将下列JSON格式数据复制到Linux系统中,并保存命名为employee.json。
| { "id":1 , "name":" Ella" , "age":36 } { "id":2, "name":"Bob","age":29 } { "id":3 , "name":"Jack","age":29 } { "id":4 , "name":"Jim","age":28 } { "id":4 , "name":"Jim","age":28 } { "id":5 , "name":"Damon" } { "id":5 , "name":"Damon" } |
为employee.json创建DataFrame,并写出Python语句完成下列操作:
- 查询所有数据;
- 查询所有数据,并去除重复的数据;
- 查询所有数据,打印时去除id字段;
- 筛选出age>30的记录;
- 将数据按age分组;
- 将数据按name升序排列;
- 取出前3行数据;
- 查询所有记录的name列,并为其取别名为username;
- 查询年龄age的平均值;
- 查询年龄age的最小值。
from pyspark.sql import SparkSession
# 创建SparkSession对象
spark = SparkSession.builder.appName("Employee").getOrCreate()
# 读取JSON文件并创建DataFrame
df = spark.read.json("file:///opt/module/spark-3.0.3-bin-without-hadoop/mycode/employee.json")
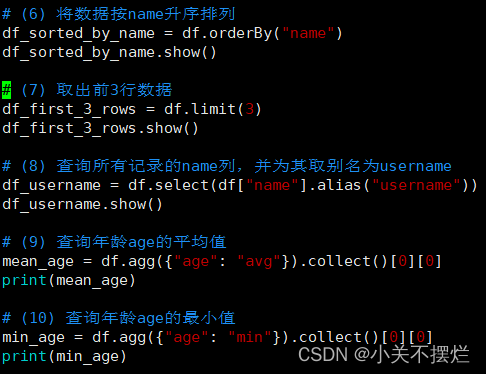
# (1) 查询所有数据
df.show()
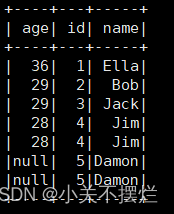
# (2) 查询所有数据,并去除重复的数据
df_drop_duplicates = df.dropDuplicates()
df_drop_duplicates.show()
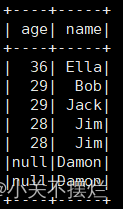
# (3) 查询所有数据,打印时去除id字段
df_no_id = df.select([c for c in df.columns if c != "id"])
df_no_id.show()
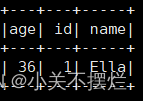
# (4) 筛选出age>30的记录
df_age_gt_30 = df.filter(df.age > 30)
df_age_gt_30.show()
# (5) 将数据按age分组
df_grouped_by_age = df.groupBy("age").count().show()
# (6) 将数据按name升序排列
df_sorted_by_name = df.orderBy("name")
df_sorted_by_name.show()
# (7) 取出前3行数据
df_first_3_rows = df.limit(3)
df_first_3_rows.show()
# (8) 查询所有记录的name列,并为其取别名为username
df_username = df.select(df["name"].alias("username"))
df_username.show()
# (9) 查询年龄age的平均值
mean_age = df.agg({"age": "avg"}).collect()[0][0]
print(mean_age)
# (10) 查询年龄age的最小值
min_age = df.agg({"age": "min"}).collect()[0][0]
print(min_age)

python3 ans3.py
(1)
(2)

(3)
(4)
(5)

(6)

(7)
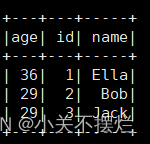
(8)
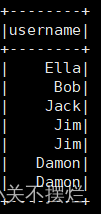
(9)
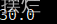
(10)

总结
- 通过查阅博客了解了agg方法可以接收多个聚合函数作为参数,也可以使用字典或多个键值对来指定要聚合的列以及聚合函数。它返回一个DataFrame,其中包含所有指定列的聚合结果。在例如计算平均值时,可以使用agg方法。第二个方法是使用groupBy方法对DataFrame进行分组,然后使用avg方法计算分组后每组age列的平均值,最后使用select方法选择要返回的列,并使用collect方法获取计算结果并转换为一个列表。由于只有一个分组并且只有一个聚合函数,因此列表中只有一个元素。使用索引[0]获取这个元素,然后使用asDict方法将其转换为字典。最后,使用字典的键'avg(age)'获取平均值聚合结果。
- 编程中也遇到很多问题,如:在数据需要去重时。可以使用Spark提供的dropDuplicates函数进行去重。distinct也是用来去重的,区别是distinct是根据每一条数据进行完整的比对和去重,dropDuplicates可以根据指定的字段进行去重。