上文Flink从入门到放弃(十二)-企业实战之事件驱动型场景踩坑(一)为大家介绍了Flink基于事件驱动场景下的渠道流量分析实时需求以及遇到的坑。
本文继续讲解基于事件驱动场景来讲解下关于响应时效、服务质量类的需求方案设计以及遇到的坑 (关于Flink主题的所有文章已整理同步到在线腾讯文档,本文中涉及到其他知识点都可在文档中查看,后台回复【文档】获取链接)。
需求背景
对于响应时效、服务质量类的需求是适用于各种业务场景下的。这里举一个实际的例子:我们在一些外卖平台上选取商品支付下单,然后进入商家接单环节,这个时候想要分析下商家接单的效率以及结合顾客的评价数据来给这个商家排级,那么可以通过等待时长的计算来反应出接单效率,并可以应用一些规则结合预警机制来触达商家。
方案设计
这里的实时计算等待时长其实和上篇文章的实际案例是一样的思路,但仍有一些不同点,上篇文章中只需要定时触发一次就可以来恢复或初始化指标值。而本次需求因为从下单到接单的过程当中,该订单并不会有任何的事件产生,那么对于我们实时计算等待时长就会有一定的难度,而不是等到商家接单了触发计算才得到等待时长。
因此如何循环驱动事件产生是本需求最大的难点。这里小编采用了队列分流的思想来设计,如下图: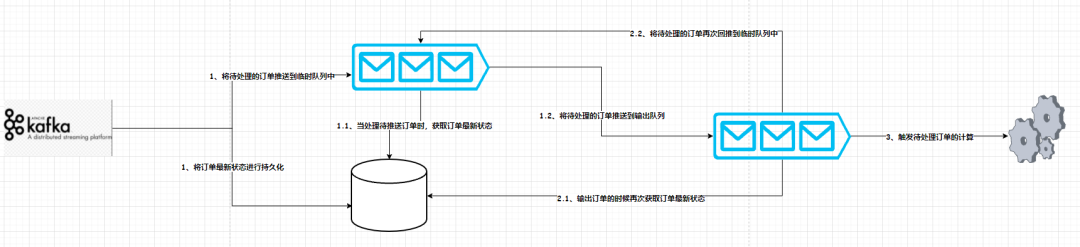 流程细节如下:
流程细节如下:
1、从数据来源Kafka中消费数据,然后进行分流;
2、将待处理的订单推送到临时队列中,将所有最新状态的订单进行持久化
3、从临时队列中拿出待处理的订单,然后再从持久化存储中查询该订单的最新状态,如果订单已经处理,则从临时队列中丢弃;如果订单仍未处理,则放到结果队列中,进行下一步的处理
4、从结果队列中拿到仍处于待处理的订单,然后再从持久化存储系统中查询最新的状态,如果处于待处理中,则回流到临时队列中进行等待处理,如果订单已经处理则丢弃;
5、从结果队列中拿到的最后需要计算的订单输出到下游,计算时长即可。
工程实践
根据上面的方案设计,涉及到队列和持久化存储。至于技术选型,可以结合企业实际情况抉择。实现方式既可以是Flink SQL 或者Jar。
小编这里选择通用的方案:即队列以Kafka为主,持久化存储以HBase作为维表关联。实现方式先以SQL的伪代码供大家参考;
--输出队列
insert into real_dwd_order_info
select
t1.*
from
( --临时队列
select *,PROCTIME() as proctime
from real_tmp_order_info_from_kafka
)t1
left join real_dim_order_info_to_hbase FOR SYSTEM_TIME AS OF t1.proctime t2 --维度关联最新订单状态
on t1.order_id = t2.order_id
where t2.order_id is null or t2.order_status='待处理'
--回流到临时队列
insert into real_tmp_order_info_from_kafka
select
t1.*
from
( --输出队列
select *,PROCTIME() as proctime
from real_dwd_order_info
)t1
left join real_dim_order_info_to_hbase FOR SYSTEM_TIME AS OF t1.proctime t2 --维度关联最新订单状态
on t1.order_id = t2.order_id
where t2.order_id is null or t2.order_status='待处理'
如下图所示:上述的方案是可实现的。
踩坑填坑
尽管上述方案可实现,但存在以下几个弊端:
1、频繁查询维度表,又因为要获取到最新的订单状态,所以缓存控制要有一定的权衡。
2、临时队列和输出队列是处于一种循环的状态,不可避免就会有存储资源严重浪费的情况,并且会影响到下游的计算,有可能会出现反压情况,对于时效性有一定的影响。这里可以根据实际情况权衡是否可以定时循环驱动(只需要调整结构即可)
3、由于循环驱动回流的特点,对下游的数据波动情况可能会比较明显(考虑到回撤问题,和问题2类似)