什么是定时器
很多场景都会用到定时器,比如心跳检测、倒计时、技能冷却等。
定时器分类
一般定时任务的形式表现为:
- 经过固定时间后触发
- 按照固定频率周期性触发
- 在某个时刻触发。
定时器的本质
那定时器到底是什么呢?可以理解为这样一个数据结构:
- 存储一系列的任务集合,并且deadline越接近的任务,拥有越高的执行优先权
- 一般定时器支持如下几种操作:
- add:新增任务
- delete:取消某个任务
- run:执行到期的任务
- update:更新到期时间
那应该如何判断一个任务是否到期呢?
- 轮询,每隔一个时间片去检查最近的任务是否到期。
- 比如说创建一个线程每隔100ms扫描一次到期的任务。
- 缺点是:比如说我有1万个5s到期的定时请求,但是扫描周期是100ms,那么那个扫描的线程在这个5秒内就会不停的对这1万个任务进行扫描遍历,要额外扫描40多次(每 100 毫秒扫描一次,5 秒内要扫描近 50 次),很浪费CPU
- 怎么解决:epoll、sleep之类的唤醒操作;时间轮
- 睡眠/唤醒,不停的查找deadline最近的任务最近的任务,到期就执行;否则sleep直到其到期。在sleep是,如果有任务被add或者delete,则deadline可能会被改变,那么线程就会被唤醒重新查找deadline
定时器与线程
对于服务端的来说,驱动服务端逻辑的事件主要有两个:一个是网络事件,一个是时间事件。
在不同的框架中,这两种事件有不同的实现方式:
- 第一种,网络事件和时间事件在一个线程中配合使用,比如nginx、redis
- 第二种,网络事件和时间事件在不同线程中处理,比如skynet
// 第一种:
while(!quit){
int now = get_now_time(); //单位:ms
int timeout = get_nearset_timer() - now;
if(timeout < 0){
timeout = 0;
}
int nevent = epoll_wait(epfd, ev, nev, timeout);
for(int i = 0; i < nevent; i++){
//.... 网络事件处理
}
update_timer(); //时间事件处理
}
// 第二种 在其他线程添加定时任务
void *thread_timer(void *thread_param){
init_timer();
while(!quit){
update_timer();
sleep(t);
}
clear_timer();
return NULL;
}
pthread_create(&pid, NULL, thread_timer, &thread_param);
需要注意两点:
- 定时任务最好不要执行阻塞的事件,否则可能会影响后面的事件不能按时处理了
- 任务也不能太抢CPU,否则会降低应用程序的性能
绝对禁止的操作
- 能不能每一个任务都创建一个线程呢?不能,线程过多,资源消耗过大
- 一个线程扫描所有的定时任务?让CPU做了很多额外的轮询遍历操作而浪费CPU的问题
其线程模型应该如下如下:
- 用户线程:检测定时任务的注册
- 定时任务队列轮询线程:负责扫描任务队列上符合要求的任务,如果任务的时间戳达到规定的时刻,首先从队列中取走此任务,然后将其交给异步线程池来处理;
- 异步线程池:负责定时任务的执行;
也就是说要把任务注册、任务到期检查、任务执行这三个分开
定时器的数据结构该如何选择
必须满足:
- 有序的结构,而且增删操作不会影响该结构有序
- 能快速查找最小节点
为此,有如下选择
(1) 有序链表
(2)红黑树
- 对于增删查,时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n) ;
- 对于红黑树,最⼩节点为最左侧节点,时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n)
(3) 最小堆
- 对于增查,时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n) ;
- 对于删,时间复杂度为
O
(
n
)
O(n)
O(n) ,但是可以通过辅助数据结构(map或者hashmap)来加快删除操作
- 对于最小堆,最小节点为根节点,时间复杂度为P(1)
(4) 跳表
- 对于增删查,时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n) ;
- 对于跳表,最⼩节点为最左侧节点,时间复杂度为
O
(
l
o
g
1
)
O(log1)
O(log1),但是空间复杂度高,为
O
(
1.5
n
)
O(1.5n)
O(1.5n)### 间轮
- 对于增删查,时间复杂度为O(1) ;
- 查找最小节点为O(1)
(5)时间轮
- 对于linux这种对定时器依赖性比较高(网络子模块的TCP协议使用了大量的定时器)的操作系统来说,以上的数据结构都是不能满足需求的,所以linux使用了效率更高的定时器算法:时间轮(timewheel)
怎么选择:
- 在任务量小的场景下:最小堆实现,可以根据堆顶设置超时时间,数组存储结构,节省内存消耗,使用最小堆可以得到比较好的效果
- 而时间轮定时器,由于需要维护一个线程用来波动指针,而且需要开辟一个bucket数组,消耗内存大,使用时间轮会较为浪费资源。
- 在任务量大的场景下,最小堆的插入复杂度是O(lg’N),相比时间轮O(1)会造成性能下降,更适合使用时间轮实现
- 在业界,服务治理的心跳检测等功能需要维护大量的链接心跳,因此时间轮是首选。
定时器设计
// 初始化定时器
void init_timer();
// 添加定时器
Node* add_timer(int expire, callback cb);
// 删除定时器
bool del_timer(Node* node);
// 找到最近要发⽣的定时任务
Node* find_nearest_timer();
// 更新检测定时器
void update_timer();
// 清除定时器
// void clear_timer();
红黑树
- STL中map结构采用的是红黑树来实现的,但是定时器不要使用map结构来实现,因为可能多个定时任务需要同时被触发,map中的key是唯一的
- 红黑树的节点同时包含key和val,红黑树节点的有序由key来决定
- 插⼊节点的时候,通过⽐较key来决定节点存储位置;红⿊树的实现并没有要求 key 唯⼀;
#pragma once
#include <stdio.h>
#include <stdint.h>
#include <unistd.h>
#include <stdlib.h>
#include <stddef.h>
#include <time.h>
#include "rbtree.h"
ngx_rbtree_t timer;
static ngx_rbtree_node_t sentinel;
typedef struct timer_entry_s timer_entry_t;
typedef void (*timer_handler_pt)(timer_entry_t *ev);
struct timer_entry_s {
ngx_rbtree_node_t rbnode;
timer_handler_pt handler;
};
static uint32_t current_time() {
uint32_t t;
#if !defined(__APPLE__) || defined(AVAILABLE_MAC_OS_X_VERSION_10_12_AND_LATER)
struct timespec ti;
clock_gettime(CLOCK_MONOTONIC, &ti);
t = (uint32_t)ti.tv_sec * 1000;
t += ti.tv_nsec / 1000000;
#else
struct timeval tv;
gettimeofday(&tv, NULL);
t = (uint32_t)tv.tv_sec * 1000;
t += tv.tv_usec / 1000;
#endif
return t;
}
ngx_rbtree_t * init_timer() {
ngx_rbtree_init(&timer, &sentinel, ngx_rbtree_insert_timer_value);
return &timer;
}
void add_timer(uint32_t msec, timer_handler_pt func) {
timer_entry_t *te = (timer_entry_t *)malloc(sizeof(timer_entry_t));
memset(te, 0, sizeof(timer_entry_t));
te->handler = func;
msec += current_time();
printf("add_timer expire at msec = %u\n", msec);
te->rbnode.key = msec;
ngx_rbtree_insert(&timer, &te->rbnode);
}
void del_timer(timer_entry_t *te) {
ngx_rbtree_delete(&timer, &te->rbnode);
free(te);
}
int find_nearest_expire_timer() {
ngx_rbtree_node_t *node;
if (timer.root == &sentinel) {
return -1;
}
node = ngx_rbtree_min(timer.root, timer.sentinel);
int diff = (int)node->key - (int)current_time();
return diff > 0 ? diff : 0;
}
void expire_timer() {
timer_entry_t *te;
ngx_rbtree_node_t *sentinel, *root, *node;
sentinel = timer.sentinel;
uint32_t now = current_time();
for (;;) {
root = timer.root;
if (root == sentinel) break;
node = ngx_rbtree_min(root, sentinel);
if (node->key > now) break;
printf("touch timer expire time=%u, now = %u\n", node->key, now);
te = (timer_entry_t *) ((char *) node - offsetof(timer_entry_t, rbnode));
te->handler(te);
ngx_rbtree_delete(&timer, &te->rbnode);
free(te);
}
}
#include <stdio.h>
#include <string.h>
#include <sys/epoll.h>
#include "rbt-timer.h"
void hello_world(timer_entry_t *te) {
printf("hello world time = %u\n", te->rbnode.key);
}
int main()
{
init_timer();
add_timer(3000, hello_world);
int epfd = epoll_create(1);
struct epoll_event events[512];
for (;;) {
int nearest = find_nearest_expire_timer();
int n = epoll_wait(epfd, events, 512, nearest);
for (int i=0; i < n; i++) {
//
}
expire_timer();
}
return 0;
}
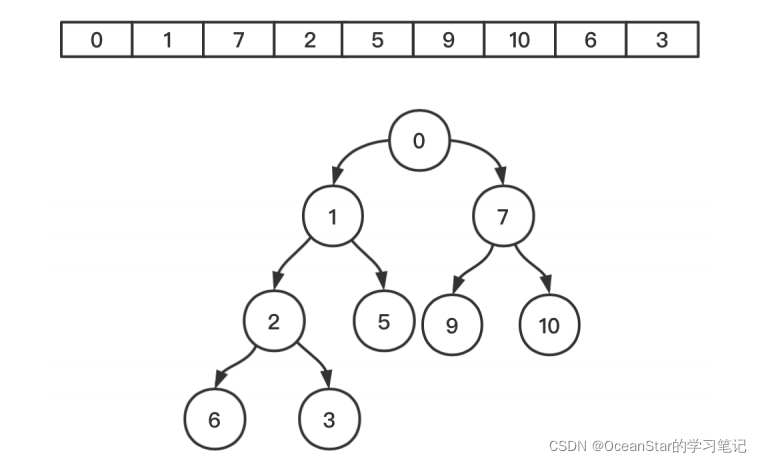
最小堆
- 是一颗完全二叉树
- 某一个节点的值总是小于等于它的子节点的值
- 堆中每个节点都是最小堆
#ifndef MARK_MINHEAP_TIMER_H
#define MARK_MINHEAP_TIMER_H
#if defined(__APPLE__)
#include <AvailabilityMacros.h>
#include <sys/time.h>
#include <mach/task.h>
#include <mach/mach.h>
#else
#include <time.h>
#endif
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
#include <stdint.h>
#include "minheap.h"
static min_heap_t min_heap;
static uint32_t
current_time() {
uint32_t t;
#if !defined(__APPLE__) || defined(AVAILABLE_MAC_OS_X_VERSION_10_12_AND_LATER)
struct timespec ti;
clock_gettime(CLOCK_MONOTONIC, &ti);
t = (uint32_t)ti.tv_sec * 1000;
t += ti.tv_nsec / 1000000;
#else
struct timeval tv;
gettimeofday(&tv, NULL);
t = (uint32_t)tv.tv_sec * 1000;
t += tv.tv_usec / 1000;
#endif
return t;
}
void init_timer() {
min_heap_ctor_(&min_heap);
}
timer_entry_t * add_timer(uint32_t msec, timer_handler_pt callback) {
timer_entry_t *te = (timer_entry_t *)malloc(sizeof(*te));
if (!te) {
return NULL;
}
memset(te, 0, sizeof(timer_entry_t));
te->handler = callback;
te->time = current_time() + msec;
if (0 != min_heap_push_(&min_heap, te)) {
free(te);
return NULL;
}
printf("add timer time = %u now = %u\n", te->time, current_time());
return te;
}
bool del_timer(timer_entry_t *e) {
return 0 == min_heap_erase_(&min_heap, e);
}
int find_nearest_expire_timer() {
timer_entry_t *te = min_heap_top_(&min_heap);
if (!te) return -1;
int diff = (int) te->time - (int)current_time();
return diff > 0 ? diff : 0;
}
void expire_timer() {
uint32_t cur = current_time();
for (;;) {
timer_entry_t *te = min_heap_top_(&min_heap);
if (!te) break;
if (te->time > cur) break;
te->handler(te);
min_heap_pop_(&min_heap);
free(te);
}
}
#endif // MARK_MINHEAP_TIMER_H
#include <stdio.h>
#include <sys/epoll.h>
#include "mh-timer.h"
void hello_world(timer_entry_t *te) {
printf("hello world time = %u\n", te->time);
}
int main() {
init_timer();
add_timer(3000, hello_world);
int epfd = epoll_create(1);
struct epoll_event events[512];
for (;;) {
int nearest = find_nearest_expire_timer();
int n = epoll_wait(epfd, events, 512, nearest);
for (int i=0; i < n; i++) {
//
}
expire_timer();
}
return 0;
}
// gcc mh-timer.c minheap.c -o mh -I./
可以将所有的定时器都放到一个[最小堆]中,并且在内部启动一个线程,持续检查堆顶的定时器是否已经到期,如果到期则触发对应的回调函数
- 获取堆顶的定时器,如果到期了就触发回调,并且如果该定时器是持续的则更新下次到期时间,并调整最小堆;如果不是则移除该定时器,同时也调整一次最小堆
- 没有到期则等待被唤醒,或者指定的时间间隔到达
将所有的定时器放到一个最小堆中,有几个明显的缺点:
- 当有多个线程同时运行的时候,容器造成锁竞争(所有对最小堆的操作但是有锁保护的)
- 当有很多的定时器存在时,最小堆的插入/删除效率也会降低
怎么优化呢?
- 将所有定时器分布到64个最小堆中,减少每个堆的数据量
- 插入定时器时用线程的id将其分布到不同的最小堆,这样插入时就可以降低锁竞争
还可以进一步优化:
- 将每个定时器直接帮到到检测线程上,这样可以随着检测线程扩展
为何要引入时间轮:
- 在定时器的数量增长到百万级之后,基于最小堆实现的定时器的性能会显著降低,需要一种更高效的实现
- 为什么能够降低:时间轮可减少额外的扫描操作。比如我的一批定时任务是在5s之后执行,那么我在4.5s之后才开始扫描这批定时任务,这样就大大节省了CPU。
时间轮
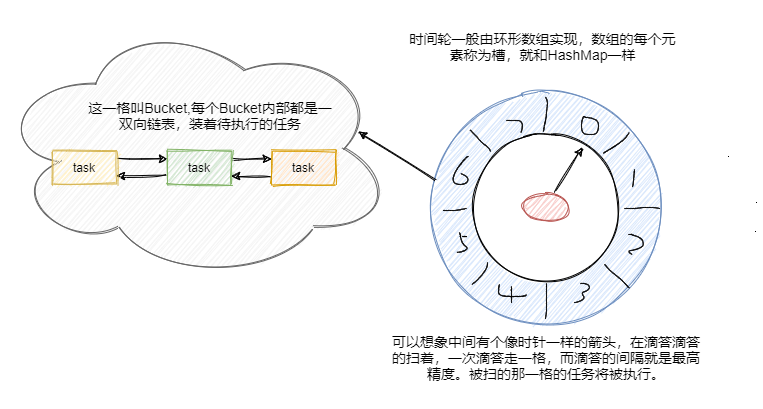
时间轮算法是通过一个时间轮去维护定时任务。一个时间轮就是一个环形结构,可以想象成时钟:
- 轮盘上有多个插槽,一个插槽代表一段时间
- 每隔固定的时间,就会从一个时间槽位调到下一个时间槽位
- 什么叫做固定的时间呢?也就是 怎么划分刻度呢?按照一定的时间单位对时间轮进行划分刻度。
- 如何设置时间论的周期和时间槽数呢?结合业务以及下面两个特点来考虑
- 时间槽位的单位时间越短,时间轮触发任务的时间越精确。比如时间槽位的单位时间是10ms,那么执行定时任务的时间误差就在 10 毫秒内,如果是 100 毫秒,那么误差就在 100 毫秒内。
- 时间轮的槽位越多,那么一个任务被重复扫描的概率就越小,因为只有在多层时间轮中的任务才会被重复扫描。比如一个时间轮的槽位有 1000 个,一个槽位的单位时间是 10毫秒,那么下一层时间轮的一个槽位的单位时间就是 10 秒,超过 10 秒的定时任务会被放到下一层时间轮中,也就是只有超过 10 秒的定时任务会被扫描遍历两次,但如果槽位是 10 个,那么超过 100 毫秒的任务,就会被扫描遍历两次。
- 定时任务是挂在插槽上的,每一个插槽上用list挂载了该格子上到期的所有任务
- 怎么知道应该插入到哪个插槽上呢?
- 根据任务延时计算任务落在该时间轮的第几个刻度上
- 任务时长超出了刻度数量,则需要增加一个参数记录时间轮需要转动的参数。
- 当时钟指到刻度上,我们就去执行对应的任务列表
- 轮询线程遍历到某一个时间刻度之后,总是执行对应刻度上任务队列中的所有任务(通常是将任务扔给异步线程池来处理)
- 这样就不再需要遍历检查所有任务的时间戳是否达到要求(不用每次从小顶堆堆顶,取数据来和时间比较,然后堆化这些操作)
- 将每个定时任务放到对应的时间槽上,可以减少扫描任务对其他时间槽位定时任务的额外遍历操作
- 时钟轮可以分为多层,下一层时钟轮中每个槽位的单位时间是当前时间论整个周期的时间(相当于 1 分钟等于 60 秒钟;)
- 当时钟轮将一个周期的所有槽位都跳动完之后,就会从下一层时钟轮中取出一个槽位的任务,重新分布到当前的时钟轮中
- 当前时钟轮则从第 0 槽位从新开始跳动,这就相当于下一分钟的第 1 秒。
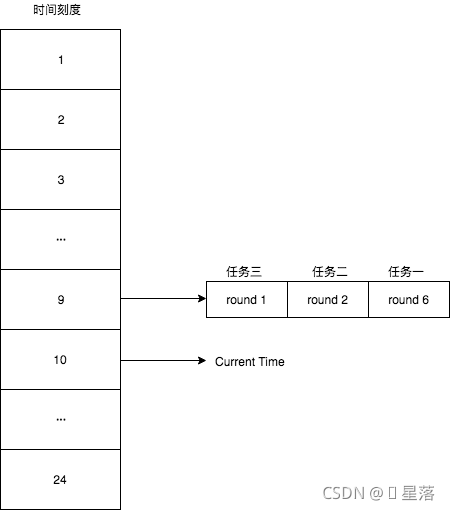
如上图:
- 可以看到指针指向的是第一个槽,一共有8个槽(0~7),假设槽的范围是1s,现在要加入一个延时5s的任务,计算方式就是5 % 8 + 1 = 6,即放到槽位6,下标为5的那个槽中。更具体的就是拼接到槽的双向链表的尾部。
- 然后每秒指针顺时钟移动一格,这样就扫描到了下一格,遍历这格中的双向链表中的任务。然后在循环继续
时间轮的数据结构:
- 时钟可以用数组或者循环链表表示,这样每个时钟的刻度就是一个槽,槽内用来存放该刻度需要执行的任务
- 如果有多个任务需要执行呢?每个槽内放一个链表就行了
比如说当我们需要在3小时、4小时、5小时之后执行某个任务,那么,如下图,我们做出一个时间轮,刻度是1h。
- 比如当前指针指向1的格子,现在我们接到了3h之后执行的任务,那么我们将任务挂到4的格子
- 这样,当我们走到4的格子之后,就将这个任务取出来
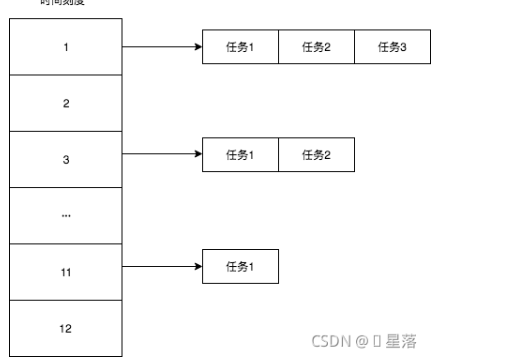
可以看到插入任务从计算槽位到插入链表,时间复杂度都是O(1)。
如果任务超出了刻度怎么办?比如说我有个任务,需要每周一上午9点指向,还有另一个任务,需要每周三的上午9点执行,怎么处理呢?
有如下方式:
- 一种是增加刻度(就是加槽扩容)。
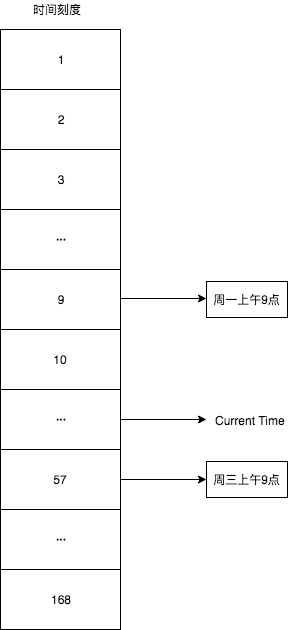
- 最直接的方式是增加时间刻度,比如说之前是时间,现在增加刻度变为分钟、秒。通过增加时间刻度,我们可以基于更精细的时间单位(分钟)来进行定时任务的执行。
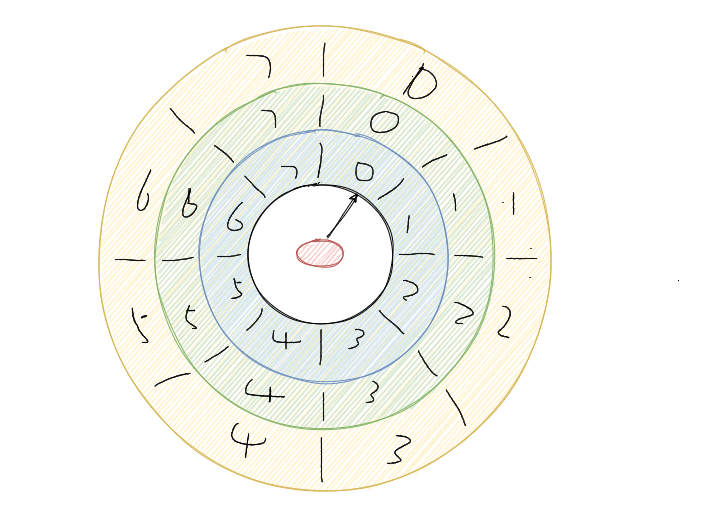
- 比如说,我们把时间轮的槽(刻度)从12个增加到168个,比如现在是星期二上午10点钟,那么下周一上午九点就是时间轮的第9个刻度,这周三上午九点就是时间轮的第57个刻度,示意图如下
- 但是,这种实现方式有如下的缺陷:
- 时间刻度太多会导致时间轮走到的多数刻度没有任务执行,比如一个月就2个任务,我得移动720次,其中718次是无用功。
- 时间刻度太多会导致存储空间变大,假如我们只有以秒为刻度,一天 24 * 60 * 60 = 86400秒,我们可能只占用几十或几百个刻度,大部分时间刻度所占用的内存空间是没有任何意义的。
- 一种是增加轮次的概念。
- 50 % 8 + 1 = 3,即应该放在槽位是 3,下标是 2 的位置。然后 (50 - 1) / 8 = 6,即轮数记为 6。也就是说当循环 6 轮之后扫到下标的 2 的这个槽位会触发这个任务。Netty 中的 HashedWheelTimer 使用的就是这种方式。
- 举个例子,假设当前的刻度还是24个,现在有3个任务需要执行。任务一每周二上午九点。任务二每周四上午九点。任务三每个月12号上午九点。比如现在是9月11号星期二上午10点,时间轮转一圈是24小时,到任务一下次执行(下周二上午九点),需要时间轮转过6圈后,到第7圈的第9个刻度开始执行。任务二下次执行第3圈的第9个刻度,任务三是第2圈的第9个刻度。
- 时间轮每移动一个刻度时,遍历任务列表,把round减1,然后取出所有round=0的任务执行
- 这样做能解决时间轮刻度范围过大造成的空间浪费,但是却带来了另一个问题:时间轮每次都需要遍历任务列表,耗时增加,当时间刻度粒度很小(秒级甚至毫秒级),任务列表又非常长时,这种遍历的方法是不可接受的
- 那有没有即省时间又省空间的方法呢?多层级时间轮
- 一种是通过多层次的时间轮。
- 多层级时间轮是基于这样一种思想:
- 针对时间复杂度的问题:不做遍历计算round,凡是任务列表中的都应该是被执行的,直接全部取出来执行
- 针对空间复杂度的问题:分层,每个时间粒度对应一个时间轮,多个时间轮之间进行级联操作
- 举个例子,比如我有三个任务:任务一每周二上午九点。任务二每周四上午九点。任务三每个月12号上午九点。
- 多层次时间轮就是这样做的。
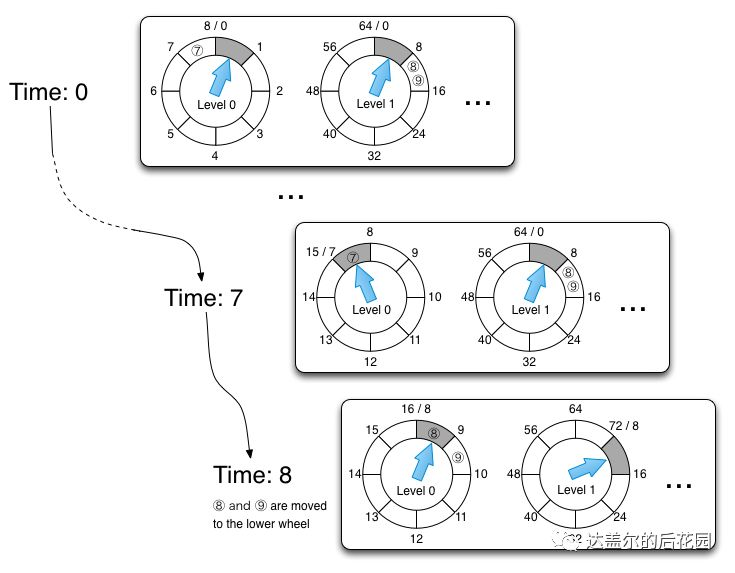
- 假设下图就是第一层,那么第一一层走了一圈,第二层就左一格
- 可以得到第二层的1格就是8s,假设第二层也是8个槽,那么第二层走一圈,第三层走一格,那么第三层就是64s
- 那么一格三层,每层8个槽,一共 24 个槽时间轮就可以处理最多延迟 512 秒的任务。
- 多层次时间轮还有降级的操作:
- 假设一个任务延迟500s执行,那么刚开始加进来一定是放到第三层的,当时间经过436s之后,此时还需要64s就会触发任务的执行,而此时相对而言它就是个延时64s后的任务,因此它会被降级到第二层中
- 再过56s,相对而言它就是个延时8s后执行的任务,因此它会再被降级到第一层中,等待执行。
-
降级是为了保证时间精度一致性
ps:时间轮除了定时任务之外,还能实现延迟消息的功能。比如让一个任务几分钟之后发送一条消息出去。在比如可以实现订单过期功能,用户下单10分钟没付款,就取消订单,可以通过时钟轮实现。
单层级时间轮
HashedWheelTimer是一个环形结构,可以用时钟来类比,钟面上有很多bucket,每一个bucket上可以存放多个任务,使用一个list保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格的转动,并执行对应bucket上所有到期的任务。任务通过取模决定应该放入哪个bucket。
从时钟表盘出发,如何⽤数据结构来描述秒表的运转
- int seconds[60]; // 数组来描述表盘刻度;
- ++tick%60;每秒中++tick来描述秒钟移动,对tick%60让秒钟永远在[0, 59]之间移动
- 对于时钟来说,它的时间精度(最小运行单元)是1秒
多级时间轮
时间轮小结:
怎么实现呢?
一个时间轮就是一个定时器容器,该容器可以高效的管理定时器。思路如下:
- 轮盘上有多个插槽
- 每个定时器都放置到合适的插槽中
- 每次轮询时直接获取最早的插槽中的定时器并触发即可
在层级时间轮中,将插槽分为多个层次,每一层的时间轮的插槽范围都会扩大。比如:
- 每一层时间轮有20个插槽,每个插槽为1s,那么第二层时间轮每个插槽为20s,第三层为400s,依次类推,除第一层外都是按需创建
- 当一个10s的定时器插入时放置到第一层时间轮中,100s的定时器放到第二层时间轮
- 随着时间的流逝,高层时间轮中的定时任务会降级重新插入到底层时间轮,直到触发位置
- 每个插槽共享一个触发时间,这样可以显著降低需要触发的事件的个数
举个例子:
- 假设我们的时钟轮有 10 个槽位,而时钟轮一轮的周期是 1 秒,那么我们每个槽位的单位时间就是 100 毫秒,而下一层时间轮的周期就是 10 秒,每个槽位的单位时间也就是 1 秒,并且当前的时钟轮刚初始化完成,也就是第 0 跳,当前在第 0 个槽位。
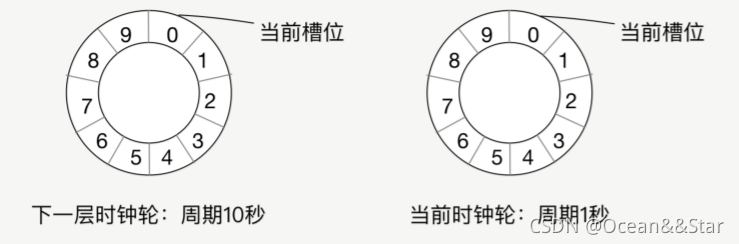
- 好,现在我们有 3 个任务,分别是任务 A(90 毫秒之后执行)、任务 B(610 毫秒之后执行)与任务 C(1 秒 610 毫秒之后执行),我们将这 3 个任务添加到时钟轮中,任务 A 被放到第 0 槽位,任务 B 被放到第 6 槽位,任务 C 被放到下一层时间轮的第 1 槽位,如下面这张图所示。
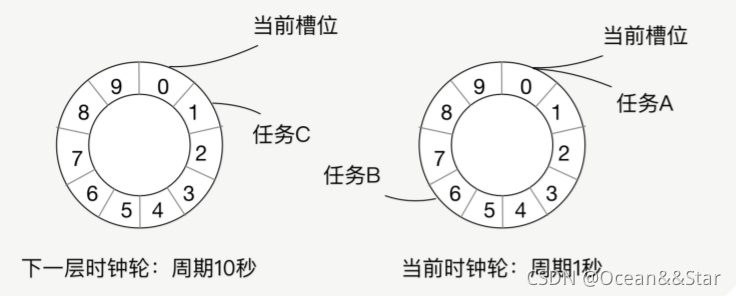
- 当任务 A 刚被放到时钟轮,就被即刻执行了,因为它被放到了第 0 槽位,而当前时间轮正好跳到第 0 槽位(实际上还没开始跳动,状态为第 0 跳);600 毫秒之后,时间轮已经进行了 6 跳,当前槽位是第 6 槽位,第 6 槽位所有的任务都被取出执行;1 秒钟之后,当前时钟轮的第 9 跳已经跳完,从新开始了第 0 跳,这时下一层时钟轮从第 0 跳跳到了第 1跳,将第 1 槽位的任务取出,分布到当前的时钟轮中,这时任务 C 从下一层时钟轮中取出并放到当前时钟轮的第 6 槽位;1 秒 600 毫秒之后,任务 C 被执行。

在这个例子中,时钟轮的扫描周期仍是 100 毫秒,但是其中的任务并没有被过多的重复扫描,它完美地解决了 CPU 浪费的问题