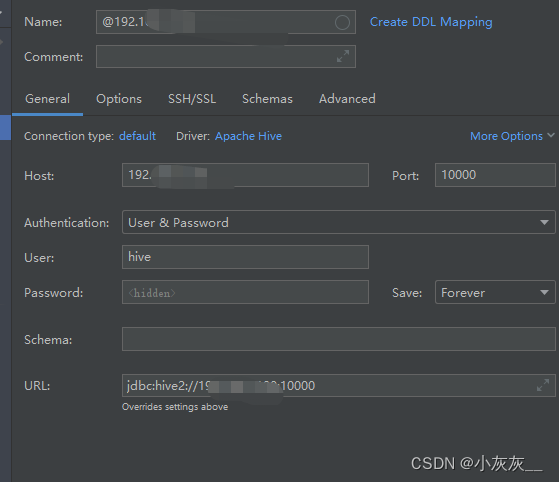
使用datagrip连接hive
-- 切换数据库
use testdb;
create database testdb;
-- 创建表
create table t_user(
id int,
name varchar(100),
age int
);
create table t_user3(
id int,
name varchar(100),
age int
)
row format delimited fields terminated by ','
STORED AS TEXTFILE;
-- 插入数据,可以通过insert和updatesql语句来操作,不过执行效率很慢,推荐通过文件的方式来写入数据
-- 这里需要结合hdfs来操作
-- 新建文本文件
[hdfs@master hive-server2]$ vim ~/user.txt
1,zhangsan,18
2,lisi,19
3,wangwu,17
4,zhaoliu,30

-- 将文件放到库中
hadoop fs -put ~/user.txt /warehouse/tablespace/managed/hive/testdb.db/t_user3
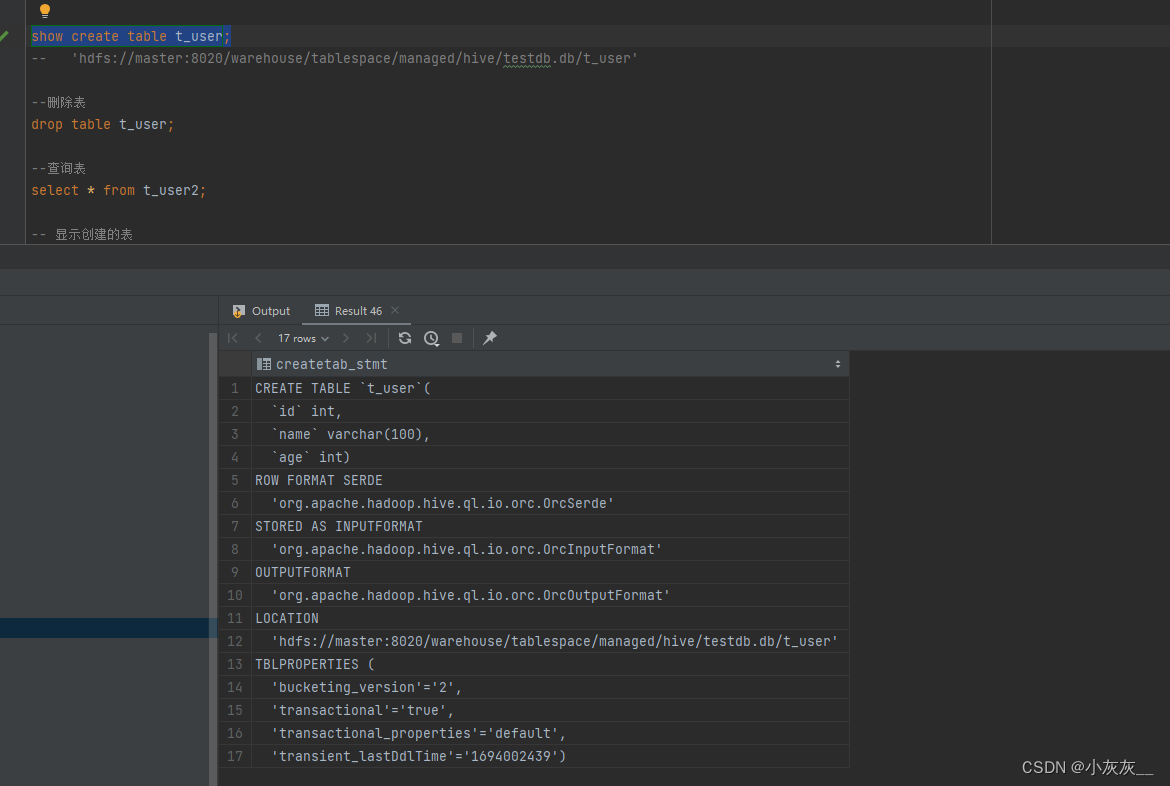
-- 查看建表语句,可以通过这个语句看到存储文件地址
show create table t_user;
-- 'hdfs://master:8020/warehouse/tablespace/managed/hive/testdb.db/t_user'
--删除表
drop table t_user;
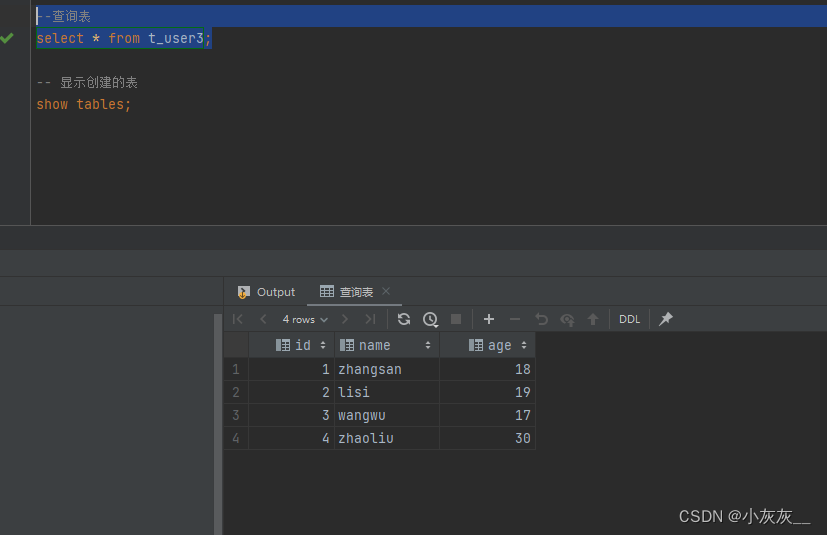
--查询表
select * from t_user3;
-- 显示创建的表
show tables;
问题处理
java.io.IOException: java.lang.RuntimeException: ORC split generation failed with exception: org.apache.orc.FileFormatException: Malformed ORC file hdfs://master:8020/warehouse/tablespace/managed/hive/testdb.db/t_user2/user.txt. Invalid postscript. org.apache.orc.FileFormatException:Malformed ORC file hdfs://master:8020/warehouse/tablespace/managed/hive/testdb.db/t_user2/user.txt. Invalid postscript.
这种报错是上传的是txt文件,而表默认使用orc的方式读取文件,导致读取失败,这里可以通过建表语句指定为txt格式
STORED AS TEXTFILE;
也可以使用标准orc文件来解决这种问题