关键词:反向传播(BP);caffe源码;im2col;卷积;反卷积;上池化;上采样
公式推导
以前看到一长串的推导公式就想直接跳过,今天上午莫名有耐心,把书上的公式每一步推导自己算一遍,感觉豁然开朗。遂为此记。

sigmoid函数求导比relu复杂一点。如果采用relu,神经元输入和输出的导数就为1,计算更方便。
因为更新的原则是朝着损失降低最快的方向更新,可以把w看成是自变量,系数的计算就是反向传播的过程,系数越大,降低越快。
Caffe 源码解读
前向传播源码:
//前向传播
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
//blobs_[0]保存权值, blobs_[1]保存偏置
const Dtype* weight = this->blobs_[0]->cpu_data();
//bottom.size()是bottom中blob的数量,等于top中blob的数量,一般情况下为1
for (int i = 0; i < bottom.size(); ++i) {
//获取输入,输出数据指针
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
//第n张图片
for (int n = 0; n < this->num_; ++n) {
//卷积操作,采用矩阵乘积实现
// bottom_dim_ =3*28*28
// kernel = 20*5*5
// top_dim_ = 20*24*24
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
//加上偏置
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
反向传播源码:
//反向传播
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down/*是否反传*/, const vector<Blob<Dtype>*>& bottom) {
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
for (int i = 0; i < top.size(); ++i) {
//上一层传下来的导数
const Dtype* top_diff = top[i]->cpu_diff();
const Dtype* bottom_data = bottom[i]->cpu_data();
//传给下一层的导数
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();
// Bias gradient, if necessary.
// 更新偏置,直接加上残差(每个偏置所对应的图内所有残差之和)
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
}
}
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// gradient w.r.t. weight. Note that we will accumulate diffs.
// 对weight 计算导数(用来更新weight)
// /将下一层残差与weight进行相关计算,得到卷积层的残差
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
}
// gradient w.r.t. bottom data, if necessary.
// 对bottom数据计算导数(传给下一层)
// bottom_data与top_diff做相关计算,得到w权值更新量
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_);
}
}
}
}
}
所以也就更好理解为什么
bottom_data * top_diff = weight_diff
top_diff * weight = bottom_diff
真实的过程应该是一个不断的循环
bottom_data * top_diff = weight_diff(用于更新当前层的权值)
top_diff * weight = bottom_diff (传递到下一层)
(上一层的bottom_diff 是下一层的top_diff )
bottom_data * top_diff = weight_diff (用于更新当前层的权值)
top_diff * weight = bottom_diff(继续传递到下一层)
关于提升卷积速度(im2col)

卷积核横向展开为1行

将多个通道应用卷积核的相同位置区域(3维数据)纵向展开为一列
案例1: 前向传播
 kernel size:20 * 5 * 5
kernel size:20 * 5 * 5
input blob:1 * 28 * 28
output blob:20 * 24 * 24(576)

kernel size:50 * 5 * 5
input blob:20 * 12 * 12
output blob:50 * 8 * 8
参考链接
案例2(前向传播、计算bottom_diff、计算weight_diff):

核心思想:
将卷积核展开成行。
将不同图片相同位置的卷积区域提取成列。
定格位置的数目即输出特征图像的大小。
反向传播过程中pad的问题
假设输入特征图 m * m,输出特征图 n * n
卷积过程pad(p) ,stride(s) =1 ,kernel (k)
n = (m+2p-k)/ s +1
m - n = k -1-2p
若 p = (k-1)/ 2,m = n
若 p != (k-1)/ 2,要考虑补边。
卷积与反卷积
卷积过程:
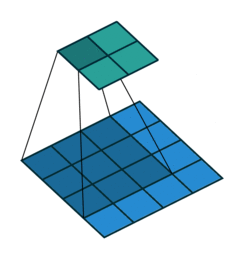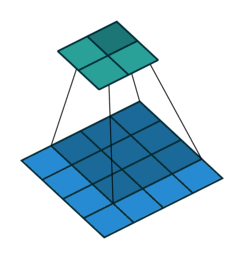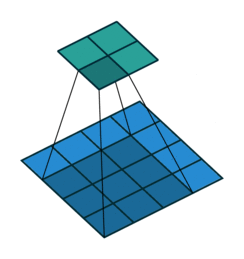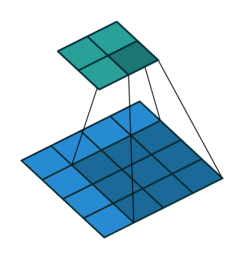
反卷积过程:
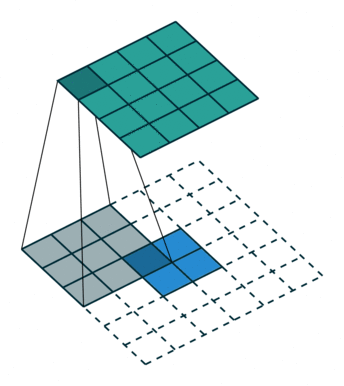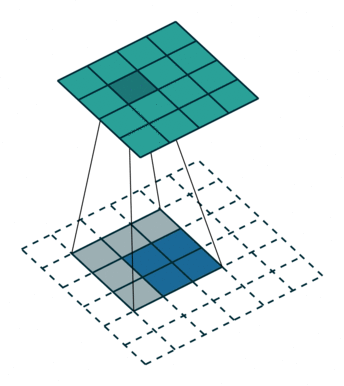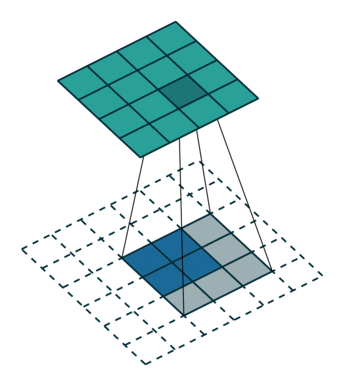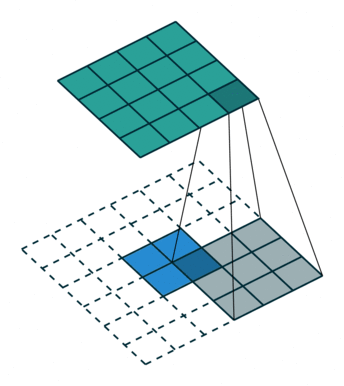
卷积 | 反向传播 | 反卷积 | 导向反向传播 | 的区别

- 反向传播要记录先前输入大于0的位置,反卷积只考虑梯度
- 反卷积的参数需要学习,反向传播用的是既有参数。
上池化 | 上采样 | 反卷积 | 的区别
上池化(UnPooling)、上采样(UnSampling)、反卷积(Deconvolution)

图(a)表示UnPooling的过程,特点是在Maxpooling的时候保留最大值的位置信息,之后在unPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。
与之相对的是图(b),两者的区别在于UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充FeatureMap。从图中即可看到两者结果的不同。
图(c)为反卷积的过程,反卷积是卷积的逆过程,又称作转置卷积。最大的区别在于反卷积过程是有参数要进行学习的(类似卷积过程),理论是反卷积可以实现UnPooling和unSampling,只要卷积核的参数设置的合理。
backward propagation:记录输入大于0的位置
unpooling:记录最大值信息(如果池化采用的是平均池化,那么UnPooling和unSampling类似)
参考链接