队列是一种按称为 FIFO 的顺序检索数据项的数据结构(先进先出)。在 FIFO 中,第一个插入的元素将首先从队列中弹出。
优先级队列是队列数据结构的高级版本。
具有最高优先级的元素被放置在优先级队列的最顶部,并且是第一个被出列的元素。
有时,队列包含具有相同优先级的项目;因此,项目将按照其在队列中的顺序出列,就像 FIFO 一样。
在Python中,有多种选项来实现优先级队列。这queuePython 中的标准库支持优先级队列。
同样,heapqPython 中的模块还实现了优先级队列。我们还可以使用列表、元组, and dict 模块来实现优先级队列。
在本教程中,您将学习如何创建优先级队列以及可以对优先级队列中的元素执行的各种其他操作。
为什么要优先队列?
优先级队列在计算机世界中有很多应用。例如:
- 操作系统使用优先级队列在不同计算单元之间平衡或分配负载(任务集)。这使得处理高效,从而引入并行计算。
- 优先级队列用于操作系统中的中断处理。
- 在人工智能中,优先级队列实现了A*搜索算法。它跟踪未探索的路线并找到图的不同顶点之间的最短路径。路径长度越小,其优先级最高。
- 实施时Dijkstra 算法,优先级队列有效地找到矩阵或邻接列表图中的最短路径。
- 优先级队列对堆进行排序。堆是优先级队列的一种实现。
如何在Python中创建优先级队列?
优先级队列中的元素总是包含key and a value。键量化了元素的优先级。
使用列表:
使用列表实现优先级队列非常简单。只需创建一个列表,追加元素(键、值),并在每次追加元素时对列表进行排序。
Code:
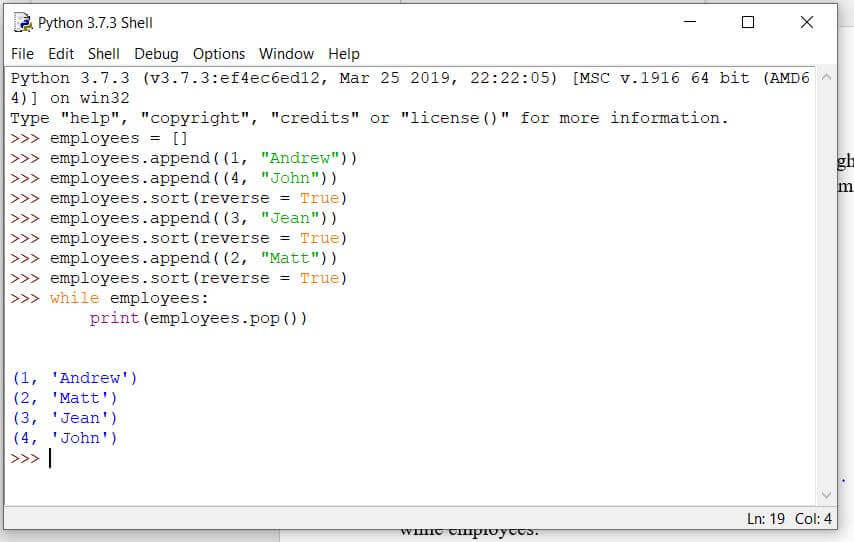
employees = []
employees.append((1, "Andrew"))
employees.append((4, "John"))
employees.sort(reverse = True)
employees.append((3, "Jean"))
employees.sort(reverse = True)
employees.append((2, "Matt"))
employees.sort(reverse = True)
while employees:
print(employees.pop())
当第一个元素被追加到列表中时,不需要对列表进行排序。优先队列的列表实现效率不高,因为在每个新条目之后都需要对列表进行排序。因此,需要时间根据元素的优先级来维护元素的顺序。
Output:
使用元组
Python 元组和列表在某种程度上是相同的。列表和元组都是Python的有序数据结构,并且允许重复值。但是列表的元素是可变的,而元组的元素是不可变的。
要使用元组实现优先级队列,我们将首先使用优先级队列的元素创建一个元组,然后对该元组进行排序。
由于您无法更改元组中的元素,因此元组不提供像列表一样的常规排序功能。要对元组进行排序,我们需要使用排序函数。
排序和排序方法之间的区别在于,排序方法不返回任何内容,而是更改列表的实际顺序。
而排序函数始终返回排序后的序列,并且不会干扰元组的实际序列。
在下面的代码行中,我们将创建一个元组并使用元组实现优先级队列:
mytuple = ((1, "bread"), (3, "pizza"), (2, "apple"))
现在让我们使用sorted()方法对元组进行排序:
sorted(mytuple)
Output:

使用字典
在 Python 字典中,数据以键和值对的形式存储。我们将使用键作为元素的优先级编号,使用值作为队列元素的值。
这样,我们就可以使用默认的Python字典来实现优先级队列。
创建字典并添加项目(键和值):
mydict = {2: "Asia", 4: "Europe", 3: "America", 1: "Africa"}
创建字典后,您需要按键对其项目进行排序。我们需要使用字典 items() 方法将字典的项目存储到变量中:
dict_items = mydict.items()
现在使用sorted()函数并打印排列好的优先级队列:
print(sorted(dict_items))
Output:

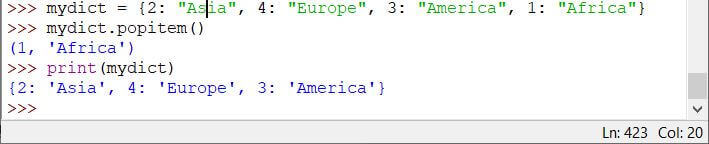
要从字典优先级队列中弹出项目,您可以使用波皮特姆()方法。字典 popitem() 方法将使具有最高优先级的元素出列:
mydict = {2: "Asia", 4: "Europe", 3: "America", 1: "Africa"}
mydict.popitem()
print(mydict)
Output:
使用队列模块
让我们使用内置的优先级队列创建一个queuePython 中的模块。使用队列模块是优先级队列最简单的用法。
Code:
import queue
p_queue = queue.PriorityQueue()
p_queue.put((2, "A"))
p_queue.put((1, "B"))
p_queue.put((3, "C"))
在此代码中,构造函数 PriorityQueue() 创建一个优先级队列并将其存储在变量 p_queue 中。 PriorityQueue 类的 put(priority_number, data) 函数在队列中插入一个项目。
put(priority_number, data) 函数有两个参数:第一个参数是一个整数,用于指定队列中元素的优先级编号,第二个参数是要插入到队列中的元素。
要从队列中弹出并返回项目,请使用 get() 函数:
print(p_queue.get())
如您所见,所有项目均已出队。要检查队列中是否存在任何元素,请使用empty()函数。 empty() 函数返回一个布尔值。如果返回true,则表示队列为空。
p_queue.empty()
使用heapdict
The heapdict模块类似于 Python 中的常规字典,但在 heapdict 中,您可以弹出项目,也可以更改优先级队列中项目的优先级。
使用heapdict,您可以更改项目的优先级:即增加或减少项目的键。
默认情况下不安装 heapdict 模块。要安装 heapdict:
pip install heapdict
现在我们来实现优先级队列:
Code:
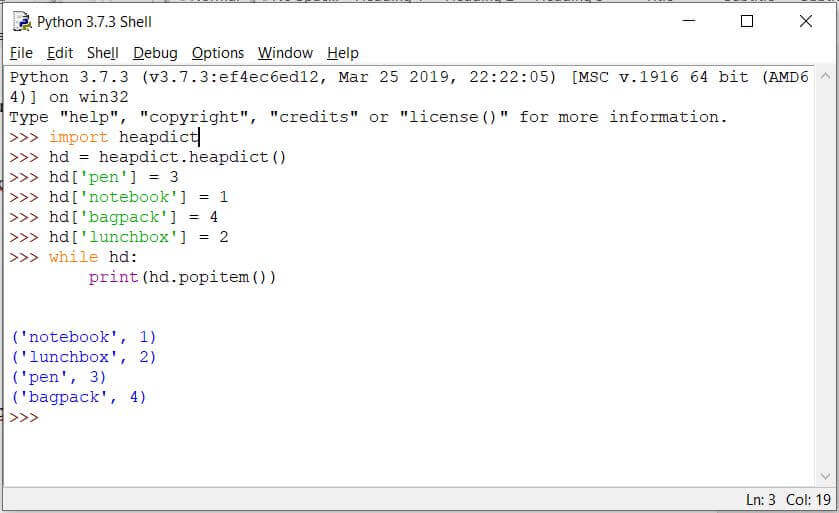
import heapdict
hd = heapdict.heapdict()
hd['pen'] = 3
hd['notebook'] = 1
hd['bagpack'] = 4
hd['lunchbox'] = 2
while hd:
print(hd.popitem())
Output:
使用堆q
计算机世界中的堆数据结构主要是为了实现优先级队列。 Python中的heapq模块可以用来实现优先级队列。
Code:
import heapq
employees = []
heapq.heappush(employees, (3, "Andrew"))
heapq.heappush(employees, (1, "John"))
heapq.heappush(employees, (4, "Jean"))
heapq.heappush(employees, (2, "Eric"))
while employees:
print(heapq.heappop(employees))
Output:
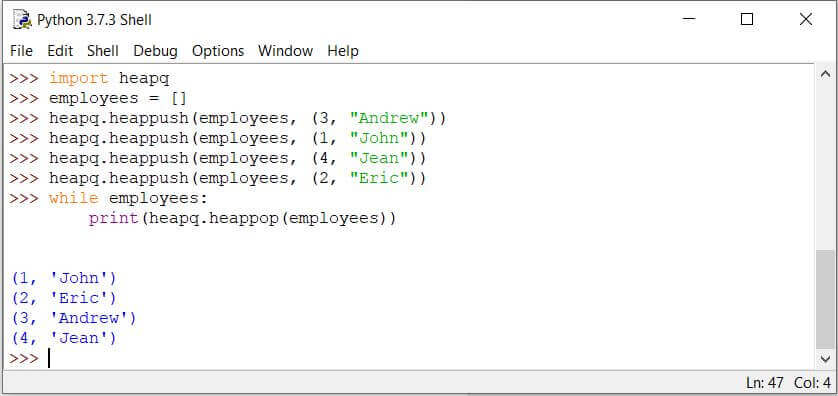
在此代码中,创建了一个堆并将元素(优先级键、值)推入堆中。
The heapq模块默认实现最小堆。具有最小键的元素被认为在最小堆中具有最高优先级。
因此,无论元素排队的顺序如何,最小的元素都会首先弹出,如上面的输出屏幕所示。
每当有元素被压入或弹出时,heapq 模块都会维护堆结构本身。
本教程将使用优先队列的 heapq 实现。
优先队列与最小堆
优先级队列是堆的实现。因此,这个实现可以是最大堆或最小堆。如果优先级队列的实现是最大堆,那么它将是最大优先级队列。
同样,如果实现是最小堆,那么优先级队列将是最小优先级队列。
在最小堆中,最小的节点是二叉树的根。
优先级队列和最小堆是相同的。唯一的区别是,在优先级队列中,元素的顺序取决于元素的优先级编号。
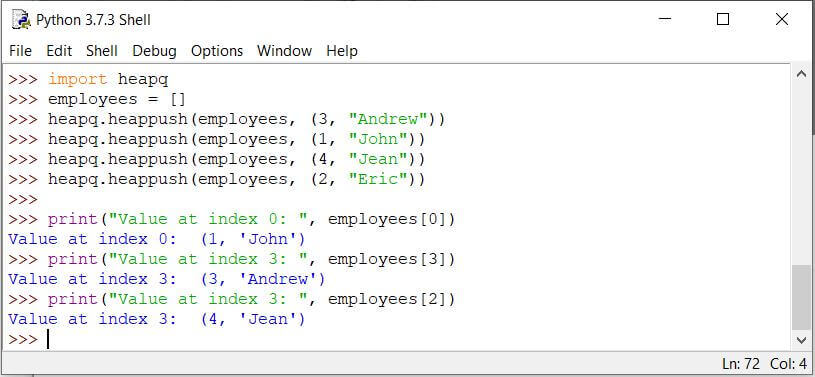
获取索引处的值
我们可以使用优先级队列的堆实现来获取索引处的值。首先创建一个堆,然后将项目推入堆中。优先级队列中的项目将有一个键和一个值。
这个键不是堆的索引。该键量化了优先级。索引是存储优先级队列的项(键、值)的位置。
考虑下面的例子:
Code:
import heapq
employees = []
heapq.heappush(employees, (3, "Andrew"))
heapq.heappush(employees, (1, "John"))
heapq.heappush(employees, (4, "Jean"))
heapq.heappush(employees, (2, "Eric"))
print("Value at index 0: ", employees[0])
print("Value at index 3: ", employees[3])
Output:
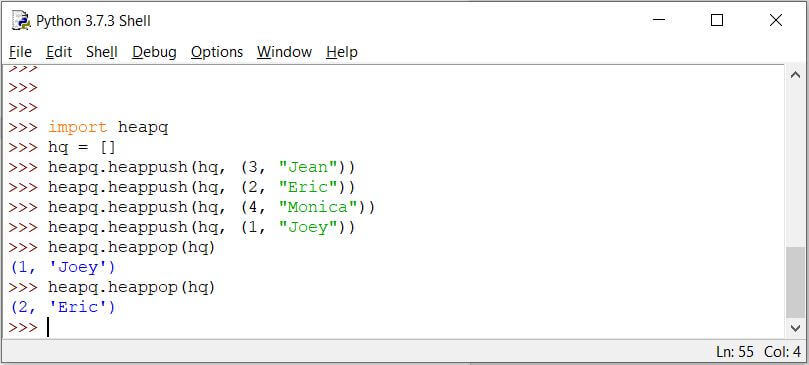
删除一个元素
要从优先级队列中删除元素,只需弹出该元素即可。具有最高优先级的元素将从队列中出列并删除。
创建队列:
Code:
import heapq
hq = []
heapq.heappush(hq, (3, "Jean"))
heapq.heappush(hq, (2, "Eric"))
heapq.heappush(hq, (4, "Monica"))
heapq.heappush(hq, (1, "Joey"))
heapq.heappop(hq)
Output:
更新优先级和值
要更新优先级队列中的优先级,请获取要更新优先级的元素的索引,并为该元素分配一个新键。
您也可以更改元素的值。查看下面的代码:
Code:
import heapq
hq = []
heapq.heappush(hq, (3, "Jean"))
heapq.heappush(hq, (2, "Eric"))
heapq.heappush(hq, (4, "Monica"))
heapq.heappush(hq, (1, "Joey"))
print(hq)
hq[1] = (6, 'Eric')
print(hq)
heapq.heapify(hq)
print(hq)
Output:
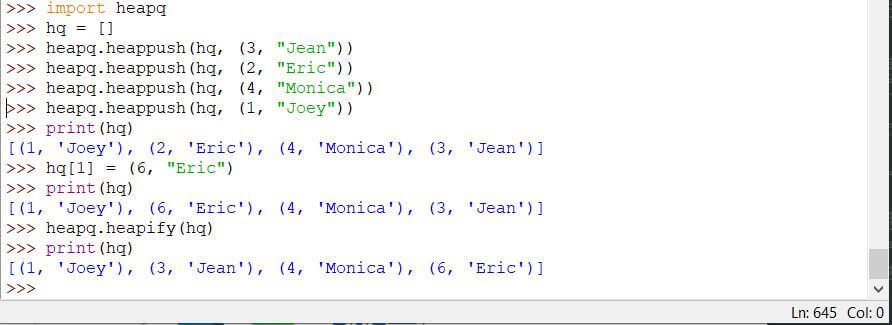
更新元素的优先级后,我们需要对堆进行heapify来维护堆数据结构。这堆化()heapq 模块的方法将 Python 可迭代对象转换为堆数据结构。
替换一个元素
在优先级队列的堆实现中,您可以弹出具有最高优先级的项目,并同时推送新项目,这意味着您正在用新的项目替换最高优先级的项目。
这是在以下人员的帮助下完成的heapq函数称为堆替换:
heapq.heapreplace(heap, item)
您将传递队列以从中弹出项目,并传递新项目以添加到队列中。
Code:
import heapq
hq = []
heapq.heappush(hq, (3, "Jean"))
heapq.heappush(hq, (2, "Eric"))
heapq.heappush(hq, (4, "Monica"))
heapq.heappush(hq, (1, "Joey"))
heapq.heapify(hq)
print(hq)
heapq.heapreplace(hq, (6, "Ross"))
print(hq)
Output:
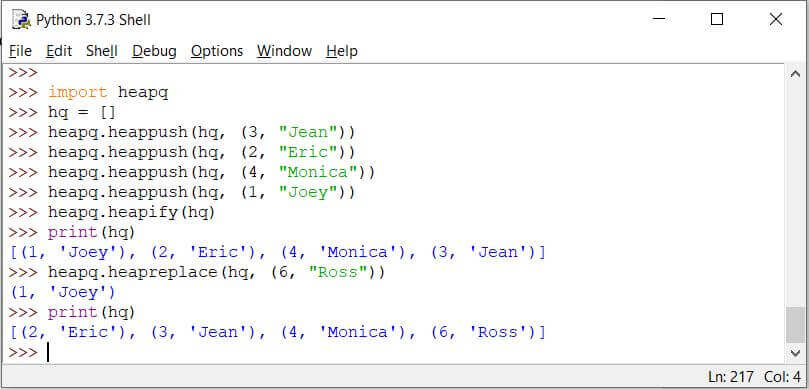
The 堆替换()函数将具有最高优先级的元素出队并将新元素添加到队列中。新元素的优先级最低。因此,它被放入队列的最后。
The heapq模块还提供了一个方法称为heappushpop(堆,项目)。 heappushpop(heap, item) 结合了 heappop() 和 heappush() 方法的功能。
heappushpop() 方法提高了效率,并且比使用单独的函数推送和弹出元素花费的时间更少。
heapreplace() 和 heappushpop() 之间的区别在于 heapreplace() 先弹出项目,然后将项目推入队列,这是替换元素的实际定义。
而 heappushpop() 将一个项目推送到队列中,更改队列的大小,然后将最小(最高优先级)的元素弹出。
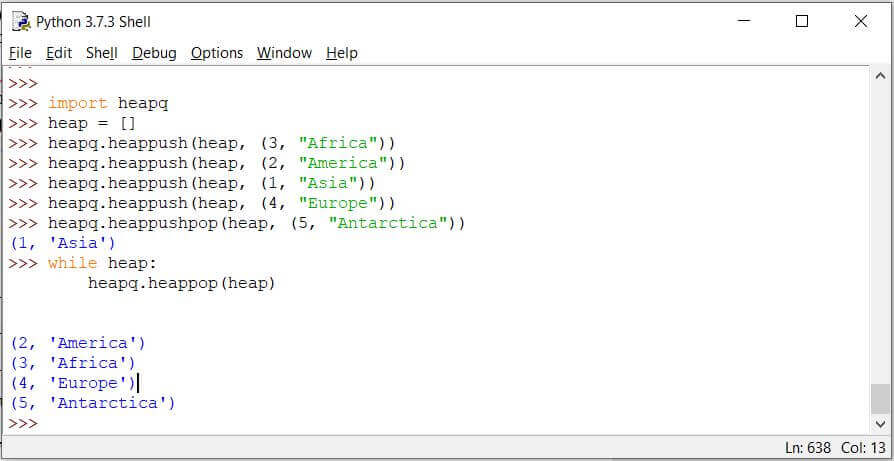
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "Africa"))
heapq.heappush(heap, (2, "America"))
heapq.heappush(heap, (1, "Asia"))
heapq.heappush(heap, (4, "Europe"))
heapq.heappushpop(heap, (5, "Antarctica"))
while heap:
heapq.heappop(heap)
Output:
查找热门项目而不删除
要查找队列中最靠前的项目而不弹出它们,heapq提供了一个函数叫做n最大(n,堆).
此函数返回优先级队列中的前 n 个项目。
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "eat"))
heapq.heappush(heap, (1, "study"))
heapq.heappush(heap, (2, "rest"))
heapq.heappush(heap, (4, "sleep"))
heapq.nlargest(3, heap)
print(heap)
Output:
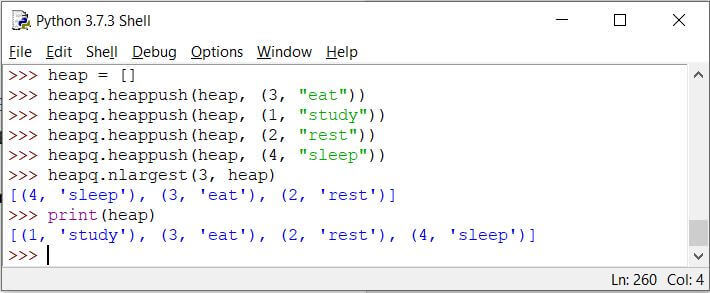
从输出中可以看出,当以下情况时,将返回优先级队列顶部的项目:n最大()使用了函数。请注意,该函数仅返回项目,并且不会将项目出列,如打印命令所示。
查找底部项目而不删除
要查找优先级队列底部的项目而不弹出它们,heapq提供了一个函数叫做n最小(n,堆)。此函数返回优先级队列底部的 n 个项目。
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "eat"))
heapq.heappush(heap, (1, "study"))
heapq.heappush(heap, (2, "rest"))
heapq.heappush(heap, (4, "sleep"))
heapq.nsmallest(3, heap)
print(heap)
Output:
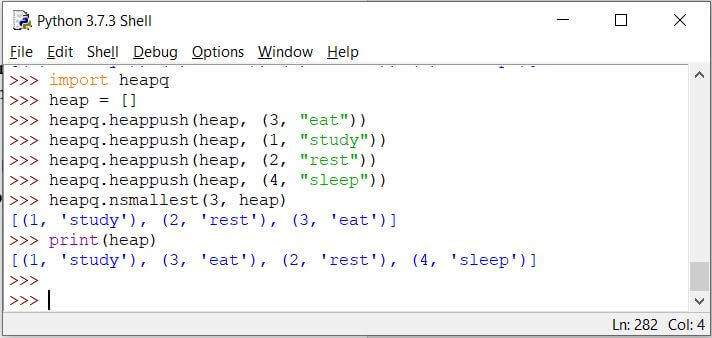
从输出中可以看出,当n最小()使用了函数。请注意,该函数仅返回项目,并且不会将项目出列,如打印命令所示。
带有自定义比较器的 Python 优先级队列
自定义比较器用于比较两个用户定义的可迭代对象。在Python优先级队列中,可以使用自定义比较器根据用户定义的值对队列进行排序。
例如,我们使用heapq创建一个优先级队列。然后我们使用sorted()方法对heapq进行排序。
它会根据元素的键(优先级编号)对队列中的元素进行排序。考虑下面的例子:
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "eat"))
heapq.heappush(heap, (1, "study"))
heapq.heappush(heap, (2, "rest"))
heapq.heappush(heap, (4, "sleep"))
print(sorted(heap))
Output:

现在让我们根据自定义比较器对队列进行排序。我们希望以这样的方式排列队列中的元素,即对队列进行排序后,值按字母顺序排列。
为此,我们将使用 lambda 函数。 lambda 函数是一种小型匿名函数,由一个带有任意数量参数的表达式组成。
lambda 函数或 lambda 表达式返回一个可以在程序中的任何位置使用的值。
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "eat"))
heapq.heappush(heap, (1, "study"))
heapq.heappush(heap, (2, "rest"))
heapq.heappush(heap, (4, "sleep"))
print(sorted(heap, key=lambda heap: heap[1]))
Output:
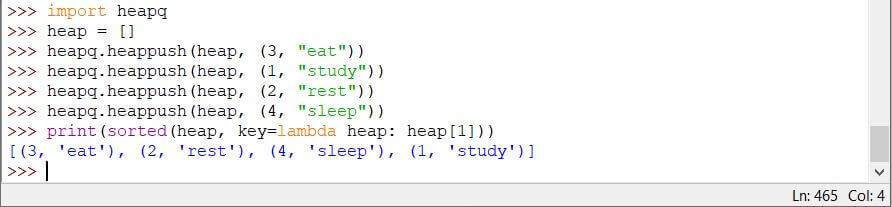
在此示例中,lambda 表达式指示根据值(而不是键)按字母顺序对队列进行排序。 Sorted() 方法采用三个参数:
- The iterable: 待排序的序列
-
Key: 该键是可选的。它被认为是排序比较的基础。关键是用户定义的比较器功能。
-
Reverse:反转是布尔值。如果设置为 true,则会反转排序顺序。默认情况下,反向参数为 false,这意味着它将按升序对序列进行排序。如果reverse设置为true,则序列将按降序排列。
反转优先队列顺序
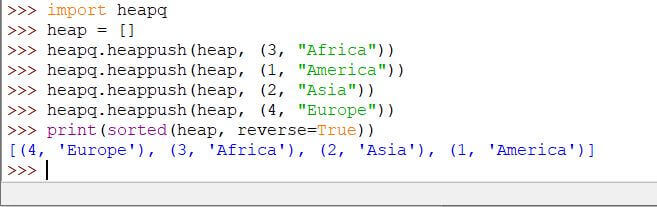
要反转优先级队列的顺序,请使用sorted()方法对队列进行排序,并设置reverse论证为真。默认情况下,队列按升序排序。
If the reverse参数设置为 true,它将按降序更改序列,如下例所示:
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "Africa"))
heapq.heappush(heap, (1, "America"))
heapq.heappush(heap, (2, "Asia"))
heapq.heappush(heap, (4, "Europe"))
print(sorted(heap, reverse=True))
Output:
重复键(同等优先级)
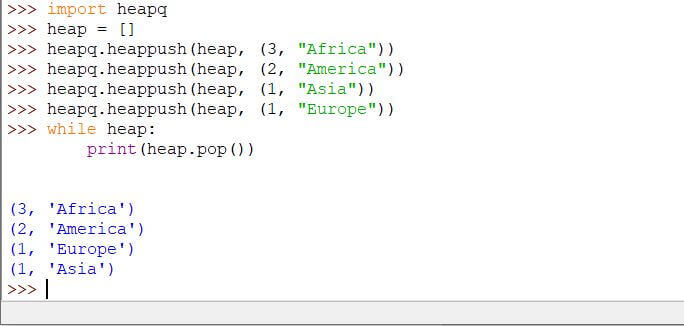
如果优先级队列中的元素有重复的键,则意味着这些元素的优先级相同。但问题是哪个元素将首先出列?
那么,位于队列顶部的元素将首先从队列中出列。
Code:
import heapq
heap = []
heapq.heappush(heap, (3, "Africa"))
heapq.heappush(heap, (2, "America"))
heapq.heappush(heap, (1, "Asia"))
heapq.heappush(heap, (1, "Europe"))
while heap:
print(heap.pop())
Output:
打破平局
当存在具有相同优先级的元素时,就会出现优先级队列中的平局。当两个元素不可比较时,即比较器在比较队列中的 a 和 b 元素后返回 0。
在这种情况下,优先级队列必须决定哪个元素首先出队。
这就是所谓的打破平局。
如果出现平局,我们可以在优先级队列中实现 FIFO(先进先出)或 LIFO(后进先出)。