HDFS is the Hadoop分布式文件系统。它是一个用于大型数据集的分布式存储系统,支持容错、高吞吐量和可扩展性。它的工作原理是将数据划分为在集群中的多台机器上复制的块。这些块可以并行写入或读取,从而提高吞吐量和容错能力。 HDFS 提供类似 RAID 的冗余以及自动故障转移功能。 HDFS 还支持压缩、复制和加密。
HDFS 最常见的用例是存储大量数据,例如图像和视频文件、日志、传感器数据等。
使用 HDFS 创建目录结构
“hdfs”命令行实用程序位于${HADOOP_HOME}/bin目录。假设Hadoop bin目录已经包含在PATH环境变量。现在以 HADOOP 用户身份登录并按照说明进行操作。
- 创建一个/dataHDFS 文件系统中的目录。我愿意使用这个目录来包含应用程序的所有数据。
hdfs dfs -mkdir /data
- 创建另一个目录/var/log,它将包含所有日志文件。由于 /var 目录也不存在,因此使用
-p也创建一个父目录。hdfs dfs -mkdir -p /var/log
- 您还可以在目录创建期间使用变量。例如,创建一个与当前登录用户同名的目录。该目录可用于包含用户的数据。
hdfs dfs -mkdir -p /Users/$USER
使用 HDFS 更改文件权限
您还可以更改 HDFS 文件系统中的文件所有权和权限。
将文件复制到 HDFS
The hdfs命令提供-get and -put用于将文件复制到 HDFS 文件系统或从 HDFS 文件系统复制文件的参数。
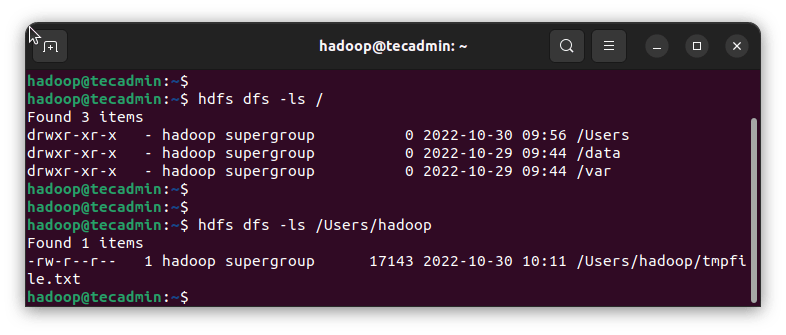
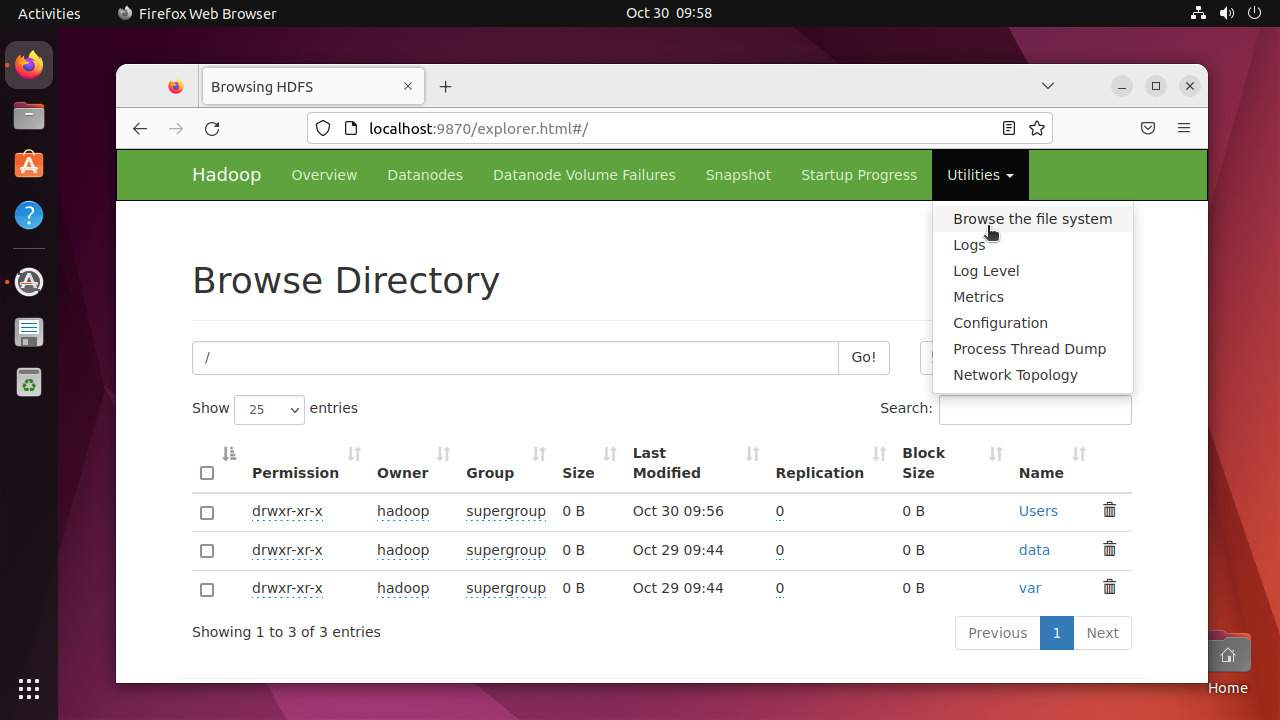
列出 HDFS 中的文件
在使用Hadoop集群时,您可以通过命令行和GUI查看HDFS文件系统下的文件。
结论
HDFS 还支持一系列其他应用程序,例如处理大量数据的 MapReduce 作业以及用户身份验证和访问控制机制。 HDFS 还可以与 S3 和 Swift 等其他分布式文件系统相结合,创建将高可用性、低延迟与低成本存储结合起来的混合云解决方案。
在本文中,您了解了如何在 HDFS 文件系统中创建目录结构、更改权限以及使用 HDFS 复制和列出文件。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)