答案仅供参考
1.数据预处理
给定数据集datingTest
实验任务:
读取DatingTest的数据文件,
(1)并输出第一列数据的最大、最小和均值
(2)输出该文件有多少数据
(3)计算第一条数据和第二条数据的欧式距离。
import pandas as pd
print("读取文件")
df=pd.read_csv('datingTestSet.txt',sep='\t',header=None,names=['x','y','z','s'])
print(df)
x=df['x']
print("1.第一列的最大值,最小值,均值")
print(x.max())
print(x.min())
print(x.mean())
print("2.文件有多少条数据")
print(len(df))
x1=df['x'][0]
x2=df['x'][1]
y1=df['y'][0]
y2=df['y'][1]
z1=df['z'][0]
z2=df['z'][1]
print("3.第一条数据第二条数据的欧氏距离")
sum=math.sqrt(math.pow(x2-x1,2)+math.pow(y1-y2,2)+math.pow(z2-z1,2))
print(sum)

2.数据清理
(1)对DatingTestSet分别进行最大最小标准化,和Z-socre标准化。
(2)计算第一行数据和每行数据的欧式距离
(3)以数据的行数为横坐标,以(2)计算的距离为纵坐标,画出每行数据和第一条数据的距离散点图。
from sklearn import preprocessing
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
print("读取文件:")
df=pd.read_csv('datingTestSet.txt',sep='\t',header=None,names=['x','y','z','s'])
print(df)
print("最大最小标准化:")
print("系统")
x=df.values
scaler=preprocessing.MinMaxScaler()
x=np.delete(x,3,axis=1)
print(x)
print("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~")
scaler.fit(x)
x=scaler.transform(x)
print(x)
print("自己")
data=pd.read_table('datingTestSet.txt',sep='\t',header=None)
tablen=data.iloc[:,:3]
themax=(tablen-tablen.min())/(tablen.max()-tablen.min())
print(themax)
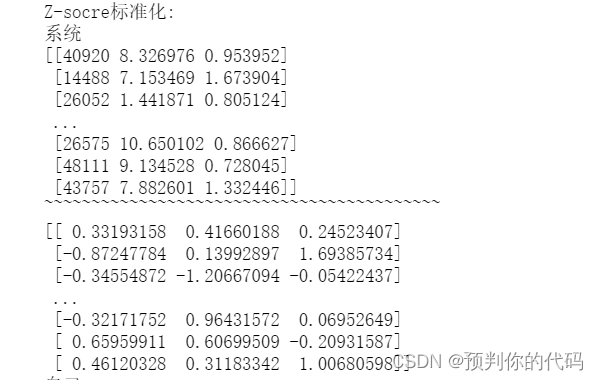
print("Z-socre标准化:")
print("系统")
x=df.values
scaler=preprocessing.StandardScaler()
x=np.delete(x,3,axis=1)
print(x)
print("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~")
scaler.fit(x)
x=scaler.transform(x)
print(x)
print("自己")
thesocre=(tablen-tablen.mean())/(tablen.std())
print(thesocre)
print("计算第一行数据和每行数据的欧式距离")
dis=[]
x=df.values
x=np.delete(x,3,axis=1)
for i in range(len(x)):
distance=np.sqrt(np.sum(np.square(x[i]-x[0])))
dis.append(distance)
print(dis)
index=np.argsort(dis)
print(index[1])
print("离散图:")
x=np.arange(0,1000)
y=np.array(dis)[x]
plt.title("t")
plt.xlabel("x")
plt.ylabel("y")
plt.plot(x,y,"ob")
plt.show()





3.KNN
1、生成模拟数据集(可以生成多个特征)
2、定义KNN模型(可以采用欧式距离或者曼哈顿距离)
3、给定待预测的对象,能够进行分类
import numpy as np
import pandas as pd
#生成模拟数据
data =np.random.randint(1,100,size=60)
data=pd.DataFrame(data.reshape((30,2)))
x=data.values
y=np.random.randint(1,4,size=30)
#定义KNN模型
def classify(inx,dataSet,labels,k):
diffMat=dataSet-inx
sqDiffMat=np.square(diffMat)
sqDistances=np.sum(sqDiffMat,axis=1)
distances =np.sqrt(sqDistances)
sortedDistindicies=distances.argsort()
classCount={}
for i in range(k):
voteLabel=labels[sortedDistindicies[i]]
classCount[voteLabel]=classCount.get(voteLabel,0)+1
sortedClassCount=sorted(classCount.items(),key=lambda x:x[1],reverse=True)
return sortedClassCount[0][0]
#给出预测对象,进行分类
print(classify([1,1],x,y,3))
print(classify([20,35],x,y,3))
print(classify([2,35],x,y,3))
print(classify([20,90],x,y,3))
print(classify([99,70],x,y,3))

4.KNN回归分析
(1)用sklearn数据集中有波士顿房价数据集,具体参考:
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
该数据集共506条给出了每个房子的13种特征,及房子对应的价格。测试数据比例设置为0.1,请采用KNN回归预测测试集房子的价格,并计算其均方误差.
(2)分析sklearn数据集diabetes,输出糖尿病数据集的样本数、特征数、将测试数据比例设为0.1,采用KNN回归模型进行预测,并计算其均方误差
要求:
(1)调用sklearn模型进行数据集的划分和数据的预测
(2)调用.DESCR属性输出有关数据集的描述,并显示前条数据
(3)利用测试集数据计算模型预测的均方误差
(4)上传源代码及截图
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn import metrics
from sklearn.metrics import classification_report
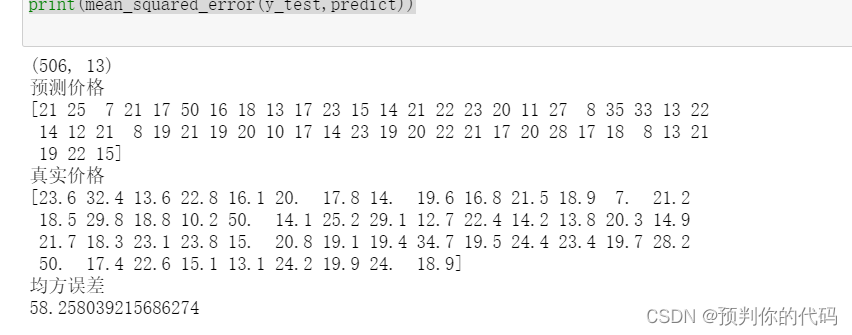
boston=datasets.load_boston()
print(boston.data.shape)
x=boston.data
y=boston.target
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.1,random_state=42)
knn=KNeighborsClassifier()
knn.fit(X_train, y_train.astype('int'))
predict=knn.predict(X_test)
print("预测价格")
print(predict)
print("真实价格")
print(y_test)
print("均方误差")
print(mean_squared_error(y_test,predict))
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
#from sklearn.metrics import mean_squared_error
from sklearn import metrics
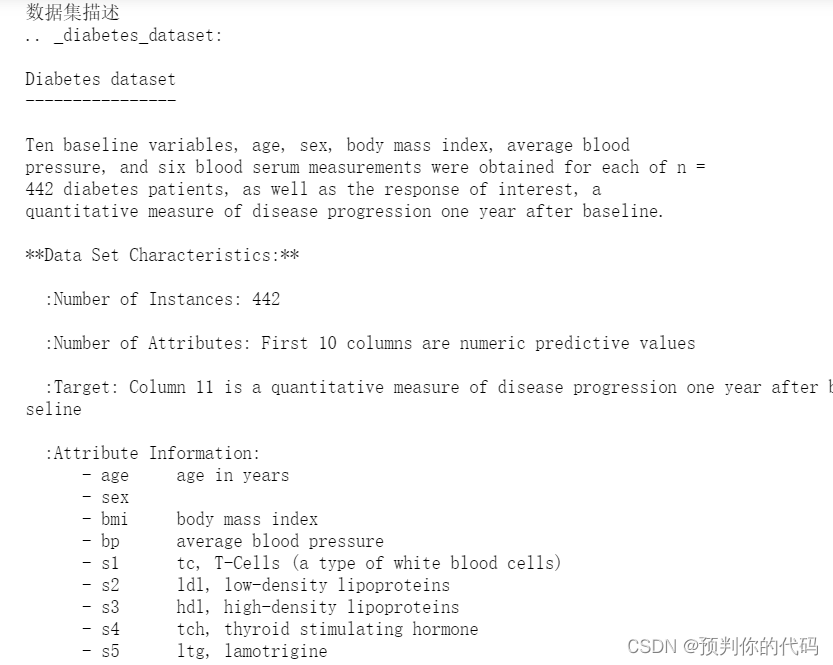
diabetes=datasets.load_diabetes()
print("数据集描述")
print(diabetes.DESCR)
print("样本数,特征数")
print(diabetes.data.shape)
print("前10个数据显示")
print(diabetes.data[:10])
x=diabetes.data
y=diabetes.target
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.1,random_state=42)
knn=KNeighborsClassifier()
knn.fit(X_train,y_train)
predict=knn.predict(X_test)
print("预测价格")
print(predict)
print("真实价格")
print(y_test)
print("均方误差")
print(mean_squared_error(y_test,predict))


5.朴素贝叶斯实验
用决策树模型与朴素贝叶斯对DatingTestSet数据集建模,测试数据比例设置为0.2,并与KNN分类的结果进行比较。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import BernoulliNB
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import LabelEncoder
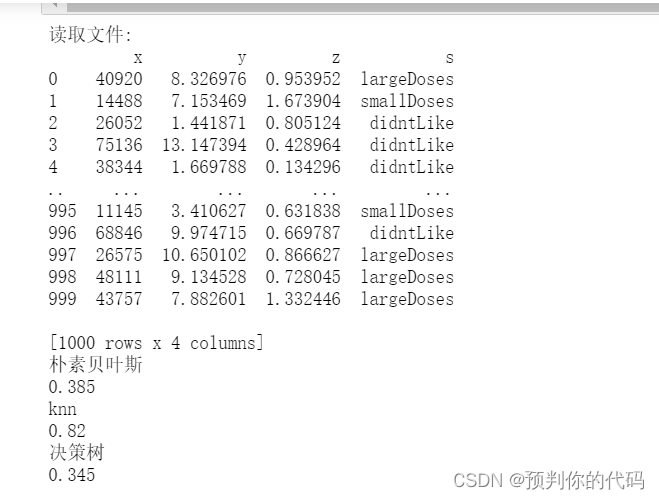
print("读取文件:")
df=pd.read_csv('datingTestSet.txt',sep='\t',header=None,names=['x','y','z','s'])
print(df)
data=df.values
X=data[:,:3]
y=data[:,-1]
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=4,test_size=0.2)
print("朴素贝叶斯")
nb=BernoulliNB()
nb.fit(X_train,y_train)
y_pred=nb.predict(X_test)
acc1=metrics.accuracy_score(y_pred=y_pred,y_true=y_test)
print(acc1)
print("knn")
knn=KNeighborsClassifier()
knn.fit(X_train,y_train)
pred=knn.predict(X_test)
acc2=metrics.accuracy_score(y_pred=pred,y_true=y_test)
print(acc2)
print("决策树")
dcr=DecisionTreeClassifier()
dcr.fit(X_train,y_train)
y_predict=clf.predict(X_test)
acc3=metrics.accuracy_score(y_pred=y_predict,y_true=y_test)
print(acc3)
6.线性回归模型
用sklearn数据集中有波士顿房价数据集,具体参考:
该数据集共506条给出了每个房子的13种特征,及房子对应的价格。测试数据比例设置为0.2
要求:
(1)调用sklearn模型进行数据集的划分和数据的预测
(2)调用.DESCR属性输出有关数据集的描述,并显示前条数据
(3)采用KNN回归模型预测房子价格,计算R2系数
(4)采用线性回归模型预测房子价格,计算R2系数
(5)采用决策树回归模型预测房屋价格,计算R2系数
(6)对比分析R2值的不同,试着尝试选定数据中几个特征再对房屋价格进行预测,并分析R2系数
(6)上传源代码及截图
from sklearn.neighbors import KNeighborsRegressor
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn import datasets
boston=datasets.load_boston()
X=boston.data
y=boston.target
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=1)
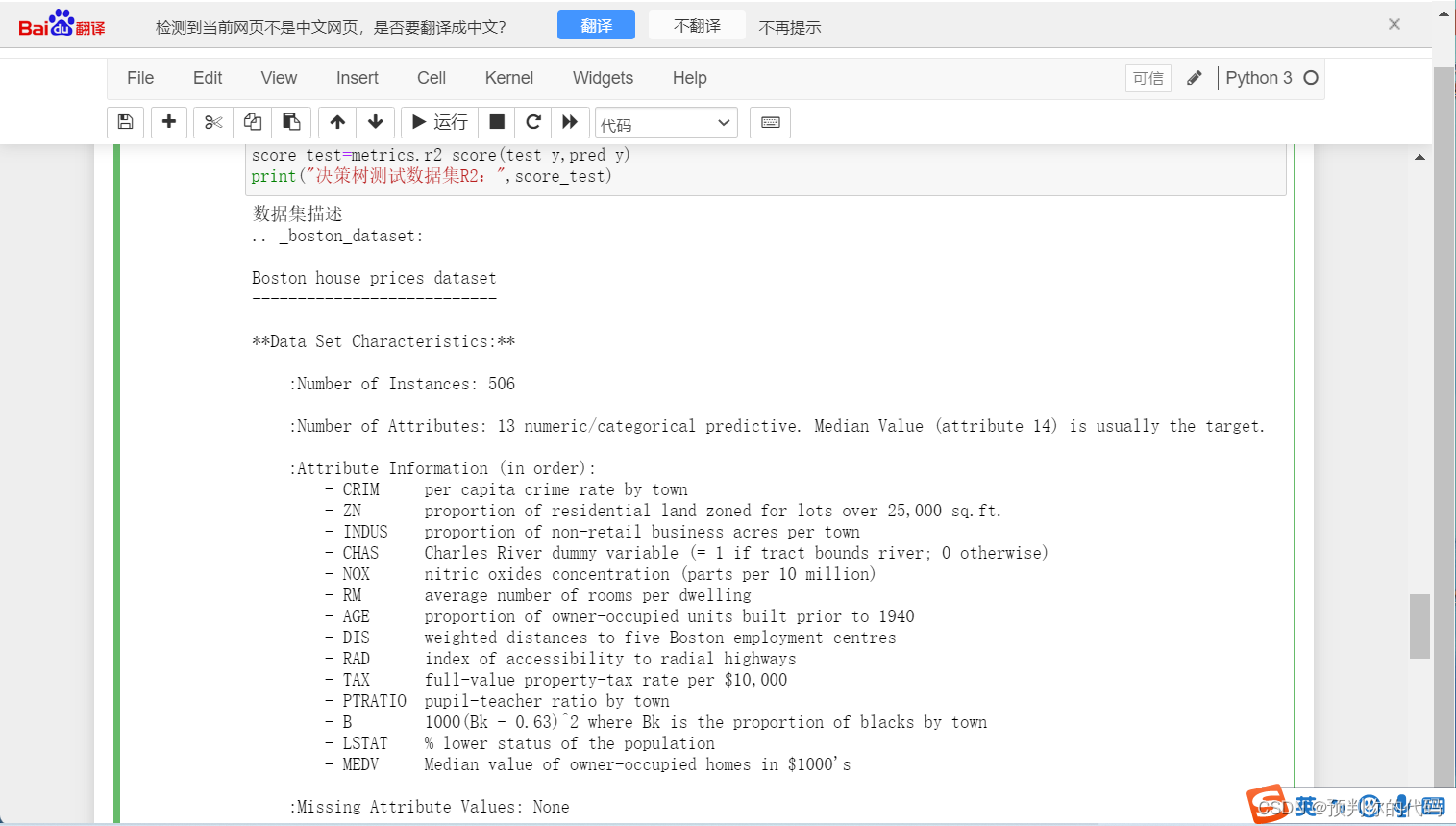
print("数据集描述")
print(boston.DESCR)
print("显示前五条数据")
print(boston.data[:5])
print("KNN:")
knn=KNeighborsRegressor()
knn.fit(train_X,train_y)
pre_y=knn.predict(test_X)
print("第一条测试数据的预测输出:",pred_y[0],"真实值",test_y[50])
score_test=metrics.r2_score(test_y,pre_y)
print("KNN测试数据集R2:",score_test)
print("线性回归:")
Ir=LinearRegression()
Ir.fit(train_X,train_y)
pred_y=Ir.predict(test_X)
print("第一条测试数据的预测输出:",pred_y[0],"真实值",test_y[50])
score_test=metrics.r2_score(test_y,pred_y)
print("线性回归测试数据集R2:",score_test)
print("决策树:")
dcr=DecisionTreeRegressor()
dcr.fit(train_X,train_y)
pred_y=dcr.predict(test_X)
print("第一条测试数据的预测输出:",pred_y[0],"真实值",test_y[50])
score_test=metrics.r2_score(test_y,pred_y)
print("决策树测试数据集R2:",score_test)
print("选定数据中4个特征再预测:")
X=X[:,:4]
print("knn:")
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=1)
knn=KNeighborsRegressor()
knn.fit(train_X,train_y)
pre_y=knn.predict(test_X)
print("第一条测试数据的预测输出:",pred_y[0],"真实值",test_y[50])
score_test=metrics.r2_score(test_y,pre_y)
print("KNN测试数据集R2:",score_test)
print("线性回归:")
Ir=LinearRegression()
Ir.fit(train_X,train_y)
pred_y=Ir.predict(test_X)
print("第一条测试数据的预测输出:",pred_y[0],"真实值",test_y[50])
score_test=metrics.r2_score(test_y,pred_y)
print("线性回归测试数据集R2:",score_test)
print("决策树:")
dcr=DecisionTreeRegressor()
dcr.fit(train_X,train_y)
pred_y=dcr.predict(test_X)
print("第一条测试数据的预测输出:",pred_y[0],"真实值",test_y[50])
score_test=metrics.r2_score(test_y,pred_y)
print("决策树测试数据集R2:",score_test)


7.决策树和随机森林
用sklearn数据集中有书写数字数据集进行分类学习。测试数据比例设置为0.2
要求:
(1)调用sklearn模型进行数据集的划分和数据的预测
(2)调用.DESCR属性输出有关数据集的描述,并显示前条数据
(3)采用KNN分类模型进行手写数字分类,计算分类准确率
(4)采用贝叶斯分类模型进行手写数字分类,计算分类准确率
(5)采用决策树模型进行手写数字分类,计算分类准确率
(6)采用随机森林进行手写数字分类,计算分类准确率
(7)采用逻辑回归进行手写数字分类,计算分类准确率。
(6)对比分析不同分类器的准确率值的不同,试着尝试改变模型的参数观察其对分类准确率的影响
(6)上传源代码及截图
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LogisticRegression
from sklearn import naive_bayes
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn import datasets
import warnings
warnings.filterwarnings("ignore")
digits=datasets.load_digits()
X=digits.data
y=digits.target
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=1)
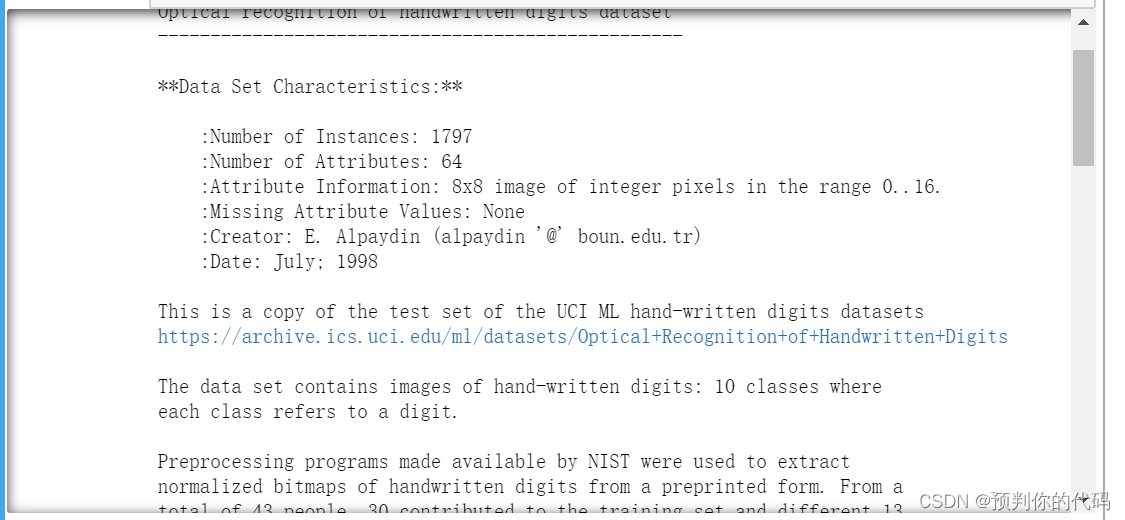
print(digits.DESCR)
print(digits.data[:5])
knn=KNeighborsRegressor()
knn.fit(train_X,train_y)
knn_score=knn.score(test_X,test_y)
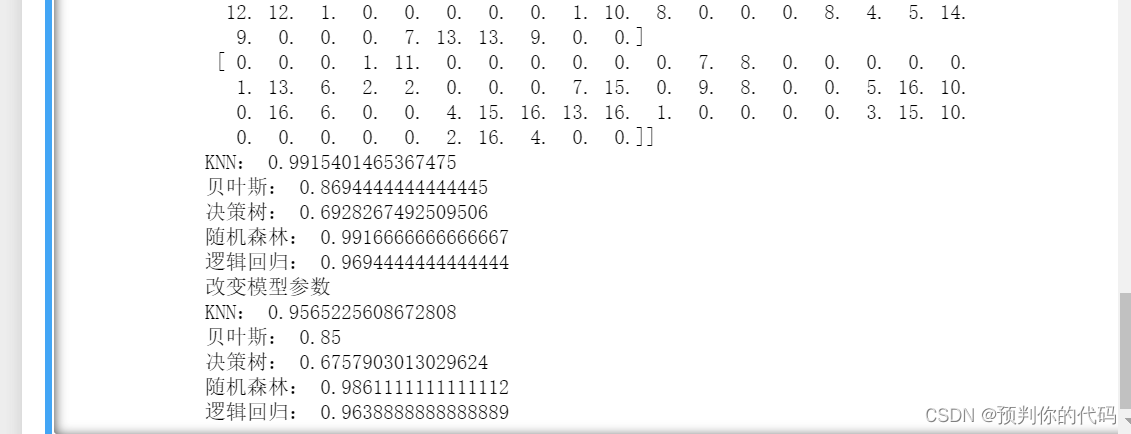
print("KNN:",knn_score)
nb=naive_bayes.BernoulliNB()
nb.fit(train_X,train_y)
nb_score=nb.score(test_X,test_y)
print("贝叶斯:",nb_score)
dcr=DecisionTreeRegressor()
dcr.fit(train_X,train_y)
dcr_score=dcr.score(test_X,test_y)
print("决策树:",dcr_score)
rf=RandomForestClassifier(n_estimators=100,criterion="entropy",n_jobs=4,oob_score=True)
rf.fit(train_X,train_y)
rf_score=rf.score(test_X,test_y)
print("随机森林:",rf_score)
lr=LogisticRegression()
lr.fit(train_X,train_y)
lr_score=lr.score(test_X,test_y)
print("逻辑回归:",lr_score)
print("改变模型参数")
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.2,random_state=4)
knn=KNeighborsRegressor()
knn.fit(train_X,train_y)
knn_score=knn.score(test_X,test_y)
print("KNN:",knn_score)
nb=naive_bayes.BernoulliNB()
nb.fit(train_X,train_y)
nb_score=nb.score(test_X,test_y)
print("贝叶斯:",nb_score)
dcr=DecisionTreeRegressor()
dcr.fit(train_X,train_y)
dcr_score=dcr.score(test_X,test_y)
print("决策树:",dcr_score)
rf=RandomForestClassifier(n_estimators=50,criterion="entropy",n_jobs=4,oob_score=True)
rf.fit(train_X,train_y)
rf_score=rf.score(test_X,test_y)
print("随机森林:",rf_score)
lr=LogisticRegression()
lr.fit(train_X,train_y)
lr_score=lr.score(test_X,test_y)
print("逻辑回归:",lr_score)
8.kmeans
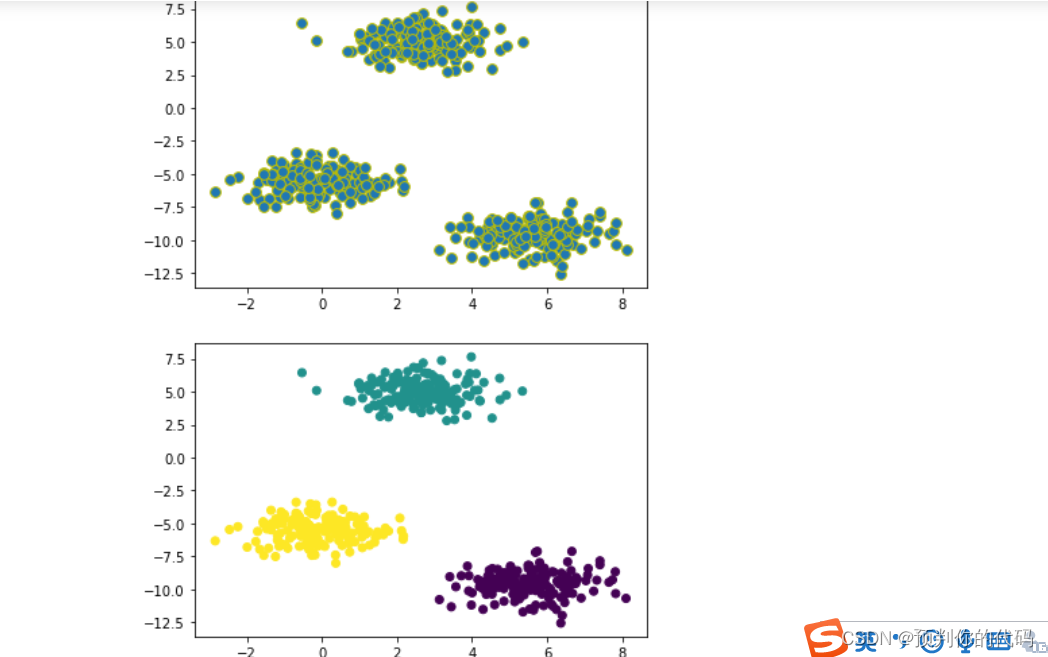
使用make_blobs函数生成样本大小是500的数据点,选用不同的参数进行聚类分析,同时改变random_state的值,通过数据可视化观察数据的分布,并采用kmeans算法设定不同的K值观察聚类后的结果,并输出聚类中心。
from sklearn.datasets import make_blobs
X,y=make_blobs(n_samples=500,centers=3,random_state=10)
import matplotlib.pyplot as plt
plt.scatter(X[:,0],X[:,1],cmap=plt.cm.cool,s=60,edgecolors='y')
plt.show()
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=3,random_state=10)
y_pred=kmeans.fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
print("聚类中心:")
print(kmeans.cluster_centers_)

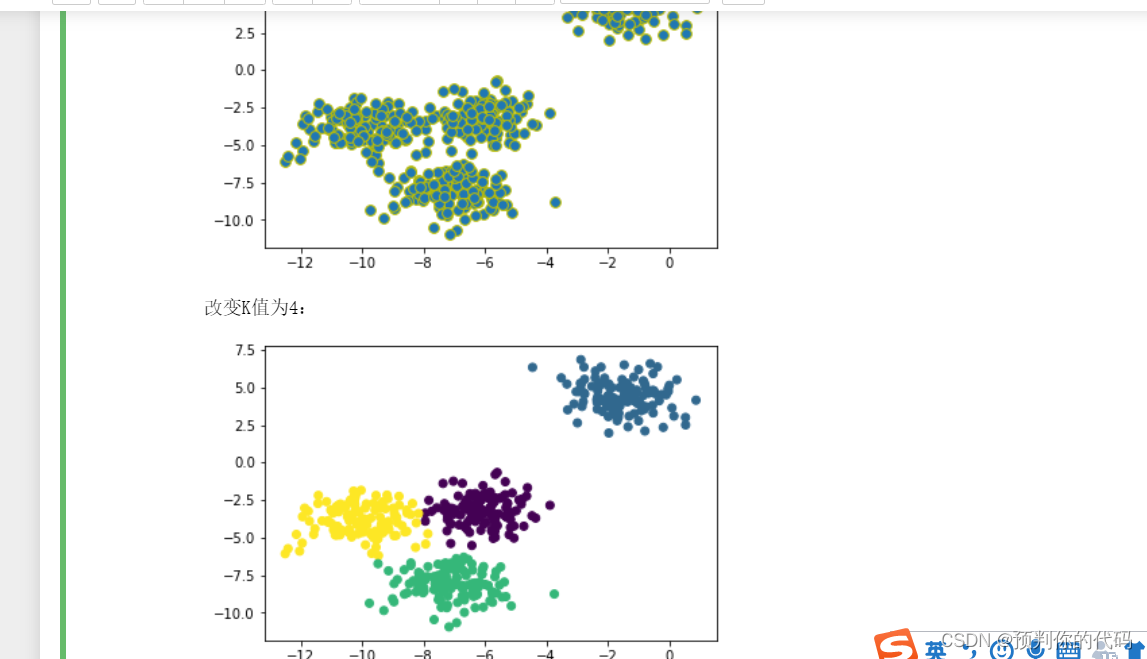
from sklearn.datasets import make_blobs
X,y=make_blobs(n_samples=500,centers=4,random_state=1)
import matplotlib.pyplot as plt
plt.scatter(X[:,0],X[:,1],cmap=plt.cm.cool,s=60,edgecolors='y')
plt.show()
print("改变K值为4:")
from sklearn.cluster import KMeans
kmeans=KMeans(n_clusters=4,random_state=100)
y_pred=kmeans.fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
print("聚类中心:")
print(kmeans.cluster_centers_)