注意:
(1)派系过滤CPM方法(clique percolation method)用于发现重叠社区,派系(clique)是任意两点都相连的顶点的集合,即完全子图。
(2)所有彼此连通的k-派系构成的集合就是一个k-派系社区,其中一个k-派系与另一个k-派系有k-1个节点重叠,则这两个k-派系是连通的
1.1 方法
1.1.1从小派系到k-派系-社区
为了更精确,我们的算法首先提取网络中不属于更大的完全子图的所有完全子图。(此过程的细节将在第1.1.2节中讨论。)这些极大完全子图简称为派系,而k-派系与派系的区别在于k-派系可以是更大的完全子图的子集。
一旦找到了派系,派系-派系重叠矩阵就准备好了。在该对称矩阵中,每一行(和一列)表示一个派系,矩阵元素等于对应的两个派系之间的公共节点数,对角线项等于派系的大小。(注意,两个派系的交集总是一个完整的子图)。
给定k值的k-派系-社区等价于这样的连接集团组件,其中相邻的集团通过至少k−1个公共节点相互连接。
这些分量可以通过擦除每一个小于k−1的非对角项来找到以及矩阵中每一个小于k的对角元素,用1替换剩下的元素,然后对这个矩阵进行分量分析。
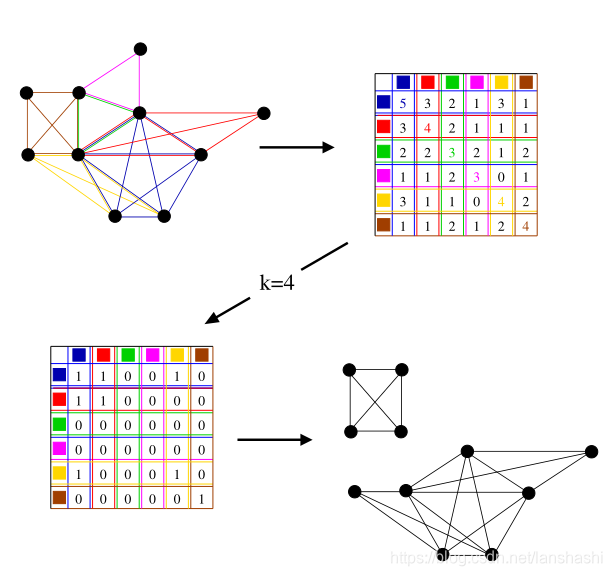
图1:使用派系-派系重叠矩阵提取k = 4处的k-派系-社区的简单说明。左上方的图片显示了不同派系用不同颜色标记的图表。根据派系-派系重叠矩阵显示在右上角。为了得到k = 4时的k-派系-社区,我们删除了小于3的非对角元素和小于4的对角元素,得到如图左下角所示的矩阵。与此矩阵相对应的连接组件(k-派系-社区)显示在右下角。
产生的独立组件相当于不同的k-派系-社区。图1给出了上述情况的一个简单说明。
该方法的另一个优点是,派系-派系重叠矩阵编码了对任意k值获取群落所需的所有信息,因此一旦构造了派系-派系重叠矩阵,就可以非常快速地获得k所有可能值的k-派系-社区。与此相反,在一个简单的k-派系查找方法中,对于每一个k值,都必须从头重新开始搜索k-派系。
1.1.2定位派系
如上一节所述,与k-clique相比,clique不能是更大的clique的子集,因此它们必须按照大小递减的顺序排列。根据结点度序列确定所研究图中可能的最大团数。从这个派系的大小(规模)开始,我们的算法反复选择一个节点,提取包含该节点的这个大小的每个派系,然后删除该节点及其边。(删除已经检查过的节点将阻止多次查找相同的派系)。当没有节点留下时,团的大小减少1,并在原始图上重新启动查找团的过程。已经找到的派系影响进一步的搜索,因为尚未显示的(较小的)派系不能是他们的子集。通过检查v的邻居之间的相互关系,可以找到包含给定节点v的大小为s的派系。在我们的算法中,这是通过以下方式实现的:
(1)首先,构造一个集合A它包含所有相互连接的节点。最初A只由v组成,我们的目标是将这个集合扩大到实际的集团大小s。另一个分离集B也被确定为链接到A中的每个节点的节点集,但不一定链接到B中的节点。最初集合B由v的邻居组成。
(2)从B转移节点到A(扩大集合A)。这是通过递归的方式完成的,以便检查被传输的节点的每一个可能的组合。(为了避免多次找到同一个派系,节点必须按照索引的递增/递减顺序从B转移到A)。当一个来自B的节点w被放到A中,不是w邻居的节点被从B中移除。(这样做是为了保持B的所有成员都链接到A的每个成员的属性)。如果B在A达到s大小之前就耗尽了节点,或者如果集合A和B的并集可以包含在一个已经找到的(更大的)组中,那么递归将被后退以检查其他可能性。当A的大小达到s时,就会发现一个新的小集团。在记录派系之后,算法将再次后退,以检查相邻索引的剩余可能组合。
图解:

对比下图:

参考文献:
Uncovering the overlapping community structure of complex networks in nature and society
社区发现算法(三)_I am not a quitter.-CSDN博客
CPM(Cluster Percolation method)派系过滤算法_u011089523的博客-CSDN博客