广度优先和深度优先搜索算法
本章主要讲述广度优先搜索算法BFS(Breadth First Search)和深度优先算法DFS(Depth First Search)。
- 广度优先:从起点开始由近及远进行广泛搜索,一般使用队列实现
- 深度优先:从起点开始沿着一条路径一直往下,直到不能搜索为止,再折返沿着另一条路径往下搜索,使用栈或者递归实现
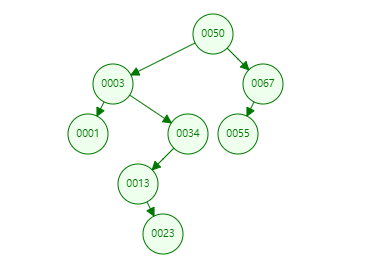
下面将以上图中的树来举例实现搜索,每个节点的数据结构如下
public static class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
广度优先搜索
- 从根节点开始遍历,将根节点加入队列,队列为
[50]
- 将队首
节点50的所有子节点按照从左到右的顺序加入队列,队列为[50,3,67]
- 将节点
50移出队列,队列为[3,67]
- 重复步骤2、3直到所有节点遍历完毕,即可完成广度优先搜索
遍历结果:50, 3, 67, 1, 34, 55, 13, 23
java代码实现如下
/**
* 广度优先搜索
* @param root
* @return
*/
public int[] bfs(TreeNode root) {
if (root == null) {
return new int[0];
}
List<Integer> result = new LinkedList<>();
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root); /* 将根节点放入队列 */
while (!queue.isEmpty()) {
TreeNode node = queue.poll(); /* 取出队首节点node */
result.add(node.val);
if (node.left != null) {
queue.add(node.left); /* 将node的左节点加入队列 */
}
if (node.right != null) {
queue.add(node.right); /* 将node的右节点加入队列 */
}
}
return result.stream().mapToInt(Integer::intValue).toArray();
}
深度优先搜索
根据节点的遍历顺序,深度优先搜索分为先序遍历、中序遍历和后序遍历。
- 先序遍历:先输出当前节点,再遍历左节点,最后遍历右节点。遍历左、右节点时,依然按照先序遍历的规则遍历。
- 中序遍历:先遍历左节点,再输出当前节点,最后遍历右节点。遍历左、右节点时,依然按照中序遍历的规则遍历。
- 后序遍历:先遍历左节点,再遍历右节点,最后输出当前节点。遍历左、右节点时,依然按照后续遍历的规则遍历。
先序遍历
输出结果:50, 3, 1, 34, 13, 23, 67, 55
/**
* 深度优先搜索-先序遍历,递归实现
*
* @param root
* @return
*/
public int[] dfsPreorder(TreeNode root) {
List<Integer> result = new LinkedList<>();
dfsPreorder(root, result);
return result.stream().mapToInt(Integer::intValue).toArray();
}
public void dfsPreorder(TreeNode node, List<Integer> result) {
if (node == null) {
return;
}
result.add(node.val); // 输出当前节点
dfsPreorder(node.left, result); // 遍历左节点
dfsPreorder(node.right, result); // 遍历右节点
}
先序遍历栈实现思路:
- 先序遍历顺序为:输出当前节点 → 遍历左节点 → 遍历右节点
- 可以从根节点开始,优先遍历左子树,最后再遍历右子树,将所有节点按照遍历顺序输出即可得到先序遍历结果
/**
* 深度优先搜索-先序遍历,栈实现
*
* @param root
* @return
*/
public int[] dfsPreorder(TreeNode root) {
List<Integer> result = new LinkedList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode node = root;
while (node != null || !stack.isEmpty()) {
if (node != null) {
stack.push(node);
result.add(node.val); // 输出当前节点
node = node.left; // 向左遍历
} else {
node = stack.pop();
node = node.right; // 向右遍历
}
}
return result.stream().mapToInt(Integer::intValue).toArray();
}
中序遍历
输出结果:1, 3, 13, 23, 34, 50, 55, 67
/**
* 深度优先搜索-中序遍历,递归实现
*
* @param root
* @return
*/
public int[] dfsMidOrder(TreeNode root) {
List<Integer> result = new LinkedList<>();
dfsMidOrder(root, result);
return result.stream().mapToInt(Integer::intValue).toArray();
}
public void dfsMidOrder(TreeNode node, List<Integer> result) {
if (node == null) {
return;
}
dfsMidOrder(node.left, result); // 遍历左节点
result.add(node.val); // 输出当前节点
dfsMidOrder(node.right, result); // 遍历右节点
}
中序遍历栈实现思路:
- 中序遍历顺序为: 遍历左节点 → 输出当前节点 → 遍历右节点
- 从根节点开始,优先遍历左子树,最后再遍历右子树,将所有节点按照出栈输出即可得到先序遍历结果
注意:中序遍历要求左节点优先输出,所以节点入栈时不要输出,待节点出栈再输出
/**
* 深度优先搜索-中序遍历,栈实现
*
* @param root
* @return
*/
public int[] dfsMidOrder(TreeNode root) {
List<Integer> result = new LinkedList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode node = root;
while (node != null || !stack.isEmpty()) {
if (node != null) {
stack.push(node); // 当前节点入栈
node = node.left; // 向左遍历
} else {
node = stack.pop(); // 栈顶元素没有左节点,此时向右遍历
result.add(node.val);
node = node.right; // 向右遍历
}
}
return result.stream().mapToInt(Integer::intValue).toArray();
}
后序遍历
输出结果:1, 23, 13, 34, 3, 55, 67, 50
/**
* 深度优先搜索-后序遍历,递归实现
*
* @param root
* @return
*/
public int[] dfsPostorder(TreeNode root) {
List<Integer> result = new LinkedList<>();
dfsPostorder(root, result);
return result.stream().mapToInt(Integer::intValue).toArray();
}
public void dfsPostorder(TreeNode node, List<Integer> result) {
if (node == null) {
return;
}
dfsPostorder(node.left, result); // 遍历左节点
dfsPostorder(node.right, result); // 遍历右节点
result.add(node.val); // 输出当前节点
}
后序遍历栈实现思路:
- 后序遍历顺序为:遍历左节点 → 遍历右节点 → 输出当前节点
- 按照栈先进后出的特点,入栈顺序应为:当前节点 → 右节点 → 左节点
- 可以从根节点开始,优先遍历右子树,最后再遍历左子树,将所有节点按照遍历顺序保存到栈中,最后按顺序出栈即可得到后序遍历结果
/**
* 深度优先搜索-后续遍历,栈实现
*
* @param root
* @return
*/
public int[] dfsPostorder(TreeNode root) {
List<Integer> result = new LinkedList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode node = root;
while (node != null || !stack.isEmpty()) {
if (node != null) {
stack.push(node); // 入栈顺序是后序遍历的倒叙排列
result.add(0, node.val); // 将倒叙变为正序
node = node.right; // 向右遍历
} else {
node = stack.pop().left; // 向左遍历
}
}
return result.stream().mapToInt(Integer::intValue).toArray();
}