Ditmars.RELEASE
1.Spring Cloud Stream 介绍
Spring Cloud Stream是一个用于构建消息驱动应用的微服务框架。Spring Cloud Stream基于Spring Boot来构建独立生产级的Spring应用,并且利用Spring Integeration提供与消息代理连接的能力。它提供来自多个供应商的中间件自定义配置,并且引入了持久性发布 - 订阅,以及消费组和分区的概念。
你可以将@EnableBinding注解添加到你的应用程序中,以立即连接到消息代理,并且你可以将@StreamListener注解添加到方法上,以使其接收并处理流事件。 以下是接收并处理来自外部传入消息的简单接收器应用示例。
@SpringBootApplication @EnableBinding(Sink.class)
public class VoteRecordingSinkApplication {
public static void main(String[] args){
SpringApplication.run(VoteRecordingSinkApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void processVote(Vote vote) {
votingService.recordVote(vote);
}
}
@EnableBinding注解可以将一个或多个接口作为参数(在这个案例中,参数是一个Sink接口)。 Spring Cloud Stream提供开箱机用的Source,Sink和Processor接口,你也可以定义适合自己的接口。
以下是Sink接口的定义:
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
@Input注解绑定一个输入通道,通过它接收消息到应用程序。@Output注解绑定一个输出通道,发布的消息通过这个通道离开应用程序。 @Input和@Output注解可以将通道名称作为参数。如果没有提供名称,则使用被注释的方法的方法名作为通道名称。
Spring Cloud Stream会为你创建一个针对于该接口的实现。 你可以在应用程序中通过自动装配来使用它,如下面的测试用例所示。
@RunWith(SpringJUnit4ClassRunner.class) @SpringApplicationConfiguration(classes=VoteRecordingSinkApplication.class)
@WebAppConfiguration
@DirtiesContext
public class StreamApplicationTests {
@Autowired
private Sink sink;
@Test
public void contextLoads() {
assertNotNull(this.sink.input());
}
}
2.重要概念
Spring Cloud Stream提供了许多抽象和原语,用于简化针对于消息驱动的微服务应用程序的编写。 本节将概述以下内容:
- Spring Cloud Stream的应用程序模型
- Binder抽象
- 持久的发布 - 订阅支持
- 消费者群体支持
- 分区支持
- 可插入的Binder API
2.1应用模型(Application model)
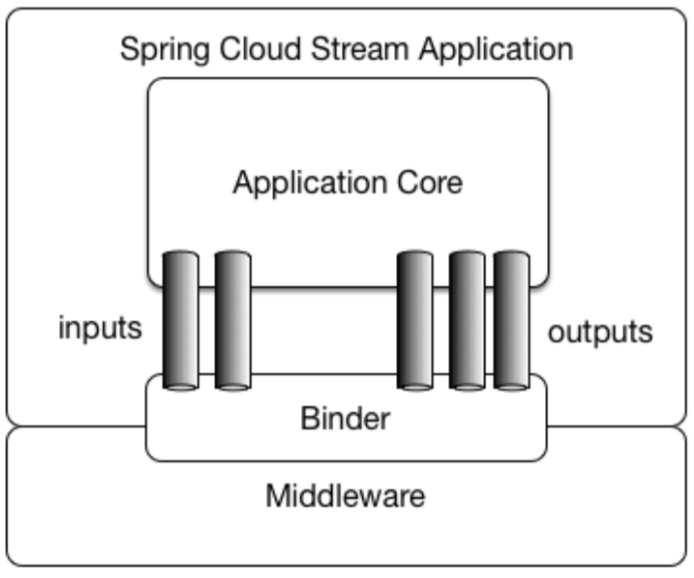
Spring Cloud Stream应用程序由一个middleware-neutral核心组成。 应用程序通过Spring Cloud Stream注入的输入和输出通道与外界进行通信。 这些通道需要通过目标中间件特定的绑定器实现与外部消息代理建立连接。
Fat JAR
Spring Cloud Stream应用程序可以在IDE中独立运行进行测试。 如果要在生产环境中运行Spring Cloud Stream应用程序,可以使用Maven或Gradle提供的标准Spring Boot插件来创建可执行的(或“fat”)JAR。
2.2 绑定器的抽象(The Binder Abstraction)
Spring Cloud Stream为Kafka和RabbitMQ提供了单独的绑定器(Binder)实现。 Spring Cloud Stream还包含一个TestSupportBinder组件,它可以让消息通道保持不变,以便测试时可以直接与通道交互,并且可以确保收到消息的通道就是你期望的通道。 你也可以使用可扩展的API编写你自己的Binder实现。
Spring Cloud Stream基于Spring Boot进行配置,同时Binder的抽象使得Spring Cloud Stream应用程序可以灵活地连接到指定的中间件服务。 例如,在程序运行期间,可以动态切换通道所连接的中间服务(例如Kafka的topics或RabbitMQ的exchanges)。 这可以通过外部属性配置,以及Spring Boot支持的任何形式(包括应用参数,环境变量,application.yml或application.properties文件)来配置。 在第1章“Spring Cloud Stream介绍”一节中的接收器示例中,将应用程序属性spring.cloud.stream.bindings.input.destination设置为raw-sensor-data将使我们的应用从原来读取数据的默认通道(比如默认有一个input通道)切换到raw-sensor-data通道读取数据。
Spring Cloud Stream会自动检测并使用类路径中所找到的binder。 你可以用相同的代码轻松享受不同中间件所提供的服务:就是说在构建时你只需指定一个适合的中间件binder即可,代码是通用的无需修改。 对于更复杂的用例,你还可以将多个中间件服务的binder与你的应用程序整合在一起,然后在运行时为不同的通道使用不同的中间件binder来提供服务。
2.3持久的发布 - 订阅支持
应用程序之间的通信遵循发布 - 订阅模式(publish-subscribe),数据通过共享主题(topic)进行广播。 在下图中可以看到,其中显示了一组典型的Spring Cloud Stream应用程序相互作用的部署形式。
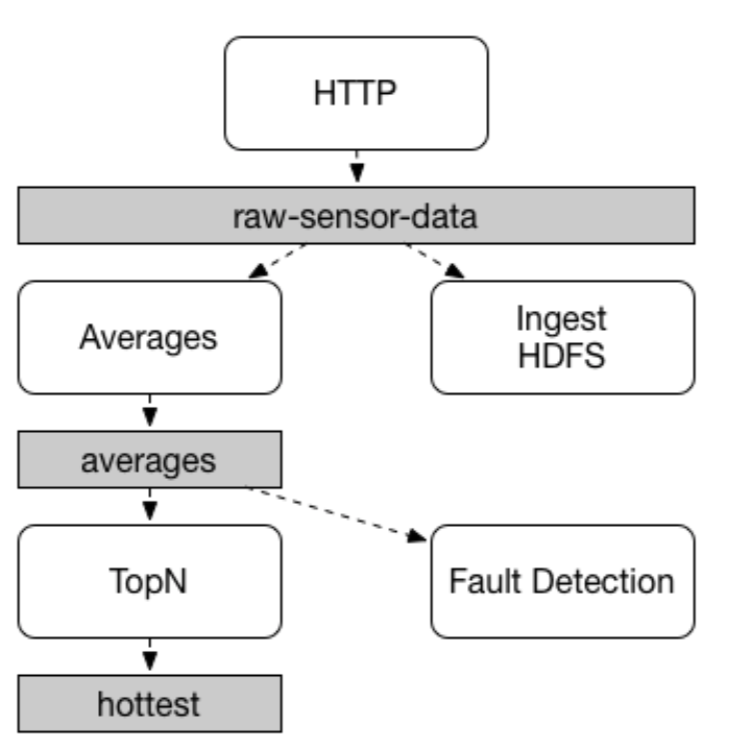
HTTP端点发布的数据被发送到名为raw-sensor-data通道。 从这儿开始,数据便由一个计算时间窗平均值的微服务应用和一个需要将原始数据读入到HDFS的微服务应用进行独立地处理。 为了能获得数据进行消费,两个应用程序在运行时都需声明这个topic,即将raw-sensor-data作为它们的订阅通道。
发布 - 订阅通信(publish-subscribe)模型降低了生产者和消费者的复杂结合,允许将新的应用程序添加到拓扑中,从而不中断现有的流程。 例如,在平均计算应用程序的下游,您可以添加一个应用程序来计算和显示监视的最高温度值。 然后还可以添加另一个应用程序来解释相同的平均流量以进行对比性故障检测。 通过共享主题而不是点对点的队列进行通信可以减少微服务之间的耦合。
虽然发布 - 订阅的概念并不新鲜,但Spring Cloud Stream增加了额外的支持,使其成为这种应用程序模式的可选项。 由于使用了本地中间件支持,Spring Cloud Stream因此也有了简化使用跨不同平台的发布 - 订阅模型的能力。
2.4消费者分组(consumer group)
尽管发布 - 订阅模型使得通过共享主题连接应用变得很容易,但要想通过创建特定应用的多个实例来扩展服务能力变得方便也同样重要。 当这样做的时候,一个应用程序的不同实例便被放置在一个具有竞争属性的消费者关系组中,组里面的这些实例只有一个能够消费消息。
Spring Cloud Stream通过消费组(consumer group)的概念来模拟这种情景。 (Spring Cloud Stream的消费组(consumer group)与Kafka 的消费组(consumer group)相似,并且也受其启发。)每个消费者绑定可以使用spring.cloud.stream.bindings..group属性来指定一个群组(group)。 对于下图中显示的消费者,此属性应设置为:
spring.cloud.stream.bindings..group = hdfsWrite 或
spring.cloud.stream.bindings..group = average。
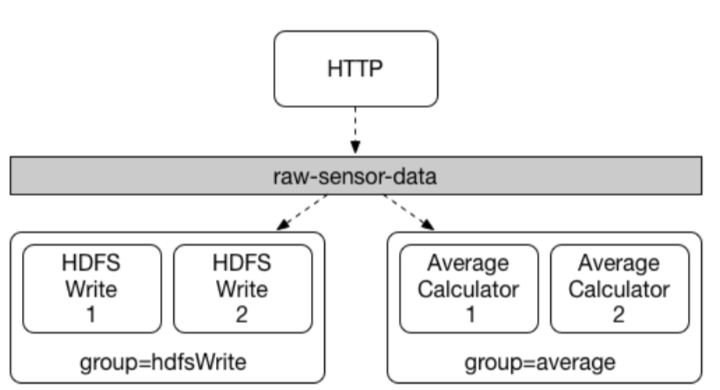
所有订阅指定通道(raw-sensor-data)的组都会收到一份已发布数据的副本,但每个组中只有一个成员能够收到此消息。 默认情况下,当未指定分组时,Spring Cloud Stream将会为该应用程序分配一个匿名独立的分组,与其他所有消费分组处于同一个发布 - 订阅环境中。
持久性(Durability)
与Spring Cloud Stream一贯的应用程序模式一致,消费组订阅是持久的。 也就是说,绑定器的实现已经确保了组订阅持久性,一旦创建了一个组的至少一个订阅,即使在组中的所有应用程序都停止了,消息也将会被发送到组。
注意:
匿名订阅本质上可以是非持久的。 对于一些绑定器的实现(例如,RabbitMQ),可能需要非持久的订阅。
通常,将应用程序绑定到指定通道的时候,有必要为输出通道指定一个消费组。 在扩展Spring Cloud Stream应用程序时,您也必须为每个订阅应用的输入通道绑定指定的消费组。 这可以防止应用程序的实例接收到重复的消息(除非你允许这种行为)。
2.5分区支持(Partitioning Support)
Spring Cloud Stream支持在特定应用程序的多个实例之间对数据进行分区消费。 在这种分区方案中,通信代理(broken topic)可以被理解为进行了同样的分区划分。 一个或多个生产者应用程序的实例将数据发送给多个消费者应用程序实例消费的时候,需要确保具有共同特征标识的数据由同一个消费者实例进行处理。
Spring Cloud Stream为了统一实现分区处理功能提供了一个通用的抽象。 无论代理服务本身是支持分区的(例如Kafka)还是不支持的(例如RabbitMQ),都可以使用分区。
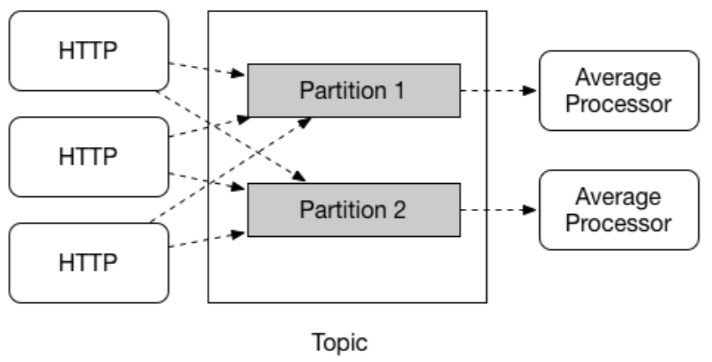
分区在有状态处理中是一个至关重要的概念,无论是基于性能还是一致性的原因,为了确保所有相关数据经由同一个处理单元处理,分区都是至关重要的。 例如,在时间窗平均计算示例中,来自任何特定传感器的所有测量值都需要由相同的消费者应用实例处理,这显然迎合了这种场景。
注意:
要使用分区处理,你必须同时对生产者和消费者进行配置。
3编程模型(Programming Model)
本节介绍Spring Cloud Stream的编程模型。 Spring Cloud Stream提供了许多预定义的注解来声明和绑定输入输出通道,以及监听通道。
3.1生命和绑定通道(Declaring and Binding Channels)
通过@EnableBinding建立绑定
您可以将@EnableBinding注解应用于其中一个应用程序的配置类,以使Spring应用转换为Spring Cloud Stream应用。 @EnableBinding注解本身就使用了@Configuration注解,因此会触发对Spring Cloud Stream基础结构的配置:
...
@Import(...)
@Configuration
@EnableIntegration
public @interface EnableBinding {
...
Class<?>[] value() default {};
}
@EnableBinding注解可以将一个或多个具有绑定通道方法的接口作为参数。
注意
@EnableBinding注解仅需在你的配置类中配置,你可以根据需要提供尽可能多的接口,例如:@EnableBinding(value = {Orders.class,Payment.class}),其中Order和Payment接口将提供@Input和@Output绑定的通道。
@Input and @Output
Spring Cloud Stream应用程序可以在接口中用@Input和@Output定义任意数量的输入和输出通道:
public interface Barista {
@Input
SubscribableChannel orders();
@Output
MessageChannel hotDrinks();
@Output
MessageChannel coldDrinks();
}
将此接口用作@EnableBinding的参数将触发创建名为orders,hotDrinks和coldDrinks的三个通道。
@EnableBinding(Barista.class)
public class CafeConfiguration {
...
}
注意
在Spring Cloud Stream中,可绑定的消息通道组件有Spring用于传递消息的MessageChannel(用于传出)及其扩展的SubscribableChannel(用于传入)组件。 使用的是与其他可绑定组件相同的机制。 在Spring Cloud Stream的Kafka binder中,KStream就是作为传入/传出时一个可被绑定的组件。 而在本文档中,我们将以MessageChannels这个可绑定组件为主要研究对象。
自定义通道名(Customizing Channel Names)
使用@Input和@Output注解,你可以为通道指定自定义的通道名称,如以下示例所示:
public interface Barista {
...
@Input("inboundOrders")
SubscribableChannel orders();
}
在这个例子中,创建的通道将被命名为inboundOrders。
Source, Sink, 和 Processor
为了便于处理最常见的使用情景(比如仅有输入通道,仅有输出通道或两者都有),Spring Cloud Stream提供了三种预定义的接口。
Source可用于具有单个传出通道的应用。
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}
Sink可用于具有单个传入通道的应用。
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
Processor可用于具有传入通道和传出通道的应用。
public interface Processor extends Source, Sink {
}
Spring Cloud Stream不为这些接口提供特殊处理; 仅仅是提供了开箱即用的能力。
访问绑定的频道(Accessing Bound Channels)
注入绑定的接口(Injecting the Bound Interfaces)
对于每个已被绑定的接口,Spring Cloud Stream将生成一个实现了对应接口的bean。 调用一个被@Input或@Output修饰的bean方法后,将返回与之相关的绑定通道。
以下示例中的bean在调用sayHello方法时会通过输出通道发送消息。 它调用注入的Source bean上的output()来获取目标通道。
@Component
public class SendingBean {
private Source source;
@Autowired
public SendingBean(Source source) {
this.source = source;
}
public void sayHello(String name) {
source.output().send(
MessageBuilder.withPayload(name).build()
);
}
}
直接注入通道(Injecting Channels Directly)
绑定的通道也可以被直接注入:
@Component
public class SendingBean {
private MessageChannel output;
@Autowired
public SendingBean(MessageChannel output) {
this.output = output;
}
public void sayHello(String name) {
output.send(
MessageBuilder.withPayload(name).build()
);
}
}
如果通道的名称是在注释中声明的,则使用时的通道名称应该是定制的名称而不是方法名称。 鉴于以下声明:
public interface CustomSource {
...
@Output("customOutput")
MessageChannel output();
}
通道被直接注入的案例如下所示:
@Component
public class SendingBean {
private MessageChannel output;
@Autowired
public SendingBean(@Qualifier("customOutput") MessageChannel output) {
this.output = output;
}
public void sayHello(String name) {
this.output.send(
MessageBuilder.withPayload(name).build()
);
}
}
生产与消费消息(Producing and Consuming Messages)
您可以使用Spring Integration的注解或Spring Cloud Stream的@StreamListener注解编写Spring Cloud Stream应用程序。 @StreamListener注解模仿的是其他Spring Message类型的注解(例如@MessageMapping,@JmsListener,@RabbitListener等),不过额外添加了内容类型管理和类型转换功能。
本地Spring Integeration支持(Native Spring Integration Support)
由于Spring Cloud Stream是基于Spring Integration的,因此Spring Cloud Stream完全继承了Spring Integration的基建设施以及组件本身。 例如,你可以将Source的输出通道对接到MessageSource:
@EnableBinding(Source.class)
public class TimerSource {
@Value("${format}")
private String format;
@Bean
@InboundChannelAdapter(
value = Source.OUTPUT,
poller = @Poller(fixedDelay = "${fixedDelay}",
maxMessagesPerPoll = "1"))
public MessageSource<String> timerMessageSource() {
return () -> new GenericMessage<>(
new SimpleDateFormat(format).format(
new Date()
)
);
}
}
或者你可以结合转换器和Processor提供的通道一起使用:
@EnableBinding(Processor.class)
public class TransformProcessor {
@Transformer(
inputChannel = Processor.INPUT,
outputChannel = Processor.OUTPUT)
public Object transform(String message) {
return message.toUpperCase();
}
}
注意
重要的是要明白,当多个被@StreamListener注解修饰的方法订阅同一个通道时,就已经形成了pub-sub模式,每个使用@StreamListener注解的方法都会收到一份属于自己的消息副本,每个方法都有自己的消费分组(匿名的)。 但是,如果您将一个通道作为@Aggregator,@Transformer或@ServiceActivator的输入通道,则这个通道发出的消息将在竞争模式中被消费,因此便不会为每个订阅者创建单独的消费组。
Spring Integeration的错误通道支持(Spring Integration Error Channel Support)
Spring Cloud Stream支持Spring Integration所提供的全局“错误通道”来接收那些发布出错消息的能力。发送出错的消息可以通过一个名为error的绑定来将消息发布到特定的地方。 例如,要将错误消息发布到名为“myErrors”的代理目标,只需提供以下的属性配置:spring.cloud.stream.bindings.error.destination = myErrors。
消息通道绑定器和错误通道(Message Channel Binders and Error Channels)
自版本1.3开始,支持了一些能将出错消息发布到“错误通道”的绑定器。 此外,这些错误通道会被桥接到上面提到Spring Integeration提供的全局“错误通道”上。 因此,您可以使用标准的Spring Integration流(IntegrationFlow,@ServiceActivator等)来消费局部或全局的出错消息。
在客户端,监听器线程捕获任何异常后,会将出错消息转发到指定的错误通道。 消息的有效实体通常具有错误消息本身(failedMessage)和错误原因(MessagingException)。 通常,从代理收到的原始数据会包含在header中。 对于支持(或配置)了“错误通道”的绑定,会有一个MessagePublishingErrorHandler订阅该“错误通道”,原始数据将被转发至此。
在生产者(Producer)方面; 对于一些发布消息后支持某种异步结果的绑定器(例如RabbitMQ,Kafka),可以通过将… producer.errorChannelEnabled设置为true来启用错误通道。 ErrorMessage的有效实体取决于绑定器的具体实现,但都会有一个带有failedMessage属性的MessagingException,和关于失败信息的附加属性。 有关完整的详细信息,请参阅Binder文档。
使用@StreamListener进行自动内容类型处理
作为Spring Integration支持的补充,Spring Cloud Stream提供了自己的@StreamListener注解,模仿其他的Spring Messaging注解(例如@MessageMapping,@JmsListener,@RabbitListener等)。 @StreamListener注解为传入的消息的处理提供了一个更简单的模型,特别是在处理涉及到内容类型管理和类型转换的场景时。
Spring Cloud Stream提供了一个可扩展的消息转换器(MessageConverter)机制来处理经由绑定通道处理的数据转换,并且会将消息分发到使用了@StreamListener注解的方法进行处理。 以下是一个针对于处理投票事件的应用程序示例:
@EnableBinding(Sink.class)
public class VoteHandler {
@Autowired
VotingService votingService;
@StreamListener(Sink.INPUT)
public void handle(Vote vote) {
votingService.record(vote);
}
}
考虑到具有String类型或application / json类型数据的带contentType头(header)的消息传入时,@StreamListener和Spring Integration的 @ServiceActivator之间的区别,在使用@StreamListener的情况下,MessageConverter机制将使用contentType的头(header)信息的contentType数据类型来将消息有效实体解析为Vote对象。
和其他Spring Messaging方法一样,方法参数可以用@Payload,@Headers和@Header注解来修饰。
注意
对于需要返回数据的方法,必须使用@SendTo注解来指定需要返回数据的方法用来输出消息的通道:
@EnableBinding(Processor.class)
public class TransformProcessor {
@Autowired
VotingService votingService;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public VoteResult handle(Vote vote) {
return votingService.record(vote);
}
}
使用@StreamListener将消息分派给多个方法
从版本1.2开始,Spring Cloud Stream支持根据条件将消息分发到多个订阅了指定输入通道的被@StreamListener修饰的方法进行处理。
为了支持这种调度,需满足以下条件:
•不能有返回值
•必须是一个独立处理消息的方法(不支持响应式API方法)
这些条件通过注解的SpEL条件表达式来确定,并且会针对每条消息进行判定。 所有相同判定条件的处理程序都将会在同一个线程中调用,并且调用的顺序不被确定。
下面是一个使用@StreamListener注解进行条件调度的例子。 在这个例子中,所有报头值为foo的消息都将被分发到receiveFoo方法进行处理,所有报头带有值为bar的消息将被分配到receiveBar方法。
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class TestPojoWithAnnotatedArguments {
@StreamListener(
target = Sink.INPUT,
condition "headers['type']=='foo'")
public void receiveFoo(@Payload FooPojo fooPojo) {
}
@StreamListener(
target = Sink.INPUT,
condition = "headers['type']=='bar'")
public void receiveBar(@Payload BarPojo barPojo) {
}
}
注意
每一个@StreamListener的条件调度仅支持单个消息的处理,不支持响应式编程(如下所述)。
响应式编程支持(Reactive Programming Support)
Spring Cloud Stream还支持使用响应式API来处理连续的传入和传出数据流。 对响应式API的支持可以通过使用spring-cloud-stream-reactive依赖获得,仅需要将其明确地添加到项目依赖中。
响应式API的编程模式是声明式的,并不是指定每个单独的消息应如何被处理,而是数据流从传入到传出,通过功能转换运算来描述的。
Spring Cloud Stream 支持以下的响应式API:
• Reactor
• RxJava 1.x
将来会支持更多通用的响应式API
响应式编程模型同样可以使用@StreamListener注解来设置响应式处理程序。 不同之处在于:
•@StreamListener注解不能指定具体的输入或输出,因为输入输出通道在方法中是作为入参和返回值确定的;
•方法的参数必须被@Input和@Output标识,因为需要将传入的数据和传出的数据与对应的通道关联上;
•方法的返回值(如果有的话)需要用@Output标识,指明数据需要被发送至何处。
注意
响应式编程仅支持Jdk 1.8以上版本
注意
从Spring Cloud Stream 1.1.1及更高版本(从发行版Brooklyn.SR2开始),响应式编程的支持需要使用Reactor 3.0.4.RELEASE及更高版本的依赖。 早期版本的Reactor(包括3.0.1.RELEASE,3.0.2.RELEASE和3.0.3.RELEASE)不被支持。 spring-cloud-stream-reactive将会检索合适的版本,但项目结构的构建过程有可能会出现将io.projectreactor:reactor-core的版本自动配置为一个早期版本,特别是在使用Maven时。 比如用Spring Boot 1.x初始化Spring项目的时候,它将覆盖Reactor版本为2.0.8.RELEASE。 这时,您必须确保发布组件的版本正确。 你可以通过在项目中添加对io.projectreactor:reactor-core版本为3.0.4.RELEASE或更高版本的直接依赖来达到目的。
注意
响应式的使用目前还要根据具体的响应式API而定,并不是由响应式的执行模式而定(比如,绑定端点的时候仍然使用“push”而不是“pull”模式)。 尽管通过使用响应式的支持省了一点事儿,但我们打算从长远角度,使本地响应式客户端为所连接的中间件通道具备完整通用的支持。
基于Reactor的处理程序(Reactor-based handlers)
基于Reactor的处理程序需要具有以下参数类型:
• 对于被@Input标识的参数,它支持Reactor类型的Flux。参数化的Flus传入遵循单个消息处理规则:它可以是整个消息,POJO可以是消息有效实体,或者,POJO 是基于消息头(header)具体内容转换的结果。 同时也支持多个输入;
• 对于被@Output标注的参数,支持FluxSender类型,它将该方法生成的Flux与一个输出通道连接起来。 一般而言,只有当方法需要有多个输出时,才建议将输出作为参数;
基于Reactor的处理程序支持Flux的返回类型,它必须用@Output注解标识。 当单个输出的flux可用时,我们建议使用该方法的返回值。
这是一个简单的基于Reactor处理器的例子。
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
@Output(Processor.OUTPUT)
public Flux<String> receive(@Input(Processor.INPUT) Flux<String> input) {
return input.map(s -> s.toUpperCase());
}
}
使用了输出参数的处理器如下所示:
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
public void receive(
@Input(Processor.INPUT) Flux<String> input,
@Output(Processor.OUTPUT) FluxSender output) {
output.send(input.map(s -> s.toUpperCase()));
}
}
RxJava 1.x 支持
RxJava 1.x处理程序遵循的规则与Reactor的相同,但将使用Observable和ObservableSender作为参数和返回类型。
以上第一个例子如下:
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
@Output(Processor.OUTPUT)
public Observable<String> receive(
@Input(Processor.INPUT) Observable<String> input) {
return input.map(s -> s.toUpperCase());
}
}
以上第二个例子如下:
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
public void receive(
@Input(Processor.INPUT) Observable<String> input,
@Output(Processor.OUTPUT) ObservableSender output) {
output.send(input.map(s -> s.toUpperCase()));
}
}
响应式Source
Spring Cloud Stream对响应式的支持还提供了通过@StreamEmitter注解创建响应式Source的功能。 使用@StreamEmitter注解,一个常规的Source可以被转换为一个响应式的Source。 @StreamEmitter是一个方法级注解,使被标识的方法成为针对于被@EnableBinding标识的相关方法的输出发射器。 并且不允@Input与@StreamEmitter一起使用,因为这个注解标记的方法并不监听任何输入通道,而是关联输出通道。 它同时还遵循@StreamListener中使用的编程模式,@StreamEmitter允许灵活使用@Output注解,这取决于方法是否需要参数,返回类型等。
以下是使用StreamEmitter的一些示例。
该示例将每毫秒发出一条“Hello World”消息,并发布到Flux。 在这种情境下,Flux中产生的消息将被发送到Source的输出通道。
@EnableBinding(Source.class)
@EnableAutoConfiguration
public static class HelloWorldEmitter {
@StreamEmitter
@Output(Source.OUTPUT) public Flux<String> emit() {
return Flux.intervalMillis(1)
.map(l -> "Hello World");
}
}
以下是与上面相同功能的另一种风格。 此方法不是返回Flux,而是使用FluxSender以编程发送方式从源发送一个Flux。
@EnableBinding(Source.class)
@EnableAutoConfiguration
public static class HelloWorldEmitter {
@StreamEmitter
@Output(Source.OUTPUT)
public void emit(FluxSender output) {
output.send(Flux.intervalMillis(1)
.map(l -> "Hello World"));
}
}
以下与上面的功能和样式片段完全相同。 但是,不同之处在于使用了参数级注解。
@EnableBinding(Source.class)
@EnableAutoConfiguration
public static class HelloWorldEmitter {
@StreamEmitter
public void emit(@Output(Source.OUTPUT) FluxSender output) {
output.send(Flux.intervalMillis(1)
.map(l -> "Hello World"));
}
}
以下与上面的功能和样式片段完全相同。 这里还有另一种使用Reactive Streams Publisher API编写响应式Source的方法,这是Spring Integration Java DSL中的支持。 该案例中生产者仍然使用Reactor Flux,但是从应用程序的角度来看,只需要Reactive Streams和Spring Integeration Java DSL来进行配合,便可对用户透明。
@EnableBinding(Source.class)
@EnableAutoConfiguration
public static class HelloWorldEmitter {
@StreamEmitter
@Output(Source.OUTPUT)
@Bean
public Publisher<Message<String>> emit() {
return IntegrationFlows.from(() -> new GenericMessage<>("Hello World"),
}
}
聚合(Aggregation)
Spring Cloud Stream支持将多个应用程序聚合在一起,直接连接其输入和输出通道,避免了通过代理交换消息的额外成本。 从Spring Cloud Stream 1.0版本到目前的版本,仅支持了以下类型的应用:
•sources应用需具有一个名为output的输出通道,通常具有org.springframework.cloud.stream.messaging.Source的单一类型绑定
•sinks应用需具有一个名为input输入通道,通常具有org.springframework.cloud.stream.messaging.Sink的单一类型绑定
•processors应用需具有名为input的单个输入通道和名为output的单个输出通道,通常具有org.springframework.cloud.stream.messaging.Processor类型的单个绑定。
可以通过创建一系列互连的应用程序将它们聚合在一起,称之为sequence,这样使得上一个元素的输出连接到下一个元素的输入(如果存在)。 从一个Source或一个Processor单元开始,整个传输过程它可以包含任意数量的Processor单元,但必须以Processor或Sink单元结束。
根据开始和结束单元的性质,sequence可能有一个或多个可绑定通道,如下所示:
•如果序列以Source开始并以Sink结束,则应用程序之间的所有通信都是直接的,不会绑定任何信道
•如果序列以Processor开始,则其输入通道将成为聚合的输入通道,并将相应地绑定
•如果序列以Processor结束,则其输出通道将成为聚合的输出通道,并将相应地进行绑定
使用AggregateApplicationBuilder实用程序类执行聚合,如以下示例中所示。 让我们考虑一个项目,其中有Source,Processor和Sink,可以在项目中定义,也可以包含在项目的一个依赖项中。
注意
如果配置类使用@SpringBootApplication,则每个组件(Source,Sink或Processor)必须在一个单独的包中。由于@SpringBootApplication对同一包内的配置类执行了类路径扫描,这是为了避免应用程序之间的串扰。 在下面的例子中,可以看到Source,Processor和Sink应用程序类被分组在不同的包中。 一种可能的选择是在单独的@Configuration类中提供Source,Sink或Processor配置,避免@SpringBootApplication / @ ComponentScan注解影响其聚合。
package com.app.mysink;
@SpringBootApplication
@EnableBinding(Sink.class)
public class SinkApplication {
private static Logger logger = LoggerFactory.getLogger(SinkApplication.class);
@ServiceActivator(inputChannel=Sink.INPUT)
public void loggerSink(Object payload) {
logger.info("Received: " + payload);
}
}
package com.app.myprocessor;
@SpringBootApplication
@EnableBinding(Processor.class)
public class ProcessorApplication {
@Transformer
public String loggerSink(String payload) {
return payload.toUpperCase();
}
}
package com.app.mysource;
@SpringBootApplication
@EnableBinding(Source.class)
public class SourceApplication {
@InboundChannelAdapter(value = Source.OUTPUT)
public String timerMessageSource() {
return new SimpleDateFormat().format(new Date());
}
}
每个配置可以用于运行一个单独的组件,但在这种情况下,它们可以聚合在一起使用,如下所示:
package com.app;
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class).args("--fixedDelay=5000")
.via(ProcessorApplication.class)
.to(SinkApplication.class).args("--debug=true")
.run(args);
}
}
该sequence的起始组件作为from()方法的参数提供。 序列的结尾部分作为to()方法的参数提供。 中间Processor作为via()方法的参数提供。 相同类型的多个处理器可以链接在一起(例如用于具有不同配置的流水线转换)。 对于每个组件,构建器(builder)可以为Spring Boot提供运行时参数。
配置聚合应用程序(Configuring aggregate application)
Spring Cloud Stream支持聚合功能之间使用“namespace”的词头属性设置。
“namespace”在聚合功能中设置如下:
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class).namespace("source")
.args("--fixedDelay=5000")
.via(ProcessorApplication.class).namespace("processor1")
.run(args);
}
}
可以使用任何支持的属性配置(命令行,环境属性等)形式。一旦为各个聚合功能程序设置了“名称空间”词头设置,便可将聚合功能中支持了对应“名称空间”的应用属性配置传递过去。
例如,要覆盖“source”和“sink”应用程序的默认fixedDelay和debug属性:
java -jar target/MyAggregateApplication-0.0.1-SNAPSHOT.jar --source.fixedDelay=10000 --sink.debug=false
配置非独立聚合应用程序的绑定服务属性
非独立聚合应用程序通过聚合应用程序的传入/传出组件(通常是消息通道)中的任一个或两个绑定到外部代理服务,而聚合应用程序内的应用之间可以直接绑定。 例如:Source应用程序的输出和Processor应用程序的输入直接绑定,而Processor的输出通道绑定到代理的外部目标。 当为非独立聚合应用程序传递绑定服务属性时,需要将绑定服务属性传递给聚合应用程序,而不是将它们设置为单个子应用程序的“参数”。 例如,
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class)
.namespace("source")
.args("--fixedDelay=5000")
.via(ProcessorApplication.class)
.namespace("processor1")
.args("--debug=true")
.run(args);
}
}
像 - spring.cloud.stream.bindings.output.destination = processor-output这样的绑定属性需要被指定为外部配置属性之一(命令行参数等)。
4 绑定器(Binder)
Spring Cloud Stream提供了一个Binder抽象,用于连接外部的目标中间件。 本节介绍有关Binder SPI的主要概念,主要组件和实现细节的信息。
生产者与消费者
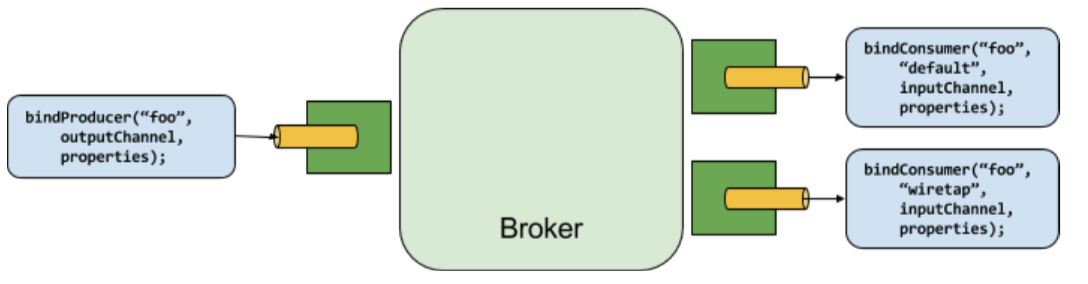
任何往通道中发布消息的组件都可称作生产者。通道可以通过代理的Binder实现与外部消息代理进行绑定。调用bindProducer()方法时,第一个参数是代理名称,第二个参数是本地通道目标名称(生产者向本地通道发送消息),第三个参数包含通道创建的适配器的属性信息(比如:分片key表达式)。
任何从通道中接收消息的组件都可称作消费者。与生产者一样,消费者通道可以与外部消息代理进行绑定。调用bindConsumer()方法时,第一个参数是目标名称,第二个参数提供了消费者组的名称。每个组都会收到生产中发出消息的副本(即,发布-订阅),如果有多个消费者属于同一个组,消息只会由一个消费者消费(即,队列)
4.2 Binder SPI
Binder SPI包含许多接口,开箱即用的实用程序类以及为连接到外部中间件提供的机制发现策略。
SPI的关键是Binder接口,它是一种将输入和输出连接到外部中间件的策略。
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
}
这些接口支持参数化,提供了许多扩展点:
•输入和输出的目标绑定 - 不过从版本1.0开始,仅支持了MessageChannel,这也将作为将来的扩展点;
•扩展的消费者和生产者属性 - 允许特定的Binder以安全支持的方式实现添加补充属性。
一个典型的Binder实现包括以下内容
•一个实现了Binder接口的类;
•一个Spring @Configuration注解,用于配置上述接口的bean实例以及中间件连接所需的基础结构;
•在包含一个或多个Binder定义的类路径上可以被找到的META-INF / spring.binders文件,例如
kafka:\
org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
4.3 Binder 检测
Spring Cloud Stream依赖于Binder SPI的实现来执行将通道连接到消息代理的任务。 每个Binder通常就是一个能连接到一种特定消息系统的具体实现。
路劲检测
默认情况下,Spring Cloud Stream依靠Spring Boot的自动配置来配置绑定过程。 如果在类路径中找到一个Binder实现,Spring Cloud Stream将自动使用它。 例如,需要绑定到RabbitMQ的Spring Cloud Stream项目可以简单地添加以下依赖项:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
有关其他Binder依赖项的特定maven配置,请参阅Binder的文档。
4.4 路径上的多个Binder
如果路径中存在多个Binder,则应用程序必须指定每个通道绑定使用的Binder。 每个Binder配置都要求有一个META-INF / spring.binders,它是一个简单的属性文件:
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration
对于其他提供的Binder实现(例如Kafka),也存在类似的文件,并且期望自定义的Binder实现也提供这种配置文件。 键(key)表示Binder实现的标识名称,而值(value)是逗号分隔的多个配置值,每个配置类有且仅有一个类型为org.springframework.cloud.stream.binder.Binder的bean定义。
Binder可以选择全局生效,通过使用
spring.cloud.stream.defaultBinder属性(spring.cloud.stream.defaultBinder = rabbit),或者单独在每个通道绑定上配置Binder。 例如,Processor应用程序(具有分别用于读取/写入的输入和输出的通道的接口)从Kafka读取并写入RabbitMQ的处理器应用可以指定以下配置:
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbit
4.5 连接到多个系统
默认情况下,各Binder可以共享Spring Boot的自动配置,以便创建在类路径中的每个Binder实例方便被发现。 如果您的应用连接到同一类型的多个代理服务,则可以指定多个Binder配置来使各个Binder具有不同的环境设置。
注意
显式的Binder配置将完全禁用默认的Binder配置。 如果您这样做,则所有正在使用的Binder必须包含在配置中。 框架本身致力于使用Spring Cloud Stream可以透明地创建按名称引用的绑定器配置,而不影响默认绑定器配置。 为了达到这种目的,Binder配置可以将其defaultCandidate标志设置为false,例如,spring.cloud.stream.binders.defaultCandidate=false。 这表示自定义的Binder配置将独立于默认的配置而存在。
例如,这是连接到两个RabbitMQ代理服务的Processor应用的典型配置:
spring:
cloud:
stream:
bindings:
input:
destination: foo
binder: rabbit1
output:
destination: bar
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host: <host1>
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host: <host2>
4.6 Binder的配置属性
在配置自定义Binder时,以下属性是可用的。 它们必须以spring.cloud.stream.binders.为前缀。
type:
Binder type。 它通常引用类路径中找到的一个Binder,特别是META-INF / spring.binders文件中的一个对应的键值。默认情况系下,其值和配置名称相同
inheritEnvironment:
配置是否会继承应用程序本身的环境。默认为true
environment:
可用于自定义Binder环境的一组根属性。 当配置以后,正在创建Binder的上下文就不再是整个应用程序上下文的子属性了。 这允许完全分离Binder部件和整个应用。默认为empty
defaultCandidate:
无论Binder是否需要被配置为默认Binder,或仅在明确需要时声明并引用。 该属性允许你所添加的Binder配置不干扰默认的配置。默认为true
5 配置项(Configuration Options)
Spring Cloud Stream支持常规配置选项以及与Binder的配置。 一些Binder支持额外的绑定属性来支持中间件特定的功能。
配置选项可以通过Spring Boot支持的任何机制提供给Spring Cloud Stream应用程序。 这包括应用程序参数,环境变量和YAML或.properties文件。
5.1 Spring Cloud Stream 属性&&5.2 Binding 属性
请自行查阅文档
5.3 动态绑定目标的使用
除了通过@EnableBinding定义的通道外,Spring Cloud Stream还允许应用程序将消息发送到动态绑定的目标。 例如,当运行时需要动态指定目标时,这就有用武之地了。 可以通过使用由@EnableBinding注释自动注册的BinderAwareChannelResolver bean来实现。
属性“spring.cloud.stream.dynamicDestinations”可用于将事先需要确定的目标名称集合设定为白名单。 如果没有设置该属性,则任何目的地都可以被动态绑定。
BinderAwareChannelResolver可以直接使用,如下例所示,其中REST控制器使用路径变量来决定路由。
@EnableBinding
@Controller
public class SourceWithDynamicDestination {
@Autowired
private BinderAwareChannelResolver resolver;
@RequestMapping(path = "/{target}", method = POST, consumes = "*/*")
@ResponseStatus(HttpStatus.ACCEPTED)
public void handleRequest(@RequestBody String body, @PathVariable("target") target,
@RequestHeader(HttpHeaders.CONTENT_TYPE) Object contentType) {
sendMessage(body, target, contentType);
}
private void sendMessage(String body, String target, Object contentType) {
resolver.resolveDestination(target)
.send(MessageBuilder.createMessage(
body,
new MessageHeaders(
Collections.singletonMap(
MessageHeaders.CONTENT_TYPE, contentType)
)
)
);
}
}
发送以下命令并在默认端口8080监听:
curl -H "Content-Type: application/json" -X POST -d "customer-1" http:
curl -H "Content-Type: application/json" -X POST -d "order-1" http:
“customers”和”order”在代理服务中被创建后(例如:RabbitMQ的exchange或kafka的topic),数据将被发布到名称为“customers”或“order”的目的地。
BinderAwareChannelResolver是一个通用的Spring Integration DestinationResolver,可以注入到其他组件中。 例如,在使用基于传入JSON消息的目标字段的SpEL表达式的路由器中。
@EnableBinding
@Controller
public class SourceWithDynamicDestination {
@Autowired
private BinderAwareChannelResolver resolver;
@RequestMapping(path = "/", method = POST, consumes = "application/json")
@ResponseStatus(HttpStatus.ACCEPTED)
public void handleRequest(@RequestBody String body, @RequestHeader(HttpHeaders.CONTENT_TYPE) Object contentType) {
sendMessage(body, contentType);
}
private void sendMessage(Object body, Object contentType) {
routerChannel()
.send(MessageBuilder.createMessage(
body,
new MessageHeaders(
Collections.singletonMap(
MessageHeaders.CONTENT_TYPE, contentType)
)
);
}
@Bean(name = "routerChannel")
public MessageChannel routerChannel() {
return new DirectChannel();
}
@Bean
@ServiceActivator(inputChannel = "routerChannel")
public ExpressionEvaluatingRouter router() {
ExpressionEvaluatingRouter router = new ExpressionEvaluatingRouter(
new SpelExpressionParser()
.parseExpression("payload.target")
);
router.setDefaultOutputChannelName("default-output");
router.setChannelResolver(resolver);
return router;
}
}
6 内容类型和转换
为了让你可以传递消息的内容类型信息,Spring Cloud Stream默认将contentType header附加到传出的消息中。 对于不直接支持头文件的中间件,Spring Cloud Stream提供了自己的传出消息自动封装机制。 对于支持标题的中间件,Spring Cloud Stream应用程序可以从非Spring Cloud Stream应用程序接收到具有给定内容类型的消息实体。
Spring Cloud Stream可以通过两种方式来支持这种带有contentType header的消息:
•通过传入和传出通道的contentType设置
•通过使用@StreamListener注解的方式进行参数映射
Spring Cloud Stream允许使用spring.cloud.stream.bindings..content-type属性来配置输入和输出的类型转换策略。 请注意,通用类型转换也可以通过在应用程序中使用transformer来轻松完成。 目前,Spring Cloud Stream本身支持在流中常用的以下类型转换:
• JSON to/from POJO
• JSON to/from org.springframework.tuple.Tuple
• Object to/from byte[] : 可以是应用程序方便远程传输的原始序列化字节,也可以是使用Java序列化转换的字节(要求对象为Serializable)
• String to/from byte[]
• Object to plain text
JSON表示包含JSON的字节数组或字符串有效实体。 目前,对象可以由JSON字节数组或字符串转换而来。 不过转换成JSON总是由一个字符串为基础来转化的。
如果在传出通道上没有设置content-type属性,则Spring Cloud Stream将使用基于Kryo框架的序列化程序对有效实体进行序列化。 消费者在反序列化消息的时候,需要有效的目标实体类与消费者的类属于同一个上下午路径。
6.1 MIME 类型
content-type值会被当做media类型进行解析,例如application / json或text / plain; charset = UTF-8。 MIME类型对于指示如何将有效实体转换为String或byte []内容特别有用。 Spring Cloud Stream还使用MIME类型的格式application / x-java-object来表示Java类型。 例如,可以将application / x-java-object; type = java.util.Map或application / x-java- object; type = com.bar.Foo设置为输入绑定的内容类型。 另外,Spring Cloud Stream提供了关联一个Tuple对象的自定义MIME类型格式application / x-spring-tuple。
6.2 MIME 类型 and Java 类型
下表总结了Spring Cloud Stream开箱即用的类型转换:“Source Payload”表示转换前的有效实体,“Target Payload”表示转换后的有效实体。 类型转换既可以在“生产者”一侧(输出)也可以在“消费者”一侧(输入)进行。
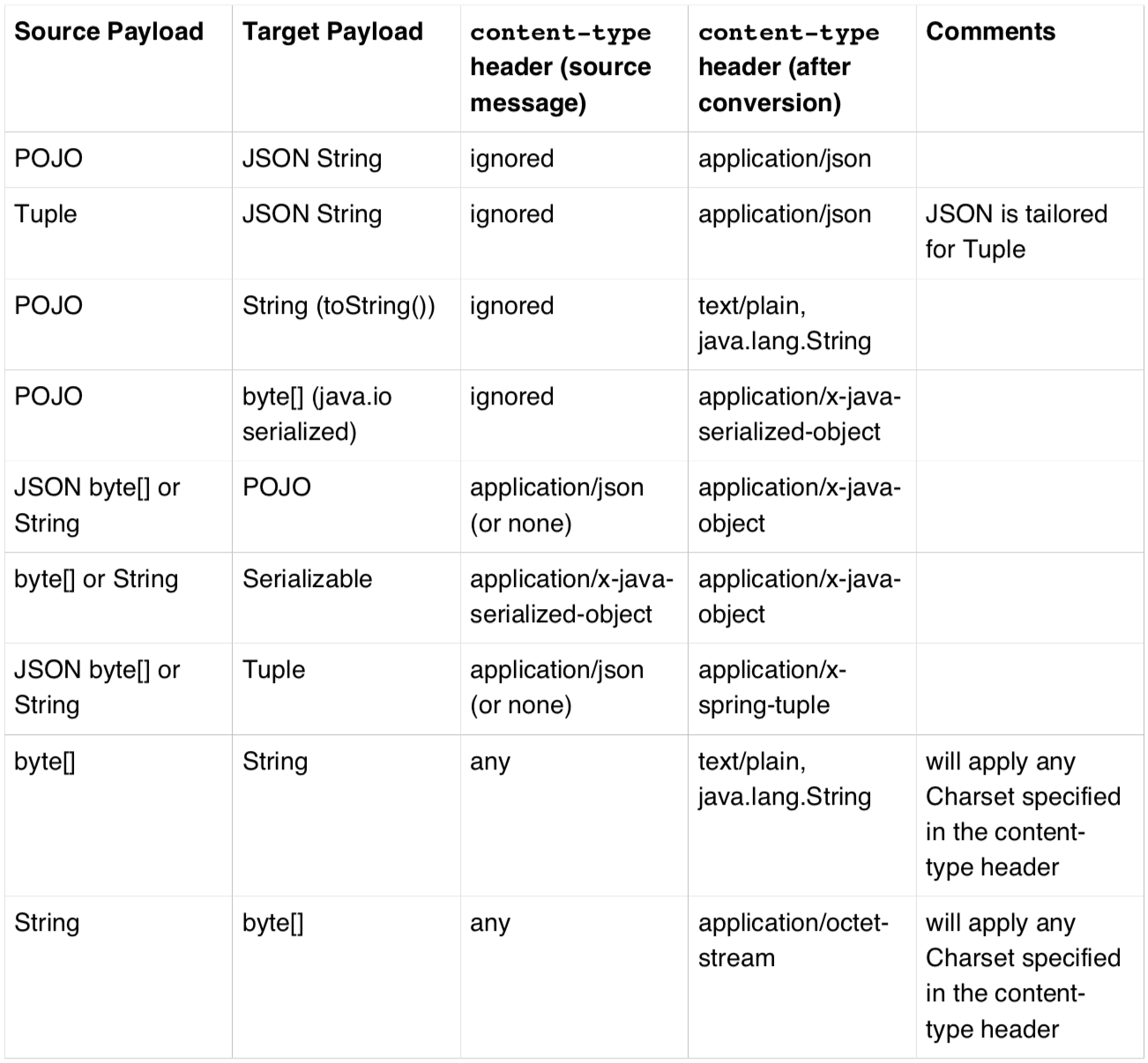
注意
转换适用于需要进行类型转换的有效实体。 例如,如果应用程序生成一个XML类型的消息,但并没有指定outputType = application / json,那么消息实体将不会从XML转换为JSON。 这是因为发送到传出通道的有效实体已经是一个字符串,所以传输过程并不会进行转换。 同样重要的是,当使用默认的序列化机制时,有效实体必须在发送和接收应用程序之间通用,也就是说二进制内容双方都得兼容。 当消息实体在两个应用程序中的某一方单独更改时,便会产生问题,因为这个二进制格式的数据和提供用于对接的代码会变得不兼容。
注意
虽然转换支持在传入和传出方进行,但还是推荐在传出消息的时候进行转换。 对于传入消息的转换,尤其是当目标是POJO时,@StreamListener将自动进行转换。
6.3 自定义消息转换
除了原本已支持的转换,Spring Cloud Stream还支持定制自己的消息类型转换实现。 这允许您以各种自定义格式(包括二进制)发送和接收数据,并将它们与特定的contentType关联。 Spring Cloud Stream将org.springframework.messaging.converter.MessageConverter类型的所有bean注册为作开箱即用的自定义消息转换器。
如果您的消息转换器需要使用特定的content-type和目标类(对于输入和输出),那么消息转换器就需要扩展org.springframework.messaging.converter.AbstractMessageConverter。 对于使用@StreamListener进行的转换,转换器实现org.springframework.messaging.converter.MessageConverter就足够了。
下面是在Spring Cloud Stream应用程序中创建消息转换器bean(带有内容类型的应用程序/栏)的示例:
@EnableBinding(Sink.class)]
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class<?> clazz) {
return (Bar.class == clazz);
}
@Override
protected Object convertFromInternal(Message<?> message, Class<?> targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}
Spring Cloud Stream还支持基于Avro的转换器和模式演变。 详情请参阅具体章节。
6.4 @StreamListener and 消息转换
@StreamListener注解为传入消息的转换提供了一种便捷方式,无需指定输入通道的内容类型。 在使用@StreamListener注解的方法调度过程中,如果参数类型指定,将自动进行转换。
例如,让我们考虑一个String类型的content {“greeting”:“Hello,world”}消息,并且在输入通道上已经指明接收application / json类型头的内容。 接收它的应用程序应该如下所示:
public class GreetingMessage {
String greeting;
public String getGreeting() {
return greeting;
}
public void setGreeting(String greeting) {
this.greeting = greeting;
}
}
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class GreetingSink {
@StreamListener(Sink.INPUT)
public void receive(Greeting greeting) {
}
}
该方法的参数将使得JSON字符串以非编组形式填充一个指定的POJO。
7. 模式进化支持(Schema evolution support)
Spring Cloud Stream通过其spring-cloud-stream-schema模块为基于模式的消息转换器提供支持。 目前,基于模式消息转换器开箱即用的唯一序列化格式是Apache Avro,未来版本中将添加更多格式。
7.1 Apache Avro 消息转换器
spring-cloud-stream-schema模块包含两种可以用于Apache Avro序列化的消息转换器:
•序列化/反序列化对象信息,或启动时已被指定模式的转化器;
•在运行时指定了模式注册表,且可以随着域对象的变化动态注册的转化器。
7.2具有模式支持的转换器
AvroSchemaMessageConverter支持使用预定义模式或使用类中已经有的模式信息对消息进行序列化和反序列化。 如果转换的目标类型是GenericRecord,则必须设置模式的支持。
为了简单地使用它,你可以将它添加到应用程序上下文中,可以选择指定一个或多个MimeTypes来关联它。 默认的MimeType是application / avro。
下面是注册一个没有预定义模式的Apache Avro MessageConverter到Sink应用程序中并对其进行配置的示例:
@EnableBinding(Sink.class)
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter userMessageConverter() {
return new AvroSchemaMessageConverter(
MimeType.valueOf("avro/bytes")
);
}
}
相反地,这是一个可以在类路径中找到并且注册了预定义模式的转换器例子:
@EnableBinding(Sink.class)
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter userMessageConverter() {
AvroSchemaMessageConverter converter = new AvroSchemaMessageConverter(
MimeType.valueOf("avro/bytes")
);
converter.setSchemaLocation(
new ClassPathResource("schemas/User.avro")
);
return converter;
}
}
为了理解客户端模式注册表转换器,我们将首先描述模式注册表的支持。
7.3模式注册表的支持(Schema Registry Support)
大多数序列化模型,尤其是跨不同平台和语言的可移植性,将依赖于一种模式来描述数据如何对二进制的有效实体进行序列化。 为了序列化数据然后解释它,发送方和接收方都必须能够支持所描述的这种二进制模式。 在某些情况下,模式可以从序列化中的有效实体类型或反序列化的目标类型推导出来,但是在多数情况下,应用程序直接读取描述了这种二进制数据格式模式信息,这样会更有好处。 模式注册表允许你以文本格式(通常为JSON)存储模式信息,并使这些信息可以被各种需要以二进制格式接收和发送数据的应用程序访问。 这种模式可以被引用为一个以下的元组定制,包括:
• 作为模式逻辑名称的主题;
• 模式版本;
• 描述数据二进制格式的模式格式。
7.4 架构注册表服务端
Spring Cloud Stream提供了架构注册表服务端的实现。 为了方便使用,可以将spring-cloud-stream-schema-server组件添加到你的项目依赖中。使用@EnableSchemaRegistryServer注解,便可将架构注册表服务端的REST控制器添加到应用程序中。 此注解用于Spring Boot Web应用程序中,并且服务器的侦听端口由server.port属性设置。 spring.cloud.stream.schema.server.path可以用来控制模式服务的根路径(特别是当它嵌入到其他应用程序中时)。 spring.cloud.stream.schema.server.allowSchemaDeletion的设置允许禁用”模式”。 默认情况下这是dosabled。
模式注册表服务端使用关系数据库来存储模式。 默认情况下,它使用嵌入式数据库。 您可以使用Spring Boot SQL数据库和JDBC配置选项自定义模式存储。
启用架构注册表的Spring Boot应用程序如下所示:
@SpringBootApplication
@EnableSchemaRegistryServer
public class SchemaRegistryServerApplication {
public static void main(String[] args) {
SpringApplication.run(
SchemaRegistryServerApplication.class, args);
}
}
架构注册表服务API
架构注册表服务端的API包含以下操作:
POST /
注册一个新的模式(schema)
接受具有以下字段的JSON实体:
•subject 模式主题;
•format 模式格式;
•definition 模式定义。
Response是JSON格式的模式对象,具有以下字段:
•id 模式ID;
•subject 模式主题;
•format 模式格式;
•version 模式版本;
•definition 模式定义。
GET /{subject}/{format}/{version}
通过主题,格式和版本检索现有模式。
Response是JSON格式的模式对象,具有以下字段:
•id 模式ID;
•subject 主题;
•format 模式格式;
•version 模式版本;
•definition 模式定义。
GET /{subject}/{format}
通过主题和格式检索现有模式的列表。
响应是每个对象JSON格式的模式列表,其中包含以下字段:
•id 模式ID;
•subject 主题;
•format 模式格式;
•version 模式版本;
•definition 模式定义。
GET /schemas/{id}
通过其ID检索现有的模式。
Response是JSON格式的模式对象,具有以下字段:
•id 模式ID;
•subject 主题;
•format 模式格式;
•version 模式版本;
•definition 模式定义。
DELETE /{subject}/{format}/{version}
依据subject,format和version删除现有模式。
DELETE /schemas/{id}
依据id删除现有模式。
DELETE /{subject}
依据subject删除现有模式。
注意
该提示仅适用于Spring Cloud Stream 1.1.0.RELEASE的用户。 Spring Cloud Stream 1.1.0.RELEASE使用”schema”作为数据库的表名来存储Schema对象,然而”schema”在许多数据库实现中却是一个关键字。 为避免将来出现任何冲突,从1.1.1.RELEASE开始,我们选择SCHEMA_REPOSITORY作为存储表的名称。 建议升级的任何需要将Spring Cloud Stream 1.1.0.RELEASE升级的用户,事前先将原本的表迁移到新表中。
7.5 架构注册表客户端
与架构注册表服务端交互的客户端抽象接口是SchemaRegistryClient,具有以下结构:
public interface SchemaRegistryClient {
SchemaRegistrationResponse register(String subject, String format, String schema);
String fetch(SchemaReference schemaReference);
String fetch(Integer id);
}
Spring Cloud Stream提供开箱即用的实现,用于与自己的模式服务端进行交互,以及与Confluent模式注册表进行交互。
Spring Cloud Stream模式注册中心的客户端可以使用@EnableSchemaRegistryClient进行配置,如下所示:
@EnableBinding(Sink.class)
@SpringBootApplication
@EnableSchemaRegistryClient
public static class AvroSinkApplication {
...
}
注意
默认的转换器被优化为不仅能缓存来自远程服务器的模式信息,并且缓存parse()和toString()这些代价很大的方法。 因此,它使用的是不缓存响应的DefaultSchemaRegistryClient。 如果你打算直接在您的代码上使用客户端,则可以请求一个在创建时就被缓存了的bean。 为此,只需将属性spring.cloud.stream.schemaRegistryClient.cached = true添加到您的应用程序属性中即可。
使用Confluent的模式注册表
默认的配置将创建一个DefaultSchemaRegistryClient bean。 如果要使用Confluent模式注册表,则需要创建一个类型为ConfluentSchemaRegistryClient的bean,该bean将取代框架默认配置的bean。
@Bean
public SchemaRegistryClient schemaRegistryClient(@Value("${spring.cloud.stream.schemaRegistryClient.endpoint}") String endpoint){
ConfluentSchemaRegistryClient client = new ConfluentSchemaRegistryClient();
client.setEndpoint(endpoint);
return client;
}
注意
ConfluentSchemaRegistryClient是针对Confluent平台版本3.2.2进行测试的。
架构注册表客户端属性
Schema Registry Client支持以下属性:
spring.cloud.stream.schemaRegistryClient.endpoint
架构服务器的位置。 设置时需要使用完整的URL,包括协议(http或https),端口和上下文路径。
默认:
https:
spring.cloud.stream.schemaRegistryClient.cached
客户端是否应缓存架构服务器响应。 通常设置为false,因为缓存发生在消息转换器中。 使用模式注册表客户端应将其设置为true。
默认:
false
7.6Avro Schema注册表客户端消息转换器
对于在应用程序上下文中注册了SchemaRegistryClient bean的Spring Boot应用程序,Spring Cloud Stream将自动配置使用模式注册表客户端进行模式管理的Apache Avro消息转换器。这简化了模式演进,因为接收消息的应用程序可以轻松访问能与自己的读取器模式进行协调的写入器模式。
对于传出的消息,如果频道的内容类型为application/*+avro,MessageConverter将被激活,例如:
spring.cloud.stream.bindings.output.contentType=application
在传出转换期间,消息转换器将尝试基于其类型推断传出消息的具体模式,并使用SchemaRegistryClient根据有效实体的类型将其注册一个主题。如果已经找到相同的模式,那么将会检索对该模式的引用。如果没有,则将注册这个模式并提供新的版本号。该消息将以contentType头为application/[prefix].[subject].v[version]+avro的模式发送,其中prefix是可配置的,并且可以从有效实体推导出subject。
例如,类型为User的消息通过contentType为application/vnd.user.v2+avro的二进制形式发送,其中user是主题,版本号是2。
当接收到消息时,转换器将从传入消息的头部推断出模式引用,并尝试检索该模式的引用它。该模式将在反序列化过程中被接收方的写入器使用。
Avro Schema注册表消息转换器属性
如果您已通过设置spring.cloud.stream.bindings.output.contentType=application/*+avro启用基于Avro的模式注册表客户端,则可以使用以下属性自定义注册的行为。
spring.cloud.stream.schema.avro.dynamicSchemaGenerationEnabled
如果您希望转换器使用反射从POJO推导出Schema,则启用。
默认:
false
spring.cloud.stream.schema.avro.readerSchema
Avro通过查看编写器的模式(源有效载荷)和读取器的模式(应用程序有效负载)来比较模式版本,查看Avro文档以获取更多信息。如果设置,这将覆盖任何盯着该模式服务器的行为,并将被用作本地读取器模式。
默认
null
spring.cloud.stream.schema.avro.schemaLocations
使用Schema服务器注册此属性中列出的任何.avsc文件。
默认:
empty
spring.cloud.stream.schema.avro.prefix
需要在Content-Type头上使用的前缀。
默认:
vnd
7.7Schema注册和解决
为了更好地了解Spring Cloud Stream注册和解析未知模式,同时也是为了与使用Avro模式进行功能上的比较,我们将提供一下两个单独的部分:一个用于注册模式,一个用于解析模式。
Schema注册流程(序列化)
注册过程的第一步是通过从信道发送的消息有效实体中提取模式。像SpecificRecord或GenericRecord这样Avro的类对象本身已经包含一个模式实例,可以从实例中直接引用。但如果是POJO,需要将spring.cloud.stream.schema.avro.dynamicSchemaGenerationEnabled设置为true(默认),才能推断出模式。

一旦模式被推导出来,转换器就会从远程服务端加载其元数据(比如version)。首先,它会查询本地缓存,如果没有找到它,则将数据提交到需要依赖版本控制信息作为回复的服务端。转换器将始终缓存一份结果,以避免每个需要序列化的新消息都要查询Schema服务端所带来的开销。

使用模式版本信息,转换器设置消息的contentType头,以携带版本信息,如application/vnd.user.v1+avro
Schema解析过程(反序列化)
一旦读取到包含版本信息的消息(即,具有上述方案的contentType标头),转换器将查询Schema服务端以获取消息写入器所需要的模式。一旦找到写入传入消息的正确模式,它就会引用一个具有该模式的读取器实例,并使用Avro提供的模式支持,解析该消息并写入到最终的目的地。

注意
了解写入器模式(写入消息的应用程序)和读取器模式(接收应用程序)之间的区别很重要。请花点时间阅读the Avro terminology,并了解此过程。Spring Cloud Stream将始终获取写入器的模式信息以确定如何正确读取消息。如果您想要获得Avro的架构演进工作的支持,那么你需要确保为你的应用程序正确配置了readerSchema。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)