爬虫 第五讲 多线程爬虫
一、多线程
1.多线程基本介绍
有很多的生活场景中的事情是同时进行的,比如一边做饭,一边跟别人聊天,一边听歌。
示例1
import time
def sing():
for i in range(3):
print("正在唱歌...%d" % i)
time.sleep(1)
def dance():
for i in range(3):
print("正在跳舞...%d" % i)
time.sleep(1)
if __name__ == '__main__':
sing()
dance()
'''
正在唱歌...0
正在唱歌...1
正在唱歌...2
正在跳舞...0
正在跳舞...1
正在跳舞...2
'''
示例2
import time
import threading
def sing():
for i in range(3):
print("正在唱歌...%d" % i)
time.sleep(1)
def dance():
for i in range(3):
print("正在跳舞...%d" % i)
time.sleep(1)
if __name__ == '__main__':
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
'''
正在唱歌...0
正在跳舞...0
正在唱歌...1
正在跳舞...1
正在唱歌...2
正在跳舞...2
'''
2.主线程和子线程的执行关系
主线程会等待子线程结束之后在结束
import threading
import time
def demo():
for i in range(5):
print('hello 子线程') # 子线程
time.sleep(1)
if __name__ == '__main__':
# 参数1 group 线程组 None
# 参数2 target 要执行的方法
# 参数3 name 线程名
t = threading.Thread(target=demo)
# 主线程会等待子线程结束之后再结束
t.start() # 创建并开启线程
print(1)
'''
hello 子线程
1
hello 子线程
hello 子线程
hello 子线程
hello 子线程'''
join() 等待子线程结束之后,主线程继续执行
import threading
import time
def demo():
for i in range(5):
print('hello 子线程') # 子线程
time.sleep(1)
if __name__ == '__main__':
# 参数1 group 线程组 None
# 参数2 target 要执行的方法
# 参数3 name 线程名
t = threading.Thread(target=demo)
# 主线程会等待子线程结束之后再结束
t.start() # 开启线程
# 等待子进程结束之后,主线程再继续执行
t.join()
print(1)
'''
hello 子线程
hello 子线程
hello 子线程
hello 子线程
hello 子线程
1
'''
setDaemon() 守护线程,不会等待子线程结束
import threading
import time
def demo():
for i in range(5):
print('hello 子线程') # 子线程
time.sleep(1)
if __name__ == '__main__':
# 参数1 group 线程组 None
# 参数2 target 要执行的方法
# 参数3 name 线程名
t = threading.Thread(target=demo)
# 守护线程,不会等待子线程结束
t.setDaemon(True)
# 主线程会等待子线程结束之后再结束
t.start() # 开启线程
print(1)
'''hello 子线程1'''
import threading
import time
def run(num):
print("子线程(%s)开始" % (threading.current_thread().name))
# 实现线程的功能
time.sleep(2)
print("打印", num)
time.sleep(2)
print("子线程(%s)结束" % (threading.current_thread().name))
if __name__ == "__main__":
# 任何进程默认就会启动一个线程,称为主线程,主线程可以启动新的子线程
# 打印当前线程的名称,current_thread():返回当前线程的实例
print("主线程(%s)启动" % (threading.current_thread().name))
# t.start()创建并启动子线程
t = threading.Thread(target=run, name="runThread", args=(1,)) # 如果不写 name="runThread",(Thread-1)排下去
t.start()
t.join() # 等待线程结束
print("主线程(%s)结束" % (threading.current_thread().name))
'''
主线程(MainThread)启动
子线程(runThread)开始
打印 1
子线程(runThread)结束
主线程(MainThread)结束'''
import threading
import time
def demo():
# 子线程
print("hello man")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=demo)
t.start()
'''
hello man
hello man
hello man
hello man
hello man'''
3.查看线程数量
threading.enumerate() 查看当前线程的数量
# threading.enumerate 列出活着的线程
import time
import threading
def demo1():
for i in range(5):
print('demo1-----%d' % i)
time.sleep(1)
def demo2():
for i in range(10):
print('demo2-----%d' % i)
time.sleep(1)
def main():
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
t2.start()
while True:
print(threading.enumerate())
if len(threading.enumerate()) <=1:
break
time.sleep(1)
if __name__ == '__main__':
main()
'''
demo1-----0
demo2-----0[<_MainThread(MainThread, started 11424)>, <Thread(Thread-1, started 11504)>, <Thread(Thread-2, started 11204)>]
demo1-----1
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-1, started 11504)>, <Thread(Thread-2, started 11204)>]
demo2-----1
demo1-----2
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-1, started 11504)>, <Thread(Thread-2, started 11204)>]
demo2-----2
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-1, started 11504)>, <Thread(Thread-2, started 11204)>]
demo2-----3
demo1-----3
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-1, started 11504)>, <Thread(Thread-2, started 11204)>]demo2-----4
demo1-----4
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-2, started 11204)>]
demo2-----5
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-2, started 11204)>]demo2-----6
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-2, started 11204)>]
demo2-----7
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-2, started 11204)>]
demo2-----8
demo2-----9[<_MainThread(MainThread, started 11424)>, <Thread(Thread-2, started 11204)>]
[<_MainThread(MainThread, started 11424)>, <Thread(Thread-2, started 11204)>]
[<_MainThread(MainThread, started 11424)>]
'''
4.验证子线程的执行与创建
当调用Thread的时候,不会创建线程。
当调用Thread创建出来的实例对象的start方法的时候,才会创建线程以及开始运行这个线程。
import threading
import time
def demo():
for i in range(5):
print('demo-----%d'%i)
time.sleep(1)
def main():
print(threading.enumerate()) # 一个主线程
t1 = threading.Thread(target=demo) # 创建? 证明它不是创建线程
print(threading.enumerate()) # 一个主线程
t1.start() # 创建线程并启动线程
print(threading.enumerate()) # 有2个线程,一个是主线程,一个是子线程
if __name__ == '__main__':
main()
'''
[<_MainThread(MainThread, started 21084)>]
[<_MainThread(MainThread, started 21084)>]
demo-----0[<_MainThread(MainThread, started 21084)>, <Thread(Thread-1, started 11688)>]
demo-----1
demo-----2
demo-----3
demo-----4'''
5.继承Thread类创建线程
示例1
import threading
import time
class A(threading.Thread):
def __init__(self, name):
super().__init__(name=name)
def run(self):
for i in range(5):
print(i)
if __name__ == "__main__":
t = A('test_name')
t.start()
'''
0
1
2
3
4'''
示例2
import threading
import time
class A(threading.Thread):
def run(self):
for i in range(4):
print(i)
if __name__ == '__main__':
a = A()
print(threading.enumerate())
a.start()
print(threading.enumerate())
time.sleep(5)
print(123)
print(threading.enumerate())
'''
[<_MainThread(MainThread, started 788)>]
0[<_MainThread(MainThread, started 788)>, <A(Thread-1, started 7788)>]
1
2
3
123
[<_MainThread(MainThread, started 788)>]'''
6.线程间的通信(多线程共享全局变量)
在一个函数中,对全局变量进行修改的时候,是否要加global要看是否对全局变量的指向进行了修改,如果修改了指向,那么必须使用global,仅仅是修改了指向的空间中的数据,此时不用必须使用global
线程是共享全局变量
import time
import threading
num = 100
def demo1():
global num
num += 1
print('demo1-nums%d'%num)
def demo2():
print('demo2-nums%d'%num)
def main():
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
time.sleep(1)
t2.start()
print('main-nums%d'%num)
if __name__ == '__main__':
main()
'''
demo1-nums101
demo2-nums101
main-nums101
'''
7.线程间的资源竞争
一个线程写入,一个线程读取,没问题,如果两个线程都写入呢?
示例
import time
import threading
num = 0
def demo1(nums):
global num
for i in range(nums):
num += 1
print('demo1-num %d' % num)
def demo2(nums):
global num
for i in range(nums):
num += 1
print('demo2-num %d' % num)
def main():
t1 = threading.Thread(target=demo1, args=(1000000,))
t2 = threading.Thread(target=demo2, args=(1000000,))
t1.start()
# time.sleep(3) # 让t1先运行3秒
t2.start()
time.sleep(3)
print('main-num %d' % num)
if __name__ == '__main__':
main()
'''
demo2-num 946165
demo1-num 1144227
main-num 1144227'''
解决资源竞争:在t1.start()之后暂停3秒再执行t2.start(),或者在分别在t1.start()、t2.start()之后加上t1.join(),t2.join() 或者加锁
加锁,Lock()创建一把锁,默认是没有上锁,这样创建的锁不可重复
示例
import time
import threading
num = 0
mutex = threading.Lock() # Lock()创建一把锁,默认是没有上锁,这样创建的锁不可重复
def demo1(nums):
global num
# 加锁
mutex.acquire()
for i in range(nums):
num += 1
# 解锁
mutex.release()
print('demo1-num %d' % num)
def demo2(nums):
global num
# 加锁
mutex.acquire()
for i in range(nums):
num += 1
# 解锁
mutex.release()
print('demo2-num %d' % num)
def main():
t1 = threading.Thread(target=demo1, args=(1000000,))
t2 = threading.Thread(target=demo2, args=(1000000,))
t1.start()
t2.start()
time.sleep(3)
print('main-num %d' % num)
if __name__ == '__main__':
main()
'''
demo1-num 1000000
demo2-num 2000000
main-num 2000000
'''
加锁,RLock()创建一把锁,默认是没有上锁,这样创建的锁可重复,要对应解锁
示例
import time
import threading
num = 0
mutex = threading.RLock() # RLock()创建一把锁,默认是没有上锁,这样创建的锁可重复,要对应解锁
def demo1(nums):
global num
# 加锁
mutex.acquire()
mutex.acquire()
for i in range(nums):
num += 1
# 解锁
mutex.release()
mutex.release()
print('demo1-num %d' % num)
def demo2(nums):
global num
# 加锁
mutex.acquire()
for i in range(nums):
num += 1
# 解锁
mutex.release()
print('demo2-num %d' % num)
def main():
t1 = threading.Thread(target=demo1, args=(1000000,))
t2 = threading.Thread(target=demo2, args=(1000000,))
t1.start()
t2.start()
time.sleep(3)
print('main-num %d' % num)
if __name__ == '__main__':
main()
'''
demo1-num 1000000
demo2-num 2000000
main-num 2000000
'''
二、生产者和消费者模型
1.线程间的资源竞争
一个线程写入,一个线程读取,没问题,如果两个线程都写入呢?
互斥锁和死锁
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
某个线程要更改共享数据时,先将其锁定,此时资源的状态为"锁定",其他线程不能改变,只到该线程释放资源,将资源的状态变成"非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
创建锁
mutex = threading.Lock()
锁定
mutex.acquire()
解锁
mutex.release()
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
示例
# 在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
import threading
import time
class MyThread1(threading.Thread):
def run(self):
# 对mutexA上锁
mutexA.acquire()
# mutexA上锁后,延时1秒,等待另外那个线程 把mutexB上锁
print(self.name+'----do1---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexB已经被另外的线程抢先上锁了
mutexB.acquire()
print(self.name+'----do1---down----')
mutexB.release()
# 对mutexA解锁
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 对mutexB上锁
mutexB.acquire()
# mutexB上锁后,延时1秒,等待另外那个线程 把mutexA上锁
print(self.name+'----do2---up----')
time.sleep(1)
# 此时会堵塞,因为这个mutexA已经被另外的线程抢先上锁了
mutexA.acquire()
print(self.name+'----do2---down----')
mutexA.release()
# 对mutexB解锁
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
'''
执行结果:打印如下,不会结束程序
Thread-1----do1---up----
Thread-2----do2---up----
'''
避免死锁
2.Queue线程
在线程中,访问一些全局变量,加锁是一个经常的过程。如果你是想把一些数据存储到某个队列中,那么Python内置了一个线程安全的模块叫做queue模块。Python中的queue模块中提供了同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue,LIFO(后入先出)队列LifoQueue。这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么都做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步。
# 初始化Queue(maxsize):创建一个先进先出的队列。
# empty():判断队列是否为空。
# full():判断队列是否满了。
# get():从队列中取最后一个数据。
# put():将一个数据放到队列中。
from queue import Queue
q = Queue()
print(q.empty()) # True 空的队列
print(q.full()) # False 不是满的队列
# --------------------------分隔线--------------------------------------
q1 = Queue()
q1.put(1) # 将数字1放到队列中
print(q1.empty()) # False 不是空的队列
print(q1.full()) # False 不是满的队列
# --------------------------分隔线--------------------------------------
q2 = Queue(3) # 指定为长度为3
q2.put(1)
q2.put(2)
q2.put(3)
print(q2.empty()) # False 不是空的队列
print(q2.full()) # True 是满的队列
# --------------------------分隔线--------------------------------------
q3 = Queue(3) # 指定为长度为3
q3.put(1)
q3.put(2)
q3.put(3)
q3.put(4, timeout=3) # 超出队列的长度,不加timeout程序将阻塞,加timeout=3,3秒后抛出异常 queue.Full
# --------------------------分隔线--------------------------------------
from queue import Queue
q4 = Queue(3) # 指定为长度为3
q4.put(1)
q4.put(2)
q4.put(3)
q4.put_nowait(4) # 超出队列的长度,直接抛出异常queue.Full
# --------------------------分隔线--------------------------------------
q5 = Queue(3) # 指定为长度为3
q5.put(1)
q5.put(2)
q5.put(3)
print(q5.get()) # 1
print(q5.get()) # 2
print(q5.get()) # 3
print(q5.get(timeout=3)) # 超出队列,程序将阻塞,添加timeout=3,3秒后抛出异常_queue.Empty
# --------------------------分隔线--------------------------------------
q6 = Queue(3) # 指定为长度为3
q6.put(1)
q6.put(2)
q6.put(3)
print(q6.get()) # 1
print(q6.get()) # 2
print(q6.get()) # 3
print(q6.get_nowait()) # 超出队列的长度,直接抛出异常_queue.Empty
3.生产者和消费者
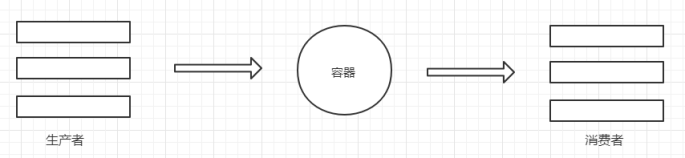
生产者和消费者模式是多线程开发中常见的一种模式。通过生产者和消费者模式,可以让代码达到高内聚低耦合的目标,线程管理更加方便,程序分工更加明确。
生产者的线程专门用来生产一些数据,然后存放到容器中(中间变量)。消费者在从这个中间的容器中取出数据进行消费
Lock版的生产者和消费者
import threading
import random
import time
gMoney = 0
gTimes = 0 # 定义一个变量 保存生产的次数 默认是0次
gLock = threading.Lock() # 定义一把锁
# 定义生产者
class Producer(threading.Thread):
def run(self) -> None:
global gMoney
global gTimes
# gLock.acquire() # 上锁
while True:
gLock.acquire() # 上锁
if gTimes >= 10:
gLock.release()
break
money = random.randint(0, 100) # 0 <= money <= 100
gMoney += money
gTimes += 1
# threading.current_thread().name 获取当前线程的名称
print("%s生产了%d元钱,累计%d元" % (threading.current_thread().name, money, gMoney))
gLock.release() # 解锁
time.sleep(1)
# 定义消费者
class Consumer(threading.Thread):
def run(self) -> None:
global gMoney
while True:
gLock.acquire() # 上锁
money = random.randint(0, 100) # 0 <= money <= 100
if gMoney >= money:
gMoney -= money
# threading.current_thread().name 获取当前线程的名称
print("%s消费了%d元钱,余额:%d元" % (threading.current_thread().name, money, gMoney))
else:
if gTimes >= 10:
gLock.release()
break
print("%s想消费%d元钱,但是余额只有%d元,不能消费" % (threading.current_thread().name, money, gMoney))
gLock.release() # 解锁
time.sleep(1)
def main():
# 开启5个生产者线程
for i in range(5):
th = Producer(name="生产者%d号" % i)
th.start()
# 开启5个消费者线程
for i in range(5):
th = Consumer(name="消费者%d号" % i)
th.start()
if __name__ == '__main__':
main()
'''
生产者0号生产了13元钱,累计13元
生产者1号生产了77元钱,累计90元
生产者2号生产了56元钱,累计146元
生产者3号生产了39元钱,累计185元
生产者4号生产了10元钱,累计195元
消费者0号消费了48元钱,余额:147元
消费者1号消费了92元钱,余额:55元
消费者2号想消费88元钱,但是余额只有55元,不能消费
消费者3号想消费68元钱,但是余额只有55元,不能消费
消费者4号消费了15元钱,余额:40元
生产者2号生产了77元钱,累计117元
消费者1号消费了99元钱,余额:18元
生产者1号生产了79元钱,累计97元
消费者0号消费了79元钱,余额:18元
消费者4号想消费40元钱,但是余额只有18元,不能消费
生产者0号生产了65元钱,累计83元
生产者4号生产了29元钱,累计112元
消费者3号消费了64元钱,余额:48元
生产者3号生产了95元钱,累计143元
消费者2号消费了73元钱,余额:70元
消费者1号消费了13元钱,余额:57元
消费者4号消费了48元钱,余额:9元
消费者1号消费了1元钱,余额:8元
'''
'''
Condition版的生产者和消费者
# 相对Lock版的生产者和消费者,Lock版消耗资源更多。Condition增加了阻塞等待
import threading
import random
import time
gMoney = 0
# 定义一个变量 保存生产的次数 默认是0次
gTimes = 0
# 定义一把锁
gCond = threading.Condition()
# 定义生产者
class Producer(threading.Thread):
def run(self) -> None:
global gMoney
global gTimes
# gLock.acquire() # 上锁
while True:
gCond.acquire() # 上锁
if gTimes >= 10:
gCond.release()
break
money = random.randint(0, 100) # 0 <= money <= 100
gMoney += money
gTimes += 1
print("%s生产了%d元钱,累计%d元" % (threading.current_thread().name, money, gMoney))
gCond.notifyAll() # 通知所有
gCond.release() # 解锁
time.sleep(1)
# 定义消费者
class Consumer(threading.Thread):
def run(self) -> None:
global gMoney
while True:
gCond.acquire() # 上锁
money = random.randint(0, 100)
while gMoney < money:
if gTimes >= 10:
gCond.release() # 解锁
return # 这里如果用break退出了内循环,但是外层循环没有退出,直接用return
print("%s想消费%d元钱,但是余额只有%d元,不能消费" % (threading.current_thread().name, money, gMoney))
gCond.wait() # 等待
# 开始消费
gMoney -= money
print("%s消费了%d元钱,余额:%d元" % (threading.current_thread().name, money, gMoney))
gCond.release() # 解锁
time.sleep(1)
def main():
# 开启5个生产者线程
for i in range(5):
th = Producer(name="生产者%d号" % i)
th.start()
# 开启5个消费者线程
for i in range(5):
th = Consumer(name="消费者%d号" % i)
th.start()
if __name__ == '__main__':
main()
'''
生产者0号生产了28元钱,累计28元
生产者1号生产了0元钱,累计28元
生产者2号生产了94元钱,累计122元
生产者3号生产了68元钱,累计190元
生产者4号生产了29元钱,累计219元
消费者0号消费了35元钱,余额:184元
消费者1号消费了96元钱,余额:88元
消费者2号消费了33元钱,余额:55元
消费者3号消费了51元钱,余额:4元
消费者4号想消费75元钱,但是余额只有4元,不能消费
生产者1号生产了63元钱,累计67元
生产者3号生产了57元钱,累计124元
消费者2号消费了75元钱,余额:49元
消费者1号想消费90元钱,但是余额只有49元,不能消费
生产者2号生产了84元钱,累计133元
消费者1号消费了90元钱,余额:43元
生产者0号生产了40元钱,累计83元
消费者0号消费了43元钱,余额:40元
生产者4号生产了3元钱,累计43元
消费者1号消费了4元钱,余额:39元
消费者2号消费了19元钱,余额:20元
消费者0号消费了18元钱,余额:2元
'''
三、多线程爬取王者荣耀高清壁纸案例
import os
import queue
from urllib import parse
from urllib.request import urlretrieve
import requests
import threading
headers = {
'referer':'https://pvp.qq.com/',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'
}
all_name_list = []
num = 0
# 定义生产者
class Producer(threading.Thread):
def __init__(self, page_queue, image_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.image_queue = image_queue
def run(self) -> None:
while not self.page_queue.empty():
page_url = self.page_queue.get()
reponse = requests.get(page_url, verify=False, headers=headers).json()
result = reponse['List']
for data in result:
# 获取图片的url
image_urls = extract_images(data)
# 获取图片名字
name = parse.unquote(data['sProdName']).replace('1:1', '').strip()
# name = parse.unquote(data['sProdName']).strip() 引发下面报错
# FileNotFoundError: [WinError 3] 系统找不到指定的路径。: '1:1等身雕塑·铠'
while name in all_name_list: # 判断是否重名
name = name + str(num + 1)
all_name_list.append(name)
# 创建文件夹
dir_path = os.path.join('image', name) # dir_path = 'image/%s' % name 也可以
if not os.path.exists(dir_path):
os.mkdir(dir_path)
# 把图片的url放进队列里
for index, image_url in enumerate(image_urls):
self.image_queue.put(
{'image_url': image_url, 'image_path': os.path.join(dir_path, '%d.jpg' % (index + 1))})
# 定义消费者
class Consumer(threading.Thread):
def __init__(self, image_queue, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.image_queue = image_queue
def run(self) -> None:
failed_image_obj = [] # 空列表存放下载失败的image_url和image_path
while True:
try:
# 获取图片的url和下载路径
image_obj = self.image_queue.get(timeout=10)
image_url = image_obj.get('image_url')
image_path = image_obj.get('image_path')
# 下载图片
try:
urlretrieve(image_url, image_path)
print(image_path, '下载完成!')
except:
print(image_path, '下载失败!')
failed_image_obj.append((image_url, image_path))
except:
break
for item in failed_image_obj: # 最后再次尝试下载失败的图片
try:
urlretrieve(item[0], item[1])
print(item[1], '再次下载,终于成功了!')
except:
print(item[0], item[1], '还是下载失败!')
def extract_images(data):
image_urls = []
for i in range(1, 9):
image_url = parse.unquote(data['sProdImgNo_%d' % i]).rstrip('200') + '0'
# image_url = parse.unquote(data['sProdImgNo_%d' % i]).replace('200', '0')
image_urls.append(image_url)
return image_urls
def main():
# 创建页数的队列
page_queue = queue.Queue(25)
# 创建图片的队列
image_queue = queue.Queue(1000)
for i in range(25):
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735'.format(
i)
# 把页数url添加到页数的队列中
page_queue.put(url)
# 定义3个生产者线程
for i in range(3):
p = Producer(page_queue, image_queue)
p.start()
# 定义8个消费者线程
for i in range(8):
c = Consumer(image_queue)
c.start()
if __name__ == '__main__':
main()
得到全部数据: