ThreadPoolExecutor是线程的池化技术,也就是首先创建几个线程,然后把线程放到池子里,有任务来的时候直接从线程池中拉线程来执行任务。为什么要用池化技术?java中的线程是系统级别的资源,创建、销毁线程都很消耗CPU的资源,有了池化技术,就可以复用线程,而不是频繁的创建、销毁。
在平常的项目开发过程中,我们可以通过Executors提供的方法创建,如newSingleThreadExecutor、newFixedThreadPool等方法,但是这些方法实际上是帮我们构建ThreadPoolExecutor对象,所以像阿里的大佬们都是不建议使用Executors来创建,而是建议自己去ThreadPoolExecutor对象,下面就来详细聊聊ThreadPoolExecutor的底层原理。
先来对构造方法的参数进行说明:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize表示核心线程数;
- maximumPoolSize表示最大线程数,注意这里包括核心线程数和临时线程数;
- keepAliveTime表示临时线程的存活时间(代码:workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)从队列中获取时设置超时时间,如果超时获取不到,则后续返回null,表示退出某个worker);
- workQueue表示工作队列;
- handler表示拒绝后的处理逻辑;
再说说整体的操作流程,如下图所示:
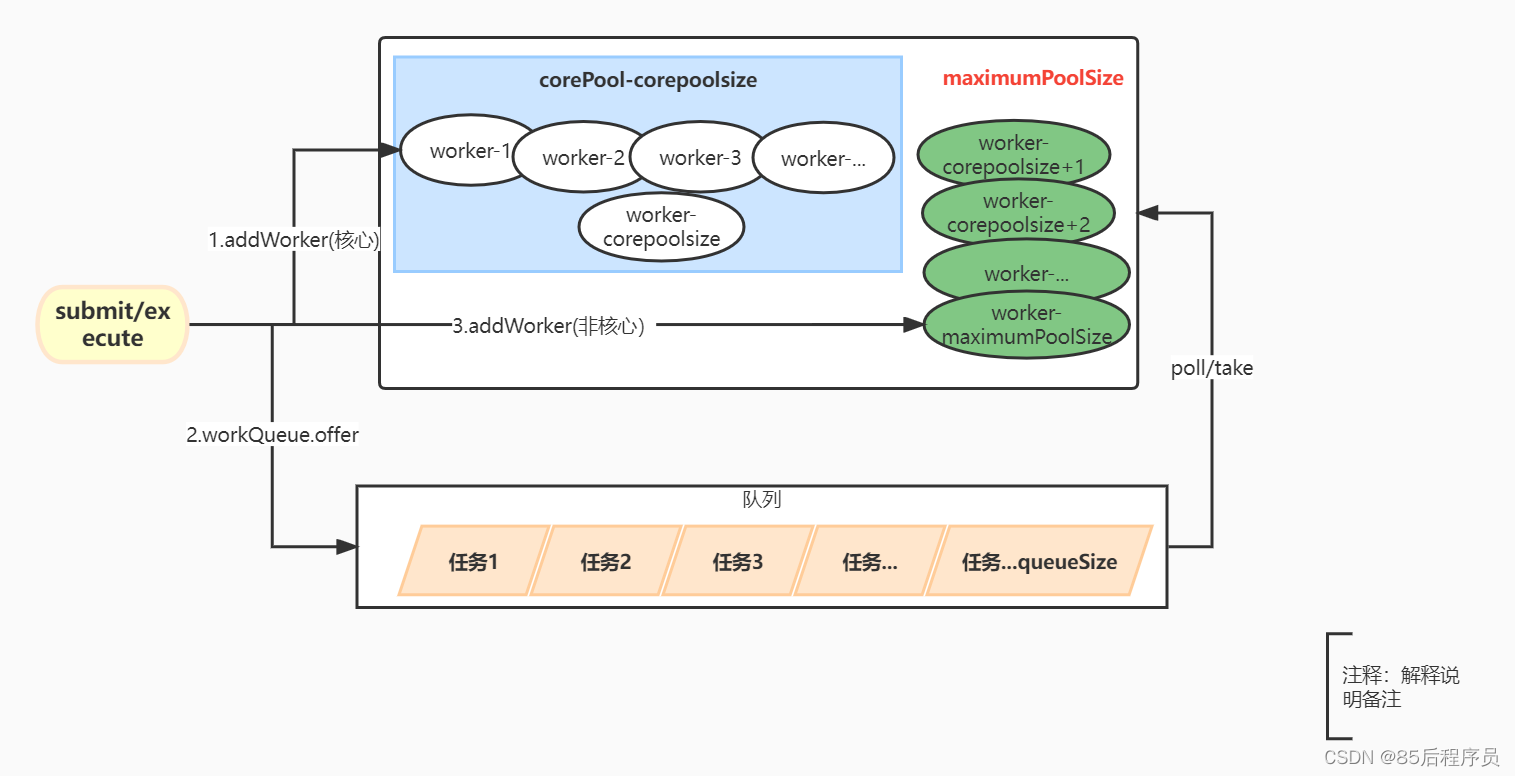
讲讲什么是Worker?
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
Worker是Runnable的实现类,咱们就把它理解为线程,举个属于程序员的例子来说明,Worker就像当于程序员,比如在华为干活的就有很多程序员,一个程序员每次只能接一个任务。但是同样是在华为干活的程序员,为啥差距就那么大呢?那是因为有些程序员是华为的正规军,有些是外包的杂牌军,正规军就相当于corePool里面的核心线程,反正没有活干了或者出现危机不会被裁掉,而杂牌军则不同,没有活干了你们就回归母公司的怀抱。对比上述图形,如果有任务了,先正规军干,如果活太多干不完了,先放队列里面,队列放不下了就找杂牌军干,如果还是太多了,那对不起老子不接了;如果队列里面的任务干完了,先把杂牌军释放,留下正规军继续等活。
牛逼吹了这么多,下面一起来看看代码长啥样:
1.首先通过调用ThreadPoolExecutor的submit或execute方法,将任务添加到ThreadPoolExecutor中去执行,那么这里submit和execute方法有什么区别呢?
这里总结节点:
其一、submit底层就是调用了execute方法,只不过在调用execute方法之前,先将任务封装成了RunnableFuture类型,这里创建的是FutureTask类型的对象:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
至于在这里为什么要这么做,因为这里使用的FutureTask可以获取到任务的执行结果,具体如何使用的,感兴趣的朋友不妨百度下,或者在评论区留言交流。
其二、我们先来看下ThreadPoolExecutor的继承结构,如下:
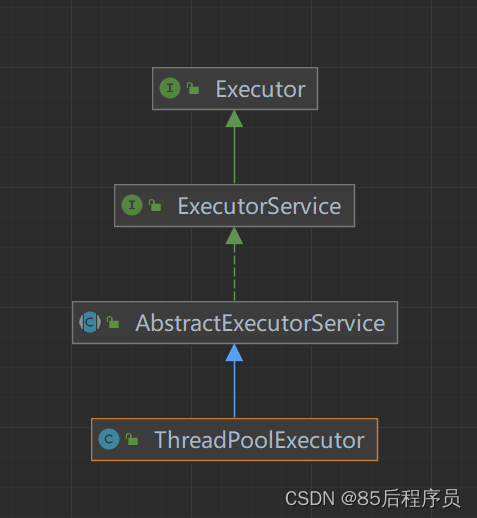
其实submit方法是AbstractExecutorService这个抽象类提供的方法,execute方法才是ThreadPoolExecutor提供的,大家想想这里是不是使用到了模板设计模式,其实设计模式无处不在,有时间多看看大佬们写的代码,可以收获很多东西的。
其三、submit有返回值,execute没有返回值。
2.那我们就来看看execute方法,上代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
//关键点1
if (addWorker(command, true))
return;
c = ctl.get();
}
//关键点2
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
//关键点3
addWorker(null, false);
}
else if (!addWorker(command, false))
//关键点4
reject(command);
}
说说几个关键点:
关键点1:
这里判断当前有几个Worker,如果worker数量小于corePoolSize则创建Worker;
关键点2:
如果大于corePoolSize个worker了,就往队列里面塞呗。
关键点3:
往队列里面塞成功了,而且是刚运行,并且worker数量为0,则创建一个worker。这里咱们掰扯掰扯,假如咱们的corePoolSize为0,那是不是表示前面还没有worker来干活啊,没人干活可不行,得创建个worker来干活。
关键点4:
如果核心worker满了(等于corePoolSize了),并且队列里面也塞满了,那就创建非核心worker,最多创建
maximumPoolSize-corePoolSize个非核心worker;如果worker和队列全满了,那就reject(拒绝)吧。
3.看看worker的庐山真面目
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
final Thread thread;
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
}
//ThreadPoolExecutor的方法
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {//关键点1
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {//关键点2
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
在addWorker方法中,会创建Worker对象,当创建成功后,会执行worker对象中的线程的start方法【this.thread = getThreadFactory().newThread(this);这个thread是worker的属性,是个线程】,而该线程会执行worker的run方法,从而调用runWorker方法。这里咱们也主要看几个关键点。
关键点1:
while (task != null || (task = getTask()) != null) 这个代码块就是通过while循环自旋,从队列中获取任务,如果任务为null则推出循环,也就是释放worker,那什么情况会返回null,看关键点2。
关键点2:
关注这个判断逻辑:
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())),来详细聊聊这个条件:
这个条件可以拆成两部分:
条件一、(wc > maximumPoolSize || (timed && timedOut)
条件二、(wc > 1 || workQueue.isEmpty())
只有两个条件都为true才会返回null,只有返回null了,才会销毁worker,也就是销毁多余的worker;
看条件一、正常情况下工作数量不可能大于maximumPoolSize,timed = allowCoreThreadTimeOut || wc > corePoolSize;allowCoreThreadTimeOut没有设置情况下为false,所以当前工作worker数量大于核心线程数量满足条件;
再看timedOut什么时候为true,当time=true时,调用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)从队列中获取数据,如果超过keepAliveTime时间还没获取到数据,则timedOut=true,那什么时候获取不到数据?正常情况下是队列中没有任务才会获取不到任务。
看条件二、当workQueue.isEmpty()为空时满足条件;
综上,我们可以看出,当worker数量大于核心线程数量(也就是有杂牌军),并且队列中没有任务时,就满足了条件,满足条件表明将销毁woker。因为这里必须是大于核心线程数才会销毁,所以也就表明了会保留核心线程数个worker。
ok,眼睛花了,也写的差不多了,欢迎大家评论区留言,如果对你有帮助,也可以帮忙转发转发,点点赞!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)