量的预测库,Paddle Inference应运而生。Paddle Inference提取了主框架的前向算子,可以无缝支持所有主框架训练好的模型,且通过内存复用、算子融合等大量优化手段,并整合了主流的硬件加速库如Intel的oneDNN、NVIDIA的TensorRT等, 提供用户最极致的部署性能。此外还封装C/C++的预测接口,使生产环境更便利多样。
有了这样一套部署工具,我们开发工业智能产品就非常简单了。一般的,我们可以基于Python语言使用PaddlePaddle来实现模型训练(可以使用一些套件库来加速模型研发,例如PaddleClas、PaddleDetection、PaddleSeg等),然后再使用C++语言利用Paddle Inference库实现工业生产环境的高效稳定部署。
本篇博文重点介绍如何利用飞桨Paddle Inference工具在windows 10平台上实现工业级深度学习应用部署,对相关的算法原理只做基本介绍。
二、算法训练和导出
2.1 任务概述和实现原理
本教程使用PP-LiteSeg模型对工业质检场景下的缺陷进行精细分割,实现像素级的工业缺陷检测任务。下图左边是原图,右边是分割图片,缺陷区域使用绿色表示,其他区域使用红色表示。

PP-LiteSeg模型是PaddleSeg团队自研的轻量级语义分割模型,模型结构如下。
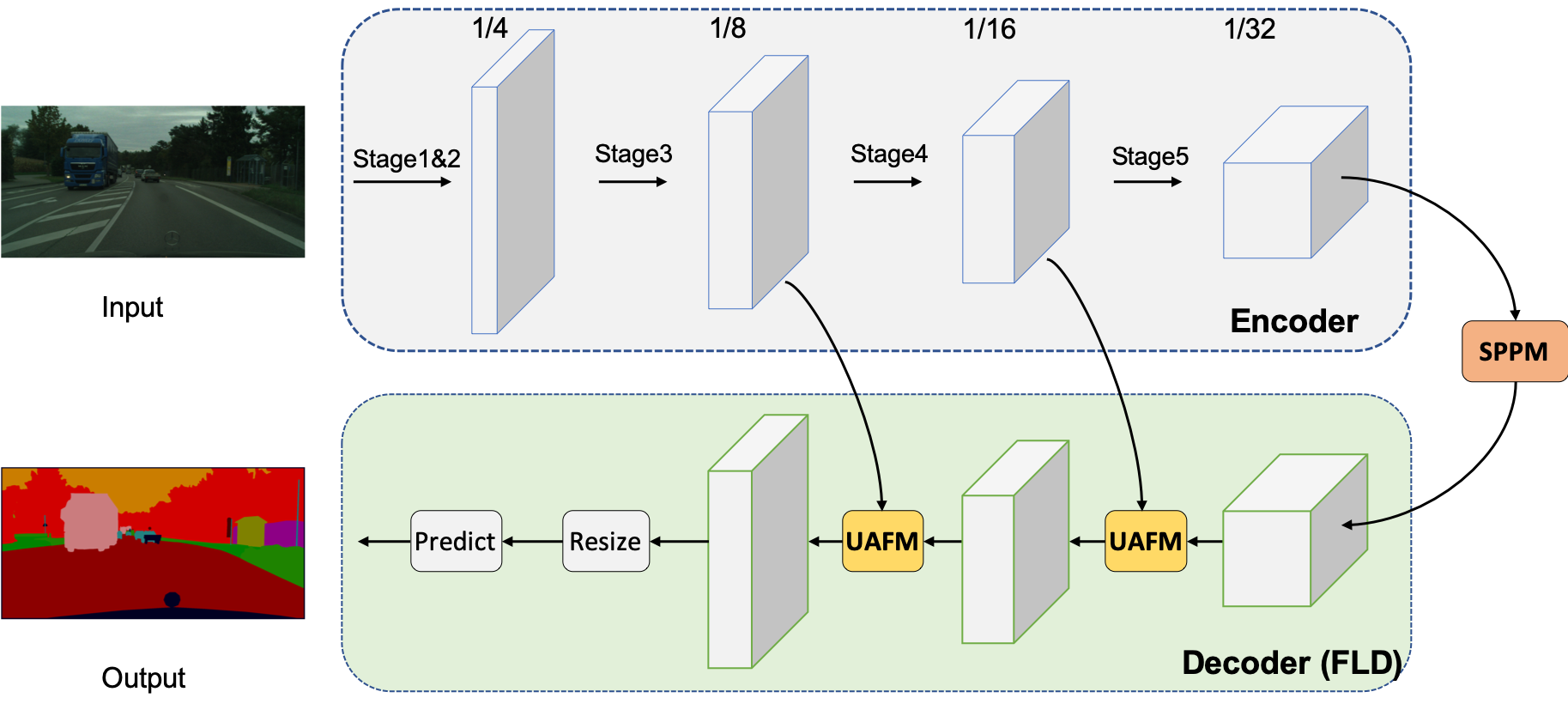
PP-LiteSeg模型更详细的原理介绍请参考官网链接。
2.2 训练和静态模型导出
本项目使用的工业质检瑕疵分割数据集,包含3类目标和1类背景。其中训练集:691张图像,验证集:86张图像,测试集:87张图像。数据集格式如下:
defect_data
├── Annotations
├── JPEGImages
├── test.txt
├── train.txt
└── val.txt
完整的训练、推理和导出代码在Ai Studio上已给出(链接),读者只需要folk即可运行。
在实际工业使用时,可以根据模型的大小以及速度要求来选型,然后只需要替换模型配置参数重新训练即可。因此,使用PaddlePaddle的相关算法套件可以很快速的完成模型开发、训练和验证工作。
整个训练时间大概耗时1小时,最终推理结果如下所示:

本项目实例在yml文件中iters设置为8000,在实际测试时发现远没有到达最佳精度位置(mIoU=0.5917),可以增加iters延长训练时间来获得更高的检测精度。尽管如此,从推理结果上看整体检测效果还是可以的,基本能够检测出对应的缺陷区域。
为了方便后面进行工业级的部署,PaddleSeg提供了一键动转静的功能,即将训练出来的动态图模型文件转化成静态图形式(只有转成静态图模型才能用C++推理)。
output
├── deploy.yaml # 部署相关的配置文件
├── model.pdiparams # 静态图模型参数
├── model.pdiparams.info # 参数额外信息,一般无需关注
└── model.pdmodel # 静态图模型文件
如果读者想深入学习如何根据算法建模、如何调参、如何高效训练等技术,请参考飞桨语义分割官方教程.(官方教程包含的案例非常丰富且步骤详细,本文不再赘述)。
三、部署环境准备
我们最终需要使用Paddle Inference工具将前面导出的模型实现Windows平台上的C++推理。因此,我们首先需要配置基本的PaddleInference环境。Paddle Inference官方下载网址。在下载C++预测库的时候,我们需要记住对应的当前版本配置环境。
如下图所示:
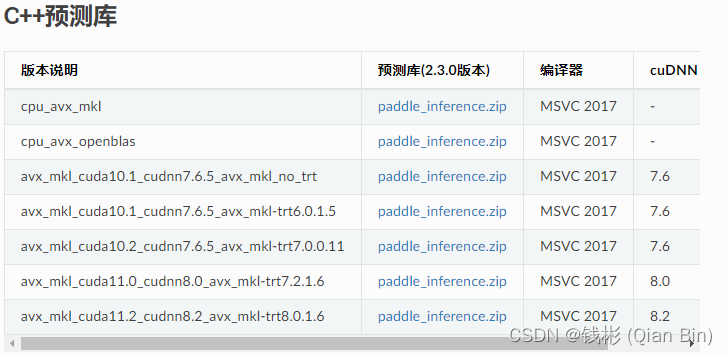
考虑到版本的适应性,我们可以选择vx_mkl_cuda10.2_cudnn7.6.5_avx_mkl-trt7.0.0.11进行下载使用。这个版本对应的cuda是10.2,cudnn是7.6.5,tensorrt库是7.0.0.11。其中尤其需要注意cuda和cudnn,如果这个预测库版本需要的cuda和cudnn跟我们当前电脑已经装好的cuda和cudnn版本不一致,并且在预编译好的预测库中没有我们当前电脑环境的版本,那么只有两种解决方法:一种就是卸载掉当前cuda和cudnn重新安装适配版本;另一种就是按照官方教程自行编译paddle inference。一般来说,自行编译paddle inference会遇到不少问题,这种解决方案的代价比较大。如果cuda和cudnn版本不一致,个人建议还是重装cuda和cudnn会更方便一些。安装好以后我们在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64目录下(此处注意版本的一致性,我们下载的paddle_inference是cuda10.2的,所以这里引用的cuda目录也要对应着10.2),然后将其中的所有的lib文件复制出来,复制到d:/toolplace下的cuda目录,这个cuda目录就是专门用于存放cuda的lib文件的
另外,本文需要使用opencv加载和预处理图像,因此需要安装好opencv。这里可以选择比较新的OpenCV4.5.5对应的windows版本下载,下载后运行解压,将opencv文件夹放置在统一的名为toolplace的目录下。
全部下载好以后我们可以将所有的环境库单独放置在统一的名为toolplace的目录下,方便我们后期配置,如下图所示:

四、Windows下C++工程编译和运行
4.1 工程创建
本小节将使用VS2019来创建一个C++控制台工程,名称为PaddleDemo,在这个工程里面实现基于C++的工业瑕疵分割推理。如下图所示:

创建完成后我们重新设置生成项目为Debug,并且是64位(必须是构建64位程序),如下图所示:

然后将项目编译运行一下确保Visual Studio基本环境没有问题。
接下来进行项目配置。
4.2 配置OpenCV
首先配置一下opencv使得能够正常的在程序中加载图像。单击菜单栏“项目”-“属性”,然后单击左侧“VC++目录”,在右边包含目录中添加如下路径:
D:\toolplace\opencv\build\include
D:\toolplace\opencv\build\include\opencv2
在库目录中添加:
D:\toolplace\opencv\build\x64\vc15\lib
如下图所示:
然后单击左侧“链接器”—“输入”,在右侧附加依赖项中添加opencv对应的lib文件:
opencv_world455d
如下图所示:

注意这里我们链接的是debug版本的opencv库,如果我们生成的是release版本的,则需要链接opencv_world455.lib文件。
最后将D:\toolplace\opencv\build\x64\vc15\bin目录下的opencv_world455d.dll文件拷贝到PaddleDemo工程的根目录下面。然后我们找张测试图片,命名为test.png也放置在PaddleDemo工程的根目录下面,如下图所示:

下面打开PaddleDemo.cpp主文件,编写C++图像调用代码测试下:
//导入系统库
#include <iostream>
//导入opencv库
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace cv;
int main()
{
Mat img = imread("test.png",cv::IMREAD_COLOR);
namedWindow("test");
imshow("test", img);
waitKey(6000);
return 0;
}
按ctrl+F5运行,如果没有问题会显示test.png图片,如下图所示:
4.3 配置Paddle Inference、cuda和tensorrt
本小节我们将来配置Paddle Inference并使用GPU进行推理。Paddle Inference文件夹中主要包含paddle原生推理库和third_party第三方依赖库。由于依赖库比较多,我们可以抽取必要的进行引入。但是在初期调试的时候,建议将所有依赖库全部引入进来,等后期完成开发了再逐步剔除,这样不容易出问题。
单击菜单栏“项目”-“PaddleDemo属性”,打开属性页面,然后在左侧单击“VC++目录”,在右侧“包含目录”中继续添加如下路径:
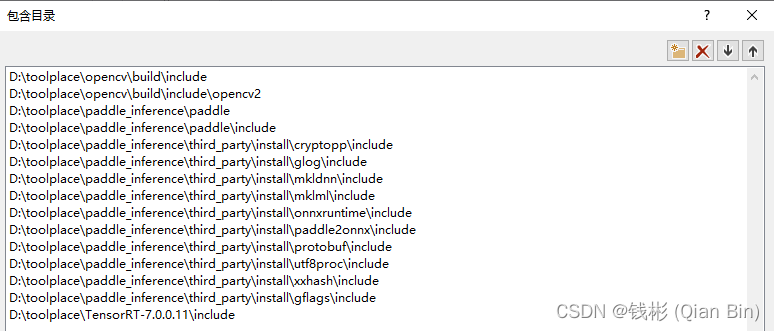
具体修改方式对照着自己的包存放路径来设置。然后在库目录里面添加如下库:

最后,单击左侧“链接器”—“输入”,在附加依赖项中输入如下lib文件:
opencv_world455.lib
paddle_inference.lib
cryptopp-static.lib
glog.lib
gflags_static.lib
mkldnn.lib
libiomp5md.lib
mklml.lib
onnxruntime.lib
paddle2onnx.lib
libprotobuf.lib
utf8proc_static.lib
xxhash.lib
cudart.lib
cublas.lib
cudnn.lib
myelin64_1.lib
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
为了能够在工程中运行深度学习模型,我们将前面动转静得到的model.pdiparams和model.pdmodel放置在PaddleDemo项目根目录下的model文件夹中,然后将前面各个配置文件夹下面的dll文件也拷贝到当前项目根目录下面,最后根目录文件如下所示:

4.4 核心代码分析
//导入系统库
#include <iostream>
//导入opencv库
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
//导入paddle库
#include <paddle_inference_api.h>
using namespace cv;
上述代码主要引入paddle inference对应的库头文件paddle_inference_api.h以及opencv库对应的三个文件,最后定义一下命名空间cv。
//模型预测器
std::shared_ptr<paddle_infer::Predictor> g_predictor;
//目标推理图像对应的宽高
int target_width = 512;
int target_height = 512;
// 归一化对应的均值和方差
std::vector<float> g_fmean;
std::vector<float> g_fstd;
上述全局变量中最关键的是定义了全局的深度学习预测器g_predictor,这是一个paddle_infer::Predictor类的指针变量,后面所有的推理都需要这个变量。由于我们真实工业场景中加载一次模型是比较耗时的,因此,一般情况下我们定义这样一个全局变量,在程序初始化时加载一次,后面就可以一直使用这个加载后的模型预测器进行推理,直到程序退出才释放这个模型。
- 主函数main
主函数部分首先使用自定义的init函数初始化深度学习推理环境,然后读取一张待预测图片,然后交给predict函数进行预测,由于我们这个模型是一个语义分割模型,输入是图片,输出也是图片,因此这里的predict函数输出是mask,最后保存mask图片即可。
int main()
{
//初始化环境
init();
//加载图像和预处理
Mat img = imread("test.png",cv::IMREAD_COLOR);
Mat mask = Mat(img.rows, img.cols, CV_8UC1);
//开始推理
predict(img, mask);
//保存掩码结果
imwrite("result.jpg", mask);
std::cout << "处理完成" << std::endl;
return 0;
}
- 初始化深度学习推理环境init
参照paddle inference官网,初始化深度学习部署环境主要就是创建配置器config,然后通过config.SetModel将训练好的静态图模型导入。如果使用GPU预测可以使用config.EnableUseGpu和config.EnableMemoryOptim来设置。考虑到后期tensorrt加速,可以使用config.EnableTensorRtEngine来开启tensorrt,但是刚开始的时候建议不要开启tensorrt,因此有可能会推导不成功,后期需要使用config.SetTRTDynamicShapeInfo来设置关键节点的动态图形状才能保证tensorrt正常推理。最后,我们手工赋值一下归一化需要使用的均值和方差。
void init() {
// 创建默认配置对象
paddle_infer::Config config;
config.SetModel("model/model.pdmodel", "model/model.pdiparams");
config.EnableUseGpu(100, 0);
config.EnableMemoryOptim();
//开启tensorrt加速
/*config.EnableTensorRtEngine(1 << 20, 1, 10,paddle_infer::PrecisionType::kFloat32, true, false);
std::map<std::string, std::vector<int>> min_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> max_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> opt_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
opt_input_shape);*/
//创建预测器
g_predictor = paddle_infer::CreatePredictor(config);
//定义预处理均值和方差
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
}
- 推理predict函数
预测部分主要分为预处理、图像转tensor、预测、后处理这样几个步骤。其中尤其需要注意取出数据的部分,需要对照模型真实的最终输出来操作。例如,本文的语义分割模型最后的输出数据格式为int64,因此我们使用std::vector out_data这样的变量来提取数据,否则会报错误。
void predict(Mat& org_img, Mat& mask)
{
//拷贝图像
int orgWidth = org_img.cols;
int orgHeight = org_img.rows;
Mat img = org_img.clone();
//预处理
cvtColor(img, img, cv::COLOR_BGR2RGB);
resize(img, img, cv::Size(target_width, target_height), 0, 0, cv::INTER_LINEAR);
int real_buffer_size = 3 * target_width * target_height;
std::vector<float> input_buffer;
input_buffer.resize(real_buffer_size);
normalize(img, input_buffer.data(), g_fmean, g_fstd);
//转tensor
auto input_names = g_predictor->GetInputNames();
auto im_tensor = g_predictor->GetInputHandle(input_names[0]);
im_tensor->Reshape({ 1, 3, target_height, target_width });
im_tensor->CopyFromCpu(input_buffer.data());
//执行预测
g_predictor->Run();
//取出预测结果
auto output_names = g_predictor->GetOutputNames();
auto output_t = g_predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = 1;
std::cout << "size of outputs[" << 0 << "]: (";
for (int j = 0; j < output_shape.size(); ++j) {
out_num *= output_shape[j];
std::cout << output_shape[j] << ",";
}
std::cout << ")" << std::endl;
std::vector<int64> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
//后处理获得掩码图
std::vector<uint8_t> out_data_u8(out_num);
for (int i = 0; i < out_num; i++) {
out_data_u8[i] = static_cast<uint8_t>(out_data[i]);
}
cv::Mat out_gray_img(output_shape[1], output_shape[2], CV_8UC1, out_data_u8.data());
cv::resize(out_gray_img, out_gray_img, Size(orgWidth, orgHeight));
cv::Mat out_eq_img;
cv::equalizeHist(out_gray_img, mask);
//结束清理
img.release();
out_eq_img.release();
std::vector<int64>(out_data).swap(out_data);
std::vector<uint8_t>(out_data_u8).swap(out_data_u8);
std::vector<float>(input_buffer).swap(input_buffer);
std::vector<int>(output_shape).swap(output_shape);
im_tensor.release();
output_t.release();
}
那么怎么查看我们模型的输出呢?
我们可以使用visualdl工具来查看具体的模型结构,命令如下(需要提前安装好visualdl):
visuladl --model model.pdmodel
- 归一化normalize函数
在前面predict函数中我们使用了normalize来预处理数据,这里主要做两件事,一是将数据从[0,255]转换到[0,1]之间,然后除以均值和方差,另外,还需要将图像按照HWC的排列方式转换为CHW的方式。
void normalize(cv::Mat& im, float* data, std::vector<float>& fmean,
std::vector<float>& fstd) {
int rh = im.rows;
int rw = im.cols;
int rc = im.channels();
double normf = static_cast<double>(1.0) / 255.0;
#pragma omp parallel for
for (int h = 0; h < rh; ++h) {
const uchar* ptr = im.ptr<uchar>(h);
int im_index = 0;
for (int w = 0; w < rw; ++w) {
for (int c = 0; c < rc; ++c) {
int top_index = (c * rh + h) * rw + w;
float pixel = static_cast<float>(ptr[im_index++]);
pixel = (pixel * normf - fmean[c]) / fstd[c];
data[top_index] = pixel;
}
}
}
}
- tensorrt加速问题
在使用tensorrt加速时,经常会有模型因为动态尺寸的问题导致不能使用tensorrt。解决办法其实也很简单,只需要通过config.SetTRTDynamicShapeInfo来设置动态变量的尺寸即可。但是这里有2个核心的问题。
1、我们怎么知道是哪些动态变量需要设置呢?
2、这些动态变量设置多大合适呢?
第1个问题其实不难,因为开启tensorrt之后每次推理一旦报错都会有提示,提示哪些变量目前还没有设置为动态尺寸,我们只需要记住这些变量即可。
第2个问题有点麻烦,我们需要使用visualdl工具来查看模型结构,然后根据动态变量名称查找到指定的节点,然后再推理当前连接线的输入尺寸(上一个节点的输出尺寸)对应的形状,这里往往需要根据邻接的局部网络进行分析。
例如对于变量bilinear_interp_v2_4.tmp_0来说(运行后tensorrt提示该变量需要设置动态尺寸),我们可以通过visualdl来找到它的模型结构,如下图所示:

可以看到这时候这根线当前提示是1x128x?x?,说明有两个维度不清楚,因此我们需要通过局部去推理,在下面的cacat输出是1x4x32x32,因此,我们可以认为bilinear_interp_v2_4.tmp_0的最佳输入是1x128x32x32。其他有问题的节点也按照这种方式推理即可。
4.5 完整推理
//导入系统库
#include <iostream>
//导入opencv库
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
//导入paddle库
#include <paddle_inference_api.h>
using namespace cv;
//定义全局变量
std::shared_ptr<paddle_infer::Predictor> g_predictor;
int target_width = 512;
int target_height = 512;
std::vector<float> g_fmean;
std::vector<float> g_fstd;
void init() {
// 创建默认配置对象
paddle_infer::Config config;
config.SetModel("model/model.pdmodel", "model/model.pdiparams");
config.EnableUseGpu(100, 0);
config.EnableMemoryOptim();
//开启tensorrt加速
/*config.EnableTensorRtEngine(1 << 20, 1, 10,paddle_infer::PrecisionType::kFloat32, true, false);
std::map<std::string, std::vector<int>> min_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> max_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> opt_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
opt_input_shape);*/
//创建预测器
g_predictor = paddle_infer::CreatePredictor(config);
//定义预处理均值和方差
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
}
void normalize(cv::Mat& im, float* data, std::vector<float>& fmean,
std::vector<float>& fstd) {
int rh = im.rows;
int rw = im.cols;
int rc = im.channels();
double normf = static_cast<double>(1.0) / 255.0;
#pragma omp parallel for
for (int h = 0; h < rh; ++h) {
const uchar* ptr = im.ptr<uchar>(h);
int im_index = 0;
for (int w = 0; w < rw; ++w) {
for (int c = 0; c < rc; ++c) {
int top_index = (c * rh + h) * rw + w;
float pixel = static_cast<float>(ptr[im_index++]);
pixel = (pixel * normf - fmean[c]) / fstd[c];
data[top_index] = pixel;
}
}
}
}
void predict(Mat& org_img, Mat& mask)
{
//拷贝图像
int orgWidth = org_img.cols;
int orgHeight = org_img.rows;
Mat img = org_img.clone();
//预处理
cvtColor(img, img, cv::COLOR_BGR2RGB);
resize(img, img, cv::Size(target_width, target_height), 0, 0, cv::INTER_LINEAR);
int real_buffer_size = 3 * target_width * target_height;
std::vector<float> input_buffer;
input_buffer.resize(real_buffer_size);
normalize(img, input_buffer.data(), g_fmean, g_fstd);
//转tensor
auto input_names = g_predictor->GetInputNames();
auto im_tensor = g_predictor->GetInputHandle(input_names[0]);
im_tensor->Reshape({ 1, 3, target_height, target_width });
im_tensor->CopyFromCpu(input_buffer.data());
//执行预测
g_predictor->Run();
//取出预测结果
auto output_names = g_predictor->GetOutputNames();
auto output_t = g_predictor->GetOutputHandle(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = 1;
std::cout << "size of outputs[" << 0 << "]: (";
for (int j = 0; j < output_shape.size(); ++j) {
out_num *= output_shape[j];
std::cout << output_shape[j] << ",";
}
std::cout << ")" << std::endl;
std::vector<int64> out_data;
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
//后处理获得掩码图
std::vector<uint8_t> out_data_u8(out_num);
for (int i = 0; i < out_num; i++) {
out_data_u8[i] = static_cast<uint8_t>(out_data[i]);
}
cv::Mat out_gray_img(output_shape[1], output_shape[2], CV_8UC1, out_data_u8.data());
cv::resize(out_gray_img, out_gray_img, Size(orgWidth, orgHeight));
cv::Mat out_eq_img;
cv::equalizeHist(out_gray_img, mask);
//结束清理
img.release();
out_eq_img.release();
std::vector<int64>(out_data).swap(out_data);
std::vector<uint8_t>(out_data_u8).swap(out_data_u8);
std::vector<float>(input_buffer).swap(input_buffer);
std::vector<int>(output_shape).swap(output_shape);
im_tensor.release();
output_t.release();
}
int main()
{
//初始化环境
init();
//加载图像和预处理
Mat img = imread("test.png",cv::IMREAD_COLOR);
Mat mask = Mat(img.rows, img.cols, CV_8UC1);
//开始推理
predict(img, mask);
//保存掩码结果
imwrite("result.jpg", mask);
std::cout << "处理完成" << std::endl;
return 0;
}
最终输出1张单通道的灰度图,如下图所示(推理前后):

输出结果和python下预测是一致的。
五、MFC工程调用
在工业应用领域,目前很多工控机程序是采用MFC和C#开发的,本节内容重点讲解如何在MFC程序中调用Paddle Inference。主要步骤分为两步:
-
- 制作基于C++的dll;
-
- MFC中调用dll实现推理;
5.1 基于C++的dll制作
在第四节,我们实现了基于C++控制台程序的Paddle Inference调用。我们本小节继续在这个demo上进行修改,首先修改这个项目的配置输出,修改为动态库(.dll)形式,如下图所示:

然后我们在当前项目中添加一个头文件,名为imagetool.h,在这个头文件里面我们来定义两个基本的dll接口,实现初始化环境和推理,完整内容如下:
#pragma once
#ifndef IMAGE_API
#define IMAGE_API
extern "C"
{
// 初始化
__declspec(dllexport) int EnvInit();
// 图像推理
__declspec(dllexport) int ImageProcess(char* pImgIn, char* pImgOut,int height,int width);
}
#endif
在定义推理接口ImageProcess的过程中,为了从拓展性考虑,我们对输入和输出采用的是char*格式,也就是通过原始图像数据内存指针来传递数据。
接下来我们重新修改PaddleDemo.cpp文件,在头部引入刚定义的imagetool.h文件:
#include "imagetool.h"
然后注释掉原文件的main函数,然后添加对应的dll接口函数,代码如下:
//初始化深度学习环境
int EnvInit()
{
try
{
// 创建默认配置对象
paddle_infer::Config config;
config.SetModel("model/model.pdmodel", "model/model.pdiparams");
config.EnableUseGpu(100, 0);
config.EnableMemoryOptim();
//开启tensorrt加速
/*config.EnableTensorRtEngine(1 << 20, 1, 10,paddle_infer::PrecisionType::kFloat32, true, false);
std::map<std::string, std::vector<int>> min_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> max_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> opt_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
opt_input_shape);*/
//创建预测器
g_predictor = paddle_infer::CreatePredictor(config);
//定义预处理均值和方差
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
return 1;
}
catch (...) // 捕获所有异常
{
return -1;
}
}
// 图像推理
int ImageProcess(char* pImgIn, char* pImgOut, int height, int width)
{
Mat img = Mat(height, width, CV_8UC3);
memcpy(img.data,pImgIn,height*width*3);
Mat mask = Mat(height, width, CV_8UC1);
//开始推理
predict(img, mask);
//返回
memcpy(pImgOut, mask.data, height * width);
//释放
img.release();
mask.release();
return 1;
}
到这里dll工程就修改完了,重新生成工程,在x64/Release目录下会生成对应的dll库文件,包括:
PaddleDemo.lib
PaddleDemo.dll
这两个文件就是我们生成出的深度学习推理文件,后面我们在MFC工程中只需要配置这两个文件即可,不需要再配置Paddle Inference了。
5.2 MFC工程中调用
首先新建一个MFC对话框程序(注意必须创建X64 Release工程)。然后调整整个的资源对话框如下所示:

具体包括2个picture控件(ID号分别是IDC_PIC_IN和IDC_PIC_OUT)和2个按钮。为了能够在这个MFC程序中加载和使用图像,我们一样使用opencv这个库来完成,具体配置方法与4.2节相同。这里主要牵扯到MFC中图像控件的图像显示问题。
我们下面给出关键的图像选择和显示的代码(熟悉MFC的读者可以自行尝试,代码实现是比较简单的)。
选择图像代码:
//选择图片
void CMFCDemoDlg::OnBnClickedButtonChoose()
{
// TODO: 在此添加控件通知处理程序代码
CFileDialog dlg(TRUE, _T("*.png"),
NULL,
OFN_ALLOWMULTISELECT | OFN_HIDEREADONLY | OFN_FILEMUSTEXIST,
_T("image Files(*.png;*.png)|*.png;*.png|All Files (*.*)|*.*||"),
NULL);
//打开文件对话框的标题名
dlg.m_ofn.lpstrTitle = _T("选择图像 ");
if (dlg.DoModal() != IDOK)
return;
//读取图片
CString mPath = dlg.GetPathName();
m_imgIn.release();
m_imgIn = imread(mPath.GetBuffer(0), IMREAD_COLOR);
m_imgOut.release();
m_imgOut = Mat(m_imgIn.rows, m_imgIn.cols, CV_8UC3, Scalar(255, 255, 255));
//获取图片控件矩形框
CRect rect;
GetDlgItem(IDC_PIC_IN)->GetClientRect(&rect);
HWND hwnd1 = GetDlgItem(IDC_PIC_IN)->GetSafeHwnd();
ShowImage(m_imgIn, hwnd1, rect);
GetDlgItem(IDC_PIC_OUT)->GetClientRect(&rect);
HWND hwnd2 = GetDlgItem(IDC_PIC_OUT)->GetSafeHwnd();
ShowImage(m_imgOut, hwnd2, rect);
}
图像显示代码:
void CMFCDemoDlg::ShowImage(Mat imgSrc, HWND hwnd, CRect &rect)
{
//缩放Mat,以适应图片控件大小
cv::resize(imgSrc, imgSrc, cv::Size(rect.Width(), rect.Height()));
// 转换格式 ,便于获取BITMAPINFO
switch (imgSrc.channels())
{
case 1:
cv::cvtColor(imgSrc, imgSrc, COLOR_GRAY2BGRA); // GRAY单通道
break;
case 3:
cv::cvtColor(imgSrc, imgSrc, COLOR_BGR2BGRA); // BGR三通道
break;
default:
break;
}
// 制作bitmapinfo(数据头)
int pixelBytes = imgSrc.channels() * (imgSrc.depth() + 1);
BITMAPINFO bitInfo;
bitInfo.bmiHeader.biBitCount = 8 * pixelBytes;
bitInfo.bmiHeader.biWidth = imgSrc.cols;
bitInfo.bmiHeader.biHeight = -imgSrc.rows; //注意"-"号(正数时倒着绘制)
bitInfo.bmiHeader.biPlanes = 1;
bitInfo.bmiHeader.biSize = sizeof(BITMAPINFOHEADER);
bitInfo.bmiHeader.biCompression = BI_RGB;
bitInfo.bmiHeader.biClrImportant = 0;
bitInfo.bmiHeader.biClrUsed = 0;
bitInfo.bmiHeader.biSizeImage = 0;
bitInfo.bmiHeader.biXPelsPerMeter = 0;
bitInfo.bmiHeader.biYPelsPerMeter = 0;
//绘图
HDC hdc = ::GetDC(hwnd);
::StretchDIBits(
hdc,
0, 0, rect.Width(), rect.Height(),
0, 0, imgSrc.cols, imgSrc.rows,
imgSrc.data,
&bitInfo,
DIB_RGB_COLORS,
SRCCOPY
);
}
其中m_imgIn和m_imgOut是两个opencv的Mat对象,在对话框头文件中作为类内变量定义。
最终效果如下所示:

我们可以任意选择并切换图像显示。
接下来就是正式的完成深度学习dll加载了。首先将前面生成的PaddleDemo.lib、PaddleDemo.dll以及自行定义的imagetool.h头文件都拷贝到当前项目根目录下,模型文件model文件夹也需要拷贝到当前项目 根目录下,同时将PaddleDemo工程下的所有dll文件也拷贝到当前项目根目录下。另外,将这些文件在当前项目的x64/Release下也拷贝一份,这样能够使用ctrl+f5在VS Code中直接运行了。
完整目录如下所示:

在当前项目的“属性—链接器—输入—附加依赖项”中,添加PaddleDemo.lib库的引用,如下图所示:

然后在工程头文件添加自定义头文件引用:
#include "imagetool.h"
接下来我们在对话框初始化函数中编写初始化深度学习环境的代码,如下所示:
BOOL CMFCDemoDlg::OnInitDialog()
{
CDialogEx::OnInitDialog();
// IDM_ABOUTBOX 必须在系统命令范围内。
ASSERT((IDM_ABOUTBOX & 0xFFF0) == IDM_ABOUTBOX);
ASSERT(IDM_ABOUTBOX < 0xF000);
CMenu* pSysMenu = GetSystemMenu(FALSE);
if (pSysMenu != nullptr)
{
BOOL bNameValid;
CString strAboutMenu;
bNameValid = strAboutMenu.LoadString(IDS_ABOUTBOX);
ASSERT(bNameValid);
if (!strAboutMenu.IsEmpty())
{
pSysMenu->AppendMenu(MF_SEPARATOR);
pSysMenu->AppendMenu(MF_STRING, IDM_ABOUTBOX, strAboutMenu);
}
}
// 设置此对话框的图标。 当应用程序主窗口不是对话框时,框架将自动
// 执行此操作
SetIcon(m_hIcon, TRUE); // 设置大图标
SetIcon(m_hIcon, FALSE); // 设置小图标
// TODO: 在此添加额外的初始化代码
//初始化深度学习环境
int result = EnvInit();
if (result < 0)
{
MessageBox("初始化深度学习环境失败");
return false;
}
return TRUE; // 除非将焦点设置到控件,否则返回 TRUE
}
然后我们可以运行一下程序,如果不报错误说明深度学习模型能够被正确加载。最后我们来完成检测的代码:
//检测
void CMFCDemoDlg::OnBnClickedButtonSeg()
{
// TODO: 在此添加控件通知处理程序代码
//推理
m_imgOut.release();
m_imgOut = Mat(m_imgIn.rows, m_imgIn.cols, CV_8UC1, Scalar(0));
int result = ImageProcess((char *)m_imgIn.data,(char *)m_imgOut.data,m_imgIn.rows,m_imgIn.cols);
//显示结果
CRect rect;
GetDlgItem(IDC_PIC_OUT)->GetClientRect(&rect);
HWND hwnd2 = GetDlgItem(IDC_PIC_OUT)->GetSafeHwnd();
ShowImage(m_imgOut, hwnd2, rect);
}
上述代码需要注意输入和输出图像的格式,需要与dll文件中的一致,否则会内存奔溃。
最终运行效果如下所示:

注意到,第一次推理速度是比较慢的,后面就很快了。因此,我们可以在初始化的时候做一下warmup(初始时就跑几次推理),这样后面正式推理时速度就快了。
到这里,MFC调用方法就介绍完了。实际读者使用时需要进一步优化上述代码,需要做一些保护操作,例如图像如果读取不到等等。
六、C#工程调用
本节以winform的C#程序为例子,讲解如何在C#程序中调用Paddle Inference。在C#中调用Paddle Inference与第五节一样,都是通过dll的方式调用。首先使用C++生成适合C#的dll,然后再由C#调用。
6.1基于C++的dll制作
本小节先来制作基于C++的dll。首先在项目属性上右键添加模块,然后添加一个PaddleDemo.def文件。如下图所示:

然后在文件中申明导出模块,这样C#程序才能准确调用这个dll。
代码如下:
LIBRARY PaddleDemo
EXPORTS EnvInit
EXPORTS ImageProcess
然后我们修改自定义的imagetool.h头文件,内容如下:
#pragma once
#define DLL_API extern "C" _declspec(dllexport)
最后我们修改PaddleDemo.cpp,核心代码如下所示:
// 初始化
DLL_API int EnvInit()
{
try
{
// 创建默认配置对象
paddle_infer::Config config;
config.SetModel("model/model.pdmodel", "model/model.pdiparams");
config.EnableUseGpu(100, 0);
config.EnableMemoryOptim();
//开启tensorrt加速
/*config.EnableTensorRtEngine(1 << 20, 1, 10,paddle_infer::PrecisionType::kFloat32, true, false);
std::map<std::string, std::vector<int>> min_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> max_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
std::map<std::string, std::vector<int>> opt_input_shape = {
{"x", {1, 3, 512, 512}},
{"bilinear_interp_v2_4.tmp_0", {1, 128, 32, 32}},
{"bilinear_interp_v2_5.tmp_0", {1, 96, 64, 64}},
{"max_2.tmp_0", {1, 1, 32, 32}},
{"bilinear_interp_v2_3.tmp_0", {1, 128, 16, 16}},
{"max_0.tmp_0", {1, 1, 16, 16}},
{"max_3.tmp_0", {1, 1, 32, 32}},
{"max_1.tmp_0", {1, 1, 16, 16}},
{"mean_0.tmp_0", {1, 1, 16, 16}},
{"relu_54.tmp_0", {1, 128, 16, 16}},
{"max_4.tmp_0", {1, 1, 64, 64}},
{"max_5.tmp_0", {1, 1, 64, 64}},
{"mean_4.tmp_0", {1, 1, 64, 64}},
{"relu_60.tmp_0", {1, 96, 64, 64}},
{"mean_2.tmp_0", {1, 1, 32, 32}},
{"relu_57.tmp_0", {1, 128, 32, 32}},
};
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
opt_input_shape);*/
//创建预测器
g_predictor = paddle_infer::CreatePredictor(config);
//定义预处理均值和方差
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
return 1;
}
catch (...) // 捕获所有异常
{
return -1;
}
}
// 图像推理
DLL_API int ImageProcess(uchar* pDataIn, int width, int height, int stride, uchar* pDataOut, size_t& size)
{
Mat img = Mat(height,width, CV_8UC3, pDataIn, stride).clone();
Mat mask = Mat(height, width, CV_8UC1);
//开始推理
predict(img, mask);
// 图像数据导出
std::vector<uchar> buf;
cv::imencode(".bmp", mask, buf);
size = buf.size();
for (uchar& var : buf)
{
*pDataOut = var;
pDataOut++;
}
//释放
img.release();
mask.release();
std::vector<uchar>(buf).swap(buf);
return 1;
}
这里尤其要注意推理函数ImageProcess的写法,这种写法可以保证将来C#能够通过图像内存地址的方式传递数据。
最后重新生成项目解决方案即可得到对应的PaddleDemo.dll和PaddleDemo.lib。对于C#调用来说,只需要PaddleDemo.dll这个文件即可。
6.2 C#中调用dll
首先我们新建一个基于C#的winform程序,然后生成平台改成Release X64。然后我们将前面生成的PaddleDemo.dll以及所有相关的dll以及存放模型的model文件夹在项目本地和x64/Release文件夹下都拷贝一份。
整个C#工程界面设计如下(2个picturebox控件以及两个按钮控件):

选择图片相关代码主要实现图片的本地选择和读取显示,代码如下:
public static Bitmap KiResizeImage(Bitmap bmp, int newW, int newH)
{
try
{
Bitmap b = new Bitmap(newW, newH);
Graphics g = Graphics.FromImage(b);
// 插值算法的质量
g.InterpolationMode = InterpolationMode.HighQualityBicubic;
g.DrawImage(bmp, new Rectangle(0, 0, newW, newH), new Rectangle(0, 0, bmp.Width, bmp.Height), GraphicsUnit.Pixel);
g.Dispose();
return b;
}
catch
{
return null;
}
}
//图像对象
private System.Drawing.Bitmap m_ImgIn;
private System.Drawing.Bitmap m_ImgOut;
// 选择图片
private void button_choose_Click(object sender, EventArgs e)
{
OpenFileDialog opnDlg = new OpenFileDialog();
opnDlg.Filter = "所有图像文件 | *.png;";
opnDlg.Title = "打开图像文件";
opnDlg.ShowHelp = true;
if (opnDlg.ShowDialog() == DialogResult.OK)
{
string curFileName = opnDlg.FileName;
try
{
//读取图片
m_ImgIn = (Bitmap)Image.FromFile(curFileName);
//显示
Bitmap img = KiResizeImage(m_ImgIn, pictureBoxIn.Size.Width, pictureBoxIn.Size.Height);
pictureBoxIn.Image = img;
pictureBoxOut.Image = null;
pictureBoxOut.Refresh();
}
catch (Exception exp)
{
MessageBox.Show(exp.Message);
}
}
}
接下来我们在对话框类初始化函数中调用dll 的EnvInit函数实现深度学习模型的读取加载,代码如下:
[DllImport("PaddleDemo.dll")]
private extern static int EnvInit();
[DllImport("PaddleDemo.dll")]
private extern static int ImageProcess(byte []pDataIn,int width, int height, int stride, ref byte pDataOut, out ulong size);
public l()
{
InitializeComponent();
int result = EnvInit();
if (result < 0)
{
MessageBox.Show("深度学习环境加载失败");
}
}
注意上述代码中我们将dll中的两个接口函数全部引用了进来,这里需要关注这种接口引用方式。
最后我们完成检测按钮的代码:
private void button_detect_Click(object sender, EventArgs e)
{
//输入数据(强转为BGR格式)
BitmapData imgData = m_ImgIn.LockBits(new Rectangle(0, 0, m_ImgIn.Width, m_ImgIn.Height), ImageLockMode.ReadWrite,
PixelFormat.Format24bppRgb);
int width = imgData.Width;
int height = imgData.Height;
int stride = imgData.Stride;
IntPtr ptr = imgData.Scan0;
// Declare an array to hold the bytes of the bitmap.
int bytesLength = Math.Abs(imgData.Stride) * m_ImgIn.Height;
//图像的Stride
byte[] buffer = new byte[bytesLength];
// Copy the RGB values into the array.
Marshal.Copy(ptr, buffer, 0, bytesLength);
//MessageBox.Show(stride.ToString());
//输出数据
byte[] ptrData = new byte[1024 * 1024 * 3]; //尽可能大的byte[],一般大于显示的最大图片内存即可
ulong size = new ulong();
//推理
int result = ImageProcess(buffer, width, height,stride, ref ptrData[0], out size);
if (result < 0)
{
MessageBox.Show("图像优化失败 原因:" + result.ToString());
return;
}
m_ImgOut = (Bitmap)Image.FromStream(new MemoryStream(ptrData, 0, (int)size));
Bitmap img = KiResizeImage(m_ImgOut, pictureBoxOut.Size.Width, pictureBoxOut.Size.Height);
pictureBoxOut.Image = img;
m_ImgIn.UnlockBits(imgData);
}
最终效果如下所示:

七、完整代码链接
所有代码均放在了百度网盘上,读者可以自行下载:
链接: https://pan.baidu.com/s/1nIZXe65VXKBTtcOypsLIXA 提取码: avm6
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)