什么是MapReduce?
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
MapReduce的来源
MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法。
Google公司设计MapReduce的初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理。Google公司发明了MapReduce之后首先用其重新改写了其搜索引擎中的Web文档索引处理系统。
但由于MapReduce可以普遍应用于很多大规模数据的计算问题,因此自发明MapReduce以后,Google公司内部进一步将其广泛应用于很多大规模数据处理问题。Google公司内有上万个各种不同的算法问题和程序都使用MapReduce进行处理。
MapReduce提供了以下的主要功能:
1)数据划分和计算任务调度:
2)数据/代码互定位:
3)系统优化:
4)出错检测和恢复:
MapReduce框架介绍
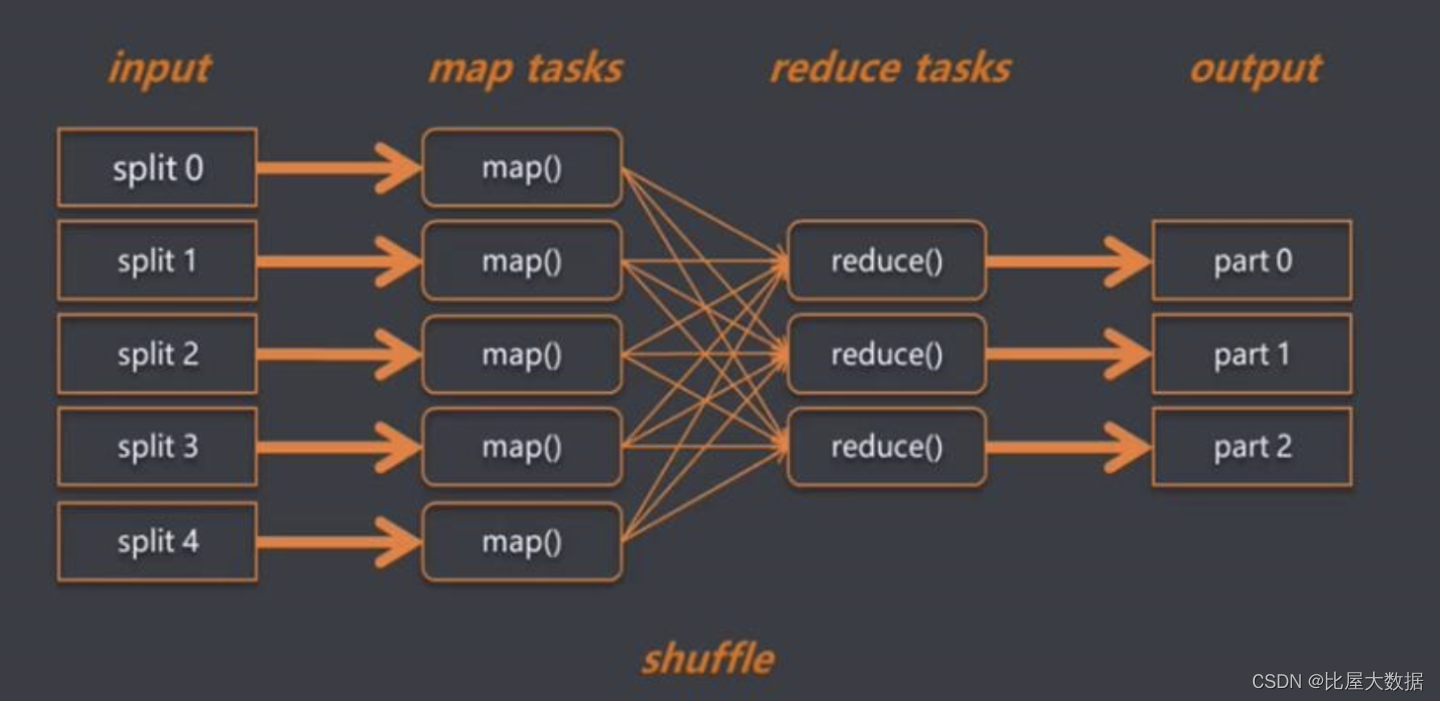
MR的数据处理流程
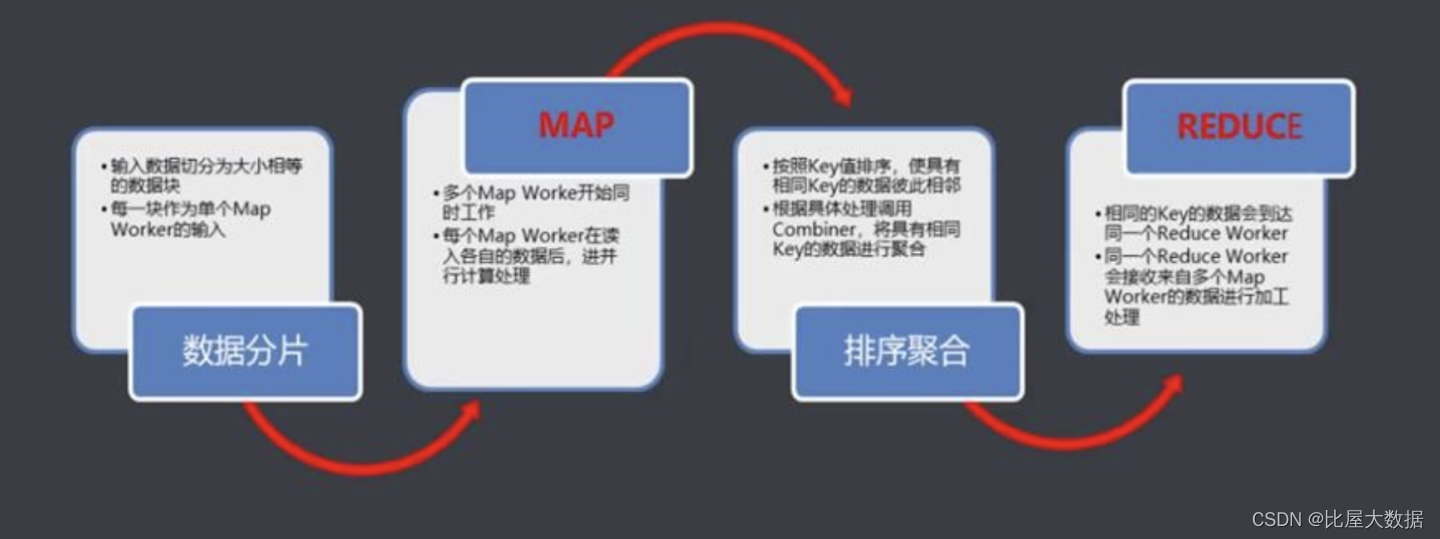
MR模型的适用场景
- 搜索:网页爬取、倒排索引、PageRank。
- Web访问日志分析:分析和挖掘用户在web上的访问、购物行为特征,实现个性化推荐;分析用户访问行为。
- 文本统计分析:比如莫言小说的WordCount、词频TFIDF分析;学术论文、专利文献的引用分析和统计;维基百科数据分析等。
- 海量数据挖掘:非结构化数据、时空数据、图像数据的挖掘。
- 机器学习:监督学习、无监督学习、分类算法如决策树、SVM等。
- 自然语言处理:基于大数据的训练和预测;基于语料库构建单词同现矩阵,频繁项集数据挖掘、重复文档检测等。
- 广告推荐:用户点击(CTR)和购买行为(CVR)预测。
Mapreduce框架应用
map: (K1,V1) → list (K2,V2)
reduce: (K2,list(V2)) → list (K3,V3)
map和reduce的输入输出都是key-value
我们写mapreduce程序需要指定:
map阶段的key,value类型
reduce阶段的key,value类型
Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 类
KEYIN:map阶段的输入类型
VALUEIN:map阶段的输出类型
KEYOUT:reduce阶段的数据类型
VALUEOUT:reduce阶段的输出类型
作用:本地数据优化(必须要做的)
可以选择的,配置就行了
map阶段处理完成,传输到reduce阶段的策略
相同的key的数据会被发送到同一个reduce
举例:统计所有湖北省的手机号有多少个
手机号如果是150,159开头的当作key进行分区
Default is the HashPartitioner that performs a modulo against the numOfPartitions to return the partition number (默认值是HashPartitioner,它对numOfPartitions执行取模以返回分区号)
源代码: return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
指的是:数据由map到reduce的过程
数据经过网络传输和排序
Reducer<K2, V2, K3, V3>类
K2:map阶段输入类型
V2:map阶段输出类型
K3:最终输出到HDFS key的类型
V3:最终输出到HDFS value的类型
//1.获取配置对象
Configuration conf = getConf();
//2.创建job对象
conf.set("fs.defaultFS","hdfs://hadoop5:8020");
Job job = Job.getInstance(conf, "WordCountMapReduce");
job.setJarByClass(this.getClass());
// 3.设置输入路径和格式,指定数据源,也就是hdfs上的目录
//input path
FileInputFormat.addInputPath(job,new Path(args[0]) );
//input format
job.setInputFormatClass(TextInputFormat.class);
// 4.设置输出路径和格式,数据输出,最终结果保存在哪里
// output path and output format
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setOutputFormatClass(TextOutputFormat.class);
//5 设置map类和reduce类
job.setMapperClass(WordCountMapper.class);
// map阶段输出key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//6. 设置Combiner,Map阶段完成后的优化策略,可以让数据本地聚合
job.setCombinerClass(WCReducer.class);
// 7. reduce类
job.setReducerClass(WordCountReducer.class);
// reduce阶段输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//8.提交程序
job.waitForCompletion(true) ? 0 : 1;
视频课程戳⬇⬇⬇
领取更多大数据开发学习教程