神经网络学习小记录51——Keras搭建孪生神经网络(Siamese network)比较图片相似性
学习前言
最近学习了一下如何比较两张图片的相似性,用到了孪生神经网络,一起来学习一下。

什么是孪生神经网络
简单来说,孪生神经网络(Siamese network)就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
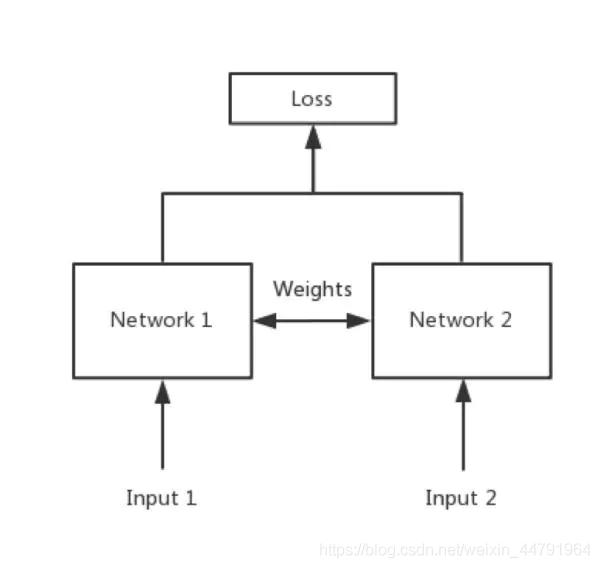
所谓权值共享就是当神经网络有两个输入的时候,这两个输入使用的神经网络的权值是共享的(可以理解为使用了同一个神经网络)。
很多时候,我们需要去评判两张图片的相似性,比如比较两张人脸的相似性,我们可以很自然的想到去提取这个图片的特征再进行比较,自然而然的,我们又可以想到利用神经网络进行特征提取。
如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。这个时候我们就可以理解孪生神经网络为什么要进行权值共享了。
孪生神经网络有两个输入(Input1 and Input2),利用神经网络将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
代码下载
https://github.com/bubbliiiing/Siamese-keras
孪生神经网络的实现思路
一、预测部分
1、主干网络介绍

孪生神经网络的主干特征提取网络的功能是进行特征提取,各种神经网络都可以适用,本文使用的神经网络是VGG16。
关于VGG的介绍大家可以看我的另外一篇博客https://blog.csdn.net/weixin_44791964/article/details/102779878
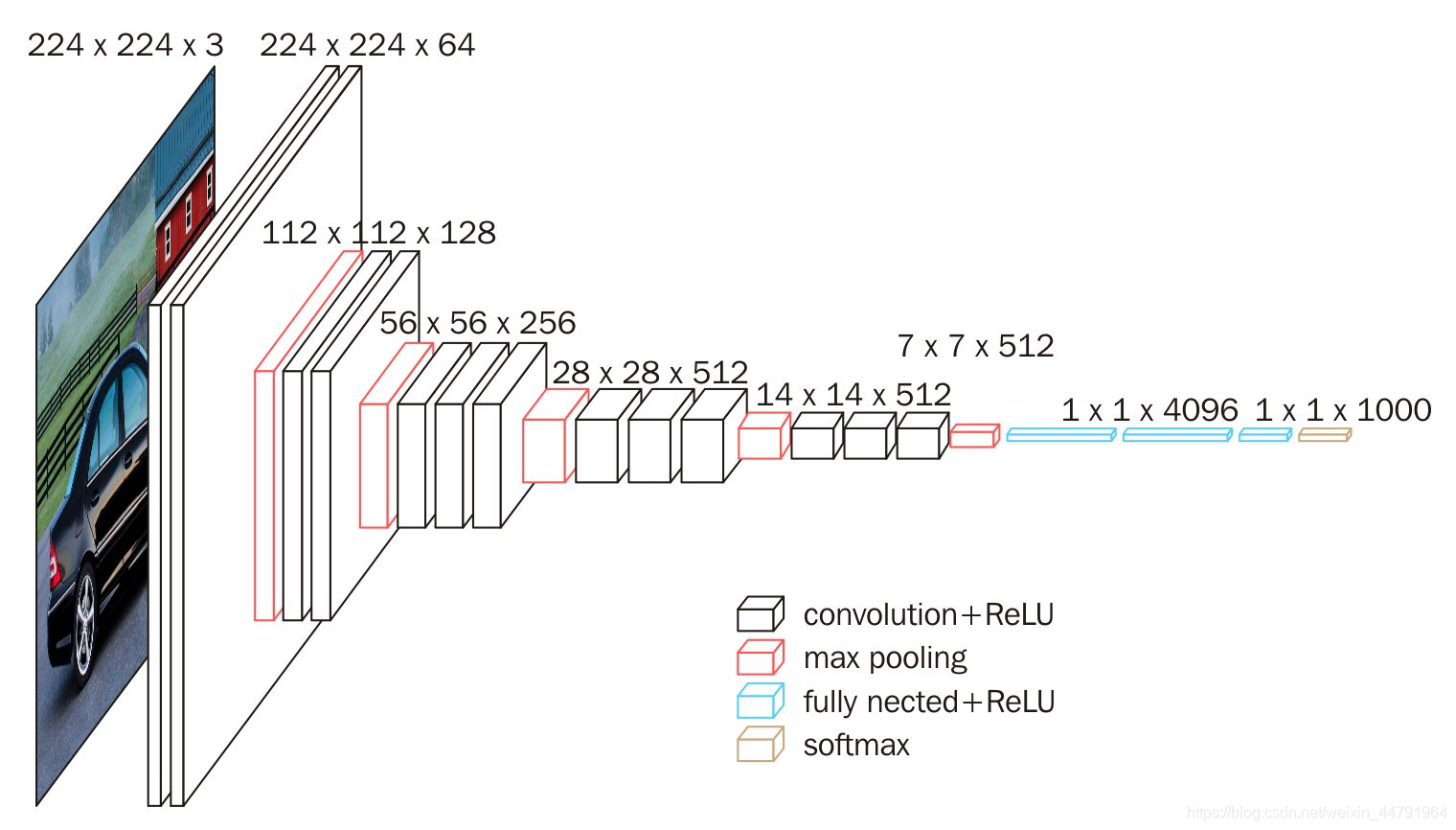
这是一个VGG被用到烂的图,但确实很好的反应了VGG的结构:
1、一张原始图片被resize到指定大小,本文使用105x105。
2、conv1包括两次[3,3]卷积网络,一次2X2最大池化,输出的特征层为64通道。
3、conv2包括两次[3,3]卷积网络,一次2X2最大池化,输出的特征层为128通道。
4、conv3包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为256通道。
5、conv4包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为512通道。
6、conv5包括三次[3,3]卷积网络,一次2X2最大池化,输出的特征层为512通道。
实现代码为:
import keras
from keras.layers import Input,Dense,Conv2D
from keras.layers import MaxPooling2D,Flatten
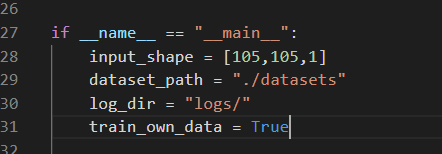
from keras.models import Model
import os
import numpy as np
from PIL import Image
from keras.optimizers import SGD
class VGG16:
def __init__(self):
self.block1_conv1 = Conv2D(64,(3,3),activation = 'relu',padding = 'same',name = 'block1_conv1')
self.block1_conv2 = Conv2D(64,(3,3),activation = 'relu',padding = 'same', name = 'block1_conv2')
self.block1_pool = MaxPooling2D((2,2), strides = (2,2), name = 'block1_pool')
self.block2_conv1 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv1')
self.block2_conv2 = Conv2D(128,(3,3),activation = 'relu',padding = 'same',name = 'block2_conv2')
self.block2_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block2_pool')
self.block3_conv1 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv1')
self.block3_conv2 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv2')
self.block3_conv3 = Conv2D(256,(3,3),activation = 'relu',padding = 'same',name = 'block3_conv3')
self.block3_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block3_pool')
self.block4_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv1')
self.block4_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv2')
self.block4_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block4_conv3')
self.block4_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block4_pool')
# 第五个卷积部分
self.block5_conv1 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv1')
self.block5_conv2 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv2')
self.block5_conv3 = Conv2D(512,(3,3),activation = 'relu',padding = 'same', name = 'block5_conv3')
self.block5_pool = MaxPooling2D((2,2),strides = (2,2),name = 'block5_pool')
self.flatten = Flatten(name = 'flatten')
def call(self, inputs):
x = inputs
x = self.block1_conv1(x)
x = self.block1_conv2(x)
x = self.block1_pool(x)
x = self.block2_conv1(x)
x = self.block2_conv2(x)
x = self.block2_pool(x)
x = self.block3_conv1(x)
x = self.block3_conv2(x)
x = self.block3_conv3(x)
x = self.block3_pool(x)
x = self.block4_conv1(x)
x = self.block4_conv2(x)
x = self.block4_conv3(x)
x = self.block4_pool(x)
x = self.block5_conv1(x)
x = self.block5_conv2(x)
x = self.block5_conv3(x)
x = self.block5_pool(x)
outputs = self.flatten(x)
return outputs
2、比较网络
在获得主干特征提取网络之后,我们可以获取到一个多维特征,我们可以使用flatten的方式将其平铺到一维上,这个时候我们就可以获得两个输入的一维向量了
将这两个一维向量进行相减,再进行绝对值求和,相当于求取了两个特征向量插值的L1范数。也就相当于求取了两个一维向量的距离。
然后对这个距离再进行两次全连接,第二次全连接到一个神经元上,对这个神经元的结果取sigmoid,使其值在0-1之间,代表两个输入图片的相似程度。
实现代码如下:
import keras
from keras.layers import Input,Dense,Conv2D
from keras.layers import MaxPooling2D,Flatten,Lambda
from keras.models import Model
import keras.backend as K
import os
import numpy as np
from PIL import Image
from keras.optimizers import SGD
from nets.vgg import VGG16
def siamese(input_shape):
vgg_model = VGG16()
input_image_1 = Input(shape=input_shape)
input_image_2 = Input(shape=input_shape)
encoded_image_1 = vgg_model.call(input_image_1)
encoded_image_2 = vgg_model.call(input_image_2)
l1_distance_layer = Lambda(
lambda tensors: K.abs(tensors[0] - tensors[1]))
l1_distance = l1_distance_layer([encoded_image_1, encoded_image_2])
out = Dense(512,activation='relu')(l1_distance)
out = Dense(1,activation='sigmoid')(out)
model = Model([input_image_1,input_image_2],out)
return model
二、训练部分
1、数据集的格式
本文所使用的数据集为Omniglot数据集。
其包含来自 50不同字母(语言)的1623 个不同手写字符。每一个字符都是由 20个不同的人通过亚马逊的 Mechanical Turk 在线绘制的。
相当于每一个字符有20张图片,然后存在1623个不同的手写字符,我们需要利用神经网络进行学习,去区分这1623个不同的手写字符,比较输入进来的字符的相似性。
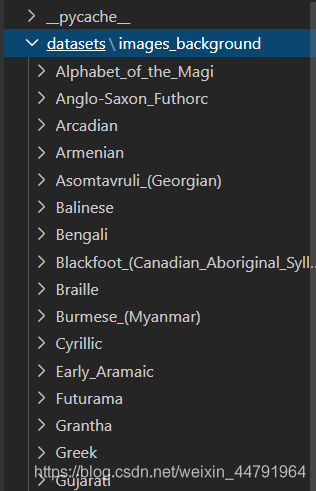
本博客中数据存放格式有三级:
- image_background
- Alphabet_of_the_Magi
- character01
- 0709_01.png
- 0709_02.png
- ……
- character02
- character03
- ……
- Anglo-Saxon_Futhorc
- ……
最后一级的文件夹用于分辨不同的字体,同一个文件夹里面的图片属于同一文字。在不同文件夹里面存放的图片属于不同文字。
上两个图为.\images_background\Alphabet_of_the_Magi\character01里的两幅图。它们两个属于同一个字。
上一个图为.\images_background\Alphabet_of_the_Magi\character02里的一幅图。它和上面另两幅图不属于同一个字。
2、Loss计算
对于孪生神经网络而言,其具有两个输入。
当两个输入指向同一个类型的图片时,此时标签为1。
当两个输入指向不同类型的图片时,此时标签为0。
然后将网络的输出结果和真实标签进行交叉熵运算,就可以作为最终的loss了。
本文所使用的Loss为binary_crossentropy。
当我们输入如下两个字体的时候,我们希望网络的输出为1。
我们会将预测结果和1求交叉熵。
当我们输入如下两个字体的时候,我们希望网络的输出为0。
我们会将预测结果和0求交叉熵。
训练自己的孪生神经网络
1、训练本文所使用的Omniglot例子

下载数据集,放在根目录下的dataset文件夹下。
运行train.py开始训练。

2、训练自己相似性比较的模型
如果大家想要训练自己的数据集,可以将数据集按照如下格式进行摆放。
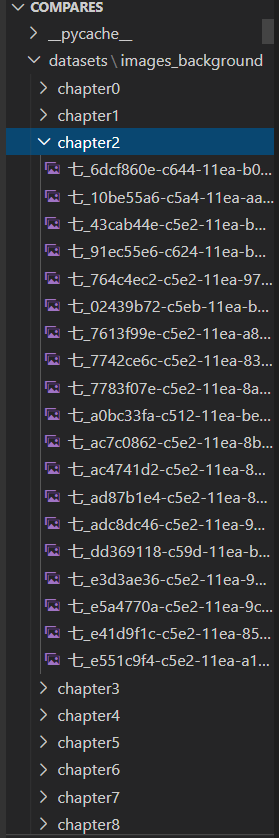
每一个chapter里面放同类型的图片。
之后将train.py当中的train_own_data设置成True,即可开始训练。