写在开头:
本人非科班,之前没读过,只听说是本好书,硬着头皮花了四天时间通读了一遍,书上画得密密麻麻的,尤其是在虚拟内存这一章到处写满注解,只能说这本书的确不好读。一直想把学习的心得整理出来,有很多只是自己的理解,有不恰当的地方只能待后面多读几遍或有专业人士看到时及时指出并慢慢来修正了,谢谢你能来。

1、csapp是一门什么课程
注意它的三个关键词
-
- 独立:因为现代的计算机系统不断更新迭代的过程程,目前已经变成了一个超级复杂的系统,所以不可能用一本书或一个课程就可以把它讲得明白的,根据我们的思维习惯,太复杂的东西第一想到的肯定就是分拆,一直分拆到我们能理解的程度再根据相应的知识点,设计出一个个课程出来,所以就有了像计算机原理、汇编语言、C语言、操作系统、数据结构、计算机网络等等这样独立的课程出来。而本书也是其中的一门独立的,主要针对计算系统工作原理的课程。
- 贯穿:从整体上分析计算机系统,主要就是硬件系统与软件系统两大主题,而上述的课程被独立成一个个课程后,为了理解方便,彼此之间的关联度不高,缺乏系统性去从硬到软,从底层到上层的系统理解计算机的工作过程。如计组与汇编、体系结构重点是说计算机硬件底层是如何工作的,而C语言、数据结构则是重点说软件是如何设计的,其中的操作系统则重点在系统内核是如何去管理硬件,协调调度程序接口的,计算机网络则是重点在网络之间程序如何进行通信……因此,缺乏一门从下到上,将所有独立的知识点串联起来的课程,而CSAPP刚好解决了这个问题
- 基础课程:和其它课程一样,CSAPP只是一门从程序员的角度去解读软件如何与操作系统交互,并驱动硬件实现我们程序的基础原理的课程。并不涉及过多的上层应用方面的知识,更多的是给了程序员一个理解计算机工作的视角,扒着缝往里面窥视一眼的课程,所以Perspective是相当到位的。




-
架构师的能力——知道计算机内部运作而能写出更好程序的人
从使用者的角度来理解计算系统的整体设计以及这些设计因素对于应用软件开发和运行的影响。这个很关键,基础课程作为计算机底层知识,看似无用,其实在后期上层应用时,如果不理解计算机系统是如何工作的,可能会出现知其然不知其所以然,即不知道为什么要这么做。
如为什么要用并发,但并发为什么不是越多越好,这就涉及到了CPU的流程线原理与实现的几个阶段;
为什么缓存优化会大行其道,无处不在,成为提升效率降低成本的核心思想,只有明白了局部性原理、缓存设计与实现原理后你才明白并不是在所有场合,缓存都一样的高效,当出现冷不命中时或缓存算法设计得不够好时,可能只会适得其反;
C和C++很高效,为什么企业开发更喜欢用JAVA来架构……
让你知道软件是如何运作的,出现故障时该从什么地方进行修复
程序如何更好利用操作系统和框架提供的功能,对各种操作的条件和运行时的参数能正确操作,使其运行起来更快
同时又能让我们写程序时尽量避免写出易受攻击或有缺陷的代码
所以本课程的关键是培养基础的计算机系统的思维方式,从整体上把握上层软件应用架构的能力,重点是思想!
A Tour of Computer Systems |
2、 数据、信息在计算内部存储方式
信息就是位+上下文
位是计算机内部进行传输时使用的基本单位,计算机能识别的传输即高电频低电频两种状态
比特是计算进行存储信息的基本单位,由8个二进制位组成,是存储器最小的寻址单位。
而我们人日常用的数字是十进制,即逢10进1,为了更好的控制计算机,发展出了16进制,即逢16进1,用更简短的16进制来表现计算机内部的二进制,每4个二进制位表示一个16进制。在汇编中表示内存地址时最常用。
从8位开始,计算机的发展都是以8为倍数进行不断迭代的。
计算机能识别的只有二进制,为了识别不同的语言并转换为基本的0和1,引入了不同的编码集方案:ASCII码、GB2312汉字码、UTF-8国际通用码等
ASCII码:1字节,8个二进制位表示一个数字或英文或控制字符。

EASCII内码:是由0到255共有256个字符组成。EASCII码比ASCII码扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号。

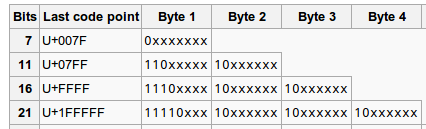
UTF-8码:为了兼容不同的语言,优化后的可变长字符编码,使用一至六个字节为每个字符编码(英文与数字是1个字节,即一个ASCII码;汉字为3个字节,其它不等)
如下面这个程序,通过ASCII码即可表示为:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}

- 上下文:在不同的位置,不同的编码,不同的场景下,同样的二进制码所表示的信息不一致。
在计算机内部的所有信息:如磁盘的文件,内存中的程序 ,或网络中传输的数据流,视频中的播放流,都是由一串串二进制位表示的,正是因为上下文的不同,一个同样的字节可能表示的是一个数字,或字母,或小数点,字符串,也有可能是一些控制指令等等。
上下文赋予了同样的比特序列不一样的意义。
3、一个简单程序的生命周期

业务需求的要求越来越高,需要计算机能处理越来越复杂多变的业务能力,演变出了不同的语言以满足不同的业务需求。
语言越往后发展,离机器底层越来越远,对于计算机内部的执行过程则刚好相反,如C语言从编辑到编译到可执行,就是一步步上往下(底层)转换的过程:

- 预处理:将所有的宏命令合并到.i文件中
- 编译:将高级的英文代码编译为汇编指令代码.s中
- 汇编:将汇编助记指令代码翻译为二进制位机器代码.o
- 链接:将内部用到的如println公共的引用或内核调用链接到另一个可执行文件中(即将两个.o文件合并起来,生成一个可执行格式的文件)
# 汇编指令
main:
subq $8, %rsp
movl $.LC0, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret
注意上面步骤中:一旦生成了汇编,即调用了本地系统的指令集与特定的CPU架构进行了绑定。
当生成指定二进制码后,即可从磁盘加载到内存中开始执行,从一个程序通过操作系统的调度,并创建一个进程开始运行:
生命周期一:存储在磁盘上的文件

生命周期二:shell调用,CPU接收键盘输入

生命周期三:收到执行指令后,从磁盘加载可执行文件到内存中

生命周期四:将hello可执行文件交给CPU去执行,并调用IO输出字符串到屏幕

几个概念:
3.1 总线
从上图可以看出,从连接的角度看,总线分三种:
- 系统总线:连接CPU与IO控制桥
- 内存总线:连接IO控制桥与内存
- IO总线:连接各基本IO与扩展设备
从传输功能上来看,总线也可以分为三种:
- 地址总线:指定各控制器存储单元(包括内存控制器,网卡控制器、显存控制器、打印控制器等)
- 数据总线:传输数据,根据CPU字长来传输不同大小的字节块,即一次传输一个字,字中的字节数由字长决定,如16位机是2字节、32位是4字节、64位是8字节
- 控制总线:对外部设备的控制能力。
下图是8086处理器,即16位字长的CPU:如果是64位,则一次可处理的更多


由此可知,计算机的处理能力取决于地址总线长度与数据总线的长度,一个64位的程序由这三个条件决定:64CPU处理能力+64位的操作系统+64位的软件程序。
对于一个64位的处理器:其可寻址的范围更大,且一次可传的数据更多。

如下数据89D8在8位机上的传输:一个16进制数相当于4个二进制位,8位机一次只能传8个二进制位

如下数据89D8在16位机上的传输:一个16进制数相当于4个二进制位,16位机一次只能传16个二进制位

如果是64位机,一次就可以传64个二进制位,相当于8个字节可以一次性传完,而不需要分多次传输
3.2 CPU
CPU一般会执行以下四个操作:
- 加载:从内存将数据复制到寄存器中,覆盖原来的内容
- 存储:将寄存器中的内容手电筒一内存中指定地址位置
- 操作:将两个寄存器中的内容复制到ALU中进行运算,并发结果放到其中一个Dest寄存器内
- 跳转:从指令中抽取一个字,并将这个字复制到PC程序计数器中,以替换之前PC中的值,实现指令跳转执行
由此可以看出,CPU是从PC计数器中取出进行指令并更新回PC指令计数器,整个工作都是围绕着寄存器、ALU计算单元、以及IO桥进行的。
4、存储层次结构与调整缓存的优化
每一层之间,访问速度越来越慢,容量越来越大,价格越来越低

每一层都可以视为其下一层的缓存,由于存储的技术远远跟不上CPU的运算速度发展,所以引入了缓存的设计,即以空间换时间,一般缓存主要有三种:
缓存都是为了减少各层之间复制带来的额外开销
- 硬件实现:如CPU的L1-L3,DMA独立通道技术(绕过CPU开销,直接在内存与IO之间进行数据传输)
- 操作系统实现:如虚拟内存中的cache技术(具体会在虚拟内存部分详细说明)
- 软件程序实现:如redis


5、操作系统对硬件的管理:进程、虚拟内存、文件
6、网络通信
7、Amdahl阿姆达尔定律
8、并发与并行
9、学习的方法:抽象
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)