1. virtio基本构建模块
virtio是一种I/O半虚拟化解决方案,是一套通用I/O设备虚拟化的程序,是对半虚拟化Hypervisior中的一组通用I/O设备的抽象。是标准化的的开放接口,以使得VM能够访问简化的设备,如块设备和网络设备等。
一个guest VM或者guest指的是在物理计算机上安装、执行和托管的VM。托管guest VM的计算机称之为host,它为guest VM提供资源。Guest VM通过hypervisor在host OS之上运行独立的OS。例如,host将为guest提供虚拟的NIC,guest感觉好像是在使用真实的NIC,而实际上使用的是虚拟的NIC
以下模块用于创建virtio环境:
- KVM:kernel based virtual machine,允许Linux充当hypervisor,以便host可以运行多个隔离的虚拟环境(guest)。KVM基本上为Linux提供了hypervisor功能。这意味这hypervisor组件(例如内存管理、调度程序、网络堆栈等)作为Linux内核的一部分提供。VM是由标准Linux 调度程序通过专用虚拟硬件(例如网络适配器)调度的常规Linux进程。
- QEMU:一个托管的虚拟机监视器,可以通过仿真为guest提供一组不同的硬件和设备模型。QEMU可以和KVM一起使用,以利用硬件扩展使得guest达到接近host的速度。Guest通过qemu命令行执行。CLI提供了为QEMU指定所有必须的配置选项和能力。
- Libvirt:一个将xml格式的配置转化为qemu CLI调用的接口。它还提供了一个admin daemon来配置子进程(如qumu),因此,qemu将不需要root权限。例如,当Openstack Nova要启动VM时,它使用libvirt通过为每个VM启动qemu进程。
下图显示了这三个模块如何结合在一起

- Host和guest都包含kernel space 和 user space。
- 从图中可以看出,KVM在host kernel space中运行,而libvirt在host user space中运行。
- Guest VM在qumu中运行,该进程只是在host user space上运行的进程,并与libvirt和KVM进行通信。
- 将为每个guest VM创建一个qemu进程,因此,如果您创建N个guest VM,则将有N个qemu进程,而libvirt将与他们进行通信。
2. vhost-net/virtio-net架构
virtio分为前端和后端,一个backend组件和一个frontend组件。backend组件是virtio接口的host端。frontend组件是virtio的guest端。
在vhost-net/virtio-net体系结构中,组件如下:vhost-net是在host kernel space中运行的backend,virtio-net是在guest kernel space中运行的frontend。

- 由于vhost-net和virtio-net都运行在host和guest的kernel space,因此,我们也将他们称之为驱动程序,因此,有些文章中写成vhost-net驱动程序。
- 我们在backend和frontend之间有一个单独的control plane和data plane。如前所述,control plane只是为vhost-net内核模块和qemu进程实现了virtio spec进行通信,然后将其传递给guest,并最终传递给virtio-net。Vhost-net使用vhost protocol建立框架,然后将其用于data plane,以使用共享内存区域在host和guest kernel space之间直接转发数据包。
对于每个guest,我们可以关联多个虚拟CPU(vCPU),并给每个vCPU创建RX/TX队列,因此,带有3个vCPU的详细示例如下所示(为了简单,删除control plane)

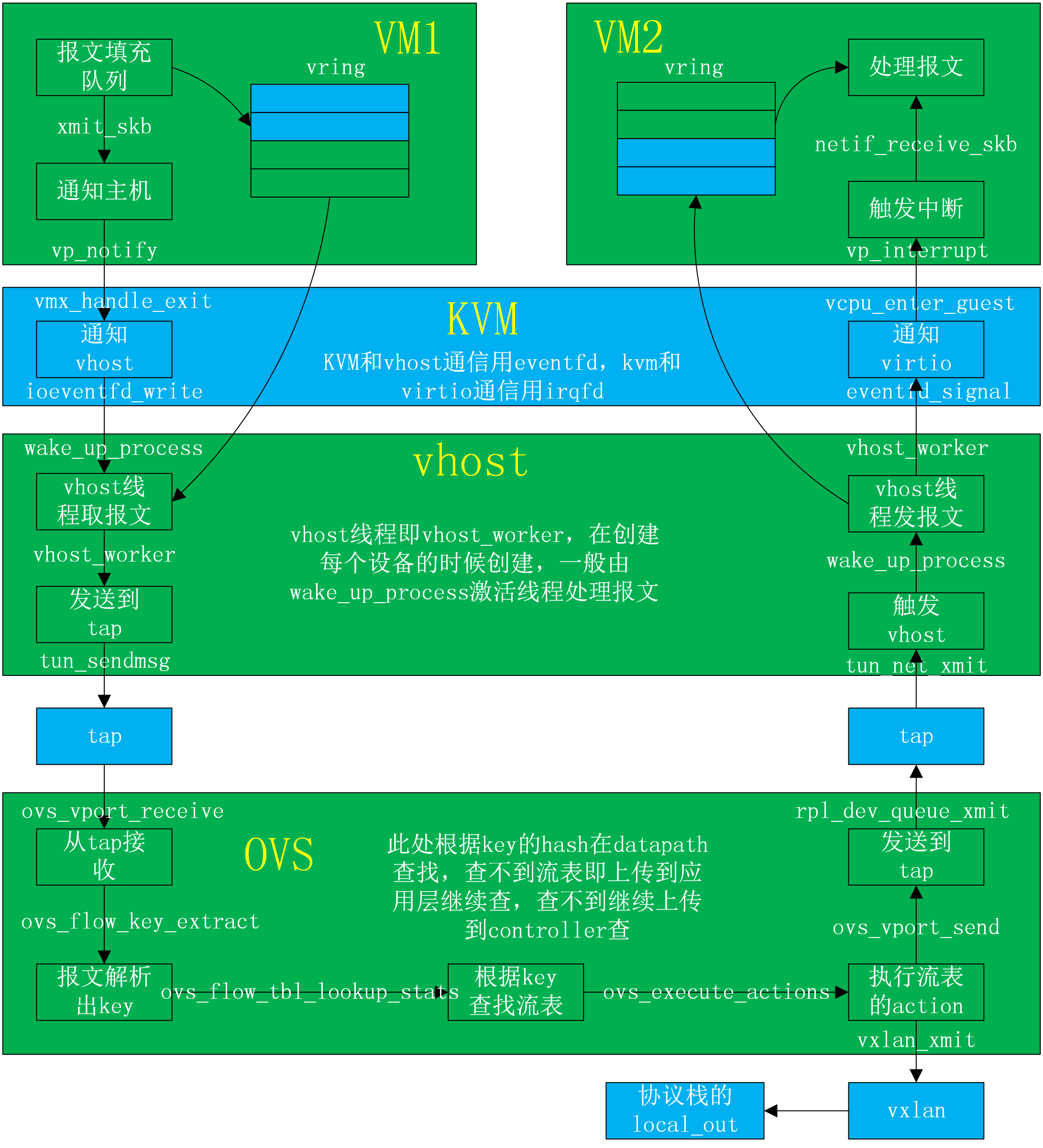
3. KVM中virtio-net与vhost-net通信
- vhost模块需要提前加载,注册一个misc的设备,供虚拟机启动时候使用。
- 虚拟机创建的时候,会初始化一个tap设备,然后启动一个vhost _$(qemu-kvm_pid)的线程,配置vring等承载数据的高度。
- guest和host进行网络数据IO的时候,只负责数据IO的中断,中断消息等由kvm模块负责。
- guest发包的时候,virtio模块负责发送数据包加入链接,然后通知kvm模块,kvm模块通过ioeventfd通知vhost模块,此时可以将有包的堆栈挂在work_list上,然后激活线程vhost进行收包操作,收到包之后传递给tap设备,再往内核协议栈中上
- guest收包的时候,首先是vhost的往tap设备发包,然后将包加入到其中一个,然后将挂在work_list,激活线程vhost,vhost进行收包的操作,然后传递到其中,然后vhost通过irqfd通知kvm模块,kvm模块给guest发送中断,guest会通过中断,到NAPI,执行轮询,接收数据包,然后上传到协议栈。
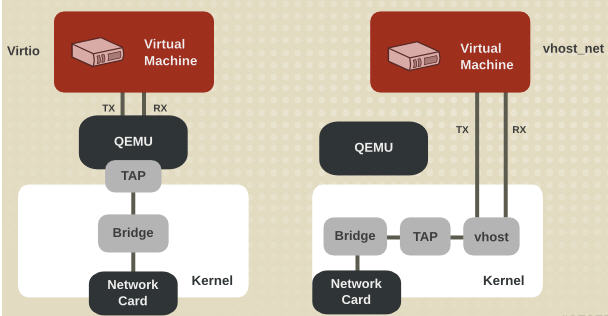
4.vhost-net 与 virtio-net 的比较
在 QEMU/KVM 中,客户机可以使用的设备大致可分为三类:
1. 模拟设备:完全由 QEMU 纯软件模拟的设备。
2. Virtio 设备:实现 VIRTIO API 的半虚拟化设备。
3. PCI 设备直接分配 (PCI device assignment) 。
4.1 全虚拟化 I/O 设备
KVM 在 IO 虚拟化方面,传统或者默认的方式是使用 QEMU 纯软件的方式来模拟 I/O 设备,包括键盘、鼠标、显示器,硬盘 和 网卡 等。模拟设备可能会使用物理的设备,或者使用纯软件来模拟。模拟设备只存在于软件中。

过程:
- 客户机的设备驱动程序发起 I/O 请求操作请求
- KVM 模块中的 I/O 操作捕获代码拦截这次 I/O 请求
- 经过处理后将本次 I/O 请求的信息放到 I/O 共享页 (sharing page),并通知用户空间的 QEMU 程序。
- QEMU 程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次 I/O 操作。
- 完成之后,QEMU 将结果放回 I/O 共享页,并通知 KMV 模块中的 I/O 操作捕获代码。
- KVM 模块的捕获代码读取 I/O 共享页中的操作结果,并把结果放回客户机。
这种方式的优点是可以模拟出各种各样的硬件设备;其缺点是每次 I/O 操作的路径比较长,需要多次上下文切换,也需要多次数据复制,所以性能较差。
4.2 virtio架构
目前 KVM 采用的的是 virtio 这个 Linux 上的设备驱动标准框架,它提供了一种 Host 与 Guest 交互的 IO 框架。
KVM/QEMU 的 vitio 实现采用在 Guest OS 内核中安装前端驱动 (Front-end driver)和在 QEMU 中实现后端驱动(Back-end)的方式。前后端驱动通过 vring 直接通信,这就绕过了经过 KVM 内核模块的过程,达到提高 I/O 性能的目的。

纯软件模拟的设备和 Virtio 设备的区别:virtio 省去了纯模拟模式下的异常捕获环节,Guest OS 可以和 QEMU 的 I/O 模块直接通信。

使用 Virtio 的完整虚机 I/O流程:

Host 数据发到 Guest:
1. KVM 通过中断的方式通知 QEMU 去获取数据,放到 virtio queue 中
2. KVM 再通知 Guest 去 virtio queue 中取数据。
vhost-net 的要求:
- qemu-kvm-0.13.0 或者以上
- 主机内核中设置 CONFIG_VHOST_NET=y 和在虚机操作系统内核中设置 CONFIG_PCI_MSI=y (Red Hat Enterprise Linux 6.1 开始支持该特性)
- 在客户机内使用 virtion-net 前段驱动
- 在主机内使用网桥模式,并且启动 vhost_net
qemu-kvm 命令的 -net tap 有几个选项和 vhost-net 相关的: -net tap,[,vnet_hdr=on|off][,vhost=on|off][,vhostfd=h][,vhostforce=on|off]
-
vnet_hdr =on|off:设置是否打开TAP设备的“IFF_VNET_HDR”标识。“vnet_hdr=off”表示关闭这个标识;“vnet_hdr=on”则强制开启这个标识,如果没有这个标识的支持,则会触发错误。IFF_VNET_HDR是tun/tap的一个标识,打开它则允许发送或接受大数据包时仅仅做部分的校验和检查。打开这个标识,可以提高virtio_net驱动的吞吐量。
-
vhost=on|off:设置是否开启vhost-net这个内核空间的后端处理驱动,它只对使用MIS-X中断方式的virtio客户机有效。
-
vhostforce=on|off:设置是否强制使用 vhost 作为非MSI-X中断方式的Virtio客户机的后端处理程序。
-
vhostfs=h:设置为去连接一个已经打开的vhost网络设备。
4.3 vhost-net
前面提到 virtio 在宿主机中的后端处理程序(backend)一般是由用户空间的QEMU提供的,然而如果对于网络 I/O 请求的后端处理能够在在内核空间来完成,则效率会更高,会提高网络吞吐量和减少网络延迟。在比较新的内核中有一个叫做 “vhost-net” 的驱动模块,它是作为一个内核级别的后端处理程序,将virtio-net的后端处理任务放到内核空间中执行,减少内核空间到用户空间的切换,从而提高效率。
4.4 vhost_user
4.4.1 什么是 vhost-user
在 vhost_net 的方案中,由于 vhost_net 实现在内核中,guest 与 vhost_net 的通信,相较于原生的 virtio 方式性能上有了一定程度的提升,从 guest 到 kvm.ko 的交互只有一次用户态的切换以及数据拷贝。这个方案对于不同 host 之间的通信,或者 guest 到 host nic 之间的通信是比较好的,但是对于某些用户态进程间的通信,比如数据面的通信方案,openvswitch 和与之类似的 SDN 的解决方案,guest 需要和 host 用户态的 vswitch 进行数据交换,如果采用 vhost_net 的方案,guest 和 host 之间又存在多次的上下文切换和数据拷贝,为了避免这种情况,业界就想出将 vhost_net从内核态移到用户态。这就是 vhost-user 的实现。
4.4.2 vhost-user 的实现
vhost-user 和 vhost_net 的实现原理是一样,都是采用 vring 完成共享内存,eventfd 机制完成事件通知。不同在于 vhost_net 实现在内核中,而 vhost-user 实现在用户空间中,用于用户空间中两个进程之间的通信,其采用共享内存的通信方式。

vhost-user 基于 C/S 的模式,采用 UNIX 域套接字(UNIX domain socket)来完成进程间的事件通知和数据交互,相比 vhost_net 中采用 ioctl 的方式,vhost-user 采用 socket 的方式大大简化了操作。
vhost-user 基于 vring 这套通用的共享内存通信方案,只要 client 和 server 按照 vring 提供的接口实现所需功能即可,常见的实现方案是 client 实现在 guest OS 中,一般是集成在 virtio 驱动上,server 端实现在 qemu 中,也可以实现在各种数据面中,如 OVS,Snabbswitch 等虚拟交换机。
如果使用 qemu 作为 vhost-user 的 server 端实现,在启动 qemu 时,我们需要指定 -mem-path 和 -netdev 参数,如:
$ qemu -m 1024 -mem-path /hugetlbfs,prealloc=on,share=on \
-netdev type=vhost-user,id=net0,file=/path/to/socket \
-device virtio-net-pci,netdev=net0
指定 -mem-path 意味着 qemu 会在 guest OS 的内存中创建一个文件,share=on 选项允许其他进程访问这个文件,也就意味着能访问 guest OS 内存,达到共享内存的目的。
-netdev type=vhost-user 指定通信方案,file=/path/to/socket 指定 socket 文件。
当 qemu 启动之后,首先会进行 vring 的初始化,并通过 socket 建立 C/S 的共享内存区域和事件机制,然后 client 通过 eventfd 将 virtio kick 事件通知到 server 端,server 端同样通过 eventfd 进行响应,完成整个数据交互。

参考链接:
Linux kernel Vhost-net 和 Virtio-net代码详解
Linux kernel Vhost-net 和 Virtio-net代码详解 - allcloud - 博客园