Python
Java
PHP
IOS
Android
Nodejs
JavaScript
Html5
Windows
Ubuntu
Linux
二叉搜索树
2023-05-16
目录
定义简介
查找结点
插入结点
删除结点
排序
二叉搜索树的效率
二叉搜索树的退化
二叉搜索树常见应用
定义简介
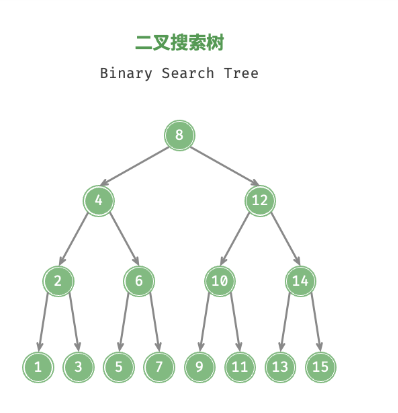
「二叉搜索树 Binary Search Tree」满足以下条件:
1. 对于根结点,左子树中所有结点的值 < 根结点的值 < 右子树中所有结点的值;
2. 任意结点的左子树和右子树也是二叉搜索树,即也满足条件 1. ;
查找结点
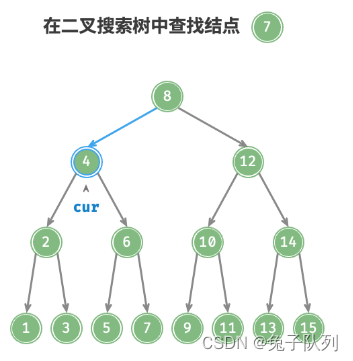
给定目标结点值 num ,可以根据二叉搜索树的性质来查找
声明一个结点 cur ,从二叉树的根结点 root出发,循环比较结点值 cur.val 和 num 之间的大小关系
若 cur.val < num ,说明目标结点在 cur 的右子树中,因此执行 cur = cur.right ;
若 cur.val > num ,说明目标结点在 cur 的左子树中,因此执行 cur = cur.left ;
若 cur.val = num ,说明找到目标结点,跳出循环并返回该结点即可;
二叉搜索树的查找操作和二分查找算法如出一辙,也是在每轮排除一半情况
循环次数最多为二叉树的高度,当二叉树平衡时,使用 𝑂(log 𝑛) 时间
插入结点
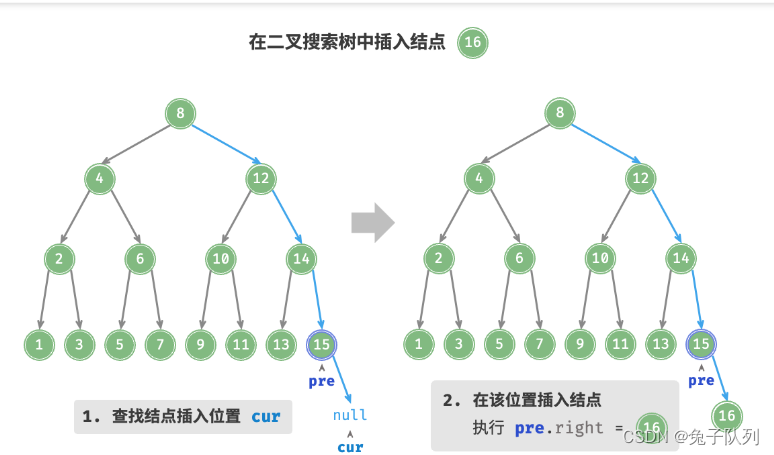
给定一个待插入元素 num ,为了保持二叉搜索树“左子树 < 根结点 < 右子树”的性质,插入操作分为两步:
1. 查找插入位置:与查找操作类似,从根结点出发,根据当前结点值和 num 的大小关系循环向下搜索,直到越过叶结点(遍历到 null )时跳出循环;
2. 在该位置插入结点:初始化结点 num ,将该结点放到 null 的位置;
二叉搜索树不允许存在重复结点,否则将会违背其定义
因此若待插入结点在树中已经存在,则不执行插入,直接返回即可
为了插入结点,需要借助辅助结点 pre 保存上一轮循环的结点,这样在遍历到 null 时,也可以获取到其父结点,从而完成结点插入操作
与查找结点相同,插入结点使用 𝑂(log 𝑛) 时间
删除结点
与插入结点一样,需要在删除操作后维持二叉搜索树的“左子树 < 根结点 < 右子树”的性质
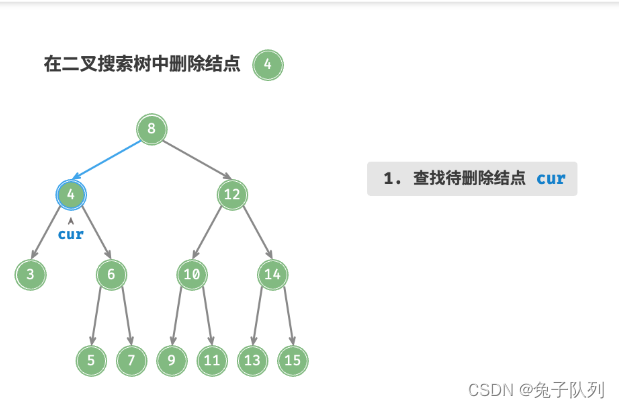
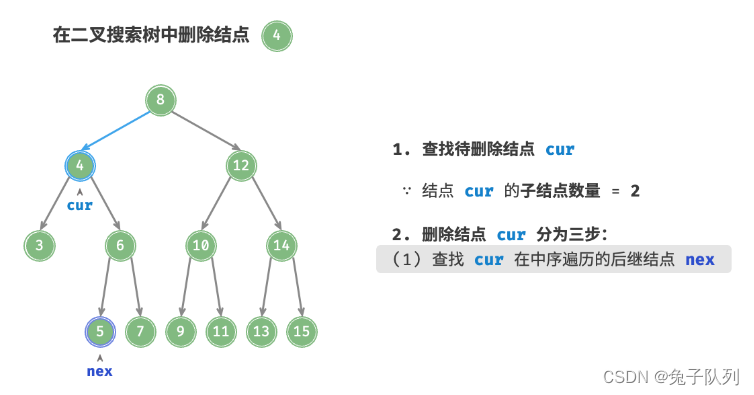
首先,需要在二叉树中执行查找操作,获取待删除结点
接下来,根据待删除结点的子结点数量,删除操作需要分为三种情况:
当待删除结点的子结点数量 = 0 时,表明待删除结点是叶结点,直接删除即可
当待删除结点的子结点数量 = 1 时,将待删除结点替换为其子结点即可
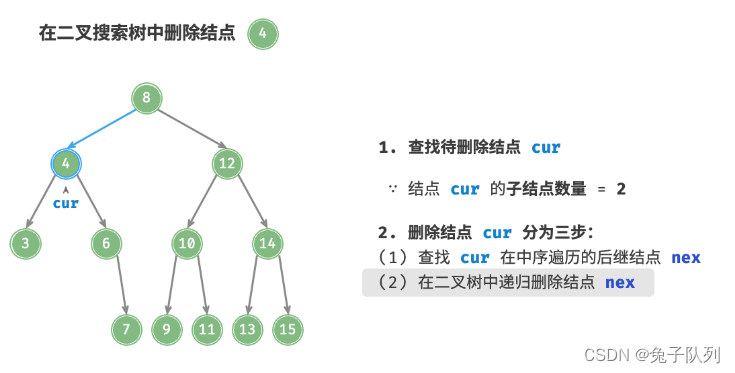
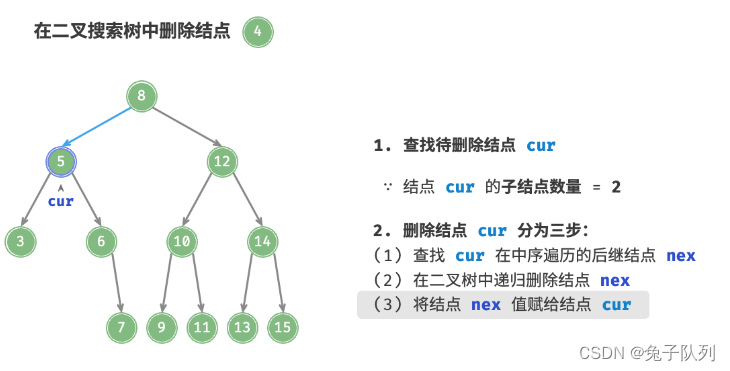
当待删除结点的子结点数量 = 2 时,删除操作分为三步:
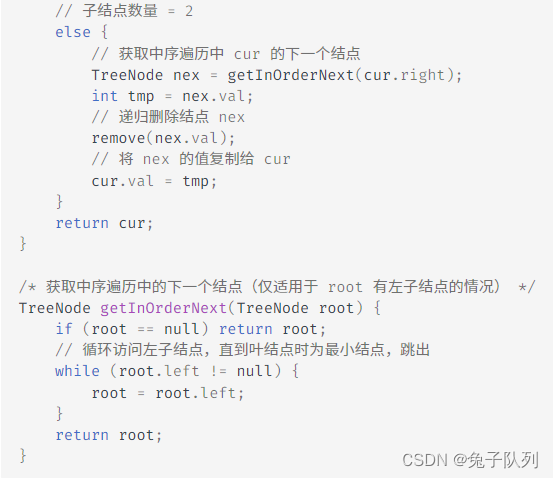
1. 找到待删除结点在 中序遍历序列 中的下一个结点,记为 nex ;
2. 在树中递归删除结点 nex ;
3. 使用 nex 替换待删除结点;
删除结点操作也使用 𝑂(log 𝑛) 时间,其中查找待删除结点 𝑂(log 𝑛) ,获取中序遍历后继结点 𝑂(log 𝑛)
排序
「中序遍历」遵循“左 → 根 → 右”的遍历优先级,而二叉搜索树遵循“左子结点 < 根结点 < 右子结点”的大小关系
因此,在二叉搜索树中进行中序遍历时,总是会优先遍历下一个最小结点
从而得出一条重要性质:二叉搜索树的中序遍历序列是升序的
借助中序遍历升序的性质,在二叉搜索树中获取有序数据仅需 𝑂(𝑛) 时间,而无需额外排序,非常高效
二叉搜索树的效率
假设给定 𝑛 个数字,最常用的存储方式是「数组」,那么对于这串乱序的数字,常见操作的效率为:
查找元素:由于数组是无序的,因此需要遍历数组来确定,使用 𝑂(𝑛) 时间;
插入元素:只需将元素添加至数组尾部即可,使用 𝑂(1) 时间;
删除元素:先查找元素,使用 𝑂(𝑛) 时间,再在数组中删除该元素,使用 𝑂(𝑛) 时间;
获取最小 / 最大元素:需要遍历数组来确定,使用 𝑂(𝑛) 时间;
为了得到先验信息,也可以预先将数组元素进行排序,得到一个「排序数组」,此时操作效率为:
查找元素:由于数组已排序,可以使用二分查找,平均使用 𝑂(log 𝑛) 时间;
插入元素:先查找插入位置,使用 𝑂(log 𝑛) 时间,再插入到指定位置,使用 𝑂(𝑛) 时间;
删除元素:先查找元素,使用 𝑂(log 𝑛) 时间,再在数组中删除该元素,使用 𝑂(𝑛) 时间;
获取最小 / 最大元素:数组头部和尾部元素即是最小和最大元素,使用 𝑂(1) 时间;
观察发现,无序数组和有序数组中的各项操作的时间复杂度是“偏科”的,即有的快有的慢;
而二叉搜索树的各项操作的时间复杂度都是对数阶,在数据量 𝑛 很大时有巨大优势
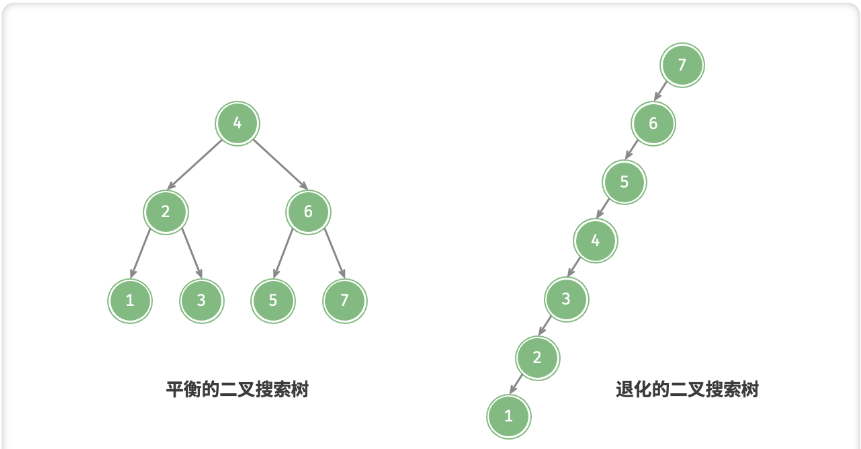
二叉搜索树的退化
理想情况下,希望二叉搜索树的是“左右平衡”的,此时可以在 log 𝑛 轮循环内查找任意结点
如果动态地在二叉搜索树中插入与删除结点,则可能导致二叉树退化为链表,此时各种操作的时间复杂度也退化之 𝑂(𝑛)
在实际应用中,如何保持二叉搜索树的平衡,也是一个需要重要考虑的问题
二叉搜索树常见应用
系统中的多级索引,高效查找、插入、删除操作
各种搜索算法的底层数据结构
存储数据流,保持其已排序
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
二叉搜索树
二叉搜索树 的相关文章
搭建Zabbix6.0版本
Zabbix简介 Zabbix是一个企业级的开源分布式监控解决方案 xff0c 由C语言编写而成的底层架构 xff08 server端和agent端 xff09 xff0c 由一个国外的团队持续维护更新 xff0c 软件可以自由下载使用 x
Linux--网络服务器配置步骤详情【1】
目录 一 配置ip地址 二 配置yum服务器 三 配置安装nfs服务器 1 第一台机 xff1a 2 第二台机 xff1a 四 安装配置samba服务器 五 安装配置DHCP 一 配置ip地址 root 64 wenjian vi etc
vscode提取拓展时出错。XHR failed
vscode提取拓展时出错 XHR failed huas weew12的博客 CSDN博客 提取扩展时出错 转载 这这人家的步骤操作 果然就好了
python天气语音播报
今天的小项目是一个天气播报 xff0c 项目效果是点击运行就读出今天的天气 那么我们可以分两步走 xff0c 第一个 xff1a 先爬取到今天的天天气内容 xff0c 第二步 xff1a 电脑读出今天的天气内容 想要电脑读出内容 xff0c
随机推荐
Linux配置SSH远程登录管理
目录 一 SSH协议 1 SSH简介 2 SSH的优点 3 SSH远程控制软件及服务 二 SSH远程管理配置 1 配置OpenSSH服务端 2 使用SSH客户端软件 xff08 1 xff09 SSH远程登录 xff08 2 xff09 s
Linux系统防火墙firewalld
目录 一 firewalld概述 二 firewalld和iptables的关系 三 firewalld区域的概念 四 firewalld数据处理流程 五 firewalld检查数据包源地址的规则 六 firewalld防火墙的配置种类 1
ubuntu18.04忘记密码后,如何重置密码的方法
ubuntu18 04安装在VMware虚拟上 ubuntu18 04忘记密码后 xff0c 如何重置密码 xff1f 重启系统后 xff0c 当跳出如下图所示画面时 xff0c 按住Shift键不放 xff0c 等待 2 但出现如下图所示
Cloudflare 小记
url xff1a https cn airbusan com content individual 五秒盾打开后一般会出现这个页面 xff0c 然后让你点击确认你是不是真人 xff0c 点击成功后会跳往所访问的url页面 有时候不会出现这
2021.11.17 指针引用数组(指针+1,指针-1以及书写格式)
例如 xff1a int arr 10 61 1 2 3 4 5 6 7 8 9 10 int p 61 arr int q 61 amp arr 0 1 p 和 q 表示的都是一样的 xff0c 表示的都是数组首元素的地址 xff0c 只
超详细的vscode 配置FTP,并本地编辑
废话少说 xff0c 直接上步骤 xff1a 搜索sftp插件并安装 xff1b 安装成功之后 ctrl 43 shift 43 p 搜索sftp config设置内容 没有的需要自己加 xff0c 有的可以不用加 xff1b 34 nam
Python求1+2+3+...+100的值,计算平方根的两个代码程序
目录 前言 一 求1 43 2 43 3 43 43 100的值 1 实现的功能 2 代码程序 3 运行截图 二 计算平方根 1 实现的功能 2 代码程序 3 运行截图 前言 1 因多重原因 xff0c 本博文由两个程序代码部分组成 xff
Python求1+2+3+...+100的值,计算自然数的立方和的两个程序代码
目录 前言 一 求1 43 2 43 3 43 43 100的值 1 实现的功能 2 代码程序 3 运行截图 二 计算自然数的立方和的 1 实现的功能 2 代码程序 3 运行截图 前言 1 因多重原因 xff0c 本博文由两个程序代码部分组
Go基本数据类型与string类型互转
一 基本数据类型转string类型 方法一 xff1a fmt Sprintf 34 参数 34 表达式 1 官方解释 xff1a Sprintf根据format参数生成格式化的字符串并返回该字符串 func Sprintf format
linux下如何设置开机自启(这里以seata服务为例)
1 编写启动脚本 xff0c 大部分都是相同的 xff0c 但是有些程序可能略要修改 Unit Description 61 Seata Server After 61 network target Service User 61 root
MIUI12.5系统精简列表更新版200多个包,ADB卸载
系统MIUI12 5 6 xff0c 无ROOT无面具没破解 xff0c 仅使用ADB工具箱 设备卸载后经过重启测试是否卡米 xff0c 这些都不会卡米 另外要说 xff0c 有些卸载不会卡米 xff0c 但是功能会失效 xff0c 比如
kali安装卡在simple-cdd不动?在右下角,有个小小的符号,找到网络适配器,然后断掉,很快就安装好了。
两种方式为button元素注册点击事件,this指向
两种方式 xff1b 第一种指向button xff0c 第二种 指向window
强化学习实战——Q learning 实现倒立摆
倒立摆参数以及数学模型 首先是写一个倒立摆的AGENT模型 pendulum env py import numpy as np import matplotlib pyplot as plt import matplotlib impor
dependencies.dependency
依赖包有两个 xff0c 根据最下一行的提示找到项目的pom xml文件找到依赖
Vue3---语法初探
目录 hello world 实现简易计时显示 反转字符串 显示隐藏 了解循环 了解双向绑定实现简易记事 设置鼠标悬停的文本 组件概念初探 xff0c 进行组件代码拆分 hello world 最原始形态 xff0c 找到 id 为 roo
MySQL实战解析底层---普通索引和唯一索引,应该怎么选择
目录 前言 查询过程 更新过程 change buffer 的使用场景 索引选择和实践 change buffer 和 redo log 前言 在不同的业务场景下 xff0c 应该选择普通索引 xff0c 还是唯一索引 xff1f 假设你在
准备离开:致消散的梦想
学到现在基本都是悲剧以前的队友现在大多放弃了初心以前的好学长现在摆烂和失败开学时的场景再也见不到了大一开学开启OJ xff0c 那是一个永远绚丽的夜晚不管是学长还是同学 xff0c 都在那时期待未来 xff0c 欲力竭以圆其说而不是现在的颓
MySQL实战解析底层---MySQL为什么有时候会选错索引
目录 前言 优化器的逻辑 索引选择异常和处理 前言 在 MySQL 中一张表其实是可以支持多个索引的但是你写 SQL 语句的时候 xff0c 并没有主动指定使用哪个索引也就是说 xff0c 使用哪个索引是由 MySQL 来确定的不知道你有没
二叉搜索树
目录 定义简介 查找结点 插入结点 删除结点 排序 二叉搜索树的效率 二叉搜索树的退化 二叉搜索树常见应用 定义简介 二叉搜索树 Binary Search Tree 满足以下条件 xff1a 1 对于根结点 xff0c 左子树中所有结点的
热门标签
wixlib
awssdkjsv3
whmcs
ccxt
evc4
swift415
nginit
yarnpkgv2
liveview
kartograph
eclipse35
rackattack
sabre
ydndb
moniker