公众号:嵌入式不难
本文仅供参考学习,如有错误之处,欢迎留言指正。
下载源代码
使用如下命令 git clone https://github.com/edenhill/librdkafka.git
切换到发布的稳定分支
刚下载下来的源代码默认在master/main分支, 最好切换到tag版本, 源分支如下
使用 git tag --list 列出存在的分支
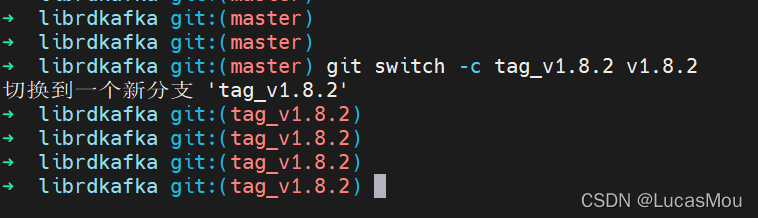
使用 git switch -c tag_v1.8.2 v1.8.2 切换到想要的分支
执行编译三部曲
执行命令 ./configure && make && sudo make install
./configure
作用: 1.首先检查机器的一些配置和环境,系统的相关依赖, 如果缺少依赖, 则脚本会自动停止
2.配置 Makefile 中的参数, 比如编译器, 库路径…
./configure --prefix=/软件要安装的路径 //将软件安装到指定的路径
./configure //未指定安装路径时, 通常默认路径都是/usr/local/
./configure --help //查看帮助文件
make
作用: 编译
make install
作用: 编译后的处理, 比如把文件移动到指定目录, 对于该库来说拷贝已经编译好的库文件, 将librdkafka下的头文件和动态库安装到/usr/local/include/和/usr/local/lib/下
该命令执行完成后, 会有如下变化
- /usr/local/include/ 文件夹下会新增 librdkafka 文件夹
librdkafka 内部的文件如下
rdkafkacpp.h rdkafka.h rdkafka_mock.h
- /usr/local/lib/ 文件下会新增一些动态链接库文件, 新增文件如下
librdkafka.a librdkafka++.a librdkafka.so librdkafka++.so librdkafka.so.1 librdkafka++.so.1 pkgconfig python2.7 python3.5
sudo ldconfig
作用: 将/etc/ld.so.conf中的路径缓存到/etc/ld.so.cache中,因此在安装完一些库文件或者修改 ld.so.conf 或者在 ld.so.conf.d 目录下新增 *.conf 文件后需要运行一下ldconfig使所有的库文件都缓存都ld.so.cache中,如果没有运行ldconfig,即使库文件就在/etc/ld.so.conf中,也是不会被使用的,结果在编译的过程中同样报错缺少库!
ldconfig指令存放于/sbin/ldconfig
/etc/ld.so.conf: 记录编译时使用的动态链接库的路径
cat /etc/ld.so.conf //cmd 展示内容如下
include /etc/ld.so.conf.d/*.conf
//含义为include /etc/ld.so.conf.d/下所有.conf结尾的文件
/etc.ld.so.conf.d: 保存动态链接库路径
cd /etc/ld.so.conf.d //cmd 进入目录
ls //cmd 结果如下
fakeroot-x86_64-linux-gnu.conf
vmware-tools-libraries.conf
x86_64-linux-gnu_EGL.conf
libc.conf
x86_64-linux-gnu.conf
x86_64-linux-gnu_GL.conf
cat libc.conf //cmd 展开 libc.conf 如下
/usr/local/lib
开始码代码
#include <rdkafka.h>
int main(int argc, char *argv[])
{
rd_kafka_conf_t *conf;
conf = rd_kafka_conf_new();
(void)conf;
return 0;
}
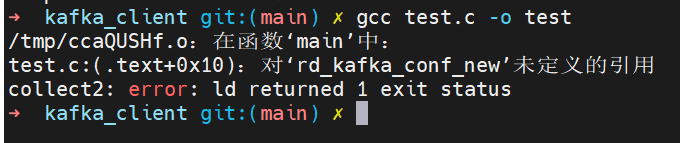
第一次编译
gcc test.c -o test结果如下

三部曲都已经没有问题了, 确报无法找到头文件, 那我就来解决这个问题
由于需要引用librdkafka的库函数, 就需要添加rdkafka*.h头文件, 但是头文件存在于 /usr/local/include/librdkafka中, 那我们怎么知道gcc在编译的时候是按照什么策略在搜索头文件的呢? 采用echo | gcc -x c -v -E -或者cpp -v指令来查看相关策略,结果如下
#include “…” search starts here:
#include <…> search starts here:
/usr/lib/gcc/x86_64-linux-gnu/5/include
/usr/local/include
/usr/lib/gcc/x86_64-linux-gnu/5/include-fixed
/usr/include/x86_64-linux-gnu
/usr/include
通过上面的知识可以知道include搜索头文件的目录只到/usr/local/include, 所以写代码的时候仅仅使用 #include <rdkafka.h> 是无法引用到头文件的, 应该使用 #include <librdkafka/rdkafka.h>
echo | gcc -x c -v -E -查看gcc预处理C时的的搜索目录
echo | gcc -x c++ -v -E -查看gcc预处理C++时的的搜索目录
第二次编译
#include <librdkafka/rdkafka.h>
int main(int argc, char *argv[])
{
rd_kafka_conf_t *conf;
conf = rd_kafka_conf_new();
(void)conf;
return 0;
}
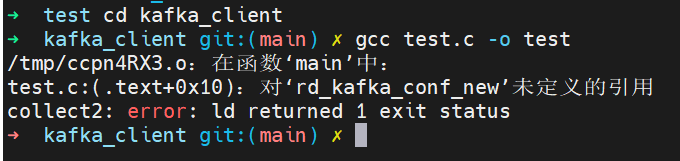
gcc test.c -o test结果如下
这次没有报找不到头文件故障了
第三次编译
那如果我偏偏要使用#include <rdkafka.h> 呢, 也不是不可以, 这里我们就需要另外的一个知识了, 我们要知道当编译#include <rdkafka.h> 的时候, 编译器第一步是从当前目录查找是否含有这个文件, 没有的话就从echo | gcc -x c -v -E -输出列表里面出现的目录去查找, 很明显, 这两个条件都不满足, 所以我们可以在使用gcc 编译的时候告诉编译器rdkafka.h 的位置, 使用方法是 gcc … -I /usr/local/include/librdkafka, 这样就可以了, 但是这样又存在一个问题, 我每次编译的时候都去输入一遍路径, 岂不是很麻烦, 有时候忘了就编译错误了, 那怎么办呢, 这个时候就需要使用C_INCLUDE_PATH 环境变量了, gcc 在编译的时候会查找这个环境变量的值, 并将环境变量的值展开, 添加到gcc 的编译参数里去, 而如何添加C_INCLUDE_PATH环境变量呢? 环境变量存在于/etc/profile 文件中, 使用export C_INCLUDE_PATH=/usr/local/include/librdkafka 就可以了, 而当我编译的, 怎么还有问题, 使用echo $C_INCLUDE_PATH 的时候, 居然为空, 然后我又一步步查, 最终查到了, 我使用的bash是ohmyzsh, 可能没有拿到/etc/profile 的配置信息, 所以我还需要将export C_INCLUDE_PATH=/usr/local/include/librdkafka 添加到zsh的环境变量里, zsh环境变量配置文件为 ~/.zshrc , 加入之后再重启一下系统就可以使用C_INCLUDE_PATH环境变量了
#include <rdkafka.h>
int main(int argc, char *argv[])
{
rd_kafka_conf_t *conf;
conf = rd_kafka_conf_new();
(void)conf;
return 0;
}
gcc test.c -o test结果如下
是我想看到的结果, 至少没有报找不到头文件
第四次编译
上面的编译都还是没有成功, 这下该解决对‘rd_kafka_conf_new’未定义的引用 问题了, 上面的问题是虽然找到了头文件, 但是无法链接到库文件, 而链接到库文件需要在编译时加上 -lrdkafka, 这里的 -lrdkafka 表示对动态链接库 rdkafka 的引用
gcc test.c -o test -lrdkafka结果如下
