对比学习孪生网络
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下对比学习孪生网络之简单的手写数字集代码实战
#博学谷IT学习技术支持
文章目录
- 对比学习孪生网络
- 前言
- 一、什么是对比学习
- 二、手写数字MNIST实战代码
-
- 总结
前言
对比学习孪生网络最近很火,这种无监督的学习方式作者最近也一直在关注和学习,今天和大家分享的是最简单的通过手写数字MNIST入门对比学习孪生网络,看看这种无监督网络的效果。
一、什么是对比学习
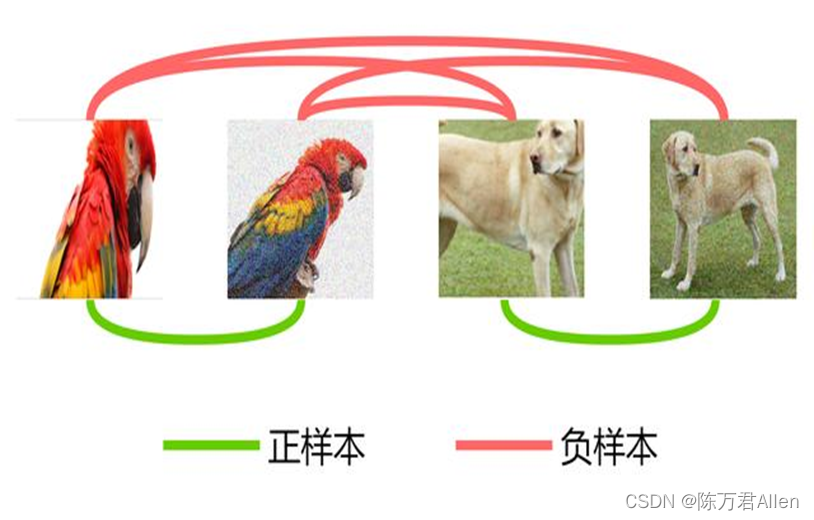
对比学习是通过对同一张猫的图像做数据增强学习之后,得到2张不同的猫,这两张猫就是一组正样本,抽样其他的猫和狗就为负样本的一种完全无监督的模型,这样的好处的在隐藏特征空间可以拉近相同的图片,拉远不相同的图片。
注意点:
- 输入图片做完数据增强之后,一定是走同样的一对encoder网络。孪生网络
- 最后模型训练完成做INFERENCE的时候是输入一张图片,用中间层h的EMBEDDING做下游任务,而不是最后的输出层z。这样模型的泛化能力更强。
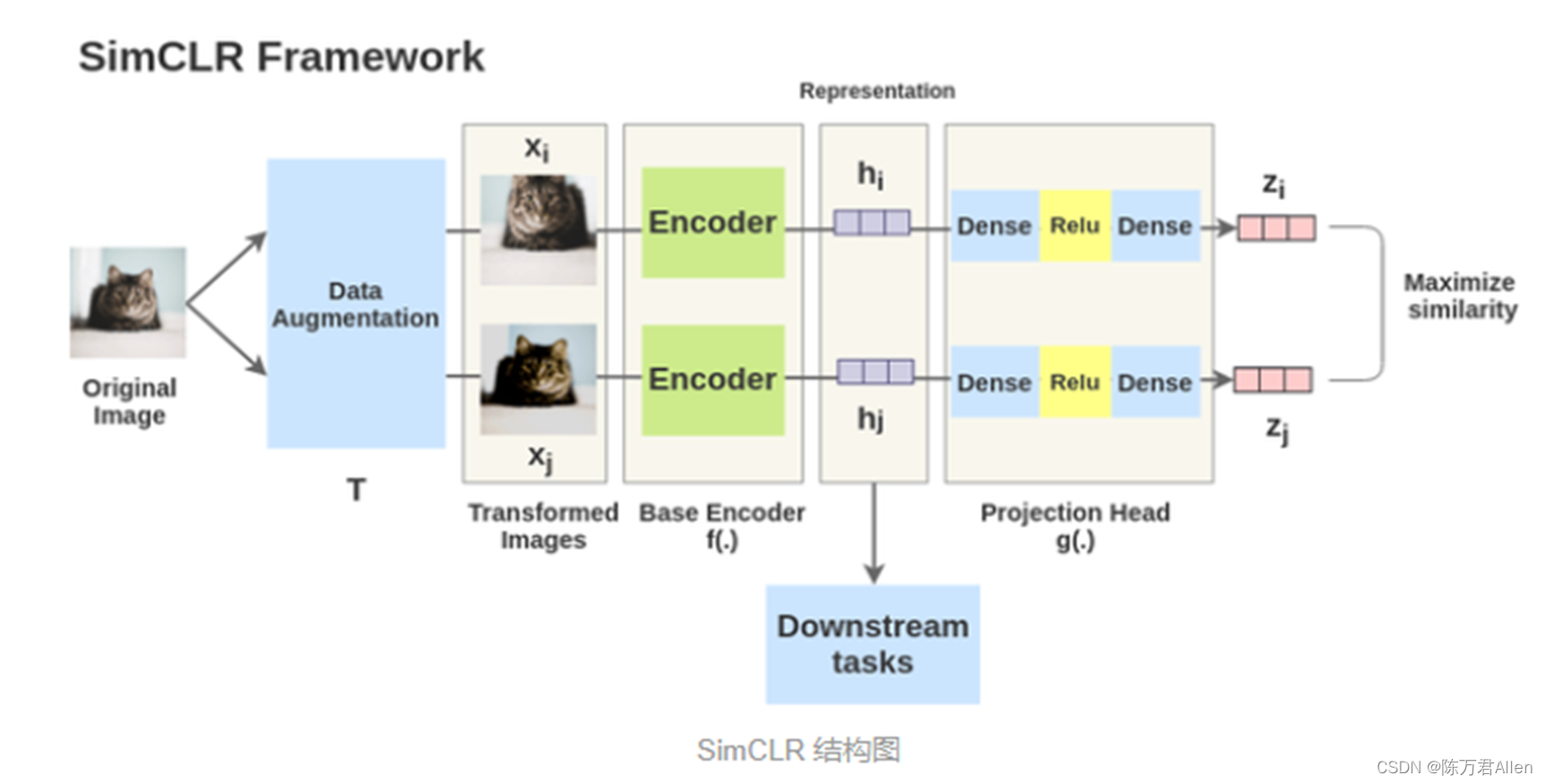
二、手写数字MNIST实战代码
1.配置文件
import torch
from torch.utils.data import DataLoader
import Dataset
from torch import nn
from torchvision import transforms, models, datasets
import torch.optim as optim
import torchvision
import copy
from model import SimCLR
import argparse
parser = argparse.ArgumentParser(description="对比学习学习图像表征")
parser.add_argument('--image_dir',default='./image_test2/',help="输入文件夹")
parser.add_argument('--batch_size',default=512,type=int,help="")
parser.add_argument('--feature_extract',default=False,type=bool,help="是否需要冻住预训练模型参数")
parser.add_argument('--image_size',default=28,type=int,help="")
parser.add_argument('--encoder_model',default=models.resnet50(),help="")
parser.add_argument('--temperature',default=0.1,type=int,help="")
parser.add_argument('--encoder_output_dim',default=28,type=int,help="")
parser.add_argument('--lr',default=0.01,type=int,help="")
parser.add_argument('--step_size',default=20,type=int,help="")
parser.add_argument('--gamma',default=0.9,type=int,help="")
parser.add_argument('--num_epochs',default=100,type=int,help="")
parser.add_argument('--filename',default="best_test.pth",type=str,help="")
args = parser.parse_args()
class Config(object):
# 配置参数
def __init__(self,args):
self.batch_size = args.batch_size
self.num_epochs = args.num_epochs
train_dataset = torchvision.datasets.MNIST(
root='./MNIST',
train=True,
download=True,
transform=torchvision.transforms.ToTensor()
)
val_dataset = torchvision.datasets.MNIST(
root='./MNISt',
train=False,
download=True,
transform=torchvision.transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=self.batch_size, shuffle=True,drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=self.batch_size, shuffle=False,drop_last=True)
self.dataloaders = {'train': train_loader, 'valid': test_loader}
# 是否用人家训练好的特征来做
self.feature_extract = args.feature_extract
self.encoder_output_dim = args.encoder_output_dim
self.image_size = args.image_size
self.filename = args.filename
# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# encoder的模型选择
if args.encoder_model is not None:
self.encoder_model = args.encoder_model
self.num_ftrs = self.encoder_model.fc.in_features
self.encoder_model.fc = nn.Sequential(nn.Linear(self.num_ftrs, self.encoder_output_dim))
self.contrastive_model = SimCLR(self.encoder_model,self.image_size,self.encoder_output_dim,temperature=args.temperature)
else:
self.contrastive_model = None
# 优化器设置
# self.optimizer_ft = optim.Adam(self.contrastive_model.parameters(), lr=args.lr)
# self.set_parameter_requires_grad()
self.optimizer_ft = optim.SGD(self.contrastive_model.parameters(), lr=args.lr)
self.scheduler = optim.lr_scheduler.StepLR(self.optimizer_ft, step_size=args.step_size, gamma=args.gamma) # 学习率每7个epoch衰减成原来的1/10
def set_parameter_requires_grad(self):
if self.feature_extract:
for param in self.encoder_model.parameters():
param.requires_grad = False
2.模型定义
import torch
from torch import nn
class SimCLR(nn.Module):
def __init__(
self,
encoder,
image_size,
encoder_output_dim,
temperature=0.1
):
super().__init__()
self.encoder = encoder
self.mlp = nn.Sequential(
nn.Linear(encoder_output_dim, encoder_output_dim),
nn.BatchNorm1d(encoder_output_dim),
nn.ReLU(inplace = True),
nn.Linear(encoder_output_dim, encoder_output_dim)
)
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 灰度图
out_channels=3, # 要得到几多少个特征图
kernel_size=1, # 卷积核大小
stride=1, # 步长
padding=0, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1
), # 输出的特征图为 (16, 28, 28)
nn.ReLU() # relu层
)
self.fc1 = nn.Sequential(
nn.Linear(784,1024),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(1024,1024),
nn.ReLU()
)
self.fc3 = nn.Sequential(
nn.Linear(1024,2),
nn.ReLU()
)
# 超简单版本,看看二维效果图
def forward(self,inputs,input_size):
device = inputs.device
input_1,input_2 = torch.split(inputs,[input_size,input_size],dim=0)
input_1 = input_1.to(device)
input_2 = input_2.to(device)
x_1 = input_1.reshape(input_size,-1)
fc1_1 = self.fc1(x_1)
fc2_1 = self.fc2(fc1_1)
output_1 = self.fc3(fc2_1)
x_2 = input_2.reshape(input_size, -1)
fc1_2 = self.fc1(x_2)
fc2_2 = self.fc2(fc1_2)
output_2 = self.fc3(fc2_2)
return None , None ,output_1 , output_2
# resnet50版本
# def forward(self, inputs, input_size):
# device = inputs.device
# input_1, input_2 = torch.split(inputs, [input_size, input_size], dim=0)
# input_1 = input_1.to(device)
# input_2 = input_2.to(device)
#
# hidden_layer_1 = self.conv1(input_1)
# hidden_layer_2 = self.conv1(input_2)
#
# hidden_layer_i = self.encoder(hidden_layer_1)
# hidden_layer_j = self.encoder(hidden_layer_2)
#
# output_1 = self.mlp(hidden_layer_i)
# output_2 = self.mlp(hidden_layer_j)
#
# return hidden_layer_i, hidden_layer_j, output_1, output_2
3.模型训练
import torch
import copy
from config import Config, args
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as plt
def params_test(model):
print("Params to learn:")
params_to_update = []
for name, param in model.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t", name)
def train_model(model, dataloaders, optimizer, device, scheduler, batch_size, num_epochs, filename):
torch.manual_seed(1)
best_loss = [9999999999]
model.to(device)
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # 训练
else:
model.eval() # 验证
running_loss = 0.0
# 把数据都取个遍
for index, (inputs, labels_ground) in enumerate(tqdm(dataloaders[phase])):
# 只能双数做为训练样本,测试没有训练过的单数数据效果
# labels = labels_ground[labels_ground % 2 == 0]
# inputs = inputs[labels_ground % 2 == 0]
# inputs = inputs.to(device)
# labels = labels.to(device)
#
# if len(labels) % 2 != 0:
# inputs = inputs[0:-1,:,:,:]
# labels = labels[0:-1,]
# 训练全部样本
labels = labels_ground.to(device)
inputs = inputs.to(device)
input_size = int(len(labels) / 2)
label_1, label_2 = torch.split(labels, [input_size, input_size], dim=0)
label = (label_1 == label_2)
label = (label+0.0).to(device)
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
with torch.set_grad_enabled(phase == 'train'):
# 查看模型需要训练的参数
# params_test(model)
_,_,output_1,output_2 = model(inputs,input_size)
eucd2 = torch.pow(torch.subtract(output_1, output_2), 2)
eucd2 = torch.sum(eucd2, 1)
eucd = torch.sqrt(eucd2 + 1e-6)
loss_pos = torch.multiply(label, eucd2)
loss_neg = torch.multiply(torch.subtract(1.0, label), torch.pow(
torch.maximum(torch.subtract(torch.tensor(5.0), eucd), torch.tensor(0)), 2))
loss = torch.mean(torch.add(loss_neg, loss_pos))
# 训练阶段更新权重
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
# 得到最好那次的模型
if phase == 'valid' and epoch_loss < min(best_loss):
best_loss = valid_losses
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(), # 字典里key就是各层的名字,值就是训练好的权重
'best_acc': best_loss,
'optimizer': optimizer.state_dict(), # 优化器的状态信息
}
torch.save(state, filename)
if phase == 'valid':
valid_losses.append(epoch_loss)
scheduler.step() # 学习率衰减
if phase == 'train':
train_losses.append(epoch_loss)
LRs.append(optimizer.param_groups[0]['lr'])
print()
if phase == 'valid' and epoch % 1 == 0:
print('episode %d: train loss %.3f' % (epoch, epoch_loss))
print('Best val Loss: {:4f}'.format(min(best_loss)))
# 训练完后用最好的一次当做模型最终的结果,等着一会测试
# model.load_state_dict(best_model_wts)
return model, valid_losses, train_losses, LRs
if __name__ == '__main__':
config = Config(args)
model_ft, valid_losses, train_losses, LRs = train_model(
config.contrastive_model,
config.dataloaders,
config.optimizer_ft,
num_epochs=config.num_epochs,
batch_size=config.batch_size,
device=config.device,
scheduler=config.scheduler,
filename=config.filename)
plt.plot(range(1,len(train_losses)+1),train_losses, color='b', label = 'train_losses')
plt.legend(), plt.ylabel('loss'), plt.xlabel('epochs'), plt.title('train_losses'), plt.show()
plt.plot(range(1,len(valid_losses)+1),valid_losses, color='b', label = 'valid_losses')
plt.legend(), plt.ylabel('loss'), plt.xlabel('epochs'), plt.title('valid_losses'), plt.show()
plt.plot(range(1,len(LRs)+1),LRs, color='b', label = 'LRs')
plt.legend(), plt.ylabel('LRs'), plt.xlabel('epochs'), plt.title('LRs'), plt.show()
3.模型测试
import torch
from config import Config, args
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn.mixture import GaussianMixture
# 保存文件的名字
def visualize(embed, labels):
labelset = set(labels.tolist())
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111)
#fig, ax = plt.subplots()
for label in labelset:
indices = np.where(labels == label)
ax.scatter(embed[indices,0], embed[indices,1], label = label, s = 20)
ax.legend()
fig.savefig('embed_2.jpeg', format='jpeg', dpi=600, bbox_inches='tight')
plt.close()
filename=r'C:\best_test.pth'
# 加载模型
checkpoint = torch.load(filename)
config = Config(args)
config.contrastive_model.load_state_dict(checkpoint['state_dict'])
dataiter = iter(config.dataloaders['valid'])
images, labels = next(dataiter)
result_layer_0,result_layer_1 = config.contrastive_model(images,256)[2],config.contrastive_model(images,256)[3]
output = torch.concat([result_layer_0,result_layer_1],0)
labels = labels.numpy()
#这里写的有点丑....就简单测试一下
one_index = list(np.where(labels == 1)[0])
all_one_tensor = output[one_index]
two_index = list(np.where(labels == 2)[0])
all_two_tensor = output[two_index]
three_index = list(np.where(labels == 3)[0])
all_three_tensor = output[three_index]
four_index = list(np.where(labels == 4)[0])
all_four_tensor = output[four_index]
five_index = list(np.where(labels == 5)[0])
all_five_tensor = output[five_index]
six_index = list(np.where(labels == 6)[0])
all_six_tensor = output[six_index]
seven_index = list(np.where(labels == 7)[0])
all_seven_tensor = output[seven_index]
eight_index = list(np.where(labels == 8)[0])
all_eight_tensor = output[eight_index]
nine_index = list(np.where(labels == 9)[0])
all_nine_tensor = output[nine_index]
zero_index = list(np.where(labels == 0)[0])
all_zero_tensor = output[zero_index]
total_tensor_list = [all_zero_tensor] + [all_one_tensor] + [all_two_tensor] + [all_three_tensor] + [all_four_tensor] + [all_five_tensor] + [all_six_tensor] + [all_seven_tensor] + [all_eight_tensor] + [all_nine_tensor]
#
# 随机抽样法,两两余弦相似度对比,效果还可以
right_num = 0
wrong_num = 0
right_cos_sim = []
wrong_cos_sim = []
index1 = random.sample(range(0,20),20)
index2 = random.sample(range(0,20),20)
for i in range(20):
right_cos_sim.append(round(torch.cosine_similarity(all_eight_tensor[index1[i]],all_eight_tensor[index2[i]],dim=0).item(),6))
wrong_cos_sim.append(round(torch.cosine_similarity(all_eight_tensor[index1[i]],all_one_tensor[index2[i]],dim=0).item(),6))
if torch.cosine_similarity(all_eight_tensor[index1[i]],all_eight_tensor[index2[i]],dim=0) >= \
torch.cosine_similarity(all_eight_tensor[index1[i]],all_one_tensor[index2[i]],dim=0):
right_num += 1
else:
wrong_num += 1
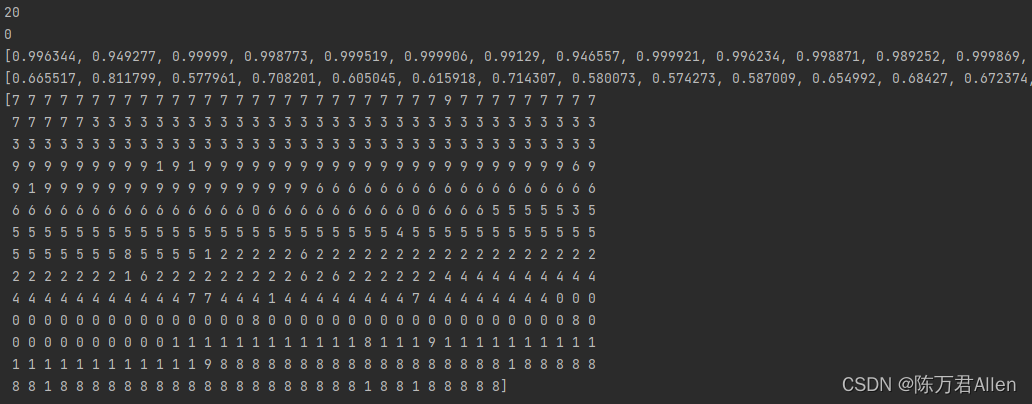
print(right_num)
print(wrong_num)
print(right_cos_sim)
print(wrong_cos_sim)
# Kmeans纯聚类算法对比
total_data = torch.concat([all_zero_tensor,all_one_tensor,all_two_tensor,all_three_tensor,all_four_tensor,all_five_tensor,all_six_tensor,all_seven_tensor,all_eight_tensor,all_nine_tensor],dim=0).detach().numpy()
total_label_list = list(str(0) * len(all_zero_tensor) + str(1) * len(all_one_tensor) + str(2) * len(all_two_tensor)
+ str(3) * len(all_three_tensor) + str(4) * len(all_four_tensor)
+ str(5) * len(all_five_tensor) + str(6) * len(all_six_tensor)
+ str(7) * len(all_seven_tensor) + str(8) * len(all_eight_tensor)
+ str(9) * len(all_nine_tensor))
total_label_list = [ int(i) for i in total_label_list]
cluster = KMeans(n_clusters=10).fit(total_data)
cluster_labels = cluster.labels_
print(cluster_labels)
output = output.detach().numpy()
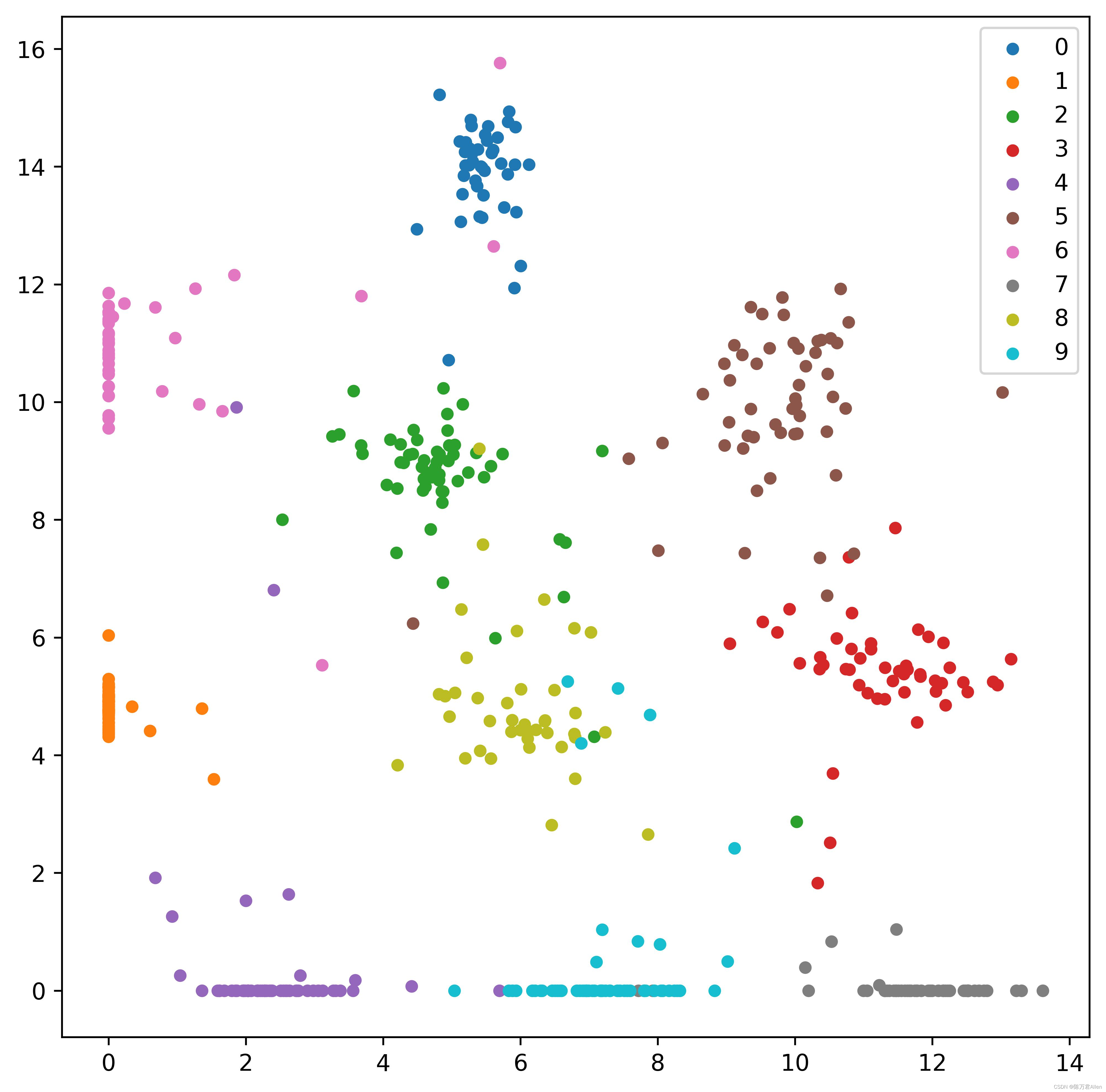
visualize(output, labels)
最后看看模型的测试效果,基本都正确。
总结
作者这里没有自己写数据增强,因为默认手写数字之间自带了数据增强的效果,其实也试了加上数据增强,区别不是很大。高维的准确效果肯定比2维的要好,resnet的效果肯定比最简单的MLP层效果好。这是无监督的方法,准确率接近有监督模型,但是如果训练集没有见过的数据,效果会有下降,比如只用双数数字进行训练,测试单数数字的泛化能力。也可以试试其他损失函数效果。
对比学习最大的优势是可以做一个强大的预训练模型,得到一个很好的图片embedding,继续做下游任务。进行各种fine tuning的操作。
大家可以试试,有问题可以留言。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)