1. 思路分析
1.1 网页关系分析
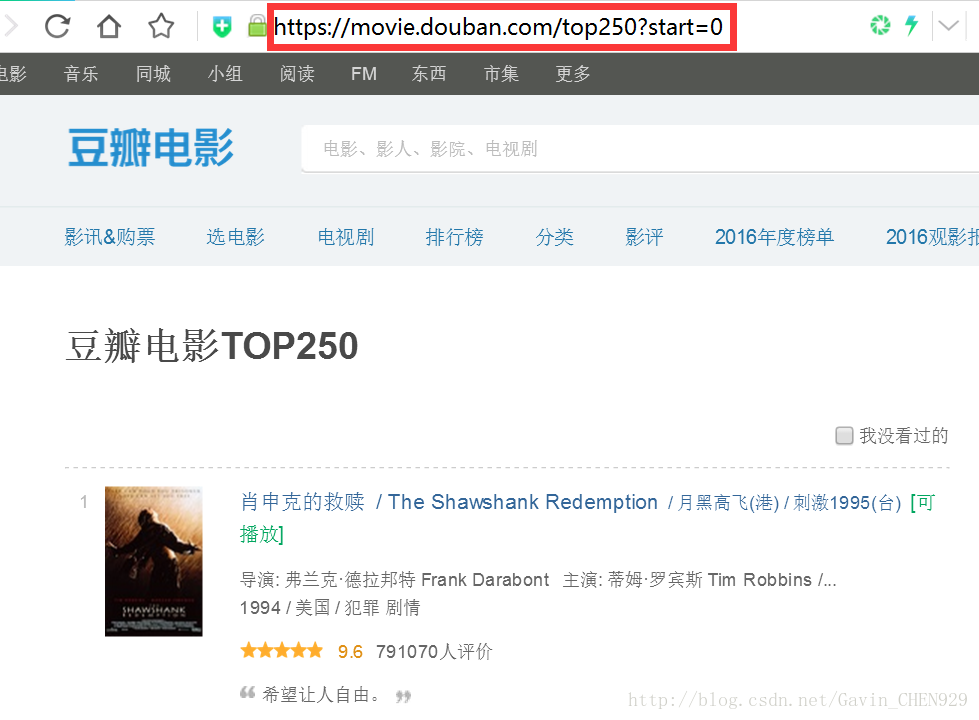
上图红框内是第一页网址
第一页网址:https://movie.douban.com/top250?start=0
第二页网址:https://movie.douban.com/top250?start=25
…
第十页网址:https://movie.douban.com/top250?start=225
可以看出存在规律,实际就是每页展示25部电影。
1.2 页面内容定位
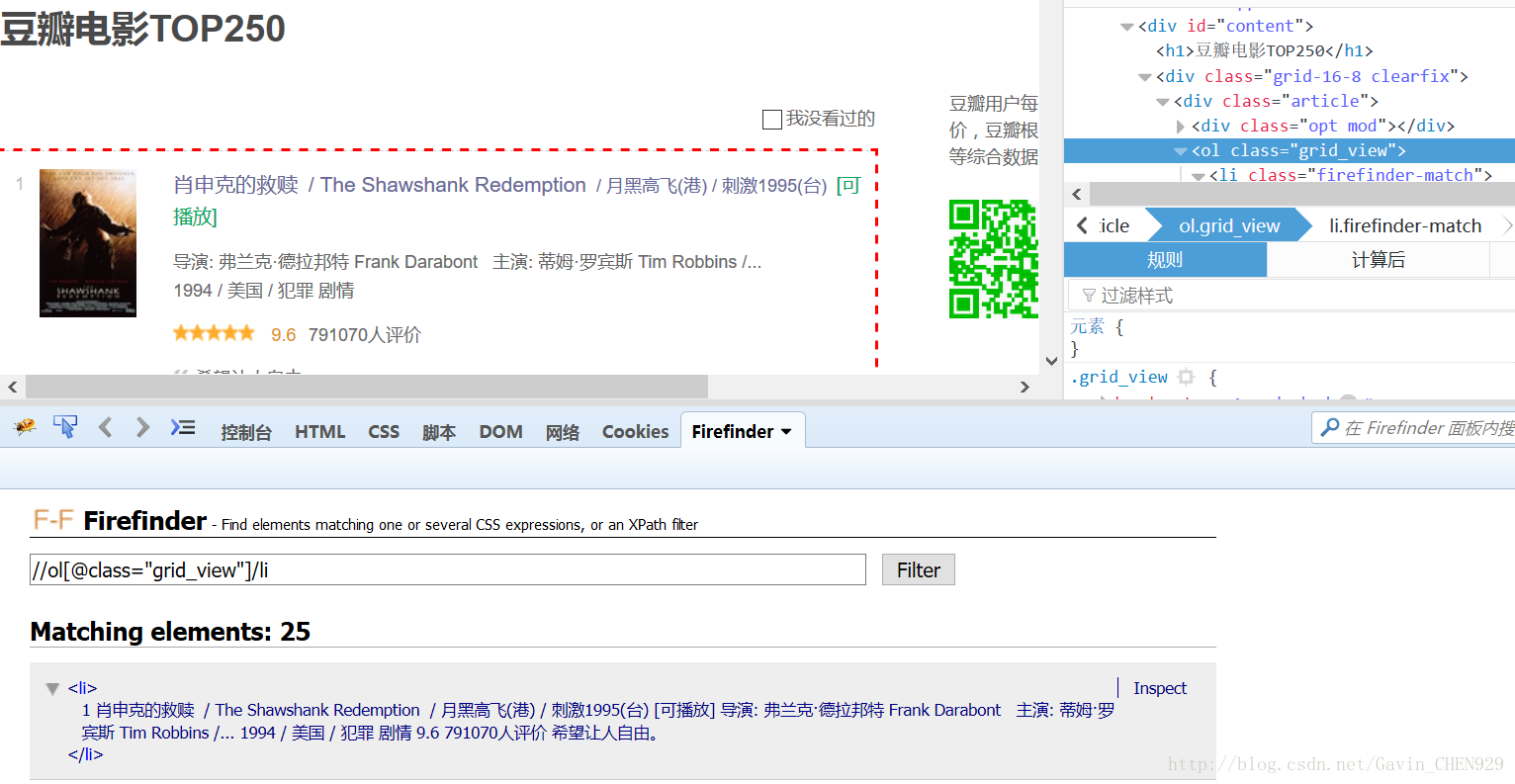
由于使用scrapy框架,可用Xpath表达式定位元素。
推荐可以使用Firefox的Firefinder插件结合Xpath,快速的定位到想要提取的元素。
2. 创建项目编写爬虫
创建一个项目目录douban
scrapy startproject douban
进入douban目录创建爬虫film
scrapy genspider -t basic film movie.douban.com
items.py代码如下
import scrapy
class DoubanItem(scrapy.Item):
rank = scrapy.Field()
title = scrapy.Field()
dr = scrapy.Field()
act = scrapy.Field()
ty = scrapy.Field()
yr = scrapy.Field()
con = scrapy.Field()
des = sc