闲的没事干,分析下我自己的一卡通消费信息。
使用了以下技术进行数据分析并且环境已经搭建好。
Hadoop hive mysql sqoop centos7 python zeppelin
思路:
python爬自己的消费记录,存入到mysql sqoop把数据转移到hive,基于zeppelin可视化。
爬虫部分
一卡通网站
爬取前F12看下抓包数据 ,要爬取的URL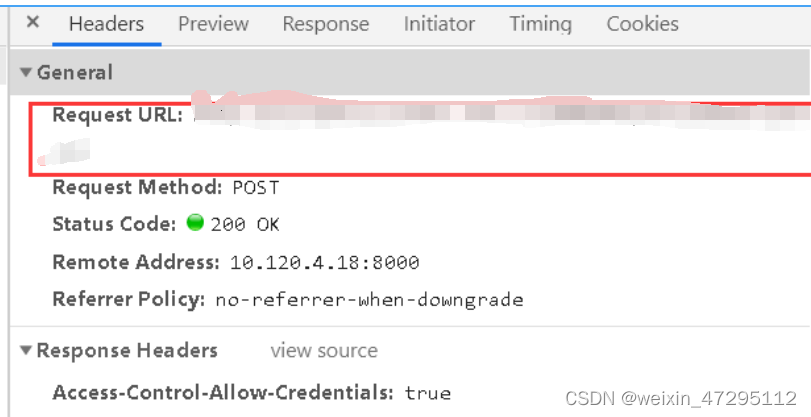
cookie登录用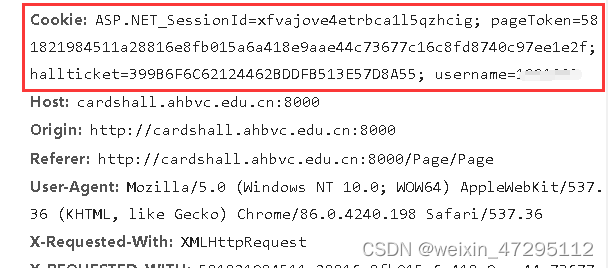
表单携带的数据sdate开始日期 edate结束日期 account为学号对应的卡号
执行爬虫代码,并保存到数据库。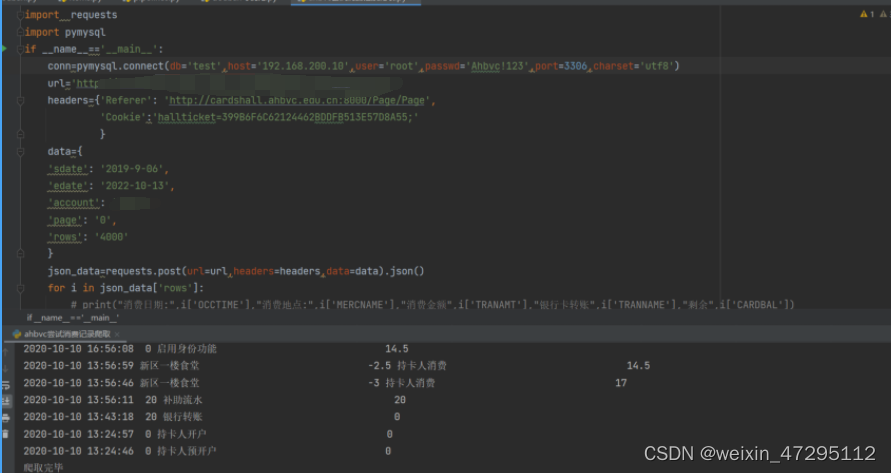
mysql查看
数据导入
sqoop把mysql数据导入到hive(hive要提前好库)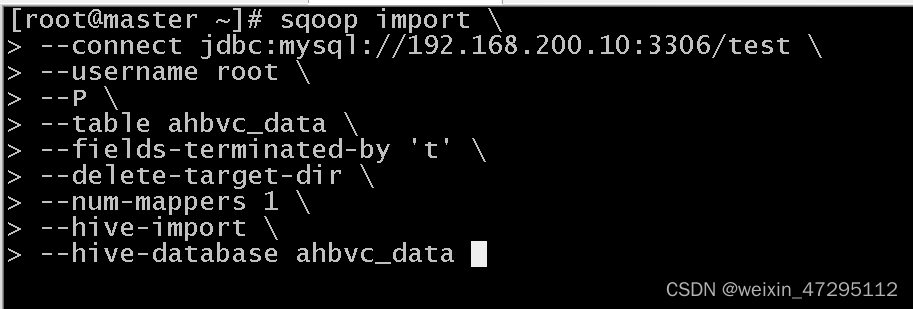
完成
hive数据

zeppelin简单分析可视化
查看数据
查看表结构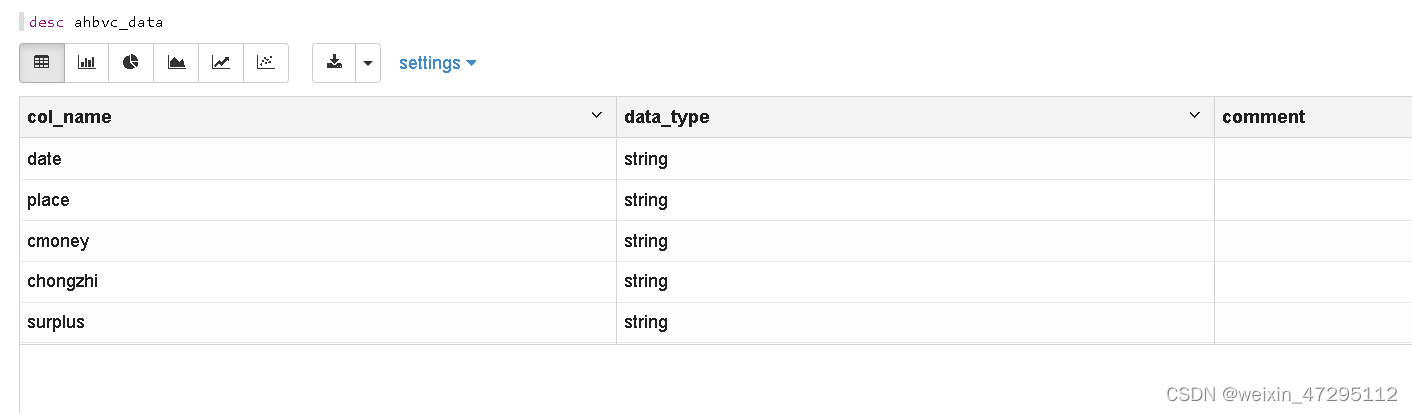
原表数据字段类型需要重新转换,建个新表加载进去
加载数据,顺便把消费里面的-去掉方便统计
insert into table sh select date,place,cmoney,split(cmoney,'-')[1] as new_xiaofei,chongzhi,surplus from ahbvc_sh;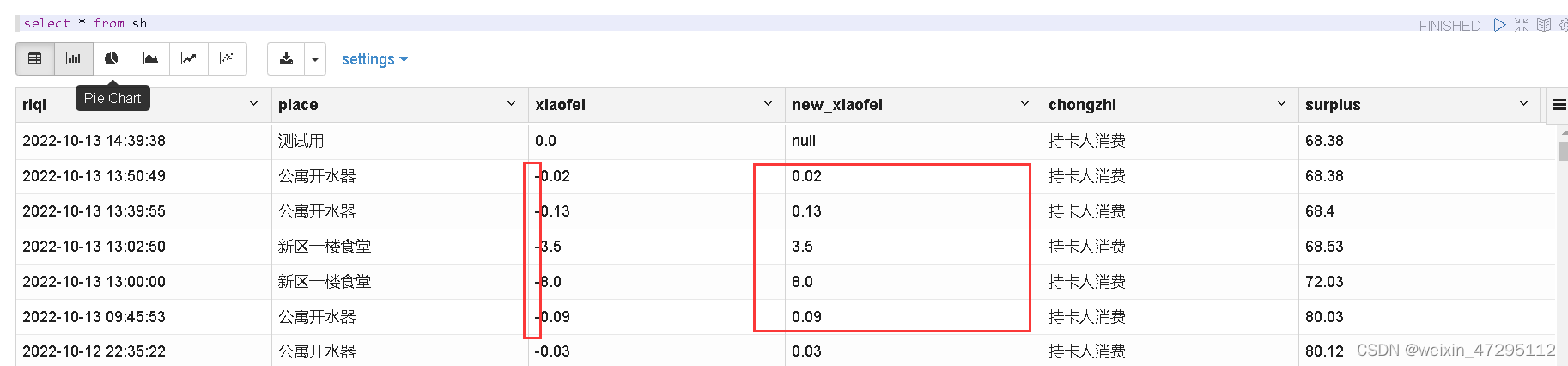
需要把日期分割出来,方便分组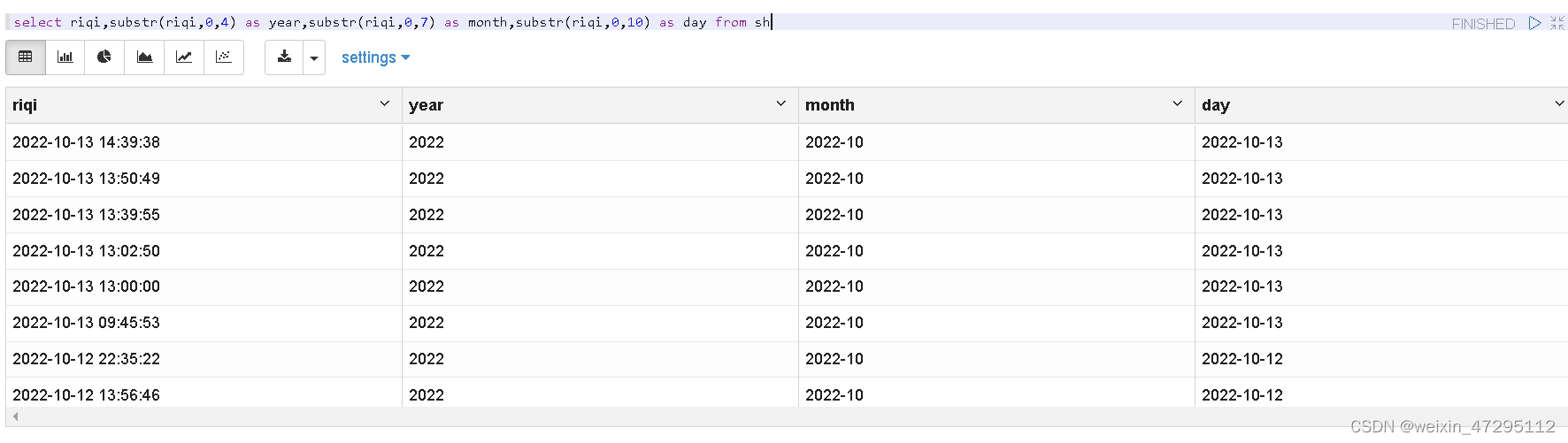
加载到新表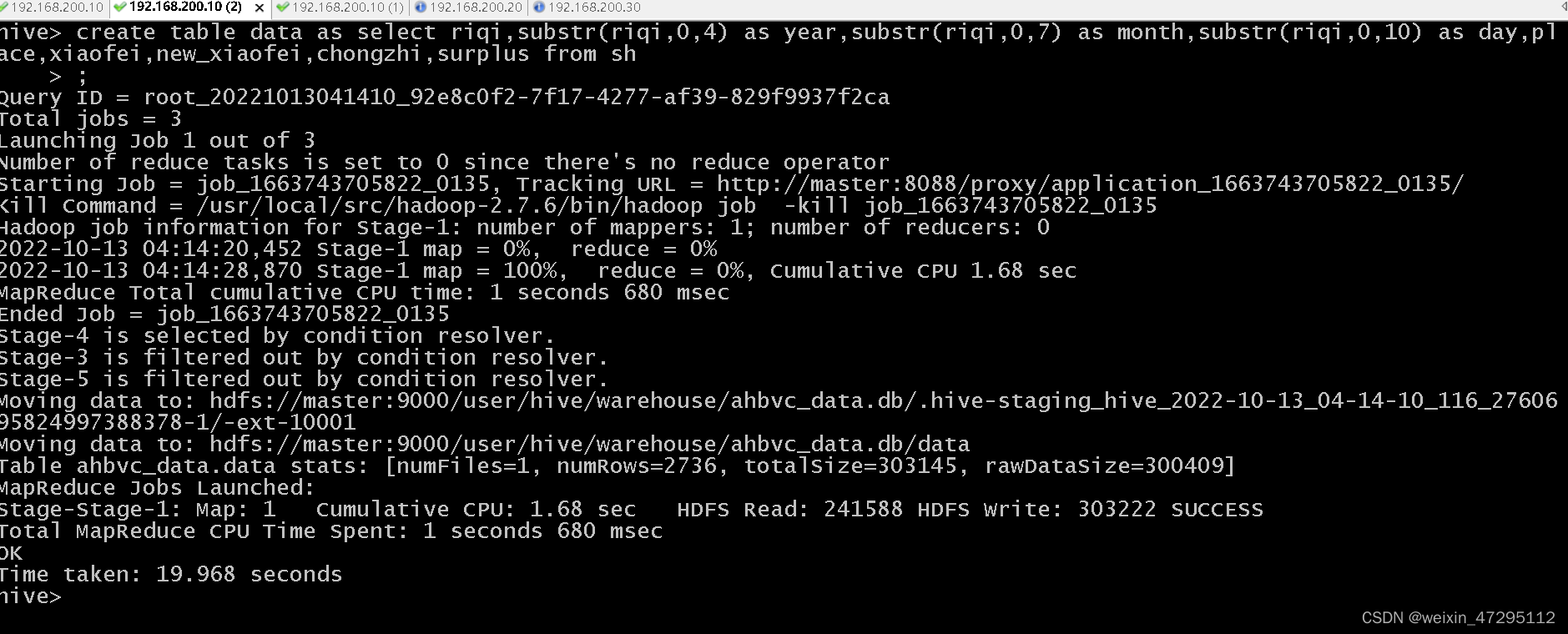
新表数据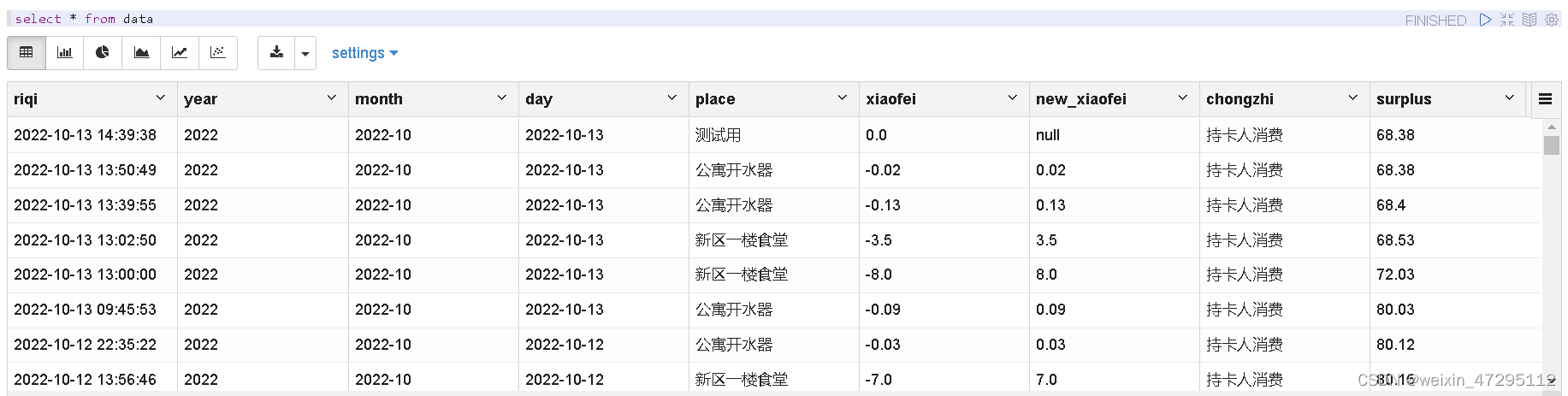
看一看充值记录(2020-10-10 到 2022-10-13)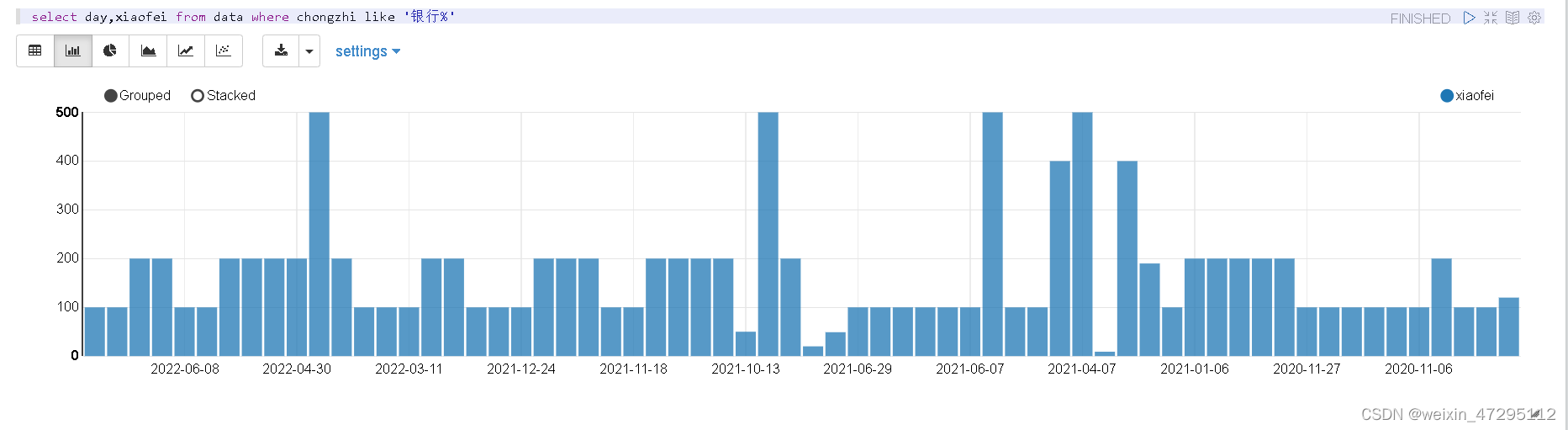
总共充值金额(不知不觉充了一万多了)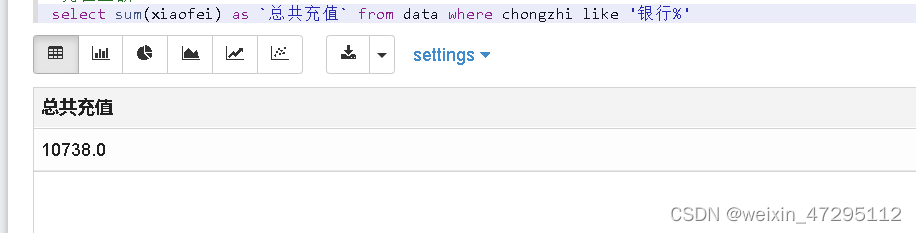
每日消费金额(可以看出每天10-30块钱很密集,怎么有条记录一天消费76?一年后才知道,心痛)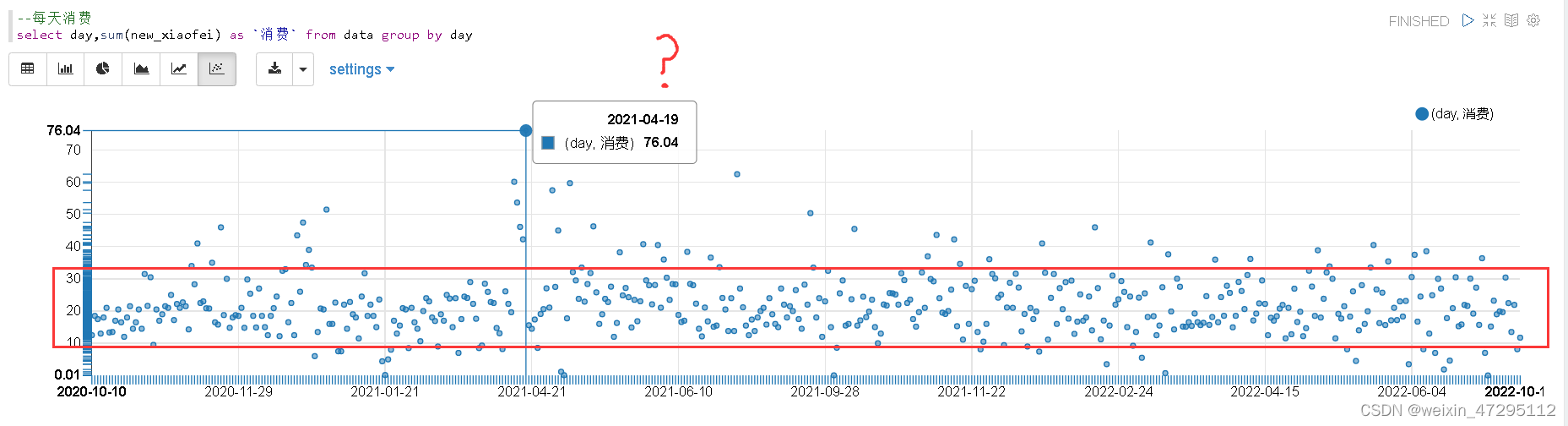
看一下(难不成被盗用了 实在想不起来咋花的了。)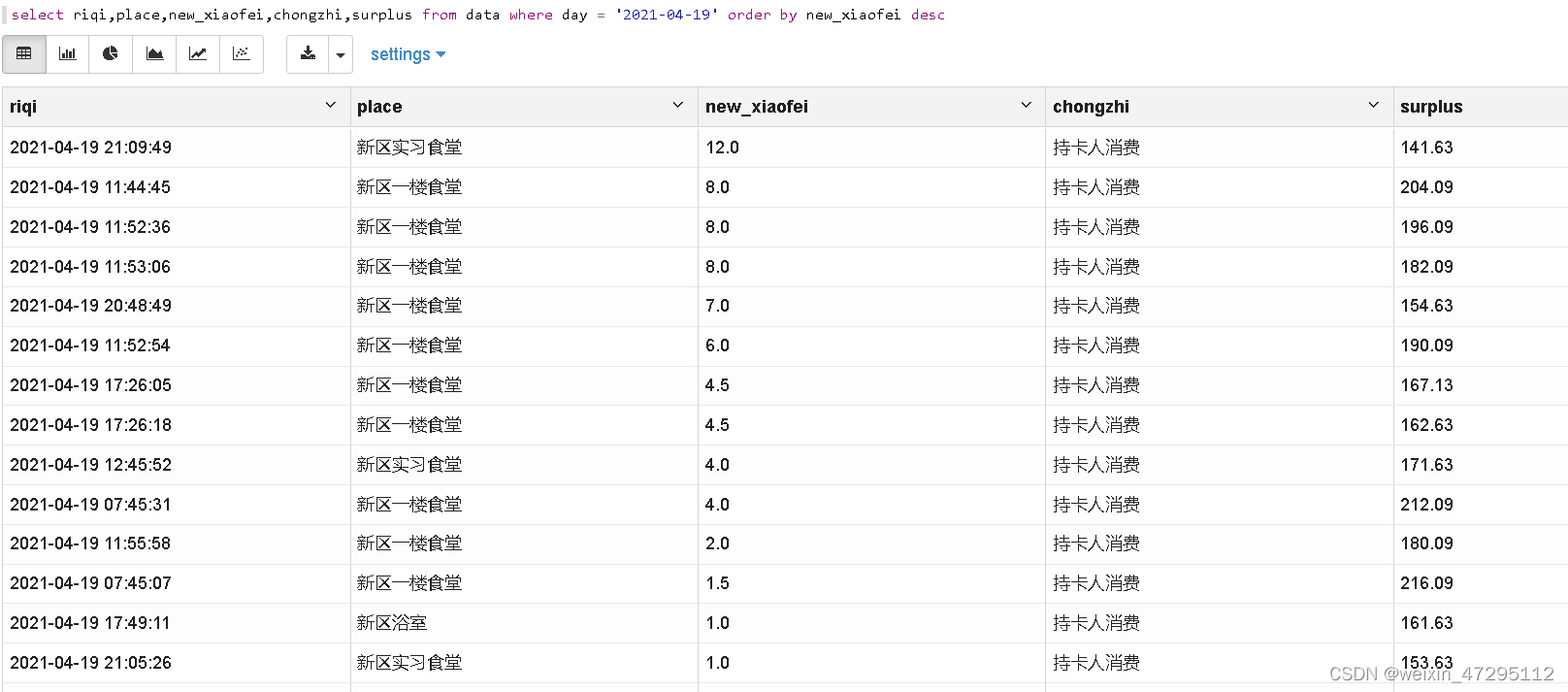
每月吃七块套餐次数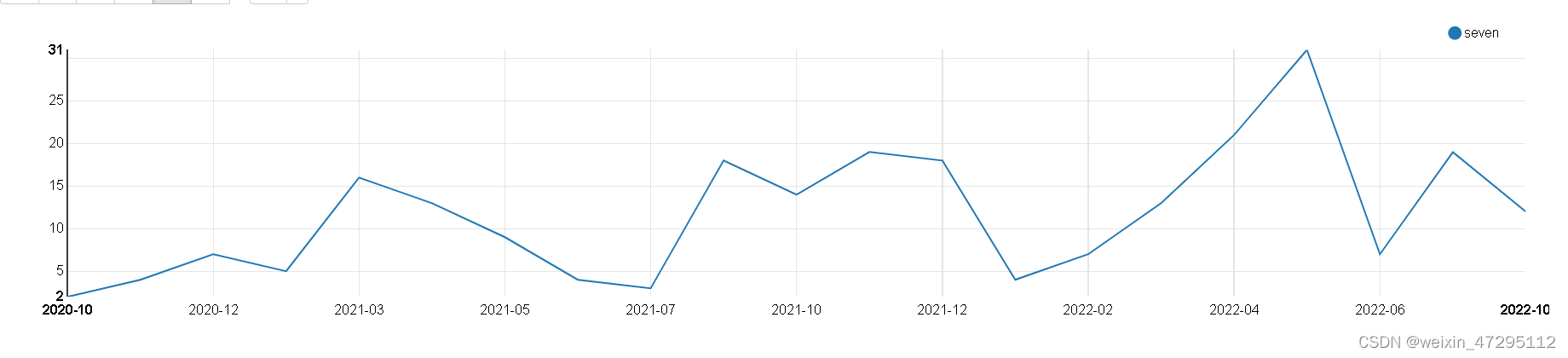
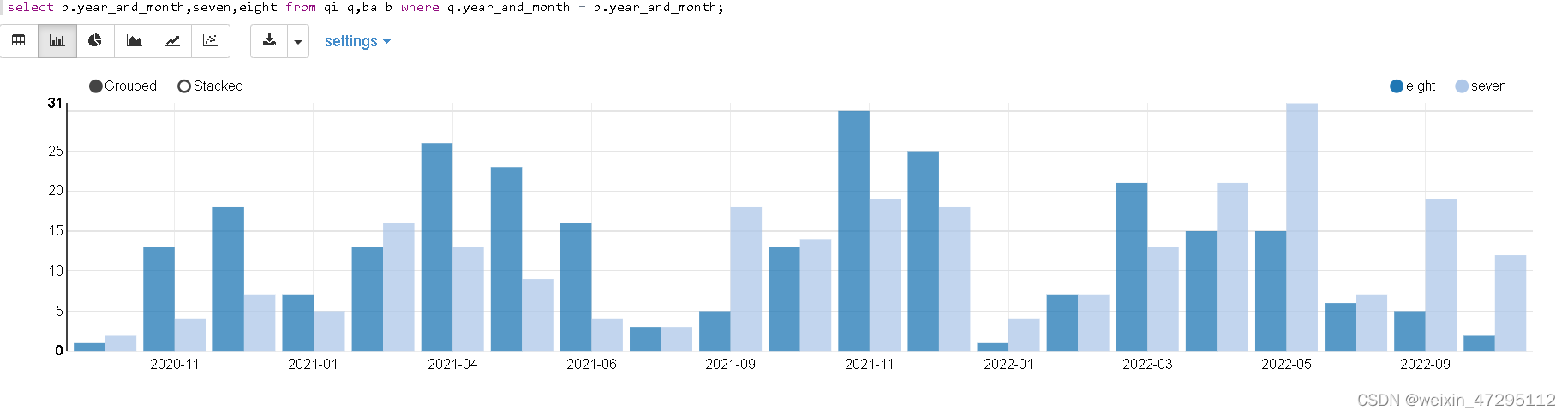
每月吃八块套餐次数
对比挺有意思,2022年之前大部分吃饭都是八块的套餐,2022年之后七块(懂得都懂 )
)
每月消费金额,基本上用来吃饭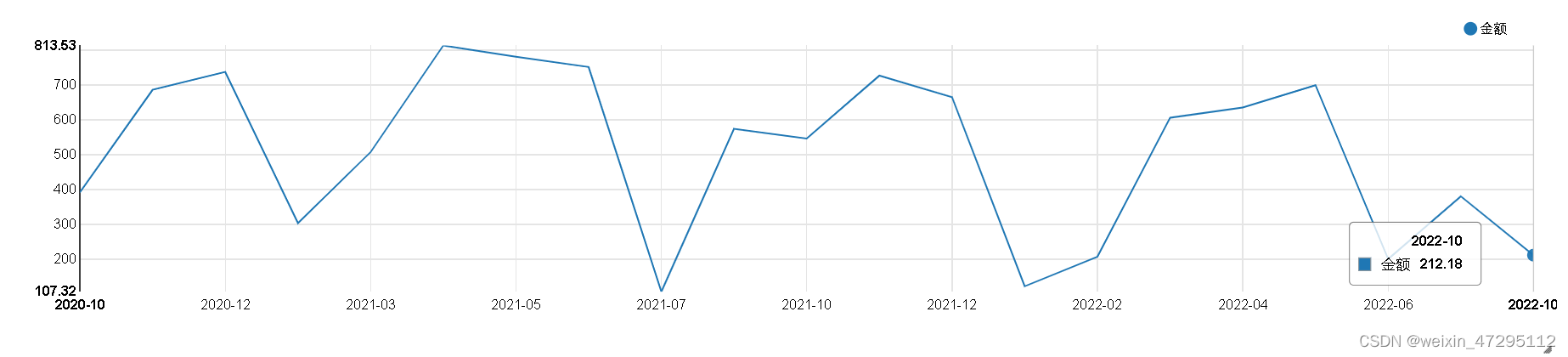
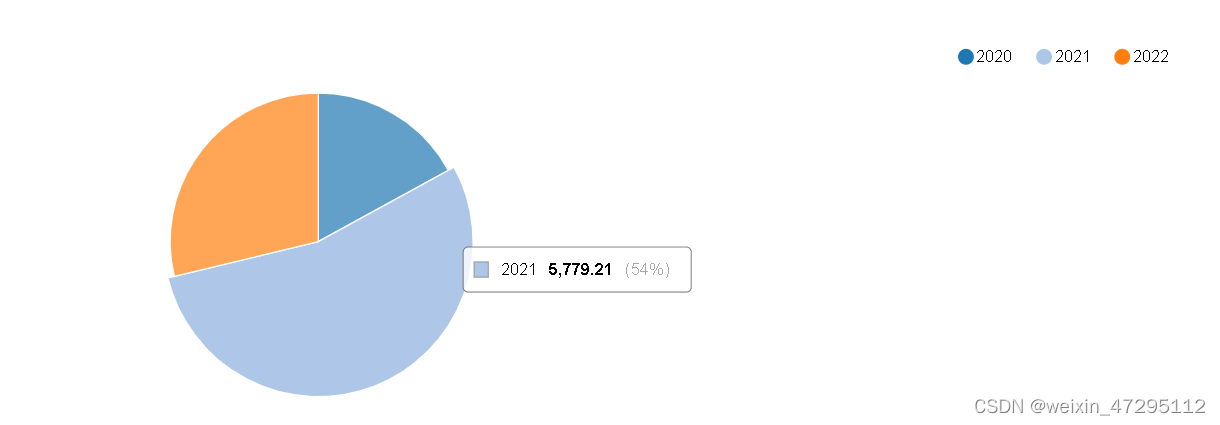
每年消费金额(2020 1816元占了17% ,2021 5779元占了54%,2022 3066元占了29%)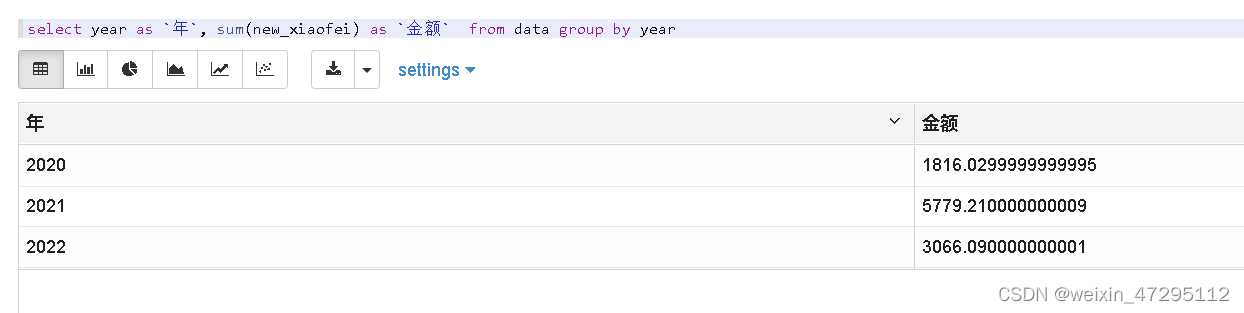
各个区域消费(一楼食堂吃的最多花了9164)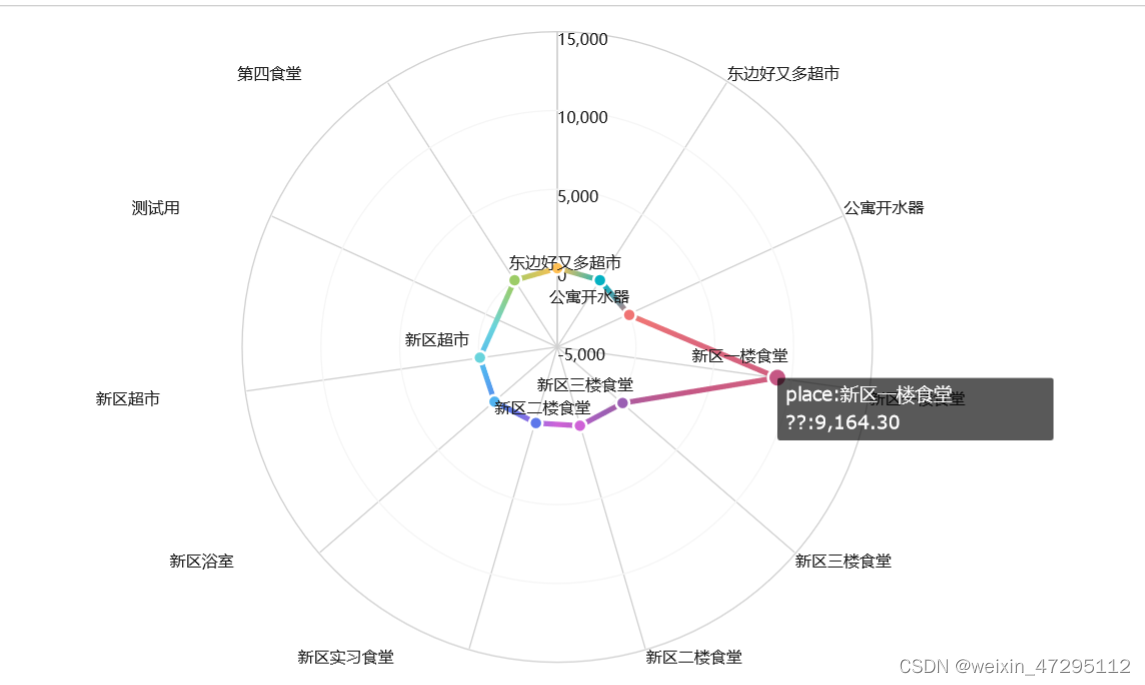
刷卡次数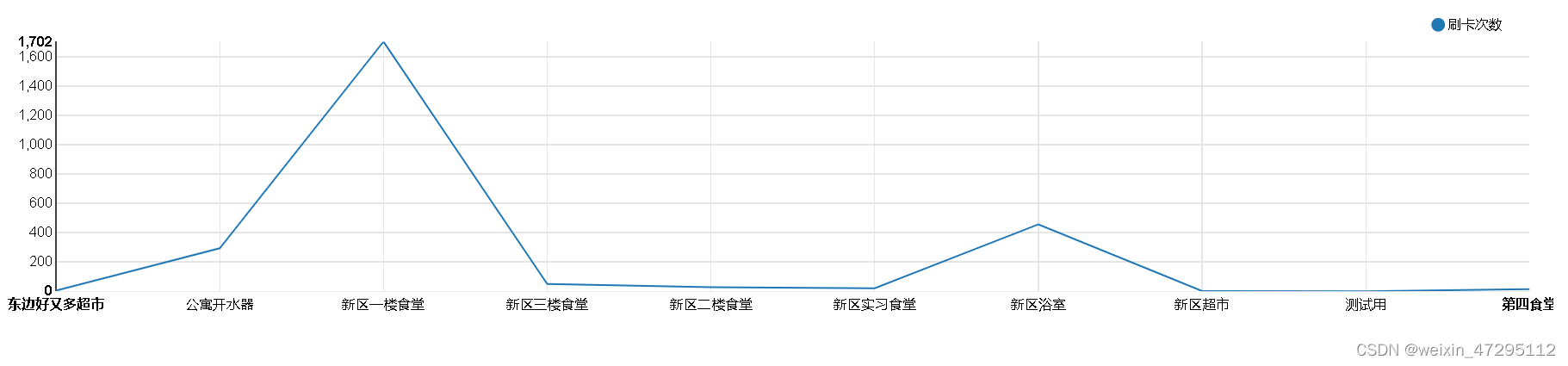
随便练习,apache开源组件 禁止用于非法用途