用
{
P
i
∣
i
=
1
,
⋅
⋅
⋅
,
n
}
\{P_i\vert i=1,\cdot\cdot\cdot,n\}
{Pi∣i=1,⋅⋅⋅,n}描述一个3D点云,其中每一个点
P
i
P_i
Pi都是一个向量。在本文中,除非特殊描述,其通道只包括位置信息
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)。
对于分类问题,网络输出对应
k
k
k个类别的
k
k
k个概率;对于分割问题,网络则输出所有
n
n
n个点对于所有
m
m
m个语义类别的的概率,即输出尺寸为
n
×
m
n\times m
n×m。
Deep Learning on Point Sets
网络结构的提出是受到了
R
n
\mathbb R^n
Rn内点云的性质的启发,因此第一部分介绍性质,第二部分介绍网络结构。
点云数据的性质
网络的输入是欧氏空间下的一个点的子集,因此具有下面三个主要性质:
无序性(Unordered):与像素点阵或三维点阵下排布的网格状数据不同,此时的点云是无序的。因此要求一个以
N
N
N个3D点为输入的网络需要对数据的
N
!
N!
N!排布具有不变性(invariant to
N
!
N!
N! permutations of the input set in data feeding order)。
点之间有关系(interaction among points):由于这些点是空间中一个有意义的子集里面按照某种距离矩阵生成的,这就要求网络要有能力识别这些相邻点之间的局部结构和这些结构的组合。
平移不变性(invariance under transformations):习得的点云描述应当对于某些变换鲁棒,比如在点云整体平移和旋转等变换下,网络对于点云的分割和分类结果不应当改变。
文中希望通过对变换后的元素应用对称函数,从而估计得到一个定义在点集上的一般函数(general function):
f
(
{
x
1
,
⋅
⋅
⋅
,
x
n
}
)
≈
g
(
h
(
x
1
)
,
⋅
⋅
⋅
,
h
(
x
n
)
)
(1)
f(\{x_1,\cdot\cdot\cdot,x_n\}) \approx g(h(x_1),\cdot\cdot\cdot,h(x_n)) \tag{1}
f({x1,⋅⋅⋅,xn})≈g(h(x1),⋅⋅⋅,h(xn))(1) 其中,
f
:
x
R
N
→
R
f:x^{\mathbb R^N} \to \mathbb R
f:xRN→R,
h
:
R
N
→
R
K
h: \mathbb R^N \to \mathbb R^K
h:RN→RK,对称函数
g
:
R
K
×
⋅
⋅
⋅
×
R
K
⏟
n
→
R
g:\underbrace {\mathbb R^K \times \cdot \cdot\cdot\times \mathbb R^K}_n\to \mathbb R
g:nRK×⋅⋅⋅×RK→R 。
文章通过实验确定的基本模型用多层感知机(multi-layer perceptron)习得
h
h
h,用一个单变量函数(single variable function)和max pooling函数习得
g
g
g。通过不同的
h
h
h,可以习得表征不同属性的多个
f
f
f。
博主注:
所谓多个
f
f
f:这里的理解就像当一组点具有某种不同属性时,其组成的整体也可以根据这些属性得到可能的属性。如大部分的点都是黑的,那么整体的颜色属性就是黑色;再如点与点之间存在某种位置关系,那么整体就是球形;以此类推……。而这里的
f
f
f就代表了不同考量下得到的属性结论,而
g
g
g要近似的也是这种结论,只不过
g
g
g并非直接考量输入的各个点,而是这些点经过
h
h
h处理后的体现。这就使得不同的
h
h
h处理出来经过相同的考量,也会对应不同的属性结论,即不同的
f
f
f。
为什么可以有这个近似:因为如果直接以原始点为输入,那么对于点的排序就有要求。而通过之前的分析,是很难找到一种方法使得结果不受顺序的影响。而这里用于近似的函数
g
g
g是一个对称函数,也就是其不考虑输入的顺序,只要保证需要的输入都进来了,就可以了。然而,在原始特征空间下,这种不考虑顺序的行为是无法实现的,因此需要一种映射,将原始数据映射到一个新的空间,使得在该空间下,数据的顺序(相互之间的关系)已经以某种形式表征出来,从而使得接下来的操作不需要考虑顺序。
局部和全局信息整合(Local and Global Information Aggregation)
上面一步的输出是一个表征了全局特征的向量
[
f
1
,
⋅
⋅
⋅
,
f
K
]
[f_1,\cdot\cdot\cdot,f_K]
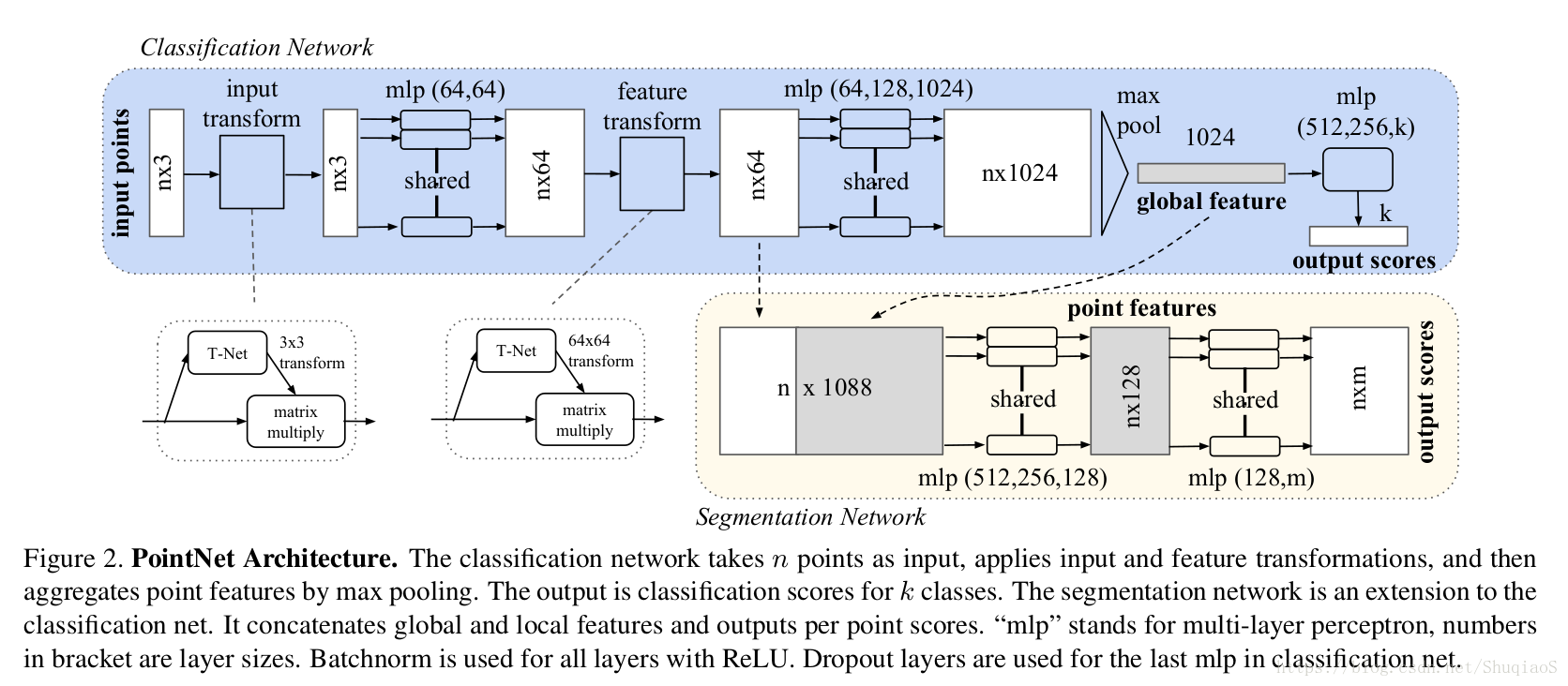
[f1,⋅⋅⋅,fK]。对于分类问题,可以直接训练一个SVM或多层感知机分类器,用于在给定全局特征向量的基础上判断类别(比如黑色、球体等等得到“眼睛”);但是对于点的分割问题,就需要统筹考虑全局和局部特征了。文章的做法是将获得的全局特征级联在每个点的局部特征后面(如上图中分割部分所示),在此基础上再学习得到新的点局部特征,此时的每个点的特征就既包含局部特征(局部几何信息)又包含全局特征(全局语义)了。
同样的思想也可以用于特征空间,即用于整合不同点云得到的特征。然而,由于特征空间下的变换矩阵维度要远远高于原始空间,为了降低最优化的难度,文章作者在softmax训练损失的基础上加了一个正则项:
L
r
e
g
=
∥
I
−
A
A
T
∥
F
2
L_{reg}=\Vert I-AA^T\Vert _F^2
Lreg=∥I−AAT∥F2 其中
A
A
A是迷你网络习得的特征整合矩阵。该正则项要求学习得到的矩阵是正交矩阵,因为正交变换不会丢失输入的信息。
这里文章作者证明了网络拟合任意连续函数的万能近似能力。直观上,由于集合函数(set function)的连续性,一个输入点集中的小扰动不太可能极大地改变函数的数值(如分类或分割score)。正式分析: 令
X
=
{
S
:
S
⊆
[
0
,
1
]
m
and
∣
S
∣
=
n
}
\mathcal X=\{S:S \subseteq [0,1]^m \text{and}\vert S\vert=n\}
X={S:S⊆[0,1]mand∣S∣=n},
f
:
X
→
R
f:\mathcal X \to \mathbb R
f:X→R是一个
X
\mathcal X
X上对Hausdroff距离
d
H
(
⋅
,
⋅
)
d_H(\cdot,\cdot)
dH(⋅,⋅)连续的集合函数,即
∀
ϵ
>
0
\forall\epsilon\gt 0
∀ϵ>0,
∃
δ
>
0
\exists\delta\gt 0
∃δ>0使得对于任意
S
,
S
′
∈
X
S,S'\in \mathcal X
S,S′∈X,若
d
H
(
S
,
S
′
)
<
δ
d_H(S,S')\lt\delta
dH(S,S′)<δ,都有
∣
f
(
S
)
−
f
(
S
′
)
∣
<
ϵ
\vert f(S) - f(S') \vert \lt \epsilon
∣f(S)−f(S′)∣<ϵ。下面的理论证明,只要max pooling层输入的神经元个数足够多(也就是公式(1)中的
K
K
K足够大),PointNet神经网络就可以随机近似任意
f
f
f。
Theorem 1.假设
f
:
X
→
R
f:\mathcal X \to \mathbb R
f:X→R是一个对于Hausdorff距离
d
H
(
⋅
,
⋅
)
d_H(\cdot,\cdot)
dH(⋅,⋅)连续的集合函数。
∀
ϵ
>
0
\forall\epsilon\gt 0
∀ϵ>0,
∃
\exists
∃一个连续函数
h
h
h和一个对称函数
g
(
x
1
,
⋅
⋅
⋅
,
x
n
)
=
γ
∘
M
A
X
g(x_1,\cdot\cdot\cdot,x_n)=\gamma \circ MAX
g(x1,⋅⋅⋅,xn)=γ∘MAX,使得对于任意
S
∈
X
S\in \mathcal X
S∈X有
∣
f
(
S
)
−
γ
(
M
A
X
x
i
∈
S
{
h
(
x
i
)
}
)
∣
<
ϵ
\left\vert f(S)-\gamma\left( \mathop{MAX}\limits_{x_i\in S} \{h(x_i)\}\right)\right\vert\lt\epsilon
∣∣∣∣f(S)−γ(xi∈SMAX{h(xi)})∣∣∣∣<ϵ 其中
x
1
,
⋅
⋅
⋅
,
x
n
x_1,\cdot\cdot\cdot,x_n
x1,⋅⋅⋅,xn是
S
S
S中所有元素的列表(随机排列),
γ
\gamma
γ是一个连续函数,
M
A
X
MAX
MAX是一个向量最大算子(输入
n
n
n个向量,其返回一个包含element-wise最大值的向量)。
博主注: 其中
∘
\circ
∘是映射乘法,也就是应用了映射
M
A
X
MAX
MAX后的结果再应用映射
γ
\gamma
γ。关于Theorem的证明可以在支撑材料中找到。
实验和理论标明,PointNet的表现严重受到max pooling层维度的影响(也就是公式(1)中的
K
K
K)。作者在这一部分给出了分析,同时也揭示了网络模型与稳定性相关的性质。
定义
u
\bf{u}
u
=
M
A
X
x
i
∈
S
{
h
(
x
i
)
}
=\mathop{MAX}\limits_{x_i\in S}\left\{h(x_i)\right\}
=xi∈SMAX{h(xi)}为
f
f
f的子网络,用于将
[
0
,
1
]
m
[0,1]^m
[0,1]m的点集映射成一个K维的向量。下面的定理证明了输入集合中的小扰动或多余的噪声点不太可能影响网络的结果:
Theorem 2.假设
u
\bf u
u
:
X
→
R
K
:\mathcal X \to \mathbb R^K
:X→RK且
u
\bf{u}
u
=
M
A
X
x
i
∈
S
{
h
(
x
i
)
}
=\mathop{MAX}\limits_{x_i\in S}\left\{h(x_i)\right\}
=xi∈SMAX{h(xi)},
f
=
γ
∘
u
f=\gamma\circ\bf{u}
f=γ∘u。那么:
(
a
)
∀
S
,
∃
C
S
,
N
S
⊆
X
,
f
(
T
)
=
f
(
S
)
i
f
C
S
⊆
T
⊆
N
S
;
(
b
)
∣
C
S
∣
≤
K
(a)\quad \forall S, \exists \mathcal C_S, \mathcal N_S\subseteq \mathcal X, f(T)=f(S) if \mathcal C_S\subseteq T \subseteq N_S;\\ (b) \quad \vert\mathcal C_S\vert \leq K
(a)∀S,∃CS,NS⊆X,f(T)=f(S)ifCS⊆T⊆NS;(b)∣CS∣≤K
上面的定理说明:(a)说明只要输入中存在的扰动没有影响到
C
S
\mathcal C_S
CS中的点,或者加入噪声点后不超过
N
S
\mathcal N_S
NS,那么
f
(
S
)
f(S)
f(S)就不变;(b)说明
C
S
\mathcal C_S
CS只包含有限个点,且点的个数由公式(1)中的
K
K
K决定。总的说来,也就是
f
(
S
)
f(S)
f(S)实际上完全由一个有限的子集
C
S
⊆
S
\mathcal C_S\subseteq S
CS⊆S决定,且子集中元素的个数不超过
K
K
K个。
因此,称
C
S
\mathcal C_S
CS是
S
S
S的关键点集,
K
K
K是
f
f
f的瓶颈维度(bottleneck dimension)。
结合
h
h
h的连续性,就可以解释模型对于点的扰动、损坏、额外噪声点的鲁棒性(参考机器学习中的稀疏性原理)。直观上来看,网络学习了如何通过一组稀疏的关键点组成的集合总结一个形状。实验标明,这组关键点恰好组成了一个目标的骨架。
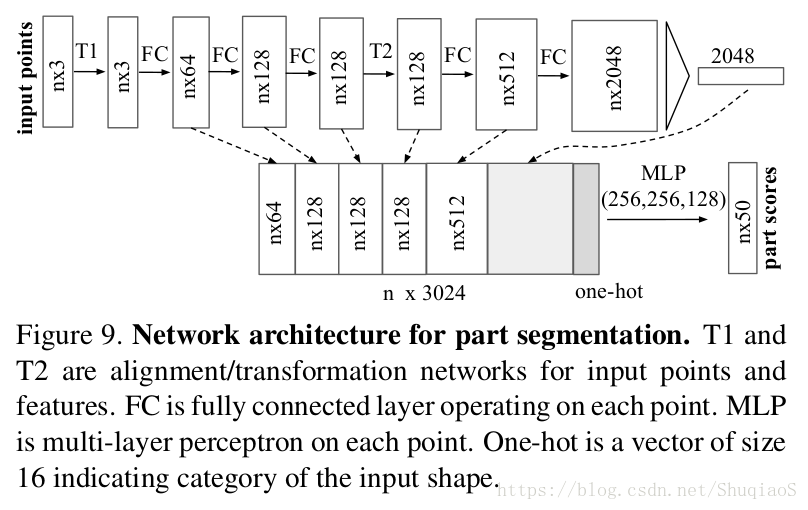
对于形状部分分割任务(shape part segmentation),作者对基础网络结构做了一定的调整以实现更好的结果。他们增加了一个one-hot向量(指示输入的类别)并将其与max pooling层的输出级联。他们还增加了某些层的神经元个数和skip links以获取不同层对应的特征,并将这些特征级联作为分割网络的输入。具体网络结构如下图所示。