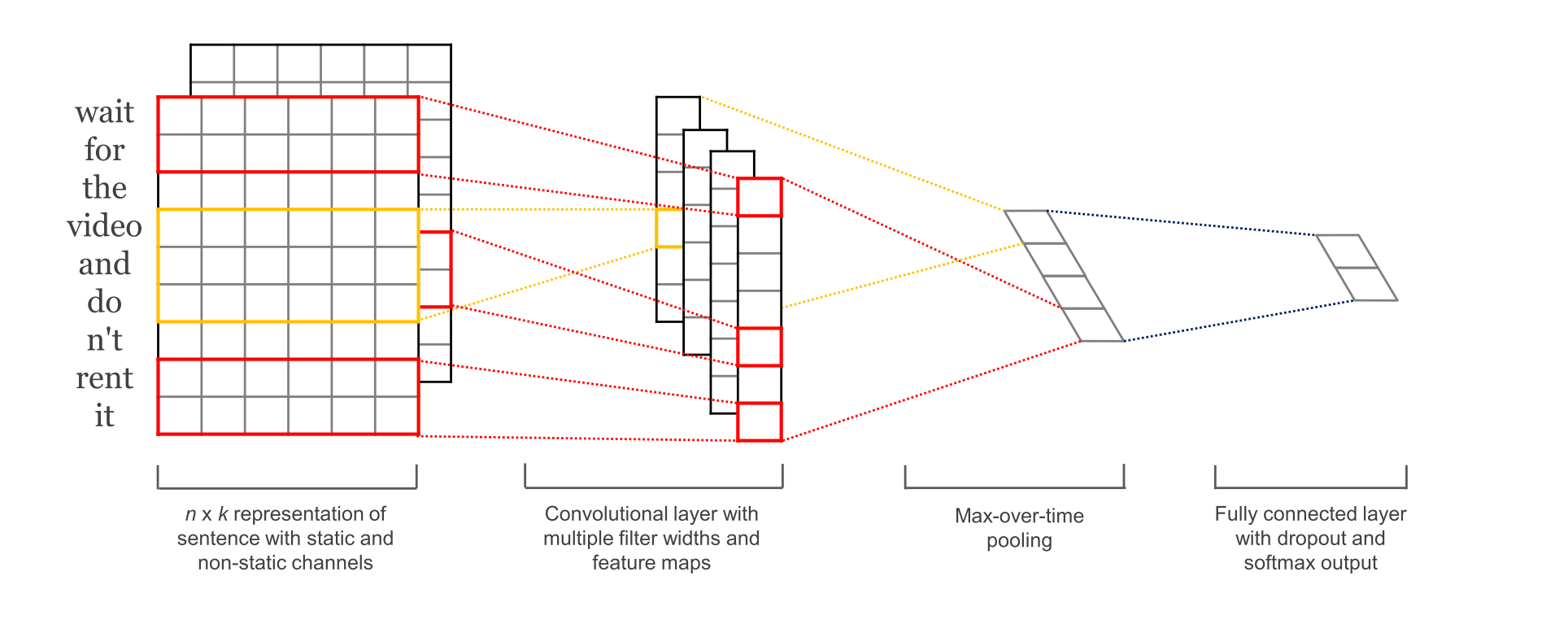
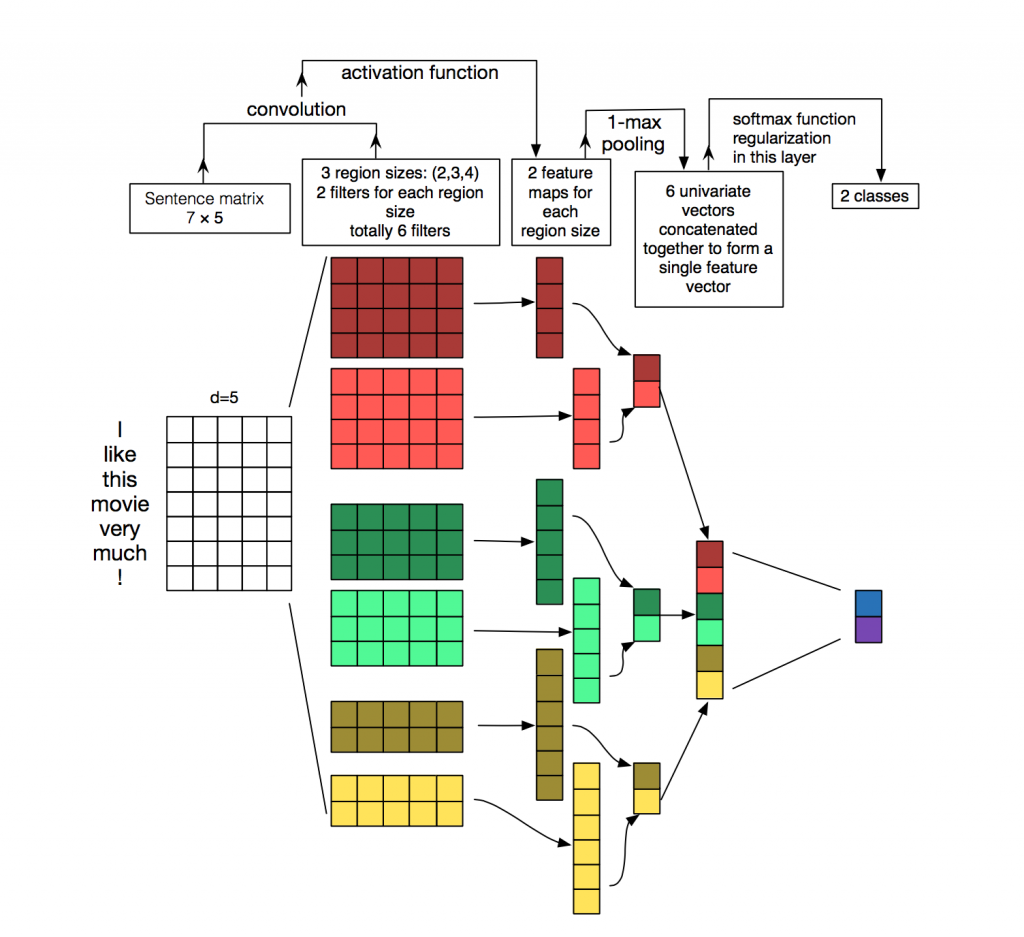
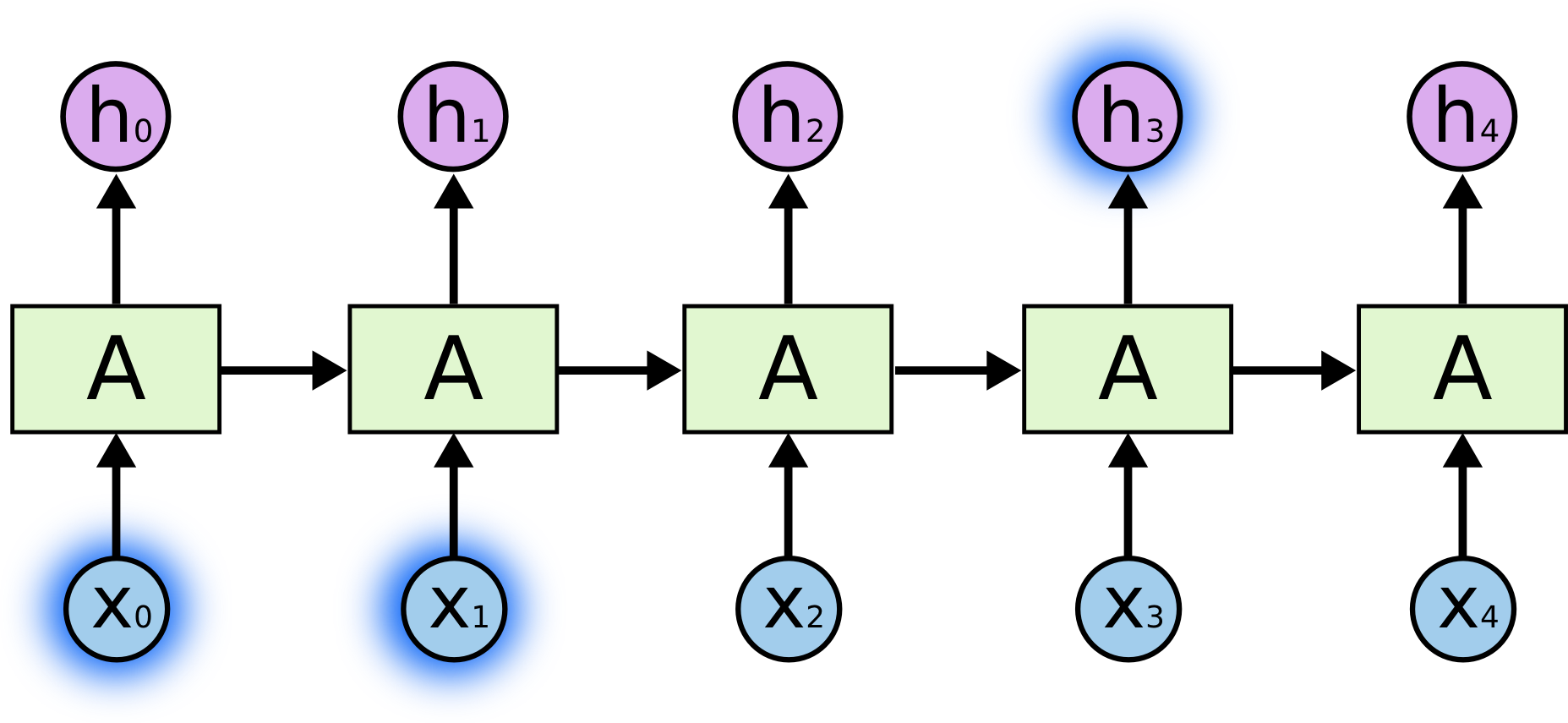
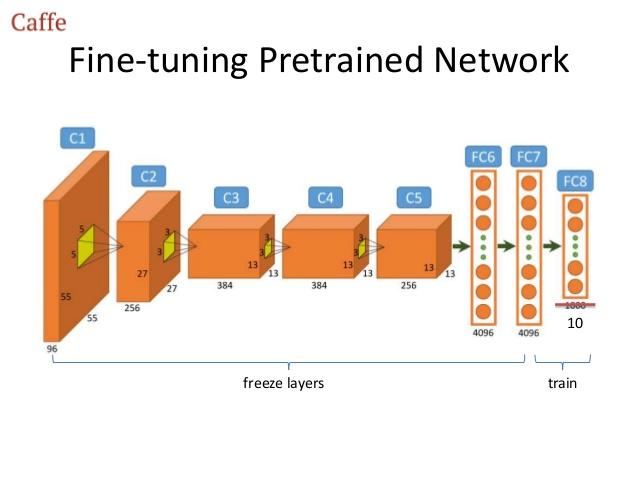
In this tutorial, we will walk you through the process of solving a text classification problem using pre-trained word embeddings and a convolutional neural network.
本文主要以CMU CS 11-747(Neural Networks for NLP)课程中Convolutional Networks for Text这一章节的内容作为主线进行讲解。本文主要包括了对如下几块内容的讲解,第一部分是对于常见的语言模型在进行文本表示时遇到的问题以及引入卷积神经网络的意义,第二部分是对于卷积神经网络模块的介绍,第三部分主要是介绍一些卷积神经网络应用于自然语言处理中的论文,第四部分主要是对这一篇综述进行总结。