目录
矩阵乘法
CPU方式
GPU方式
GPU中矩阵相乘步骤
GPU矩阵乘法代码示例
利用shared memory优化矩阵乘法
Share Memory矩阵乘法代码示例
矩阵乘法

CPU方式
利用三个for循环进行矩阵乘法
GPU方式
GPU中2维gird的线程索引
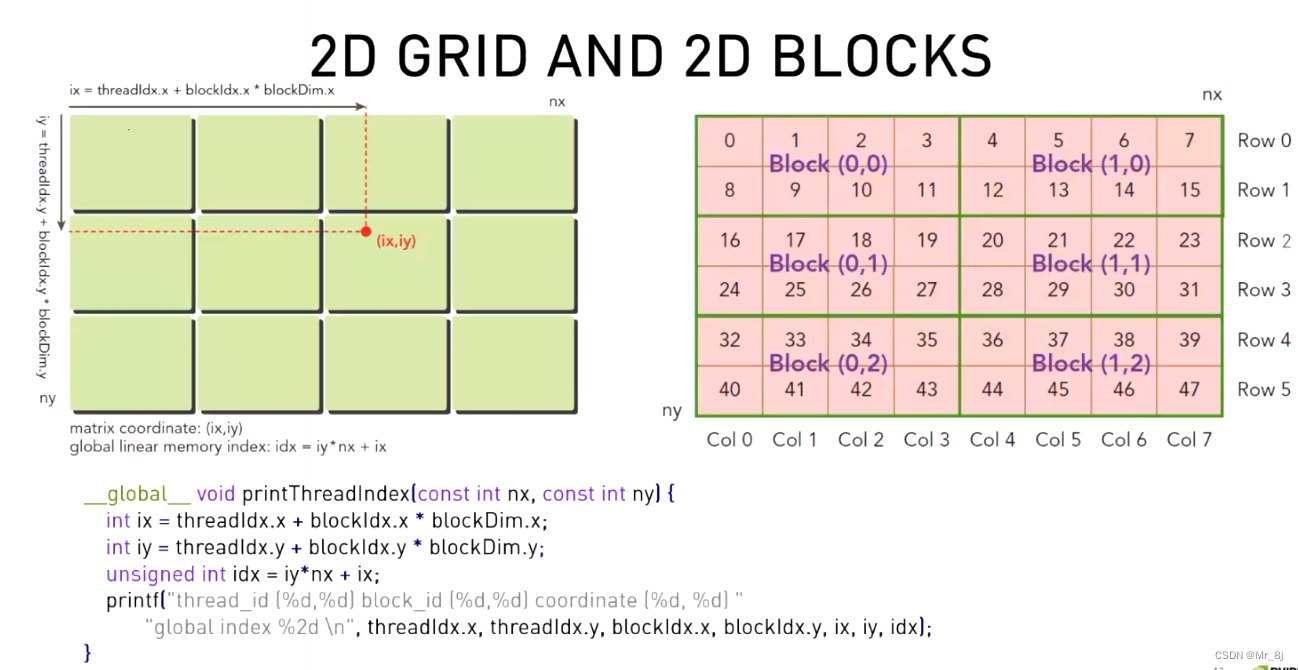
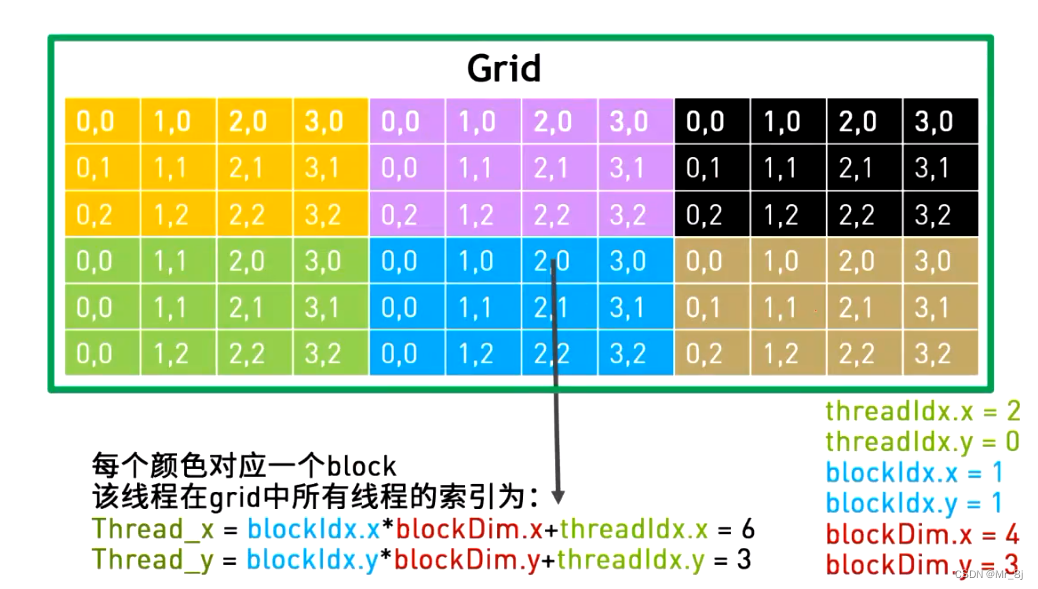
GPU中矩阵相乘步骤


通过并行计算,减少了两层for循环。
GPU矩阵乘法代码示例
#include <stdio.h>
#include <math.h>
#define BLOCK_SIZE 16
//二维矩阵乘法-GPU算法
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
//计算处当前执行的线程在所有线程中的坐标
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
//初始化不要忘记
int sum = 0;
//读取a矩阵的一行,b矩阵的一列,并做乘积累加
if( col < k && row < m)
{
//此处for循环是读取a矩阵每行的第i个数和b矩阵每列的第i个数
for(int i = 0; i < n; i++)
{
//a[所在行数 * a矩阵列的宽度(一行就几个元素) + 所在行的第几个 b[所在列的第几个(从0开始)*b矩阵列的宽度 + 所在列数]
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
//二维矩阵乘法-cpu基本for循环算法
void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) {
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
int tmp = 0.0;
for (int h = 0; h < n; ++h)
{
tmp += h_a[i * n + h] * h_b[h * k + j];
}
h_result[i * k + j] = tmp;
}
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
//申请主机cpu内存,这里等于普通的malloc()
int *h_a, *h_b, *h_c, *h_cc;
cudaMallocHost((void **) &h_a, sizeof(int)*m*n);
cudaMallocHost((void **) &h_b, sizeof(int)*n*k);
cudaMallocHost((void **) &h_c, sizeof(int)*m*k);
cudaMallocHost((void **) &h_cc, sizeof(int)*m*k);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
//申请GPU内存
int *d_a, *d_b, *d_c;
cudaMalloc((void **) &d_a, sizeof(int)*m*n);
cudaMalloc((void **) &d_b, sizeof(int)*n*k);
cudaMalloc((void **) &d_c, sizeof(int)*m*k);
// copy matrix A and B from host to device memory 从GPU拷贝数据到CPU
cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice);
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
//从CPU拷贝数据到GPU
cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost);
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory 释放内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
cudaFreeHost(h_cc);
return 0;
}
利用shared memory优化矩阵乘法

C = A * B,矩阵C第n行的每个元素都要读取矩阵A的第n行,矩阵C的第m列的每个元素都要读取矩阵B的第m列。
原来方法会多次从glabal memory读取同样的数据。但利用shared memory可以将global memory中的数据先存储到shared memory上,然后每次从shared memory上读取数据,加快速度。
shared memory优点是速度快,缺点是空间小。无法容纳大量数据。因此需要分多次读取。
步骤:
1、申请小块,小块进行滑动读取所有数据存储到shared memory中。
2、各个小块内部进行矩阵乘法。
3、再将各个小块矩阵乘法之后得到的数据累加。
思想:利用shared memory;将大矩阵拆分成小矩阵。 —— 分而治之

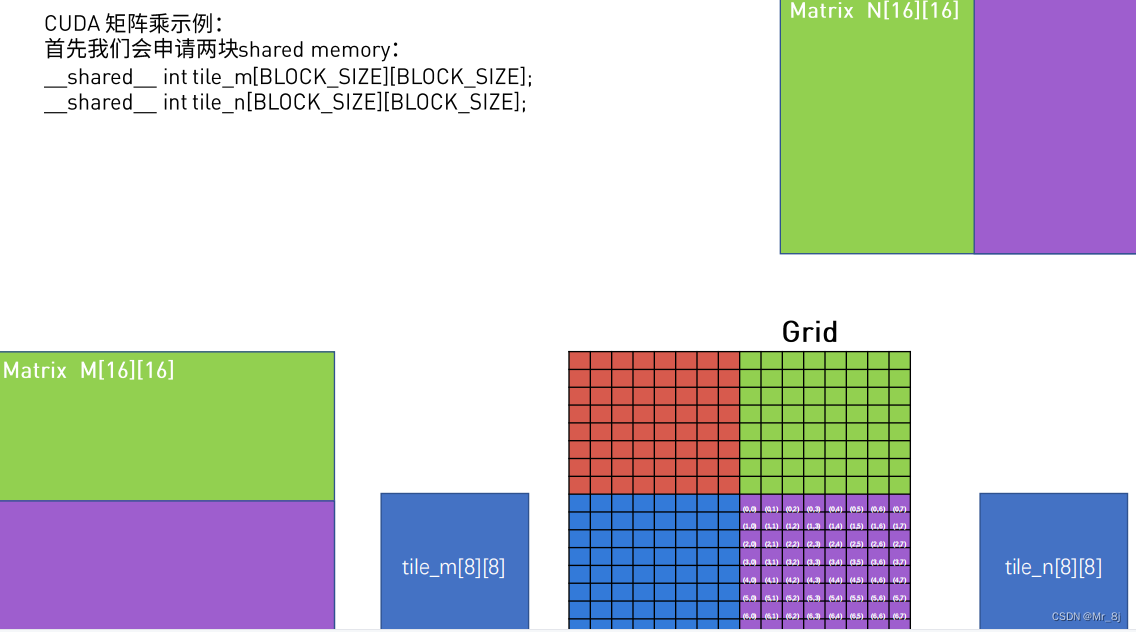
以sub=0为例子,sub=1同理。
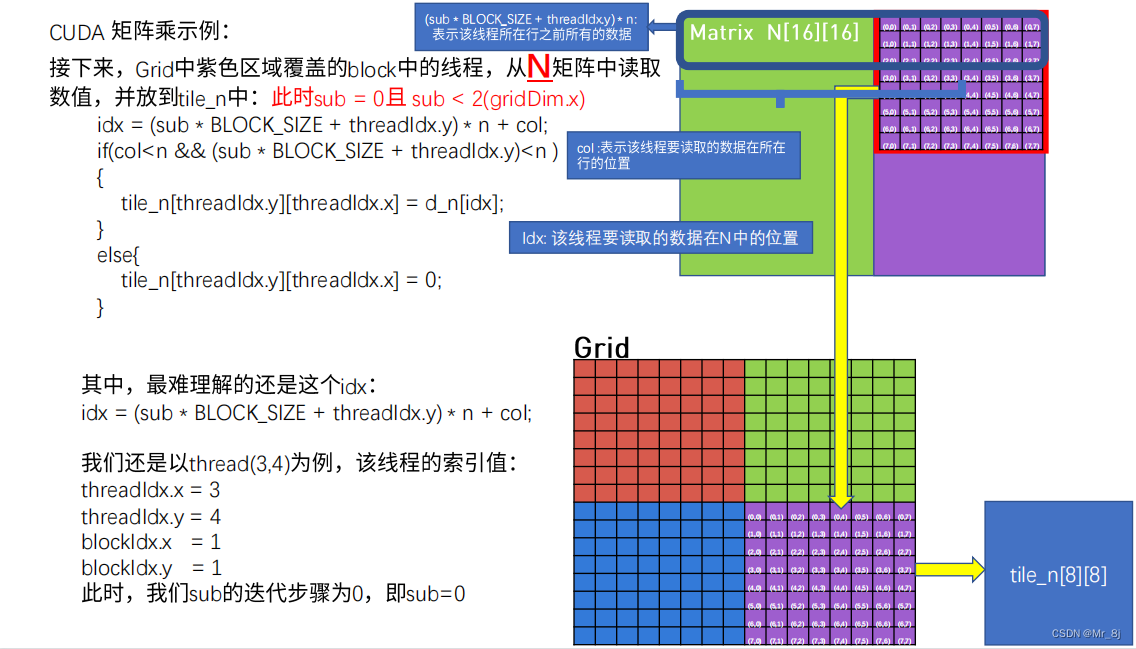


总结:


Share Memory矩阵乘法代码示例
#include <stdio.h>
#include <math.h>
#include "error.cuh"
#define BLOCK_SIZE 16
//普通GPU矩阵乘法运算
__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int sum = 0;
if( col < k && row < m)
{
for(int i = 0; i < n; i++)
{
sum += a[row * n + i] * b[i * k + col];
}
c[row * k + col] = sum;
}
}
//利用shared memory矩阵乘法运算
__global__ void gpu_matrix_mult_shared_memory(int *d_m, int *d_n, int *d_result, int n)
{
__shared__ int tile_m[BLOCK_SIZE ][BLOCK_SIZE ]; //BLOCK_SIZE 是行数或列数
__shared__ int tile_n[BLOCK_SIZE ][BLOCK_SIZE ];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 0;
int tmp = 0;
//将矩阵数据放入shared memory中(全局索引转为小块索引)
for(int sub = 0;sub<gridDim.x;sub++) //sub为滑动次数,滑动次数等于block x方向的个数,即gridDim.x
{
idx = row*n + sub*BLOCK_SIZE +threadIdx.x; //计算全局的index row*n代表该线程所在行之前行的所有数据 sub*BLOCK_SIZE +threadIdx.x表示该线程要读的数据(用小块索引)在所在行中的位置
if(row<n && (sub*BLOCK_SIZE +threadIdx.x) < n) //保证 矩阵的x坐标小于矩阵x方向维度,滑动之后x坐标小于矩形x方向维度
{
tile_m[threadIdx.y][threadIdx.x] = d_m[idx];//将数据放入小块中,按小块进行索引
}
else
{
tile_m[threadIdx.y][threadIdx.x] = 0; //若不满足if条件,小块中置0
}
idx = (sub*BLOCK_SIZE + threadIdx.y)*n + col; //N矩阵idx全局索引计算
if(col<n && (sub * BLOCK_SIZE +threadIdx.y)<n) //保证y方向坐标不超过整个矩阵y向坐标
{
tile_n[threadIdx.y][threadIdx.x] = d_n[idx];
}
else
{
tile_n[threadIdx.y][threadIdx.x] = 0;
}
__syncthreads(); //同步等待所有线程都完成
for(int k = 0;k<BLOCK_SIZE ;k++)
{
tmp += tile_m[threadIdx.y][k] * tile_n[k][threadIdx.x];//tmp一直存在,一直累加,直到所有线程都完成计算
}
__syncthreads(); //同步等待所有线程都完成
}
if(row < n && col <n)
{
d_result[row*n + col] = tmp;
}
}
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_c_shared;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_c_shared, sizeof(int)*m*k));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c,*d_c_shared;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
CHECK(cudaMalloc((void **) &d_c_shared, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaMemcpy(h_c, d_c, sizeof(int)*m*k, cudaMemcpyDeviceToHost));
gpu_matrix_mult_shared_memory<<<dimGrid, dimBlock>>>(d_a, d_b, d_c_shared, n);
CHECK(cudaMemcpy(h_c_shared, d_c_shared, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_c_shared[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFree(d_c_shared));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
CHECK(cudaFreeHost(h_c_shared));
return 0;
}