Hadoop配置
文章目录
- Linux shell
- 配置环境变量
- 使环境变量生效
- Hadoop 集群安装配置到两台阿里云linux主机上
- Hadoop集群模式安装
- 实验环境
- 实验内容
- 1.安装jdk
- 2.下面来修改环境变量
- 3.安装hadoop
- 4.下面来修改环境变量
- 5.修改hadoop hadoop-env.sh文件配置
- 6.修改hadoop core-site.xml文件配置
- 7.修改hadoop hdfs-site.xml文件配置
- 8.修改hadoop yarn-site.xml文件配置
- 9.mapred-site.xml文件配置
- 10.修改hadoop slaves文件配置
- 11.修改hosts文件
- 12.创建公钥
- 13.拷贝公钥
- 14.拷贝文件到所有从节点
- 15.格式化分布式文件系统
- 16.启动Hadoop
- 17.查看Hadoop进程
- 18.在命令行中输入以下代码,打开Hadoop WebUI管理界面:
- 19.测试HDFS集群以及MapReduce任务程序
- Extra Question
Linux shell
配置环境变量
sudo vim /etc/profile
添加以下的export语句
Eg:PATH=$PATH:$HOME/bin
1,$HOME这个代码表示一个环境变量($),它代表的是当前登录的用户的主文件夹的意思。(就是目录 ~ 的那个)
2,$HOME/bin这个代码指的就是主文件夹下的bin子目录,代表的是文件夹的内部子目录。(注意不是根目录的那个)
3,PATH=$PATH:$HOME/bin这个代码是设置PATH环境变量,就是设置环境变量用等号。首先:冒号是分割符。记得Windows上面也有PATH环境变量,Windows的路径之间的分隔符是;分号。
使环境变量生效
source /etc/profile
Hadoop 集群安装配置到两台阿里云linux主机上
-
Hadoop集群模式安装
实验环境
Linux Centos 6
实验内容
在Linux系统的服务器上,安装Hadoop3.0.0集群模式。

-
1.安装jdk
将/data/hadoop目录下jdk-8u161-linux-x64.tar.gz 解压缩到/opt目录下。
sudo tar -xzvf /data/hadoop/jdk-8u161-linux-x64.tar.gz -C /opt
其中,tar -xzvf 对文件进行解压缩,-C 指定解压后,将文件放到/opt目录下。
下面将jdk1.8.0_161目录重命名为java,执行:
sudo mv /opt/jdk1.8.0_161/ /opt/java
修改java目录的所属用户和所属组:
sudo chown -R dolphin.dolphin /opt/java
-
2.下面来修改环境变量
sudo leafpad /etc/profile
末端添加如下内容:
#java
export JAVA_HOME=/opt/java
export PATH=$JAVA_HOME/bin:$PATH

保存并关闭编辑器
让环境变量生效。
source /etc/profile
刷新环境变量后,可以通过java的家目录找到java可使用的命令。 利用java查看版本号命令验证是否安装成功:
java -version
正常结果显示如下

java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
-
3.安装hadoop
将hadoop-3.0.0.tar.gz解压缩到/opt目录下。
sudo tar -xzvf /data/hadoop/hadoop-3.0.0.tar.gz -C /opt/
为了便于操作,我们也将hadoop-3.0.0重命名为hadoop。
sudo mv /opt/hadoop-3.0.0/ /opt/hadoop
修改hadoop目录的所属用户和所属组:
sudo chown -R dolphin.dolphin /opt/hadoop
-
4.下面来修改环境变量
sudo leafpad /etc/profile
末端添加如下内容:
#hadoop
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
保存并关闭编辑器
让环境变量生效。
source /etc/profile
利用hadoop查看版本号命令验证是否安装成功:
hadoop version
正常结果显示如下
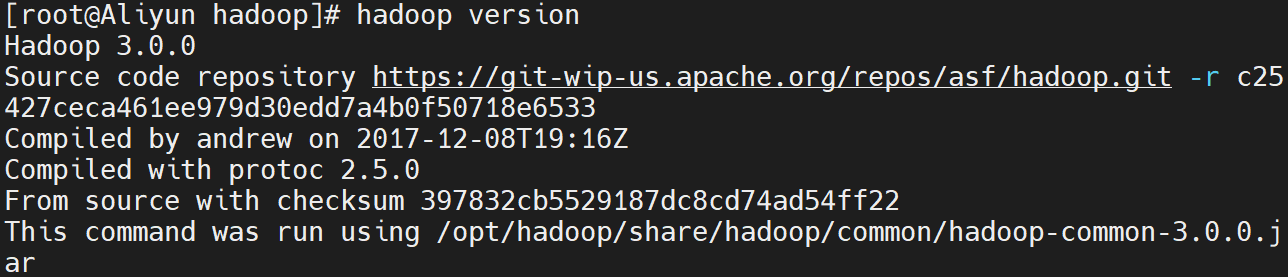
Hadoop 3.0.0
Source code repository https://git-wip-us.apache.org/repos/asf/hadoop.git -r c25427ceca461ee979d30edd7a4b0f50718e6533
Compiled by andrew on 2017-12-08T19:16Z
Compiled with protoc 2.5.0
From source with checksum 397832cb5529187dc8cd74ad54ff22
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-3.0.0.jar
-
5.修改hadoop hadoop-env.sh文件配置
leafpad /opt/hadoop/etc/hadoop/hadoop-env.sh
末端添加如下内容:
export JAVA_HOME=/opt/java/
保存并关闭编辑器
-
6.修改hadoop core-site.xml文件配置
leafpad /opt/hadoop/etc/hadoop/core-site.xml
添加下面配置到
<configuration>与</configuration>
标签之间。
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
保存并关闭编辑器
-
7.修改hadoop hdfs-site.xml文件配置
leafpad /opt/hadoop/etc/hadoop/hdfs-site.xml
添加下面配置到
<configuration>与</configuration>
标签之间。
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
保存并关闭编辑器
-
8.修改hadoop yarn-site.xml文件配置
leafpad /opt/hadoop/etc/hadoop/yarn-site.xml
添加下面配置到
<configuration>与</configuration>
标签之间。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
保存并关闭编辑器
-
9.mapred-site.xml文件配置
leafpad /opt/hadoop/etc/hadoop/mapred-site.xml
添加下面配置到
与
标签之间。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
保存并关闭编辑器
-
10.修改hadoop slaves文件配置
leafpad /opt/hadoop/etc/hadoop/workers
覆盖写入主节点映射名和从节点映射名:
master
slave1
保存并关闭编辑器
-
11.修改hosts文件
查看master ip地址
ifconfig eth0|sed -n '2p'|awk -F " " '{print $2}'|awk -F ":" '{print $2}'
记录下显示的ip
打开slave1 节点,做如上操作,记录下显示的ip
编辑/etc/hosts文件:
sudo leafpad /etc/hosts
添加master IP地址对应本机映射名和其它节点IP地址对应映射名(如下只是样式,请写入实验时您的正确IP):
172.25.200.236 master
8.129.5.124 slave1
-
12.创建公钥
在dolphin用户下创建公钥:
ssh-keygen -t rsa
-
13.拷贝公钥
提示:命令执行过程中需要输入“yes”和密码“dolphin”。三台节点请依次执行完成。
ssh-copy-id master
ssh-copy-id slave1
测试连接是否正常:
ssh master
-
14.拷贝文件到所有从节点
scp -r /opt/java/ /opt/hadoop/ slave1:/tmp/
至此,主节点配置完成。
-
15.格式化分布式文件系统
hdfs namenode -format
-
16.启动Hadoop
/opt/hadoop/sbin/start-all.sh
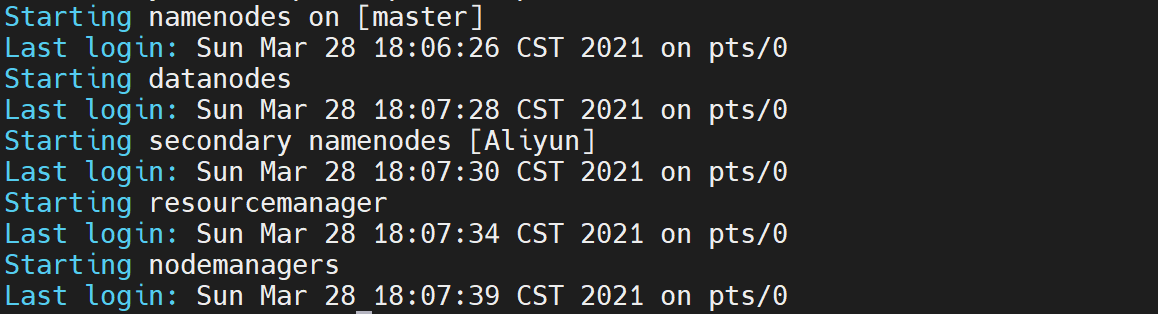
-
17.查看Hadoop进程
在hadoop主节点执行:
jps
输出结果必须包含6个进程,结果如下:

2529 DataNode
2756 SecondaryNameNode
3269 NodeManager
3449 Jps
2986 ResourceManager
2412 NameNode
在hadoop从节点执行同样的操作:
jps
输出结果必须包含3个进程,具体如下:
2529 DataNode
3449 Jps
2412 NameNode
-
18.在命令行中输入以下代码,打开Hadoop WebUI管理界面:
firefox http://master:8088
-
19.测试HDFS集群以及MapReduce任务程序
利用Hadoop自带的WordCount示例程序进行检查集群;在主节点进行如下操作,创建HDFS目录:
hadoop fs -mkdir /dolphin/
hadoop fs -mkdir /dolphin/input
创建测试文件
leafpad /home/dolphin/test
添加下面文字
dolphin
保存并关闭编辑器
将测试文件上传到到Hadoop HDFS集群目录:
hadoop fs -put /home/dolphin/test /dolphin/input
执行wordcount程序:
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /dolphin/input/ /dolphin/out/
查看执行结果:
hadoop fs -ls /dolphin/out/

如果列表中结果包含”_SUCCESS“文件,代码集群运行成功。
查看具体的执行结果,可以用如下命令:
hadoop fs -text /dolphin/out/part-r-00000

到此,集群安装完成。
Extra Question
如果出现
Call From master/ip to master:8088 failed on connection exception:…
在master主机的hosts文件 必须是:

/opt/hadoop/sbin/start-dfs.sh
g)
如果列表中结果包含”_SUCCESS“文件,代码集群运行成功。
查看具体的执行结果,可以用如下命令:
hadoop fs -text /dolphin/out/part-r-00000
到此,集群安装完成。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)