前言:上次分享了单向链表的增删查改,这次要介绍双向链表的增删查改,其实双向链表也有多种,这次主要介绍结构最复杂但是实现起功能反而最简单的带头双向循环链表,希望我的分享对各位有些许帮助。学习这篇文章的内容最好有这篇文章的基础
目录
一:双向链表的简单介绍
(1) 概述
(2) 图示 (带头双向循环链表)
二:用带头双向循环链表实现简单的增删查改
(1) 大致框架
(2) 四大基本功能函数的实现
1. 创建哨兵位头节点
2. 创建新节点
3. 打印链表
4. 销毁链表
(3) 尾插尾删的实现
1. 尾插
2. 尾删
(3) 头插头删的实现
1. 头插
2. 头删
(4) 特定位置的插入与删除
1. 特定位置的寻找
2. 特定位置的插入
3. 特定位置的删除
三:完整代码及测试样例的展示
(1) Test.c
(2) List.h
(3) List.c
(4) 测试样例的展示
一:双向链表的简单介绍
双向链表的种类有多种——不带头,带头,循环,非循环等等,这里我们主要介绍最复杂的带头双向循环链表:结构最复杂,有一个存储无效数据的哨兵位头节点,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向 循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们函数功能的实现可以很好地体现。
而双向链表与单向链表最本质的区别就是: 单向链表只有一个指针域,而双向链表有两个指针域,所以双向链表可以灵活的找到一个节点的左右节点,使得相对于单向链表而言有很大的优势。

二:用带头双向循环链表实现简单的增删查改
(1) 大致框架

Test.c——用于测试接口函数的功能
#define _CRT_SECURE_NO_WARNINGS
#include "List.h"
void Test1()//测试尾插尾删
{
}
void Test2()//测试头插头删
{
}
void Test3()//测试特定位置的插入与删除
{
}
int main()
{
Test1();//测试尾插尾删
//Test2();//测试头插头删
//Test3();//测试特定位置的插入与删除
return 0;
}
List.h——用于各种定义
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//将int重定义为LTDataType,方便链表数据类型的更改(eg:int->double)
typedef int LTDataType;
//定义一个带头双向循环链表
typedef struct ListNode
{
LTDataType data;//数据域
struct ListNode* prev;//可以链接前一个节点的指针域
struct ListNode* next;//可以链接后一个节点的指针域
} LTNode;
LTNode* ListInit();//创建哨兵位头节点
void ListPrint(LTNode* phead);//打印
LTNode* BuyListNode(LTDataType x);//创建新节点
void ListDestroy(LTNode* phead);//销毁链表
void ListPushBack(LTNode* phead, LTDataType x);//尾插
void ListPopBack(LTNode* phead);//尾删
void ListPushFront(LTNode* phead, LTDataType x);//头插
void ListPopFront(LTNode* phead);//头删
LTNode* ListNodeFind(LTNode* phead, LTDataType x);//找到链表中数据为x的第一个节点
void ListInsertNode(LTNode* pos, LTDataType x);//在pos节点前插入节点
void ListEraseNode(LTNode* pos);//删除pos节点
List.c——用于接口函数功能的实现
#define _CRT_SECURE_NO_WARNINGS
#include "List.h"
LTNode* ListInit()//创建哨兵位头节点
{
}
void ListPrint(LTNode* phead)//打印
{
}
LTNode* BuyListNode(LTDataType x)//创建新节点
{
}
void ListPushBack(LTNode* phead, LTDataType x)//尾插
{
}
void ListPopBack(LTNode* phead)//尾删
{
}
void ListPushFront(LTNode* phead, LTDataType x)//头插
{
}
void ListPopFront(LTNode* phead)//头删
{
}
LTNode* ListNodeFind(LTNode* phead, LTDataType x)//找到链表中数据为x的第一个节点
{
}
void ListInsertNode(LTNode* pos, LTDataType x)//在pos节点前插入节点
{
}
void ListEraseNode(LTNode* pos)//删除pos节点
{
}
void ListDestroy(LTNode* phead)//销毁链表
{
}
(2) 四大基本功能函数的实现
1. 创建哨兵位头节点
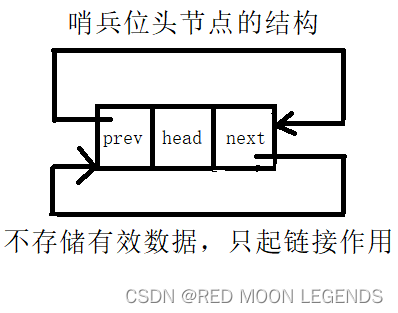
对于带头双向循环链表而言,哨兵位头节点起到了至关重要的作用,所以实现带头双向循环链表的第一步就是创建一个哨兵位头节点:
LTNode* ListInit()//创建哨兵位头节点
{
LTNode* tmp = (LTNode*)malloc(sizeof(LTNode));
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
LTNode* phead = tmp;
phead->next = phead;
phead->prev = phead;
return phead;//返回开辟的头节点
}
带头双向循环链表中头节点的实际结构:
2. 创建新节点
从之前分享的单链表增删查改的知识也可以很清楚的知道,在插入节点之前要先创建一个新节点,所以为了方便创建节点,直接分装在一个函数中实现即可:
LTNode* BuyListNode(LTDataType x)//创建新节点
{
LTNode* tmp = (LTNode*)malloc(sizeof(LTNode));
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
LTNode* newnode = tmp;
newnode->next = NULL;
newnode->prev = NULL;
newnode->data = x;//数据域为新节点的有效数据x
return newnode;
}
3. 打印链表
跟单链表思路相似,遍历链表即可,不同的是二者的终止条件不同,由于这是循环链表,所以链表的终点不是NULL:
void ListPrint(LTNode* phead)//打印链表
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)//带头双向循环链表遍历一遍后会回到哨兵位头节点
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
4. 销毁链表
与打印的思路相同,遍历链表的过程中不断释放节点,回到头节点即可,这里需要特别注意的是:哨兵位头节点也是动态开辟出来的,所以也要进行释放并置空,而为了维持函数接口传递参数的一致性,该函数接口传递的是表示哨兵位头节点的一级指针,此时形参只是实参的一份临时拷贝,在函数内部改变无法引起其变化,所以哨兵位头节点的置空要在哨兵位头节点所在的作用域函数内实现。
void ListDestroy(LTNode* phead)//销毁链表————遍历即可
{
assert(phead);
LTNode* cur = phead->next;
while (cur->next != phead)
{
LTNode* curNext = cur->next;
free(cur);
cur = curNext;
phead->next = cur;
cur->prev = phead;
}
free(phead);
}

(3) 尾插尾删的实现
1. 尾插
void ListPushBack(LTNode* phead, LTDataType x)//尾插
{
assert(phead);
//1.常规思路———利用结构的特殊,直接形成链接关系即可
LTNode* newnode = BuyListNode(x);
LTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
phead->prev = newnode;
newnode->next = phead;
//2.调用函数ListInsertNode,简化尾插
}
2. 尾删
void ListPopBack(LTNode* phead)//尾删
{
assert(phead);
assert(phead->next != phead);
//1.常规思路————记录尾节点的前一个节点,把前一个结点当作新的尾节点,释放旧的尾节点
LTNode* tail = phead->prev;
LTNode* tailPrev = tail->prev;
phead->prev = tailPrev;
tailPrev->next = phead;
free(tail);
tail = NULL;
//2.调用函数ListEraseNode,简化尾删
}
(3) 头插头删的实现
1. 头插
void ListPushFront(LTNode* phead,LTDataType x)//头插
{
assert(phead);
//1.常规思路————要知道链表真正的起点是哨兵位头节点的后一个节点
LTNode* newnode = BuyListNode(x);
LTNode* next = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next = next;
next->prev = newnode;
//2.调用函数ListInsertNode,简化尾删
}
2. 头删
void ListPopFront(LTNode* phead)//头删
{
assert(phead);
assert(phead->next != phead);//删除前一定要判空,即不能删除哨兵位头节点
//1.常规思路
LTNode* cur = phead->next;
LTNode* next = phead->next->next;
free(cur);
phead->next = next;
next->prev = phead;
//2.调用函数ListEraseNode,简化头删
}
(4) 特定位置的插入与删除
1. 特定位置的寻找
LTNode* ListNodeFind(LTNode* phead, LTDataType x)//找到链表中数据为x的第一个节点并返回
{
assert(phead);
LTNode* cur = phead->next;
while (cur->next != phead)//遍历寻找
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
2. 特定位置的插入
//在pos节点前插入节点,pos节点是调用ListNodeFind函数得到的
void ListInsertNode(LTNode* pos, LTDataType x)
{
LTNode* newnode = BuyListNode(x);//得到一个新节点
//简单的链接过程
LTNode* posPrev = pos->prev;
posPrev->next = newnode;
newnode->prev = posPrev;
newnode->next = pos;
pos->prev = newnode;
}
3. 特定位置的删除
void ListEraseNode(LTNode* pos)//删除pos节点
{
//删除pos节点需要知道pos节点的前一个节点与后一个节点,这样才能在删除后重新形成链接关系
LTNode* posPrev = pos->prev;
LTNode* posNext = pos->next;
posPrev->next = posNext;
posNext->prev = posPrev;
free(pos);
}
注意:对于带头双向循环链表而言,这三个接口函数的实现很重要,其实只要掌握了这三个解控函数,就可以很快的构建起一个带头双向循环链表,因为插入与删除的相关接口函数直接调用这三个函数就能够实现:
//复用两个接口函数实现这些相关函数最重要的一点是真正理解带头双向循环链表的结构(上面那张图很重要)
void ListPushBack(LTNode* phead, LTDataType x)//尾插
{
assert(phead);
//1.常规思路
//2.调用函数ListInsertNode,简化尾插
ListInsertNode(phead, x);//在哨兵位头节点前面插入就可以实现尾插
}
void ListPopBack(LTNode* phead)//尾删
{
assert(phead);
assert(phead->next != phead);
//1.常规思路
//2.调用函数ListEraseNode,简化尾删
ListEraseNode(phead->prev);//删除哨兵位头节点的前一个节点可以实现尾删
}
void ListPushFront(LTNode* phead, LTDataType x)//头插
{
assert(phead);
//1.常规思路
//2.调用函数ListInsertNode,简化尾删
ListInsertNode(phead->next, x);//在哨兵位头节点后面插入就可以实现头插
}
void ListPopFront(LTNode* phead)//头删
{
assert(phead);
assert(phead->next != phead);
//1.常规思路
//2.调用函数ListEraseNode,简化头删
ListEraseNode(phead->next);//删除哨兵位头节点的后一个节点可以实现尾删
}
三:完整代码及测试样例的展示
(1) Test.c
#define _CRT_SECURE_NO_WARNINGS
#include "List.h"
void Test1()//测试尾插尾删
{
LTNode* phead = ListInit();//哨兵位头节点
ListPushBack(phead, 1);
ListPushBack(phead, 2);
ListPushBack(phead, 3);
ListPushBack(phead, 4);
ListPushBack(phead, 5);
ListPrint(phead);
ListPopBack(phead);
ListPopBack(phead);
ListPopBack(phead);
ListPrint(phead);
ListDestroy(phead);
phead = NULL;
}
void Test2()//测试头插头删
{
LTNode* phead = ListInit();//哨兵位头节点
ListPushFront(phead, 1);
ListPushFront(phead, 2);
ListPushFront(phead, 3);
ListPushFront(phead, 4);
ListPushFront(phead, 5);
ListPrint(phead);
ListPopFront(phead);
ListPopFront(phead);
ListPopFront(phead);
ListPrint(phead);
ListDestroy(phead);
phead = NULL;
}
void Test3()//测试特定位置的插入与删除
{
LTNode* phead = ListInit();//哨兵位头节点
ListPushBack(phead, 1);
ListPushBack(phead, 2);
ListPushFront(phead, 3);
ListPushFront(phead, 4);
ListPushFront(phead, 5);
ListPrint(phead);
LTNode* pos = ListNodeFind(phead, 1);
if (pos)
{
ListInsertNode(pos, 6);
}
ListPrint(phead);
pos = ListNodeFind(phead, 3);
if (pos)
{
ListInsertNode(pos, 7);
}
ListPrint(phead);
pos = ListNodeFind(phead, 5);
if (pos)
{
ListEraseNode(pos);
}
ListPrint(phead);
pos = ListNodeFind(phead, 4);
if (pos)
{
ListEraseNode(pos);
}
ListPrint(phead);
ListDestroy(phead);
phead = NULL;
}
int main()
{
//Test1();//测试尾插尾删
//Test2();//测试头插头删
Test3();//测试特定位置的插入与删除
return 0;
}
(2) List.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
//将int重定义为LTDataType,方便链表数据类型的更改(eg:int->double)
typedef int LTDataType;
//定义一个带头双向循环链表
typedef struct ListNode
{
LTDataType data;//数据域
struct ListNode* prev;//可以链接前一个节点的指针域
struct ListNode* next;//可以链接后一个节点的指针域
} LTNode;
LTNode* ListInit();//创建哨兵位头节点
void ListPrint(LTNode* phead);//打印
LTNode* BuyListNode(LTDataType x);//创建新节点
void ListDestroy(LTNode* phead);//销毁链表
void ListPushBack(LTNode* phead, LTDataType x);//尾插
void ListPopBack(LTNode* phead);//尾删
void ListPushFront(LTNode* phead, LTDataType x);//头插
void ListPopFront(LTNode* phead);//头删
LTNode* ListNodeFind(LTNode* phead, LTDataType x);//找到链表中数据为x的第一个节点
void ListInsertNode(LTNode* pos, LTDataType x);//在pos节点前插入节点
void ListEraseNode(LTNode* pos);//删除pos节点
(3) List.c
#define _CRT_SECURE_NO_WARNINGS
#include "List.h"
LTNode* ListInit()//1.创建哨兵位头节点
{
LTNode* tmp = (LTNode*)malloc(sizeof(LTNode));
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
LTNode* phead = tmp;
phead->next = phead;
phead->prev = phead;
return phead;//返回开辟的头节点
}
LTNode* BuyListNode(LTDataType x)//2.创建新节点
{
LTNode* tmp = (LTNode*)malloc(sizeof(LTNode));
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
LTNode* newnode = tmp;
newnode->next = NULL;
newnode->prev = NULL;
newnode->data = x;//数据域为新节点的有效数据x
return newnode;
}
void ListPrint(LTNode* phead)//3.打印链表
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)//带头双向循环链表遍历一遍后会回到哨兵位头节点
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
void ListPushBack(LTNode* phead, LTDataType x)//4.尾插
{
assert(phead);
//1.常规思路
LTNode* newnode = BuyListNode(x);
LTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
phead->prev = newnode;
newnode->next = phead;
//2.调用函数ListInsertNode,简化尾插
//ListInsertNode(phead, x);//在哨兵位头节点前面插入就可以实现尾插
}
void ListPopBack(LTNode* phead)//5.尾删
{
assert(phead);
assert(phead->next != phead);
//1.常规思路
LTNode* tail = phead->prev;
LTNode* tailPrev = tail->prev;
phead->prev = tailPrev;
tailPrev->next = phead;
free(tail);
tail = NULL;
//2.调用函数ListEraseNode,简化尾删
//ListEraseNode(phead->prev);
}
void ListPushFront(LTNode* phead,LTDataType x)//6.头插
{
assert(phead);
//1.常规思路
LTNode* newnode = BuyListNode(x);
LTNode* next = phead->next;
phead->next = newnode;
newnode->prev = phead;
newnode->next = next;
next->prev = newnode;
//2.调用函数ListInsertNode,简化尾删
//ListInsertNode(phead->next, x);
}
void ListPopFront(LTNode* phead)//7.头删
{
assert(phead);
assert(phead->next != phead);
//1.常规思路
LTNode* cur = phead->next;
LTNode* next = phead->next->next;
free(cur);
phead->next = next;
next->prev = phead;
//2.调用函数ListEraseNode,简化头删
//ListEraseNode(phead->next);
}
LTNode* ListNodeFind(LTNode* phead, LTDataType x)//8.找到链表中数据为x的第一个节点并返回
{
assert(phead);
LTNode* cur = phead->next;
while (cur->next != phead)//遍历寻找
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
void ListInsertNode(LTNode* pos, LTDataType x)//9.在pos节点前插入节点,pos节点是调用ListNodeFind函数得到的
{
LTNode* newnode = BuyListNode(x);
LTNode* posPrev = pos->prev;
posPrev->next = newnode;
newnode->prev = posPrev;
newnode->next = pos;
pos->prev = newnode;
}
void ListEraseNode(LTNode* pos)//10.删除pos节点
{
LTNode* posPrev = pos->prev;
LTNode* posNext = pos->next;
posPrev->next = posNext;
posNext->prev = posPrev;
free(pos);
}
void ListDestroy(LTNode* phead)//11.销毁链表————遍历即可
{
assert(phead);
LTNode* cur = phead->next;
while (cur->next != phead)
{
LTNode* curNext = cur->next;
free(cur);
cur = curNext;
phead->next = cur;
cur->prev = phead;
}
free(phead);
}
(4) 测试样例的展示

总结:
虽然带头双向循环链表的结构比单向链表复杂很多,但是它对功能实现的难易程度以及自身的价值都优于单链表,所以大家在掌握单链表的同时也要掌握好双向链表,再次提醒各位,结构十分重要,结构又可以在图示中很好的体现出来,所以各位在数据结构的学习过程中一定要重视画图以及理解所化的图。就这样,我又分享了一次自己在学习道路上的理解,希望对各位有所帮助,再见。
