一、设置CPU/GPU运行环境:
指定使用CPU:
import tensorflow as tf
tf.debugging.set_log_device_placement (True) # 设置输出运算所在的设备
cpus = tf.config.list_physical_devices ('CPU') # 获取当前设备的 CPU 列表
tf.config.set_visible_devices (cpus) # 设置TensorFlow的可见设备范围为cpu
二、tf定义变量与简单操作
变量。。。
random_float = tf.random.uniform(shape=()) #定义一个随机数(标量)
zero_vector = tf.zeros(shape=(2)) #定义一个有两个元素的零向量
X = tf.constant([[1., 2.], [3., 4.]]) #定义常量
w = tf.Variable(initial_value=[[1.], [2.]]) #定义变量
# 查看/改变矩阵x的形状、类型和值(转化为numpy查看值)
print(X.shape) # 获取tensor的shape,输出(2, 2)
print(X.dtype) # 获取tensor的数据类型,输出<dtype: 'float32'>
print(X.numpy()) # 得到tensor的array形式,输出[[1. 2.][3. 4.]]
ts=tf.constant([1,2,3,4,7,32])
t1 = tf.reshape(ts,[-1,3])) # 改变shape,结果返回新的tensor对象,tf.Tensor([[ 1 2 3] [ 4 7 32]], shape=(2, 3), dtype=int32)
t2 = tf.expand_dims(ts, axis = 1) # 扩张维度,指定的axis维度为1,结果[[1],[2],[3],[4],[7],[32]]
ts_int=tf.convert_to_tensor(10) # 将给定的参数转化为tensor,结果tf.Tensor(10, shape=(), dtype=int32)
eq=tf.math.not_equal([1,1,1,0,0,4], 0) # x,y是否相等情况,返回bool类型的tensor,结果:tf.Tensor([ True True True False False True], shape=(6,), dtype=bool)
cst=tf.cast(eq,dtype=tf.int32) # 将ep中值强制进行类型转换,结果:tf.Tensor([1 1 1 0 0 1], shape=(6,), dtype=int32)
# 简单的矩阵计算
A = tf.constant([[1, 2], [3, 4]])
B = tf.constant([[5, 6], [7, 8]])
print(tf.add(A,B)) #矩阵相加,结果:tf.Tensor([[ 6 8] [10 12]], shape=(2, 2), dtype=int32)
print(tf.matmul(A,B)) #矩阵乘法,结果:tf.Tensor([[19 22] [43 50]], shape=(2, 2), dtype=int32)
print(tf.reduce_sum(A)) #对矩阵所有元素求和,结果:tf.Tensor(10, shape=(), dtype=int32)
concat操作:
两个tensor要concat的那个维度(也就是第二个参数所指的维度)的shape必须一样
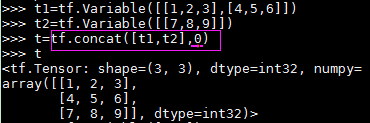
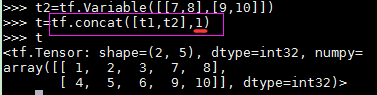
初始化器。。。(利用类对参数初始化)
vr=tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.05, seed=None) #正态分布初始化器
vm=tf.keras.initializers.RandomUniform(minval=-0.05, maxval=0.05, seed=None) #均匀正太分布初始化器
vt=tf.keras.initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None) #截尾正太分布初始化器
vv=tf.random_normal_initializer(mean=0.0, stddev=0.05, seed=None) #正太分布初始化器
vz=tf.zeros_initializer() #生成初始化为0的张量的初始化器。
【基于tf2做数据处理——Tokenizer】
1、使用TF2实现token2id、padding
后续对结果进行词向量转化的话:
生成的结果后面直接跟tf.keras.layer.Embedding()层,
或者
tf.Variable()初始化向量矩阵,使用tf.nn.embedding_lookup(params, ids, max_norm=None, name=None)
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import jieba
vocab_size = 50
oov_tok = '<OOV>'
sequence_length=100
sentense='按我的理解,优化过程的第一步其实就是求梯度。这个过程就是根据输入的损失函数,提取其中的变量,进行梯度下降,使整个损失函数达到最小值。'
sentense_words=[[w for w in jieba.cut(sentense) if w not in [',','。','的']]]
# 对句子中的词生成索引
tokenizer=Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts([sentense_words])
words_index=tokenizer.word_index # 结果类型为dict,{word:word_index}
print('word_index:',words_index)
# 根据词-索引,将各个句子表示成索引向量(即各个词用其索引表示)
X_train_sequences = tokenizer.texts_to_sequences(sentense_words)
print('X_train_sequences:',X_train_sequences)
# 句子进行padding
X_train_sequences_padding=pad_sequences(sequences=X_train_sequences,
maxlen=sequence_length,
padding='post', # pre/post,指定在句子前/后填充
truncating='post', # pre/post,指定在句子前/后截断
value=-1) # 指定填充的值,默认是使用0
print('X_train_sequences_padding:',X_train_sequences_padding)
结果输出如下:

2、基于gensim(版本:3.8.3)
【见我的博客:词向量训练实战——Word2vector、Glove、Doc2vector】
进行token2id,方便后续利用word2vector进行embedding
3、基于keras_bert、bert4keras,对BERT输入tokenizer
【见我的博客:知识图谱三元组抽取——python中模型总结实践】
适用于对bert两个外部输入的生成token_id,segment_id。
三、基于TF2的模型构建
tf2中有两种高级封装——keras和Estimator。也可以使用tf自己定义网络结构包括其中的训练参数???。
【也可以通过继承 tf.keras.layers.Layer 来自定义自己的layer。方式见该自定义的CRF层】
1、基于tf.keras
模型的构建:tf.keras.Model(inputs, outputs, name) 和 tf.keras.layers
tf.keras.Sequential(layers=None, name=None) 和 tf.keras.layers
模型的损失函数: tf.keras.losses
模型的优化器: tf.keras.optimizer5
模型的评估: tf.keras.metrics
(整理、学习ing)
1.1基于tf.keras.Model(inputs, outputs, name)
方法1:通过继承 tf.keras.Model 这个类来定义自己的模型。
:1)在继承类中,我们需要重写 init()(构造函数,初始化)和 call(input)*(模型调用)两个方法。
2)也可以根据需要增加自定义的方法。
示例:构建CNN神经网络(下述代码没有完整验证过)
【对比2维卷积Conv2D:
tf.keras.layers.Conv1D( # 输入是3维向量[batch, seq, emd], 输出也是3维向量[batch, new_seq, filters]
filters, # 卷积核数目,决定输出最后一维度大小(列向量个数),有多少个filters就有多少个列向量
kernel_size, # 卷积核尺寸,其第二维度由 emd 决定
strides=1,
padding='valid',)
】
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D( # 输入是4维向量[batch, row, col, emd], 输出也是4维向量[batch, n_row, n_col, filters]
filters=32, # 卷积层神经元(卷积核)数目,决定输出的最后一维度大小,有多少filters就有多少个[n_row, n_col]矩阵
kernel_size=[5, 5], # 感受野大小(卷积核尺寸,对于NLP任务,一般设置为[filter_size, embedding_size])
padding='same', # padding策略(valid 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], # 池化窗口大小,对于NLP任务,卷积步长为1时,一般设置为[seq_len-filter_size+1, 1]
strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs, training=False): # call中也可以增加一个training参数,对不同过程(训练、测试)进行特殊操作
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
if training:
x = self.dropout(x, training=training)
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
num_epochs = 5
batch_size = 50
learning_rate = 0.001
data_loader = MNISTLoader()
model = CNN()
# 模型训练使用的优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# 模型训练
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
# 模型评估
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model.predict(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
方法2:基于函数API,从输入开始链式构建网络结构
具体如下(上述网络结构可如下定义):
注:①tf.keras.Model()接收的输入层必须是tf.keras.Input(shape)/ tf.keras.layers.Input(shape)等生成的tensor
②第一层没有shape时,输出的模型结构Output Shape都是multiple
③tf.keras.layers.Input()接受输入时,不像其他结构层次可以定义好结构后直接跟(x),该方法可以使用tensor参数,如tf.keras.layers.Input(tensor=my_input),my_input为上一层的输出。示例参见知识图谱中“三元组”抽取——Python中模型总结实战中的第四部分代码。
inputs = tf.keras.Input(shape=(6,28,64)) # [None, 6, 28, 64]
conv1_x = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[2, 2], # 感受野大小
padding='same', # padding策略(valid 或 same)
activation=tf.nn.relu # 激活函数
)(inputs)
pool1_x = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)(conv1_x )
conv2_x = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[2, 2],
padding='same',
activation=tf.nn.relu
)(pool1_x)
pool2_x = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)(conv2_x)
flatten_x = tf.keras.layers.Reshape(target_shape=(1 * 7 * 64,))(pool2_x)
dense1_x = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)(flatten_x)
dense2_x = tf.keras.layers.Dense(units=10)(dense1_x)
model=tf.keras.Model(inputs=inputs, outputs=dense2_x )
print(model.summary())
打印的结果:

1.2基于tf.keras.Sequential( layers=None, name=None)
方法1:以list的方式构建模型层次,将整个list作为tf.keras.Sequential()参数
示例:构建简单的BiLSTM模型
vocab_size=10000
embedding_dim=125
stacked_lstmCell=tf.keras.layers.StackedRNNCells([tf.keras.layers.LSTMCell(embedding_dim) for _ in range(2)])
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=vocab_size, # 字典长度(大小)
output_dim=embedding_dim,
input_length=None, #Length of input sequences,如果该层后面连接flatten并dense则必须指定input_length。
embeddings_initializer='uniform'), # 输入:[batch_size, input_length],输出:[batch_size, input_length, output_dim]。
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(units=embedding_dim), # BiLSTM, units为LSTM每个time_step(sequence_length)输出维度大小;return_sequences=True, 表示return the full sequence,即LSTM中间每一个step神经元计算输出,最终shape[batch, step, lstm_dim]
merge_mode='concat') # merge_mode为双向计算结果的结合方式,可以是'sum', 'mul', 'concat', 'ave', None
# tf.keras.layers.RNN(stacked_lstmCell), # 多层LSTM
tf.keras.layers.Dense(embedding_dim, activation='relu'),
tf.keras.layers.Dense(11, activation='softmax')
])
model.summary()
上述BiLSTM模型结构如下:

多层(2层)LSTM的结构如下:

【上面的LSTM模型,output shape在经过说个time_step(swquence_length)loop之后,变为(time_step,batch_size,hidden_size)】
方法2:先构建tf.keras.Sequential()对象,使用add方法在对象上添加层
(将上述list形式的构建方式进行改写,模型结构完全一致)
vocab_size=10000
embedding_dim=125
model = tf.keras.Sequential()
# 输入:[batch_size, input_length],输出:[batch_size, input_length, output_dim]。
model.add(tf.keras.layers.Embedding(input_dim=vocab_size, #input_dim表明输入的word index最大为vocab_size-1
output_dim=embedding_dim,
input_length=None, #如果该层后面连接flatten并dense则必须指定input_length
embeddings_initializer='uniform'))
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(units=embedding_dim),merge_mode='concat')) # units为LSTM每个time_step(sequence_length)输出维度大小,merge_mode为双向计算结果的结合方式,可以是'sum', 'mul', 'concat', 'ave', None
model.add(tf.keras.layers.Dense(embedding_dim, activation='relu'))
model.add(tf.keras.layers.Dense(11, activation='softmax'))
model.summary()
上述构建的BiLSTM结构如下:

【区别于上述例子中直接调用keras.layers的Embedding层(其输入shape为[batch, seq_len],同tf.nn.embedding_lookup的ids参数),也可以自己定义embedding层,以使用外部训练的向量权重矩阵W:】
import tensorflow as tf
import numpy as np
with tf.name_scope('my_embedding_layer') as scope: #命名空间的使用,当执行后该命名空间中的Tensors W, input_ids, embed, 名字会转变为 my_embedding_layer/W, my_embedding_layer/input_ids, my_embedding_layer/embed
W=tf.Variable([[1,0,0,0,0,0],[0,1,0,0,0,1],[0,0,1,0,0,2],[0,0,0,1,0,3],[0,0,0,0,1,4]])
input_ids=tf.Variable([[0,4,2],[1,0,3]])
embed=tf.nn.embedding_lookup(params=embed_wieght,ids=input_ids)
print(embed)
结果:

2、基于tf.nn
四、基于TF2 的模型训练、测试与保存
1、使用tf.keras中封装好的API
基于API链式构建或者基于tf.keras.Sequential构建的模型,使用基于API的该方法
训练之前要先编译model.compile(),为训练进行配置:
compile(
optimizer='rmsprop',
loss=None, # 'sparse_categorical_crossentropy'
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None, **kwargs
)
然后,model.fit(),训练:
fit(
x=None,
y=None,
batch_size=None, # 不指定时默认32
epochs=1, # 一个epoch就是所有训练数据训练一遍
verbose='auto',
callbacks=None, validation_split=0.0, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None,
validation_steps=None, validation_batch_size=None, validation_freq=1,
max_queue_size=10, workers=1, use_multiprocessing=False
)
然后,model.predict(),预测:
predict( # 返回numpy array
x, # A Numpy array (or array-like), or a list of arrays;A TensorFlow tensor, or a list of tensors,。。。
batch_size=None,
verbose=0, steps=None, callbacks=None, max_queue_size=10,
workers=1, use_multiprocessing=False
)
最后保存model.save()or加载:
from keras.models import load_model
model.save(
'my_model.h5', # 可以保存为Tensorflow SavedModel or a single HDF5 file
overwrite=True, include_optimizer=True, save_format=None,
signatures=None, options=None, save_traces=True
)
# returns a compiled model,identical to the previous one
model = load_model('my_model.h5')
2、使用自定义的训练过程:自定义每个batch的循环过程
继承tf.keras.Model类定义的模型需要使用该方法,model(x)传数据
1、loss函数
注意:Sparse前缀的loss函数,其中的label(或y_true)都是label本身,非one-hot编码。
1)tf.keras定义损失函数:
tf.keras.metrics.sparse_categorical_crossentropy(
y_true, y_pred, from_logits=False, axis=-1
)
使用:
y_true = [1, 2]
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
loss_m = tf.keras.metrics.sparse_categorical_crossentropy(y_true, y_pred)
loss_l = tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred)
print('loss_m:',loss_m)
print('loss_l:',loss_l)
print('loss_m_mean:',tf.reduce_mean(loss_m)) # argmax()、reduce_mean()都在tf.math.中,使用时也可以省略math
结果:

另:
tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=False, reduction=losses_utils.ReductionV2.AUTO, #tf.keras.losses.Reduction.SUM
name='sparse_categorical_crossentropy'
)
使用
说明:
①Use this crossentropy loss function when there are two or more label classes. We expect labels to be provided as integers. If you want to provide labels using one-hot representation, please use CategoricalCrossentropy loss. There should be # classes floating point values per feature for y_pred and a single floating point value per feature for y_true.
②The shape of y_true is [batch_size] and the shape of y_pred is [batch_size, num_classes].
③return:损失值,float
y_true = [1, 2] # 使用label编码,不可以one-hot形式
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
# Using 'auto'/'sum_over_batch_size' reduction type.
scce = tf.keras.losses.SparseCategoricalCrossentropy()
scce(y_true, y_pred).numpy()
2)tf.nn定义损失函数:
tf.nn.softmax_cross_entropy_with_logits(
labels, logits, axis=-1, name=None
)
使用:
说明:
①A common use case is to have logits and labels of shape [batch_size, num_classes], but higher dimensions are supported, with the axis argument specifying the class dimension.
②logits and labels must have the same dtype (either float16, float32, or float64).
③return:A Tensor that contains the softmax cross entropy loss. Its type is the same as logits and its shape is the same as labels except that it does not have the last dimension of labels.
logits = [[4.0, 2.0, 1.0], [0.0, 5.0, 1.0]]
labels = [[1.0, 0.0, 0.0], [0.0, 0.8, 0.2]]
losses=tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits)
lose=tf.reduce_mean(losses)
2、优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# 模型训练
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
for batch_index in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f" % (batch_index, loss.numpy()))
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
五、keras_bert
1、模型加载
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
bert_model = load_trained_model_from_checkpoint(config_path,
check_point_path,
seq_len=seq_len,
output_layer_num=self.layer_nums,
training=self.training,
trainable=self.trainable)
self._model = tf.keras.Model(bert_model.inputs, bert_model.output)
2、模型输入
bert模型的输入包括词向量,段向量和位置向量。
(注意模型的输入:当training为False时输入只包含前两项。一般词向量输入词索引,段向量一般是0向量,位置向量对应位置下标由于是固定的,会在模型内部生成,不需要手动再输入一遍)
bert_model.predict() # 当
六、TensorFlow2.x的常见异常
1、TensorFlow版本与numpy版本不兼容报错
异常信息:NotImplementedError: Cannot convert a symbolic Tensor (ner_model/bidirectional/forward_lstm/strided_slice:0) to a numpy array. This error may indicate that you're trying to pass a Tensor to a NumPy call, which is not supported
处理:本人python3.8,TensorFlow为2.3、2.4或2.5时,numpy降到1.19.x(1.18.x也行)
使用tensorflow2_0和LSTM的文本多分类2https://github.com/tongzm/ml-python/blob/master
tf2.0中国社区:https://tf.wiki/
谷歌TensorFlow2官网:https://tensorflow.google.cn/api_docs/python/tf/keras