架构图:(网图,很通俗易懂了,就不自己画了,这里实现的是一个Producer 两个Consumer)
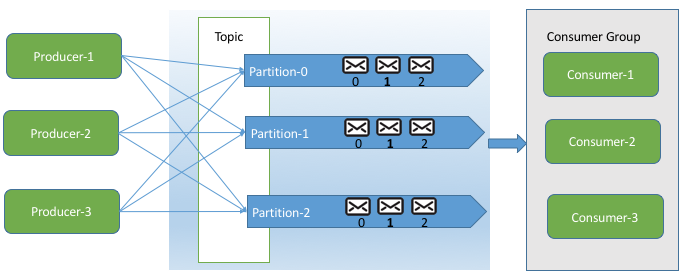
前提:已经开启zookeeper 和kafka ,具体可参考博客https://blog.csdn.net/DGH2430284817/article/details/90483089
步骤:
1,:设置kafka 分区为2 :
修改kafka 目录config 下的文件server.properties ,修改 num.partitions=2,保存,重启kafka。
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=2
在修改后,生产者在发送消息到kafka 的broker 的时候就会保存到两个分区中的一个,具体是哪个要根据分区规则的写法,一般采取的都是生产者提供一个key ,对这个key 进行hashCode() 计算它的值,再对这个值除分区数取余,用这个余数来决定消息保存到哪个分区。(如现在分区是2,经过上面的计算后只会出现0和1的值,而且是散列的,两个分区的数据量会差不多)
2:编写分区规则:
package com.kafka1;
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class SimplePartitioner implements Partitioner {
public SimplePartitioner () { }
public SimplePartitioner (VerifiableProperties props) { }
public int partition(Object key, int numPartitions) {
int partition = 0;
String k = (String)key;
partition = Math.abs(k.hashCode()) % numPartitions;//根据key的hashCode和分区数numPartitions,算出所在分区,如分区数为2,返回值只会是0和1
return partition;
}
}
3:编写生产者类PartitionerProducer.java:
package com.kafka1;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.producer.Partitioner;
public class PartitionerProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "127.0.0.1:9092");//连接 kafka
props.put("partitioner.class", "com.kafka1.SimplePartitioner"); //指定分区规则的类
Producer<String, String> producer = new Producer<String, String>(new ProducerConfig(props));
String topic = "dgh-test";
Partitioner Partitioner = new SimplePartitioner();
for (int i = 0; i <= 10; i++) {
String k = "key" + System.currentTimeMillis(); //key+当前毫秒,形成唯一key,也可以使用时间戳
String v = k + ":value" + i; //消息内容
int partition = Partitioner.partition(k, 2); //计算消息key所保存的分区号,2是分区数,实际生产这里可以不用,因为要方便观看所以输出分区
System.out.println("topic:" + topic + ", partition:" + partition + ", key:" + k + ", value:" +v);
producer.send(new KeyedMessage<String, String>(topic, k, v));
}
producer.close();
}
}
右键运行:
topic:dgh-test, partition:1, key:key1560695392884, value:key1560695392884:value0
topic:dgh-test, partition:1, key:key1560695393122, value:key1560695393122:value1
topic:dgh-test, partition:1, key:key1560695393124, value:key1560695393124:value2
topic:dgh-test, partition:0, key:key1560695393127, value:key1560695393127:value3
topic:dgh-test, partition:1, key:key1560695393128, value:key1560695393128:value4
topic:dgh-test, partition:0, key:key1560695393129, value:key1560695393129:value5
topic:dgh-test, partition:0, key:key1560695393130, value:key1560695393130:value6
topic:dgh-test, partition:0, key:key1560695393132, value:key1560695393132:value7
topic:dgh-test, partition:1, key:key1560695393133, value:key1560695393133:value8
topic:dgh-test, partition:1, key:key1560695393135, value:key1560695393135:value9
根据控制台结果,可以看到一共生产了10条消息,其中根据分区规则,有6条消息保存在partition分区1,4条在分区0,如果数据量大,两个分区的数据是很平均的。(想要多个生产者的就多开几个线程去生产消息)
4:编码消费者类DConsumer.java:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.message.MessageAndMetadata;
public class DConsumer extends Thread{
public static void main(String[] args) throws InterruptedException {
//开两个线程,两个连接,相当于两个消费者
DConsumer consumer1 = new DConsumer("consumer-1");//消费者consumer-1
consumer1.start();
DConsumer consumer2 = new DConsumer("consumer-2");//消费者consumer-2
consumer2.start();
}
private String consumerName = null;
public DConsumer ( String consumerName) {
this.consumerName = consumerName;
}
@Override
public void run() {
System.out.println("消费者:" +consumerName + "开始处理消息");
String topic = "dgh-test";
Properties props = new Properties();
props.put("group.id", "group1");
//props.put("zookeeper.connect", "127.0.0.132:2181,127.0.0.133:2182,127.0.0.134:2183");
props.put("zookeeper.connect", "127.0.0.1:2181");//连接 zookeeper
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(props));
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
MessageAndMetadata<byte[], byte[]> mam = it.next();
System.out.println("consumer: " + consumerName + ", Partition: " + mam.partition() + ", Message: " + new String(mam.message()) + "");
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
右键运行:
消费者:consumer-1开始处理消息
消费者:consumer-2开始处理消息
[2019-06-16 22:38:40,317] INFO Starting ZkClient event thread. (org.I0Itec.zkclient.ZkEventThread)
[2019-06-16 22:38:40,317] INFO Starting ZkClient event thread. (org.I0Itec.zkclient.ZkEventThread)
consumer: consumer-1, Partition: 0, Message: key1560695393127:value3
consumer: consumer-2, Partition: 1, Message: key1560695392884:value0
consumer: consumer-2, Partition: 1, Message: key1560695393122:value1
consumer: consumer-1, Partition: 0, Message: key1560695393129:value5
consumer: consumer-1, Partition: 0, Message: key1560695393130:value6
consumer: consumer-2, Partition: 1, Message: key1560695393124:value2
consumer: consumer-2, Partition: 1, Message: key1560695393128:value4
consumer: consumer-1, Partition: 0, Message: key1560695393132:value7
consumer: consumer-2, Partition: 1, Message: key1560695393133:value8
consumer: consumer-2, Partition: 1, Message: key1560695393135:value9
在消费者连接进行消息消费的时候,如果只有一个消费者,那两个分区的消息都是会把消息发送给这个消费者,如果两个消费者的话,先连接的消费者获取的分区0的消息,后连接的消费者获取分区1的消息。如果三个消费者的话,第三个连的消费者会获取不了消息,所以消费者的数量最好不要超过分区数。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)