ElasticSearch笔记
我们要讲解什么?
SQL : like %狂神说% ,如果是的大数据,就十分慢!索引!
ElasticSearch:搜索! (百度、github、 淘宝电商! )
1、聊一个人
2、货比三家
3、安装
4、生态圈.
5、分词器ik
6、RestFul操作 ES
7、CRUD
8、SpringBoot集成ElasticSearch (从原理分析! )
9、爬虫爬取数据!
10、 实战,模拟全文检索!
以后你只要,需要用到搜索,就可以使用ES! (大数据量的情况下使用! )
聊聊Doug Cutting
1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。

无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。

左为Doug Cutting,右为Lucene的LOGO
Lucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源(代码公开),非常受程序员们的欢迎。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge(一个开源软件网站)。后来,2001年底,Lucene成为Apache软件基金会jakarta项目的一个子项目。

Apache软件基金会,搞IT的应该都认识
2004年,Doug Cutting再接再励,在Lucene的基础上,和Apache开源伙伴Mike Cafarella合作,开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为Nutch。

Nutch是一个建立在Lucene核心之上的网页搜索应用程序,可以下载下来直接使用。它在Lucene的基础上加了网络爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络的搜索上,就像Google一样。
Nutch在业界的影响力比Lucene更大。
大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。甚至有一段时间,在硅谷有了一股用Nutch低成本创业的潮流。
随着时间的推移,无论是Google还是Nutch,都面临搜索对象“体积”不断增大的问题。
尤其是Google,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。

在这个过程中,Google确实找到了不少好办法,并且无私地分享了出来。
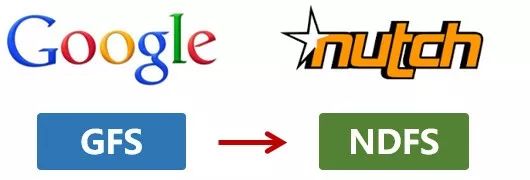
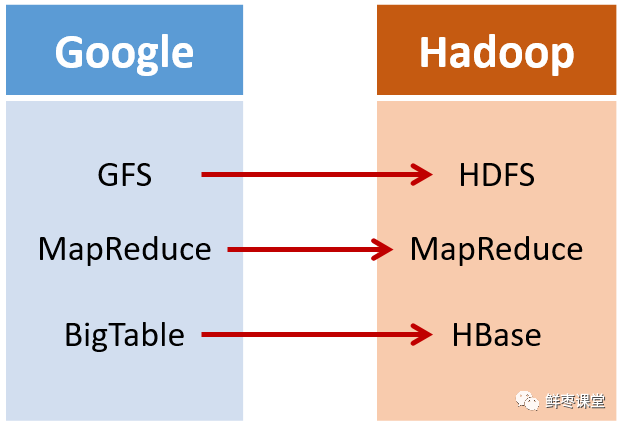
2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件系统。
第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。
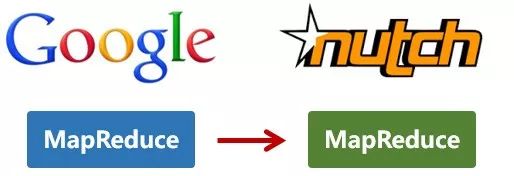
还是2004年,Google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型。这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。
第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting。

这里要补充说明一下雅虎招安Doug的背景:2004年之前,作为互联网开拓者的雅虎,是使用Google搜索引擎作为自家搜索服务的。在2004年开始,雅虎放弃了Google,开始自己研发搜索引擎。所以。。。
加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System)。
这个,就是后来大名鼎鼎的大数据框架系统——Hadoop的由来。而Doug Cutting,则被人们称为Hadoop之父。

Hadoop这个名字,实际上是Doug Cutting他儿子的黄色玩具大象的名字。所以,Hadoop的Logo,就是一只奔跑的黄色大象。

我们继续往下说。
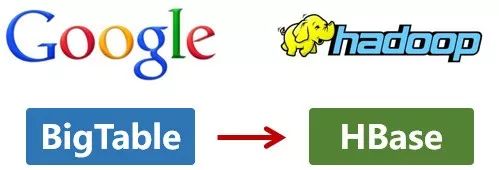
还是2006年,Google又发论文了。
这次,它们介绍了自己的BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase。
好吧,反正就是紧跟Google时代步伐,你出什么,我学什么。
所以,Hadoop的核心部分,基本上都有Google的影子。
2008年1月,Hadoop成功上位,正式成为Apache基金会的顶级项目。
同年2月,Yahoo宣布建成了一个拥有1万个内核的Hadoop集群,并将自己的搜索引擎产品部署在上面。
7月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,用时209秒。
回到主题
在学习ElasticSearch之前,先简单了解一下Lucene:
-
Doug Cutting开发
-
是apache软件基金会4 jakarta项目组的一个子项目
-
是一个开放源代码的全文检索引擎工具包
-
不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)
-
当前以及最近几年最受欢迎的免费Java信息检索程序库。
Lucene和ElasticSearch的关系:
- ElasticSearch是基于Lucene 做了一下封装和增强
-
一、ElasticSearch概述
官网:https://www.elastic.co/cn/downloads/elasticsearch
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是 通过简单的==RESTful API(/user get post put delete)==来隐藏Lucene的复杂性,从而让全文搜索变得简单 。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便lava程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
谁在使用:
1、维基百科,类似百度百科,全文检索,高亮,搜索推荐/2(权重,百度!)
2、The Guardian (国外新闻网站) ,类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论) +社交网络数据(对某某新闻的相关看法) ,数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
3、Stack Overflow (国外的程序异常讨论论坛) , IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相
关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
4、GitHub (开源代码管理),搜索 上千亿行代码
5、电商网站,检索商品
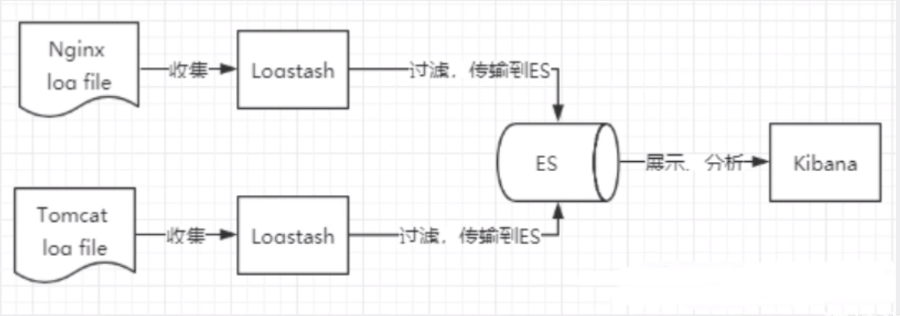
6、日志数据分析, logstash采集日志, ES进行复杂的数据分析, ELK技术, elasticsearch+logstash+kibana
7、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
8、BI系统,商业智能, Business Intelligence。比如说有个大型商场集团,BI ,分析一下某某区域最近3年的用户消费 金额的趋势以及用户群体的组成构成,产出相关的数张报表, **区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开-个新商场。ES执行数据分析和挖掘, Kibana进行数据可视化
9、国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门
的一一个使用场景)
1、ElasticSearch简介
- Elasticsearch是一个实时分布式搜索和分析引擎。 它让你以前所未有的速度处理大数据成为可能。
- 它用于 全文搜索、结构化搜索、分析以及将这三者混合使用:
- 维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。
- 英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
- StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
- Github使用Elasticsearch检索1300亿行的代码。
- 但是Elasticsearch不仅用于大型企业,它还让像DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。
- Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
- Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域, Lucene可被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
- 但是, Lucene只是一个库。 想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是, Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
- Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2、Solr简介
- Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
- Solr可以独立运行,运行在letty. Tomcat等这些Selrvlet容器中 , Solr 索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档, Solr根据xml文档添加、删除、更新索引。Solr 搜索只需要发送HTTP GET请求,然后对Solr返回xml、json等格式的查询结果进行解析,组织页面布局。
- Solr不提供构建UI的功能, Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
- Solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene.
- Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交-定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
3、lucene简介
4、ElasticSearch与Solr比较
-
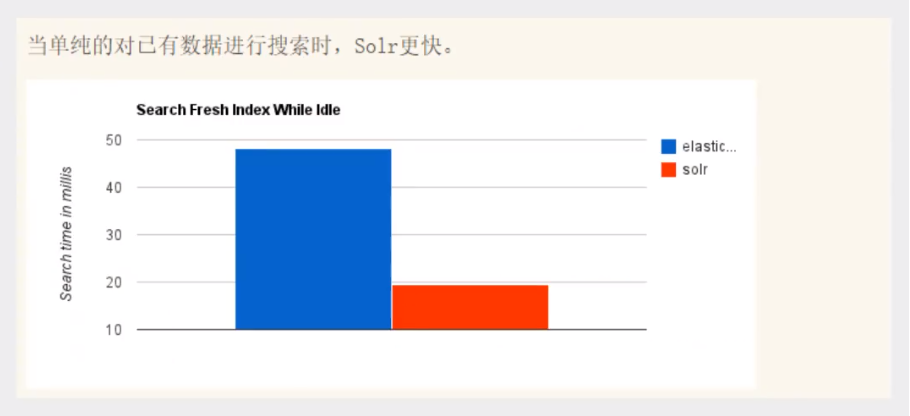
当单纯的对已有数据进行搜索时,Solr更快
-
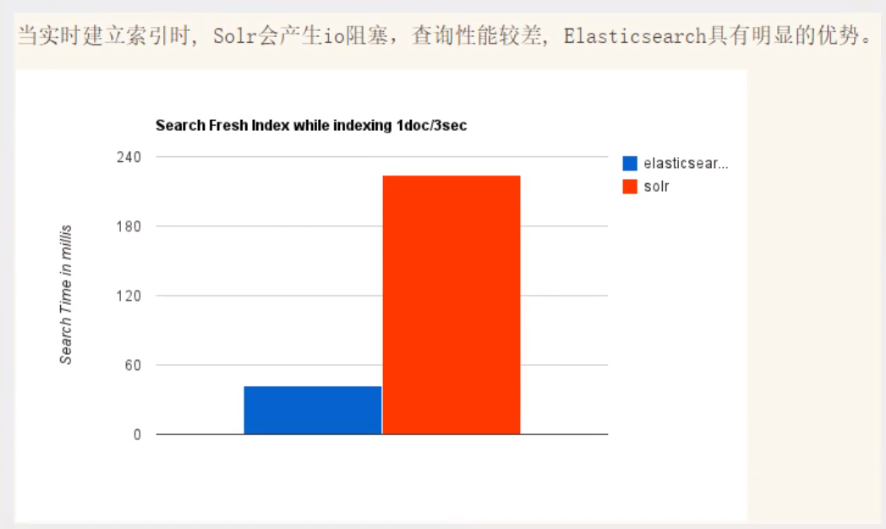
当实时建立索引时,Solr会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势
-
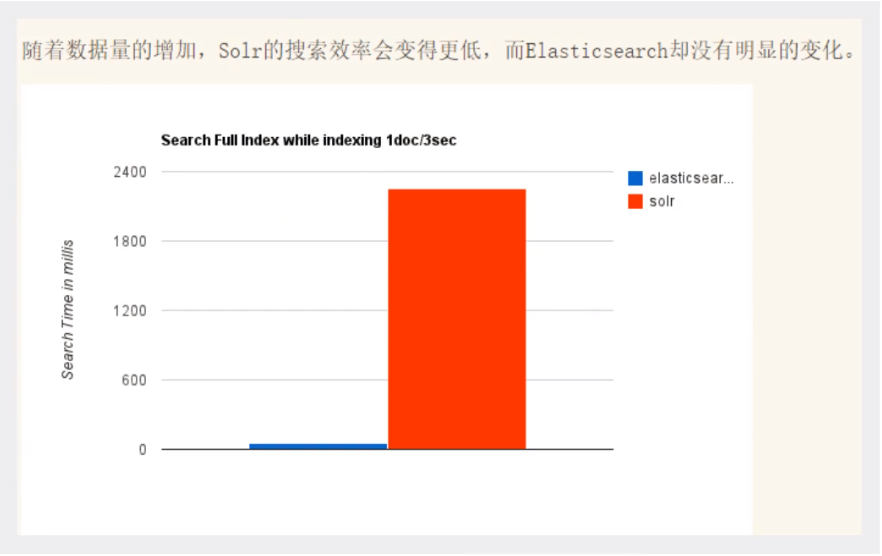
随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化
-
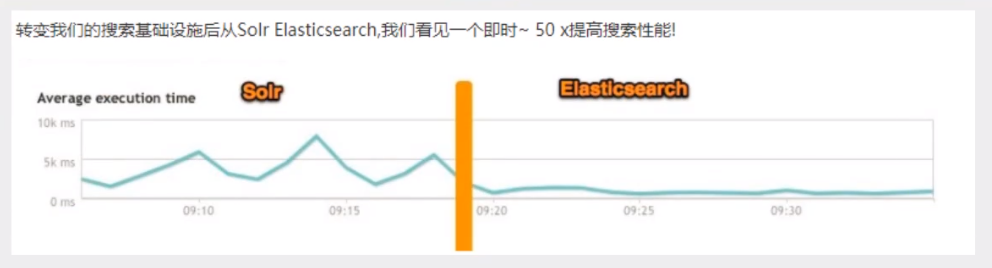
转变我们的搜索基础设施后从Solr ElasticSearch,我们看见一个即时~ 50x提高搜索性能!
-
总结
1、es基本是开箱即用(解压就可以用!) ,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用Zookeeper进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能 。
3、Solr 支持更多格式的数据,比如JSON、XML、 CSV ,而Elasticsearch仅支持json文件格式。
4、Solr 官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、 Solr 查询快,但更新索引时慢(即插入删除慢) ,用于电商等查询多的应用;
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
二、ElasticSearch安装
JDK8,最低要求
使用Java开发,必须保证ElasticSearch的版本与Java的核心jar包版本对应!(Java环境保证没错)
1、Windows下安装
-
安装
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
-
熟悉目录
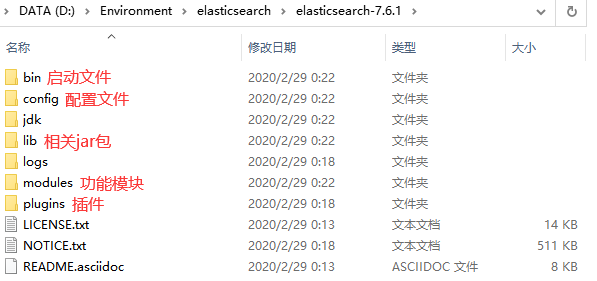
bin 启动文件目录
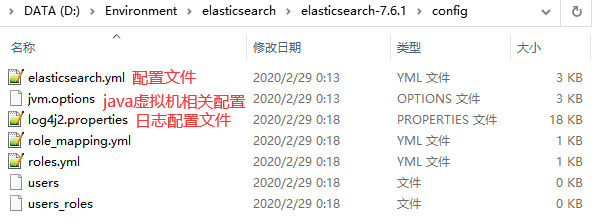
config 配置文件目录
1og4j2 日志配置文件
jvm.options java 虚拟机相关的配置(默认启动占1g内存,内容不够需要自己调整)
elasticsearch.ym1 elasticsearch 的配置文件! 默认9200端口!跨域!
1ib
相关jar包
modules 功能模块目录
plugins 插件目录 ik分词器
-
启动
一定要检查自己的java环境是否配置好
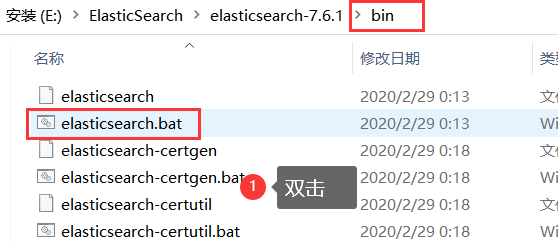
访问http://127.0.0.1:9200/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BHBAjane-1629335862690)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801163244729.png)]
2、安装可视化界面
elasticsearch-head
使用前提:需要安装nodejs
安装 npm install
运行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H3HhcwGV-1629335862691)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801163714826.png)]
访问
存在跨域问题(只有当两个页面同源,才能交互)
同源(端口,主机,协议三者都相同)
https://blog.csdn.net/qq_38128179/article/details/84956552
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YOgBgbqT-1629335862691)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801163921981.png)]
开启跨域(在elasticsearch解压目录config下elasticsearch.yml中添加)
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"
重启elasticsearch
再次连接
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iThCJoG4-1629335862692)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801164409422.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K1jqAiY9-1629335862692)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801164608843.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h0YR0wOy-1629335862693)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801164751717.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xcf6RbvQ-1629335862693)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801164806636.png)]
如何理解上图:
- 如果你是初学者
- 索引 可以看做 “数据库”
- 类型 可以看做 “表”
- 文档 可以看做 “库中的数据(表中的行)”
- 这个head,我们只是把它当做可视化数据展示工具,之后所有的查询都在kibana中进行
了解ELK
ELK是Elasticsearch、Logstash、 Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。
其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。
Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ )收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。
Kibana可以将elasticsearch的数据通过友好的页面展示出来 ,提供实时分析的功能。
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称 ,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
收集清洗数据(Logstash) ==> 搜索、存储(ElasticSearch) ==> 展示(Kibana)
3、安装kibana
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GIesv2b5-1629335862694)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801170737205.png)]
-
下载地址:
下载的版本需要与ElasticSearch版本对应==
https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
-
安装
解压即可(尽量将ElasticSearch相关工具放在统一目录下)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ApwCiKW-1629335862694)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801170813158.png)]
-
启动
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-92OqTf94-1629335862695)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801170841562.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fbf6GLWp-1629335862695)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801171017960.png)]
-
访问
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SzVVCyg2-1629335862696)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801171203919.png)]
开发工具
(Postman、curl、head、谷歌浏览器插件)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8t9vw2Y7-1629335862697)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801171427526.png)]
如果说,你在英文方面不太擅长,kibana是支持汉化的
-
kibana汉化
编辑器打开kibana解压目录/config/kibana.yml(kibana-7.13.1-windows-x86_64/config/kibana.yml),添加
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qT4fSj7M-1629335862697)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801171628288.png)]
重启kibana
汉化成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KjWeLFAI-1629335862698)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801171934076.png)]
三、ElasticSearch核心概念
概述
集群,节点,索引,类型,文档,分片,映射是什么?
1、索引(ElasticSearch)
2、字段类型(映射)mapping
3、文档(documents)
4、分片(Lucene索引,倒排索引)
elasticsearch是面向文档,关系型数据库和elasticsearch客观的对比!一切都是json
| Relational DB |
Elasticsearch |
| 数据库(database) |
索引(indices) |
| 表(tables) |
types |
| 行(rows) |
documents |
| 字段(columns) |
fields |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7UAfOfN3-1629335862699)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801172228464.png)]
elasticsearch(集群)中可以包含多个索引(数据库) ,每个索引中可以包含多个类型(表) ,每个类型下又包含多个文档(行) ,每个文档中又包含多个字段(列)。
物理设计:
elasticsearch在后台把每个索引划分成多个分片。每个分片可以在集群中的不同服务器间迁移
一个人就是一个集群! ,即启动的ElasticSearch服务,默认就是一个集群,且默认集群名为elasticsearch
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cM08DVVK-1629335862699)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801172814790.png)]
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引->类型->文档id,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是一个字符串。
1、文档
文档(”行“)
就是我们的一条条的记录
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档, elasticsearch中,文档有几个重要属性:
- 自我包含, - -篇文档同时包含字段和对应的值,也就是同时包含key:value !
- 可以是层次型的,-一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一 个json对象! fastjson进行自动转换!}
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
2、类型
类型(“表”)
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定 义称为映射,比如name映射为字符串类型。我们说文档是无模式的 ,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, elasticsearch就开始猜,如果这个值是18 ,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对 ,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
3、索引
索引(“库”)
就是数据库!
索引是映射类型的容器, elasticsearch中的索引是一个非常大的文档集合。索|存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
一个集群至少有一 个节点,而一个节点就是一-个elasricsearch进程 ,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有-一个副本( replica shard ,又称复制分片)

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同-个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上, 一个分片是- -个Lucene索引, -一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
4、倒排索引
倒排索引
elasticsearch使用的是一种称为倒排索引 |的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up to forever # 文 档1包含的内容
To forever, study every day,good good up # 文档2包含的内容
为为创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,然后创建一一个包含所有不重 复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term |
doc_1 |
doc_2 |
| Study |
√ |
x |
| To |
x |
x |
| every |
√ |
√ |
| forever |
√ |
√ |
| day |
√ |
√ |
| study |
x |
√ |
| good |
√ |
√ |
| every |
√ |
√ |
| to |
√ |
x |
| up |
√ |
√ |
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档
| term |
doc_1 |
doc_2 |
| to |
√ |
x |
| forever |
√ |
√ |
| total |
2 |
1 |
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
|
|
|
|
| 博客文章(原始数据) |
博客文章(原始数据) |
索引列表(倒排索引) |
索引列表(倒排索引) |
| 博客文章ID |
标签 |
标签 |
博客文章ID |
| 1 |
python |
python |
1,2,3 |
| 2 |
python |
linux |
3,4 |
| 3 |
linux,python |
|
|
| 4 |
linux |
|
|
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中 ,索引被分为多个分片,每份分片是-个Lucene的索引。所以一个elasticsearch索引是由多 个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
四、IK分词器(elasticsearch插件)
IK分词器:中文分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一一个匹配操作,默认的中文分词是将每个字看成一个词(不使用用IK分词器的情况下),比如“我爱狂神”会被分为”我”,”爱”,”狂”,”神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法: (ik_smart和ik_max_word )
-
ik_smart为最少切分
-
ik_max_word为最细粒度划分!
1、下载
版本要与ElasticSearch版本对应
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2、安装
ik文件夹是自己创建的
3、重启观察ES
加载了IK分词器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FJseP7oJ-1629335862700)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801185112382.png)]
使用 ElasticSearch安装补录/bin/elasticsearch-plugin 可以查看插件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kMoNHfOe-1629335862701)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801185235609.png)]
4、使用kibana测试
查看不同的分词效果
ik_smart:最少切分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LujVv9pf-1629335862701)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801185851313.png)]
ik_max_word:最细粒度划分(穷尽词库的可能)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BmPp2u3D-1629335862702)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801185919174.png)]
输入 超级喜欢狂神说java
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XG2xUjQe-1629335862702)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801190307461.png)]
发现问题:狂神说被拆开了!
这种自己需要的词,需要自己加到我们的分词器的字典中!
添加自定义的词添加到扩展字典中
elasticsearch目录/plugins/ik/config/IKAnalyzer.cfg.xml
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VHD6mPKa-1629335862703)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801190537280.png)]
创建字典文件,添加字典内容
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1thcrS3t-1629335862703)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801190741819.png)]
打开 IKAnalyzer.cfg.xml 文件,扩展字典
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1DU1WDcj-1629335862704)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801190706681.png)]
重启ElasticSearch,再次使用kibana测试
加载了自己的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fj3xxcht-1629335862705)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801192026208.png)]
测试kibana
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E42Naj7k-1629335862705)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801192233452.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JYv3b5kK-1629335862706)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801192310546.png)]
五、Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
1、基本Rest命令说明:
| method |
url地址 |
描述 |
| PUT(创建,修改) |
localhost:9200/索引名称/类型名称/文档id |
创建文档(指定文档id) |
| POST(创建) |
localhost:9200/索引名称/类型名称 |
创建文档(随机文档id) |
| POST(修改) |
localhost:9200/索引名称/类型名称/文档id/_update |
修改文档 |
| DELETE(删除) |
localhost:9200/索引名称/类型名称/文档id |
删除文档 |
| GET(查询) |
localhost:9200/索引名称/类型名称/文档id |
查询文档通过文档ID |
| POST(查询) |
localhost:9200/索引名称/类型名称/文档id/_search |
查询所有数据 |
2、关于索引的基本操作
1、创建一个索引,添加
PUT /索引名/~类型名~/文档id
{请求体}
PUT /test1/type1/1
{
"name" : "流柚",
"age" : 18
}
# 返回结果
# 警告信息: 不支持在文档索引请求中的指定类型
# 而是使用无类型的断点(/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "test1", # 索引
"_type" : "type1", # 类型(已经废弃)
"_id" : "1", # id
"_version" : 1, # 版本
"result" : "created", # 操作类型
"_shards" : { # 分片信息
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Hnu3WY5-1629335862706)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801192812053.png)]
完成了自动增加了索引!数据也成功的添加了,这就是我说大家在初期可以把它当左数据库学习的原因!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fq4QHDyU-1629335862707)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801193029770.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-slGJK7Km-1629335862707)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801193225217.png)]
2、字段数据类型
-
字符串类型
text、keyword
- text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
-
数值型
- long、Integer、short、byte、double、float、half float、scaled float
-
日期类型
-
te布尔类型
-
二进制类型
-
等等…
3、指定字段的类型(使用PUT)
创建规则 类似于建库(建立索引和字段对应类型),也可看做规则的建立
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZfIP5RVI-1629335862708)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801193621767.png)]
4、获取规则
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DL51KNnZ-1629335862708)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801193749847.png)]
5、获取默认信息
_doc 默认类型(default type),type 在未来的版本中会逐渐弃用,因此产生一个默认类型进行代替
PUT /test3/_doc/1
{
"name": "流柚",
"age": 18,
"birth": "1999-10-10"
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3hrcL8u4-1629335862709)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801194047099.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RkOzGYC7-1629335862709)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801194126272.png)]
如果自己的文档字段没有被指定,那么ElasticSearch就会给我们默认配置字段类型
扩展:通过get _cat/ 可以获取ElasticSearch的当前的很多信息!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aMiISu1p-1629335862710)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801194413008.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VHXJMdy9-1629335862710)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801194711510.png)]
6、修改
两种方案
-
旧的(使用put覆盖原来的值)
-
版本+1(_version)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nJ1T8s3B-1629335862711)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801194940285.png)]
-
但是如果漏掉某个字段没有写,那么更新是没有写的字段 ,会消失
-
新的(使用post的update)
- version不会改变
- 需要注意doc
不会丢失字段
POST /test3/_doc/1/_update
{
"doc": {
"name": "法外狂徒张三",
"age": 2
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qAsHub6s-1629335862711)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801195230099.png)]
7、删除
GET /test1
DELETE /test1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DCu4JJe2-1629335862712)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801195840803.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SqtfxuP4-1629335862712)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801195856125.png)]
3、关于文档的基本操作(重点)
基本操作
1、添加数据
PUT /hcd/user/1
{
"name": "狂神说",
"age": 23,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["运动","阳光","直男"]
}
PUT /hcd/user/2
{
"name": "张三",
"age": 23,
"desc": "法外狂徒",
"tags": ["运动","旅游","渣男"]
}
PUT /hcd/user/3
{
"name": "李四",
"age": 23,
"desc": "mmp,不知道 如何形容",
"tags": ["靓仔","旅游","唱歌"]
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lvHMmCA6-1629335862713)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801201308203.png)]
2、查询数据
GET hcd/user/1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GL22Depk-1629335862713)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801201412031.png)]
3、更新数据
PUT /hcd/user/3
{
"name": "李四233",
"age": 23,
"desc": "mmp,不知道 如何形容",
"tags": ["靓仔","旅游","唱歌"]
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6RIJyulj-1629335862714)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801201548534.png)]
4、POST _update,推荐使用这种更新方式
put如果不传值就会本覆盖
POST hcd/user/1/_update
{
"doc": {
"name": "狂神说java"
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xKUU9BF1-1629335862714)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801202046461.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ejzv7GLz-1629335862715)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801202147373.png)]
简单的搜索
GET hcd/user/1
简单的条件查询,可以根据默认的映射规则,产生基本的查询!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1TgsCHSD-1629335862716)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801203110105.png)]
这边name是text 所以做了分词的查询 如果是keyword就不会分词搜索了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AgUnJ5ii-1629335862716)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801203623623.png)]
复杂操作搜索 select(排序,分页,高亮,模糊查询,精准查询)
//测试只能一个字段查询
GET hcd/user/_search
{
"query": {
"match": {
"name": "狂神"
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fltHkQwM-1629335862717)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801203813903.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HdvNgRbZ-1629335862717)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801204327248.png)]
结果过滤,就是只展示列表中某些字段
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kQYseYHM-1629335862718)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801204508918.png)]
我们之后使用java操作es,所有的方法和对象就是这里面的key!
排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8xBdwg42-1629335862718)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801204818329.png)]
分页
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SDyQv243-1629335862719)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801205133546.png)]
数据下标还是从0开始,和学的所有的数据结构是一样的!
布尔值查询
must(and),所有的条件都要符合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TJbiSTtI-1629335862719)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801205825075.png)]
should(or)或者的 跟数据库一样
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QTjEg5Er-1629335862720)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801210016133.png)]
must_not(not)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nryMdptv-1629335862720)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801210145584.png)]
过滤器 filter
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eOWk2g56-1629335862721)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801210511588.png)]
- gt大于
- gte大于等于
- lte小于
- lte小于等于
匹配多个条件(数组)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xnZbpM8r-1629335862721)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801211030648.png)]
match没用倒排索引 这边改正一下???(不确定)
精确查询
term查询是直接通过倒排索引指定的词条进程精确查找的
关于分词
- term,直接查询精确的
- match,会使用分词器解析!(先分析文档,然后通过分析的文档进行查询)
两个类型 text keyword
- text:
-
支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作;
- text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:
-
不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
- keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
精确查询多个值
PUT /test_db/_doc/3
{
"t1": "22",
"t2": "2020-09-10"
}
PUT /test_db/_doc/4
{
"t1": "33",
"t2": "2020-09-11"
}
GET test_db/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": "22"
}
},
{
"term": {
"t1": "33"
}
}
]
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bPsWjTrG-1629335862722)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801212801644.png)]
高亮
GET hcd/user/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zw1tQr4H-1629335862722)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801213208364.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mCo3dq3c-1629335862723)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210801213410532.png)]
这些其实MySQL也可以做,只是MySQL效率比较低!
- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
六、集成SpringBoot
找官方文档
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B8IIeZcU-1629335862723)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802111414458.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y2X6oAjv-1629335862724)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802111517118.png)]
1、找到原生的依赖
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kqy0Jcs5-1629335862725)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802144520575.png)]
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
2、找对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ETVUGGsA-1629335862725)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802112004907.png)]
3、分析这个类中的方法即可
项目结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uw6ctBgp-1629335862726)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802142057147.png)]
配置基本的项目
问题:一定要保证我们导入的依赖和我们es版本一致
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xn9FzUKQ-1629335862726)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802113742252.png)]
下载以后
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qT7rd967-1629335862727)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802114231234.png)]
配置类
//spring两步骤
// 1、找对象
// 2、放到spring中待用
@Configuration
public class ElasticSearchClientConfig {
//elk
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
)
);
return client;
}
}
实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
private String name;
private Integer age;
}
具体的api测试
@SpringBootTest
class HcdEsApiApplicationTests {
//通过面向对象操作
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
// 创建索引
@Test
void testCreateIndex() throws IOException {
// 1. 创建索引请求
CreateIndexRequest request = new CreateIndexRequest("hcd_index");
// 2. 客户端执行请求, IndicesClient,请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
// 测试索引存在
@Test
void testExistsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hcd_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("索引是否存在: " + exists);
}
// 删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hcd_index");
//删除
AcknowledgedResponse acknowledgedResponse = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(acknowledgedResponse.isAcknowledged());
}
// 添加文档
@Test
void testAddDocument() throws IOException {
User user = new User("狂神说", 28);
IndexRequest request = new IndexRequest("hcd_index");
// 规则 PUT /index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
// 将数据放入请求 json
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.toString());//IndexResponse[index=hcd_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
System.out.println(response.status());//输出 CREATED
}
// 获取文档 判断是否存在 GET /index/_doc/1
@Test
void testIsExists() throws IOException {
GetRequest request = new GetRequest("hcd_index", "1");
// 不获取返回的 _source 的上下文了
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none_");
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println("文档是否存在: " + exists);
}
// 获取文档
/**
* 返回结果:
* {"age":28,"name":"狂神说"}
* {
* "_index":"hcd_index",
* "_type":"_doc","_id":"1",
* "_version":1,
* "_seq_no":0,
* "_primary_term":1,
* "found":true,
* "_source":{"age":28,"name":"狂神说"}
* }
*/
@Test
void testGetDocument() throws IOException {
GetRequest request = new GetRequest("hcd_index", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());//{"age":28,"name":"狂神说"}
System.out.println(response);
}
// 更新文档
@Test
void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("hcd_index", "1");
request.timeout("1s");
User user = new User("小韩学Java", 18);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
System.out.println(updateResponse);
}
// 删除文档
/**输出信息
*DeleteResponse[index=hcd_index,
* type=_doc,id=1,version=2,result=deleted,shards=ShardInfo{total=2, successful=1, failures=[]}
* ]
*/
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("hcd_index", "1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse);
}
// 批量插入数据(修改,删除类似操作)
@Test
void testBulkRequest() throws IOException {
BulkRequest request = new BulkRequest();
request.timeout("10s");
ArrayList<User> users = new ArrayList<>();
users.add(new User("hcd1", 21));
users.add(new User("hcd2", 22));
users.add(new User("hcd3", 23));
users.add(new User("hcd4", 18));
users.add(new User("hcd5", 19));
// 批处理请求, 修改,删除,只要在这里修改相应的请求就可以
for (int i = 0; i < users.size(); i++) {
request.add(new IndexRequest("hcd_index")
.id(String.valueOf(i + 1))
.source(JSON.toJSONString(users.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(request, RequestOptions.DEFAULT);
//是否失败,返回false表示成功
System.out.println(bulkResponse.hasFailures());
}
// 查询文档
// 搜索请求SearchRequest
// 条件构造SearchSourceBuilder
// 构建高亮HighlightBuilder
// 精确查找MatchAllQueryBuilder
// 对应我们刚才看到的所有命令 xxxQueryBuilder
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("hcd_index");
// 构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 查询条件, 可以使用QueryBuilders工具类实现
// QueryBuilders.termQuery 精确
// QueryBuilders.matchLLQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "hcd1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSON(searchResponse.getHits()));
System.out.println("======================================");
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
/**
* 查询结果
* {"hits":
* [{ "sourceAsMap":{"name":"hcd1","age":21},
* "seqNo":-2,"primaryTerm":0,
* "index":"hcd_index",
* "type":"_doc",
* "sortValues":[],
* "sourceAsString":"{\"age\":21,\"name\":\"hcd1\"}",
* "version":-1,
* "score":1.3862942,
* "fragment":false,
* "highlightFields":{},
* "matchedQueries":[],
* "id":"1","fields":{},"
* sourceRef":{"fragment":true},
* "rawSortValues":[]}],
* "fragment":true,
* "totalHits":{"value":1,"relation":"EQUAL_TO"},
* "maxScore":1.3862942}
* ======================================
* {name=hcd1, age=21}
*/
}
七、ElasticSearch实战
1、概述
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lgZj5lV0-1629335862727)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802162028024.png)]
实现京东的搜索效果,高亮
项目结构图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UDKpsKfG-1629335862728)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802181456195.png)]
配置文件
# 更改端口,防止冲突
server.port=9999
# 关闭thymeleaf缓存
spring.thymeleaf.cache=false
导入前端后测试页面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RVZ7l03K-1629335862729)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802184830921.png)]
Config
@Configuration
public class ElasticSearchClientConfig {
//elk
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")
)
);
return client;
}
}
2、爬虫
京东网站:http://search.jd.com/search?keyword=java
依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
爬取数据(获取请求返回的页面信息,筛选出可用的)
创建HtmlParseUtil,并简单编写
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
//获取请求
// 使用前需要联网
// 请求url
String url="https://search.jd.com/Search?keyword=java";
// 1.解析网页(jsoup 解析返回的对象是浏览器Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
// 使用document可以使用在js对document的所有操作
// 2.获取元素(通过id)
Element j_goodsList = document.getElementById("J_goodsList");
//System.out.println("j_goodsList = " + j_goodsList);
// 3.获取J_goodsList ul 每一个 li
Elements lis = j_goodsList.getElementsByTag("li");
// 4.获取li下的 img、price、name
for (Element li : lis) {
// 关于图片特别多的网站,所有图片都是延时加载的!
// source-data-lazy-img
String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img");// 获取li下 第一张图片
String name = li.getElementsByClass("p-name").eq(0).text();
String price = li.getElementsByClass("p-price").eq(0).text();
System.out.println("=======================");
System.out.println("img : " + img);
System.out.println("name : " + name);
System.out.println("price : " + price);
}
new HtmlParseUtil().parseJD("python").forEach(System.out::println);
//注意中文不能,需要转义
}
}
审查页面元素
页面列表id:J_goodsList
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uyUedA3u-1629335862729)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802162828751.png)]
目标元素:img、price、name
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-deXYOjVl-1629335862730)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802163134611.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k15QMQUH-1629335862731)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802163348154.png)]
原因是啥?
一般图片特别多的网站,所有的图片都是通过延迟加载的
// 打印标签内容
Elements lis = j_goodsList.getElementsByTag("li");
System.out.println(lis);
打印所有li标签,发现img标签中并没有属性src的设置,只是data-lazy-ing设置图片加载的地址

创建HtmlParseUtil、改写
- 更改图片获取属性为
data-lazy-img
- 与实体类结合,实体类如下
封装为方法
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keywords) throws IOException {
//获取请求
// 使用前需要联网
// 请求url
String url="https://search.jd.com/Search?keyword="+keywords;
// 1.解析网页(jsoup 解析返回的对象是浏览器Document对象)
Document document = Jsoup.parse(new URL(url), 30000);
// 使用document可以使用在js对document的所有操作
// 2.获取元素(通过id)
Element j_goodsList = document.getElementById("J_goodsList");
//System.out.println("j_goodsList = " + j_goodsList);
// 3.获取J_goodsList ul 每一个 li
Elements lis = j_goodsList.getElementsByTag("li");
ArrayList<Content> goodList = new ArrayList<>();
// 4.获取li下的 img、price、name
for (Element li : lis) {
// 关于图片特别多的网站,所有图片都是延时加载的!
// source-data-lazy-img
String img = li.getElementsByTag("img").eq(0).attr("data-lazy-img");// 获取li下 第一张图片
String title = li.getElementsByClass("p-name").eq(0).text();
String price = li.getElementsByClass("p-price").eq(0).text();
Content content=new Content();
content.setTitle(title);
content.setPrice(price);
content.setImg(img);
goodList.add(content);
}
return goodList;
}
}
service调用
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
/*// 不能直接使用 @Autowired 需要Spring容器
public static void main(String[] args) throws IOException {
new ContentService().parseContent("java");
}*/
// 1、解析数据放入es索引中
public Boolean parseContent(String keywords) throws IOException {
List<Content> contents=new HtmlParseUtil().parseJD(keywords);
//把查询的数据放入es中
BulkRequest bulkRequest=new BulkRequest();
bulkRequest.timeout("2m");
for (int i=0;i<contents.size();i++){
bulkRequest.add(new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
}
controller层
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyword) throws IOException {
System.out.println("keyword = " + keyword);
return contentService.parseContent(keyword);
}
通过接口调用后数据存入了es中
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Iw8v7cgu-1629335862731)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802184350581.png)]
分页
service层
// 2、获取这些数据实现搜索功能
public List<Map<String,Object>> searchPage(String keyword,int pageNo,int pageSize) throws IOException {
if (pageNo<=1){
pageNo=1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
//分页
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
//精准匹配关键字
TermQueryBuilder termQueryBuilder= QueryBuilders.termQuery("title",keyword);
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list=new ArrayList<>();
for (SearchHit documentFields:searchResponse.getHits()){
list.add(documentFields.getSourceAsMap());
}
return list;
}
controller层
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> parse(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
//if (pageNo==0)
//System.out.println(contentService.searchPage(keyword,pageNo,pageSize));
return contentService.searchPage(keyword,pageNo,pageSize);
}
效果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G0rNKStx-1629335862732)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802183431944.png)]
3、前后端分离(简单使用Vue)
载并引入Vue.min.js和axios.js
如果安装了nodejs,可以按如下步骤,没有可以到后面素材处下载
npm install vue
npm install axios
修改静态页面
引入js
<script th:src="@{/js/vue.min.js}"></script>
<script th:src="@{/js/axios.min.js}"></script>
修改后的index.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>狂神说Java-ES仿京东实战</title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
</head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<!-- 头部搜索 -->
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<!-- Logo-->
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
</h1>
<div class="header-extra">
<!--搜索-->
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>天猫搜索</legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<input v-model="keyword" type="text" autocomplete="off" value="dd" id="mq"
class="s-combobox-input" aria-haspopup="true">
</div>
</div>
<button type="submit" @click.prevent="searchKey" id="searchbtn">搜索</button>
</div>
</fieldset>
</form>
<ul class="relKeyTop">
<li><a>狂神说Java</a></li>
<li><a>狂神说前端</a></li>
<li><a>狂神说Linux</a></li>
<li><a>狂神说大数据</a></li>
<li><a>狂神聊理财</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<!-- 商品详情页面 -->
<div id="content">
<div class="main">
<!-- 品牌分类 -->
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
品牌
</div>
<div class="attrValues">
<ul class="av-collapse row-2">
<li><a href="#"> 狂神说 </a></li>
<li><a href="#"> Java </a></li>
</ul>
</div>
</div>
</div>
</div>
</form>
<!-- 排序规则 -->
<div class="filter clearfix">
<a class="fSort fSort-cur">综合<i class="f-ico-arrow-d"></i></a>
<a class="fSort">人气<i class="f-ico-arrow-d"></i></a>
<a class="fSort">新品<i class="f-ico-arrow-d"></i></a>
<a class="fSort">销量<i class="f-ico-arrow-d"></i></a>
<a class="fSort">价格<i class="f-ico-triangle-mt"></i><i class="f-ico-triangle-mb"></i></a>
</div>
<!-- 商品详情 -->
<div class="view grid-nosku">
<div class="product" v-for="result in results">
<div class="product-iWrap">
<!--商品封面-->
<div class="productImg-wrap">
<a class="productImg">
<img :src="result.img">
</a>
</div>
<!--价格-->
<p class="productPrice">
<em><b>¥</b>{{result.price}}</em>
</p>
<!--标题-->
<p class="productTitle">
<a v-html="result.title"></a>
</p>
<!-- 店铺名 -->
<div class="productShop">
<span>店铺: 狂神说Java </span>
</div>
<!-- 成交信息 -->
<p class="productStatus">
<span>月成交<em>999笔</em></span>
<span>评价 <a>3</a></span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<script th:src="@{/js/axios.min.js}"></script>
<script th:src="@{/js/vue.min.js}"></script>
<script>
new Vue({
el:"#app",
data:{
keyword:'', //搜素的关键字
results:[] //搜素的结果
},
methods:{
searchKey(){
let keyword = this.keyword;
console.log(keyword);
axios.get('search/'+keyword+'/0/10').then(response=>{
console.log(response.data);
this.results=response.data; //绑定数据
})
}
}
});
</script>
</body>
</html>
service(实现高亮)
//3、获取这些数据实现搜索高亮功能
public List<Map<String,Object>> searchPageHighlightBuilder(String keyword,int pageNo,int pageSize) throws IOException {
if (pageNo<=1){
pageNo=1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
//分页
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
//精准匹配关键字
TermQueryBuilder termQueryBuilder= QueryBuilders.termQuery("title",keyword);
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);// 多个高亮显示!
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
searchSourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list=new ArrayList<>();
for (SearchHit hit:searchResponse.getHits()){
Map<String, HighlightField> highlightFieldMap=hit.getHighlightFields();
HighlightField title=highlightFieldMap.get("title");
Map<String,Object> sourceAsMap=hit.getSourceAsMap(); //原来的结果
//解析高亮的字段,将原来的字段换为我们高亮的字段即可!
if (title!=null){
Text[] fragments=title.fragments();
String n_title="";
for (Text text : fragments) {
n_title+=text;
}
sourceAsMap.put("title",n_title); //高亮字段替换掉原来的内容即可!
}
list.add(sourceAsMap);
}
return list;
}
测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-twsWSJQH-1629335862733)(C:\Users\DELL\AppData\Roaming\Typora\typora-user-images\image-20210802195450860.png)]
if (pageNo<=1){
pageNo=1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
//分页
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
//精准匹配关键字
TermQueryBuilder termQueryBuilder= QueryBuilders.termQuery("title",keyword);
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);// 多个高亮显示!
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
searchSourceBuilder.highlighter(highlightBuilder);
//执行搜索
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
//解析结果
ArrayList<Map<String,Object>> list=new ArrayList<>();
for (SearchHit hit:searchResponse.getHits()){
Map<String, HighlightField> highlightFieldMap=hit.getHighlightFields();
HighlightField title=highlightFieldMap.get("title");
Map<String,Object> sourceAsMap=hit.getSourceAsMap(); //原来的结果
//解析高亮的字段,将原来的字段换为我们高亮的字段即可!
if (title!=null){
Text[] fragments=title.fragments();
String n_title="";
for (Text text : fragments) {
n_title+=text;
}
sourceAsMap.put("title",n_title); //高亮字段替换掉原来的内容即可!
}
list.add(sourceAsMap);
}
return list;
}
测试
[外链图片转存中...(img-twsWSJQH-1629335862733)]