资源清单
资源类型
- 名称空间级别:
- 工作负载型资源(workload) : Pod、Replica Set、Deployment、Stateful Set、Daemon Set、Job、 CronJob(Replication Controller在v 1.11版本被废弃)
- 服务发现及负载均衡型资源(Service Discovery Load Balance) : Service、Ingress、 .
- 配置与存储型资源: Volume(存储卷) 、CSI(容器存储接口, 可以扩展各种各样的第三方存储卷)
- 特殊类型的存储卷:Config Map(当配置中心来使用的资源类型) 、Secret(保存敏感数据) 、
- Downward API(把外部环境中的信息输出给容器)
- 集群级别:
- 集群级资源: :Namespace、Node、Role、ClusterRole、RoleBinding、ClusterRoleBinding
- 元数据型:
- 元数据型资源:HPA、PodTemplate、LimitRange
资源清单
在k8s中,一般使用 yaml 格式的文件来创建符合我们预期期望的pod, 这样的yaml 文件我们一般 称为资源清单
yaml基本使用
- 缩进时不允许使用Tab键, 只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- #标识注释,从这个字符一直到行尾,都会被解释器忽略
- 对象:键值对的集合, 又称为映射(mapping) /哈希(hashes) ) /字典(dictionary) 装
- 数组:一组按次序排列的值, 又称为序列(sequence) /列表 (list)
- 纯量(scalars) :单个的、不可再分的值
-
对象类型:对象的一组键值对,使用冒号结构表示
name:Steve age: 18
-
Yaml也允许另一种写法, 将所有键值对写成一个行内对象
hash: :{name:Steve, age:18}
-
数组类型:一组连词线开头的行,构成一个数组
animal
- Cat
- Dog
-
数组也可以采用行内表示法
animal:[Cat, Dog]
-
复合结构:对象和数组可以结合使用,形成复合结构
languages:
- Ruby
- Perl
- Python
websites
YAML:yaml.org
Ruby:ruby-lang.org
Python:python.org
Perl:use.perl.org
-
纯量:纯量是最基本的、不可再分的值。以下数据类型都属于纯量
- 字符串 布尔值 整数 浮点数 Null
- 时间日期
- 数值直接以字面量的形式表示
number :12.30
- 布尔值用true和false表示
is Set:true
- null用~表示
parent:~
- 时间采用IS08601格式
iso8601:2001-12-14t21:59:43.10-05:00
- 日期采用复合iso 8601格式的年、月、日表示
date:1976-07-31
- YAML允许使用两个感叹号, 强制转换数据类型
e: !!str 123
f: !!str true
-
字符串
- 字符串默认不使用引号表示
str:这是一行字符串
- 如果字符串之中包含空格或特殊字符,需要放在引号之中
str: ‘内容: 字符串’
- 单引号和双引号都可以使用,双引号不会对特殊字符转义
s1: ‘内容\n字符串’
s2: “内容\n字符串”
- 单引号之中如果还有单引号,必须连续使用两个单引号转义
str: : ‘labor’‘s day’
- 字符串可以写成多行,从第二行开始,必须有一个单空格缩进。换行符会被转为空格
str:这是一段
多行
字符串
- 多行字符串可以使用|保留换行符,也可以使用>折叠换行
this: |
Foo
Bar
that:>
Foo
Bar
- +表示保留文字块末尾的换行,-表示删除字符串末尾的换行
s1: |
Foo
s2: |+
Foo
s3: |-
Foo
资源清单格式
apiVersion: group/apiversion #如果没有给定group名称, 那么默认为core, 可以使用kubectl api-versions #获取当前k8s版本上所有的api Version版本信息(每个版本可能不同)
kind: #资源类别
metadata: #资源元数据
name
namespace
lables
annotations #主要目的是方便用户阅读查找
spec: #期望的状态(disi redstate)
status: #当前状态, 本字段有Kubernetes自身维护, 用户不能去定义
资源清单的常用命令
kubectl api-versions # 获取api version版本信息
# 获取资源的api Version版本信息
kubectl explain pod
kubectl explain Ingress
kubectl explain pod # 获取字段设置帮助文档
字段配置格式
apiVersion <string> # 表示字符串类型
metadata <Object> # 表示需要嵌套多层字段
labels <map[string] string> # 表示由k:v组成的映射
finalizers<[]string> # 表示字串列表
ownerReferences<[]Object> # 表示对象列表
hostPID<boolean> # 布尔类型
priority<integer> # 整型
name<string> -required- # 如果类型后面接 -required-, 表示为必填字段
通过定义清单文件创建Pod
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
spec:
containers:
- name: myapp-1
image: my.example.com/library/myapp:v1
- name: busybox
image: busybox:latest
command:
- "/bin/sh"
- "-c"
- "sleep 3600"
kubectl get pod xx.xx.xx -o yaml
常用字段说明
| 参数名 |
字段类型 |
说明 |
| 必填字段 |
– |
– |
| versions |
String |
这里是指的是K8SAPI的版本, 目前基本上是v1, 可以用kubectl api-version 命令查询 |
| kind |
String |
这里指的是yaml文件定义的资源类型和角色, 比如:Pod |
| metadata |
Object |
元数据对象, 固定值就写metadata |
| metadata.name |
String |
元数据对象的名字, 这里由我们编写, 比如命名Pod的名字 |
| metadata.namespace |
String |
元数据对象的命名空间,由我们自身定义 |
| Spec |
Object |
详细定义对象, 固定值就写Spec |
| spec.containers[] |
list |
这里是Spec对象的容器列表定义, 是个列表 |
| spec.containers[] .name |
String |
这里定义容器的名字 |
| spec.containers[] .image |
String |
这里定义要用到的镜像名称 |
| 主要字段 |
– |
– |
| spec.containers[] .imagePullPolicy |
String |
定义镜像拉取策略, 有Always、Never、 If Not Present 三个值可选 (1) Always:意思是 每次都尝试重新拉取镜像 (2) Never:表示仅 使用本地镜像 (3) If Not Present:如果本地有 镜像就使用本地镜像,没有就拉取在线镜像。 上面三个值都没设置的话, 默认是Always。 |
| spec.containers[].command[] |
List |
指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令。 |
| spec.containers[].args[] |
List |
指定容器启动命令参数,因为是数组可以指定多个。 |
| spec.containers[].workingDir |
String |
指定容器的工作目录 |
| spec.containers[] .volumeMounts[] |
List |
指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name |
String |
指定可以被容器挂载的存储卷的名称 |
| spec.containers[].volume Mounts[].mountPath |
String |
指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volume Mounts[].readOnly |
String |
设置存储卷路径的读写模式, ture或者false, 默认为读写模式 |
| spec.containers[].ports[] |
List |
指定容器需要用到的端口列表 |
| spec.containers[].ports[].name |
String |
指定端口名称 |
| spec.containers[].ports[].containerPort |
String |
指定容器需要监听的端口号 |
| spec.containers[].ports[].hostPort |
String |
指定容器所在主机需要监听的端口号,默认跟上面containerPort相同, 注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol |
String |
指定端口协议, 支持TCP和UDP, 默认值为TCP |
| spec.containers[].env[] |
List |
指定容器运行前需设置的环境变量列表 |
| spec.containers[].env[].name |
String |
指定环境变量名称 |
| spec.containers[].env[].value |
String |
指定环境变量值 |
| spec.containers[].resources |
Object |
指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits |
Object |
指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu |
String |
指定CPU的限制, 单位为core数, 将用于 docker run --cpu-shares参数 |
| spec.containers[].resources.limits.memory |
String |
指定MEM内存的限制, 单位为MIB、GiB |
| spec.containers[].resources.requests |
Object |
指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu |
String |
CPU请求, 单位为core数, 容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory |
String |
内存请求,单位为MIB、GiB, 容器启动的初始化可用数量 |
| 额外字段 |
– |
– |
| spec.restartPolicy |
String |
定义Pod的重启策略, 可选值为Always、OnFailure、Never, 默认值为 Always. 1.Always:Pod一旦终止运行, 则无论容器是如何终止的, kubelet服务都将重启它。 2.OnFailure:只有Pod以非零退出码终止时, kubelet才会重启该容 器。如果容器正常结束(退出码为0) , 则kubelet将不会重启它。 3.Never:Pod终止后, kubelet将退出码报告给Master, 不会重启该 Pod。 |
| spec.nodeSelector |
Object |
定义Node的Label过滤标签, 以keyvalue格式指定 |
| spec.imagePullSecrets |
Object |
定义pull镜像时使用secret名称, 以name:secretkey格式指定 |
| spec.hostNetwork |
Boolean |
定义是否使用主机网络模式, 默认值为false。设置true表示使用宿主机网络, 不使用docker网桥, 同时设置了true将无法在同一台宿主机 上启动第二个副本。 |
容器生命周期

kubectl --> kubeapi --> etcd --> kubelet
kubellet --> 容器环境初始化 --> pause --> (init C)* --> Main C --> START(?) # *和?为正则
readiness <> Main C <> Liveness
Main C --> STOP
Init容器
Pod能够具有多个容器, 应用运行在容器里面, 但是它也可能有一个或多个先于应用容器启动的Init 容器
Init容器与普通的容器非常像, 除了如下两点:
- Init容器总是运行到成功完成为止
- 每个Init容器都必须在下一个Init容器启动之前成功完成
如果Pod的Init容器失败, Kubernetes会不断地重启该Pod, 直到Init容器成功为止。然而如果Pod对应的restartPolicy为Never, 它不会重新启动
Init容器的作用
因为Init容器具有与应用程序容器分离的单独镜像, 所以它们的启动相关代码具有如下优势:
- 它们可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这 些实用工具的
- 它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像, 只需要在安装过程中使用类似sed、 awk、 python或dig 这样的工具。
- 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像
- Init容器使用Linux Namespace, 所以相对应用程序容器来说具有不同的文件系统视图。因 此,它们能够具有访问Secret的权限, 而应用程序容器则不能。
- 它们必须在应用程序容器启动之前运行完成, 而应用程序容器是并行运行的, 所以Init容 器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件。
Init容器的特殊说明
- 在Pod启动过程中, Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出
- 如果由于运行时或失败退出, 将导致容器启动失败, 它会根据Pod的restartPolicy指定的策略进行重试。然而, 如果Pod的restartPolicy设置为Always, Init容器失败时会使用 RestartPolicy策略
- 在所有的Init容器没有成功之前, Pod将不会变成Ready状态。Init容器的端口将不会在 Service中进行聚集。 正在初始化中的Pod处于Pending状态, 但应该会将Initializing状态设置为true
- 如果Pod重启, 所有Init容器必须重新执行
- #对Init容器 spec的修改被限制在容器image字段, 修改其他字段都不会生效。更改Init 容器的image字段, 等价于重启该Pod
- Init容器具有应用容器的所有字段。除了readinessProbe, 因为Init容器无法定义不同于完成 (completion) 的就绪(readiness) 之外的其他状态。这会在验证过程中强制执行
- 在Pod中的每个app和Init容器的名称必须唯一; 与任何其它容器共享同一个名称, 会在验证时抛出错误
Init容器 yaml模板
# init模板
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: mvapp-container
image: busybox
command: ['sh', ,'-c', , 'echo The app is running!&&sleep 3600']
initContainers:
- name: init-myservice
image: busybox
command: ['sh', ,'-c', , 'until nslookup my service;do echo waiting for my service;sleep 2;done;']
- name: init-mydb
image: busybox
command: ['sh', ,'-c', , 'until nslookup my db;do echo waiting for my db;sleep 2;done;'
---
# svc myservice 配置
kind: Service
apiVersion: v1
metadata:
name:myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
# svc mydb配置
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
容器探针
探针是由kubelet对容器执行的定期诊断。要执行诊断, kubelet调用由容器实现的Handler。有三 种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查。如果端口打开, 则诊断被认为是成功的。
- HTTPGetAction; :对指定的端口和路径上的容器的IP地址执行HTTP Get请求。如果响应的 状态码大于等于200且小于400,则诊断被认为是成功的
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动
探测方式
- livenessProbe: :指示容器是否正在运行。如果存活探测失败, 则kubelet会杀死容器, 并且容器将受到其 重启策略的影响。如果容器不提供存活探针, 则默认状态为Success
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败, 端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为Failure。如果容 器不提供就绪探针, 则默认状态为Success
就绪检测 readinessProbe 配置
# readinessProbe-httpget 模式
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
spec:
containers:
- name: readiness-httpget-container
image: myapp:v1
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
port: 80
path: /index1.html
initialDelaySeconds: 1
periodSeconds: 3
存活检测 livenessProbe 配置
# livenessProbe-exec
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "touch/tmp/live; sleep 60; rm-rf/tmp/live; sleep 3600"]
livenessProbe:
exec:
command: ["test", "-e", "/tmp/live"]
initialDelaySeconds : 1
periodSeconds: 3
# livenessProbe-httpget
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
port: 80
path: /index1.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
# livenessProbe-tcp
apiVersion: v1
kind: Pod
metadata:
name: liveness-tcp-pod
spec:
containers:
- name: liveness-tcp-container
image: myapp:v1
imagePullPolicy: IfNotPresent
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
timeoutSeconds: 2
启动和退出运作配置
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: myapp:v1
lifecycle:
postStart:
exec: ["/bin/sh", "-c", "echo will start"]
preStop:
exec: ["/bin/sh", "-c", "echo will stop"]
Pod hook
Pod hook(钩子) 是由Kubernetes管理的kubelet发起的, 当容器中的进程启动前或者容器中的进程终止之前运行, 这是包含在容器的生命周期之中。可以同时为Pod中的所有容器都配置hook
Hook 的类型包括两种:
- exec: 执行一段命令
- HTTP:发送HTTP请求
重启策略
Pod Spec中有一个restartPolicy字段, 可能的值为Always、On Failure和Never。默认为 Always。
restartPolicy适用于Pod中的所有容器。restartPolicy仅指通过同一节点上的 kubelet重新启动容器。失败的容器由kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40 秒…) 重新启动, 并在成功执行十分钟后重置。如Pod文档中所述, 一旦绑定到一个节点, Pod将永远不会重新绑定到另一个节点。
Pod phase
Pod的status 字段是一个PodStatus对象, PodStatus中有一个phase字段。
Pod的相位(phase) 是Pod在其生命周期中的简单宏观概述。该阶段并不是对容器或Pod 的综合汇 总,也不是为了做为综合状态机
Pod相位的数量和含义是严格指定的。除了本文档中列举的状态外, 不应该再假定Pod有其他的 phase值
Pod phase可能的状态值
- 挂起(Pending) :Pod已被Kubernetes系统接受, 但有一个或者多个容器镜像尚未创建。等待时间包括调度Pod的时间和通过网络下载镜像的时间, 这可能需要花点时间
- 运行中(Running) :该Pod已经绑定到了一个节点上, Pod中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态
- 成功(Succeeded) :Pod中的所有容器都被成功终止, 并且不会再重启
- 失败(Failed) :Pod中的所有容器都已终止了, 并且至少有一个容器是因为失败终止。也就是说, 容器以非0状态退出或者被系统终止
- 未知(Unknown) :因为某些原因无法取得Pod的状态, 通常是因为与Pod所在主机通信失败
Pod控制器类型
ReplicationController
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,如果有容器异常退出,会自动创建新的Pod来替代;异常多出来的容器也会自动回收,在新版本的k8s中建议使用ReplicaSet来取代ReplicationController
ReplicaSet
和ReplicationController没有本质的不同,ReplicaSet支持集合式的selector
虽然ReplicaSet可以独立使用,但一般还是建议用命Deployment来自动管理ReplicaSet(解决跟其它机制的不兼容问题,如ReplicaSet不支持rolling-update,但Deployment支持)
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend # 期望值是匹配这个标签
template:
metadata:
labels:
tier: frontend # RS创建的容器会打上这个标签
spec: # 这下面放的就是普通的pod 参数
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
env:
- name: GET_HOSTSFROM
value: dns
ports:
- containerPort: 80
RS和Deployment的关联
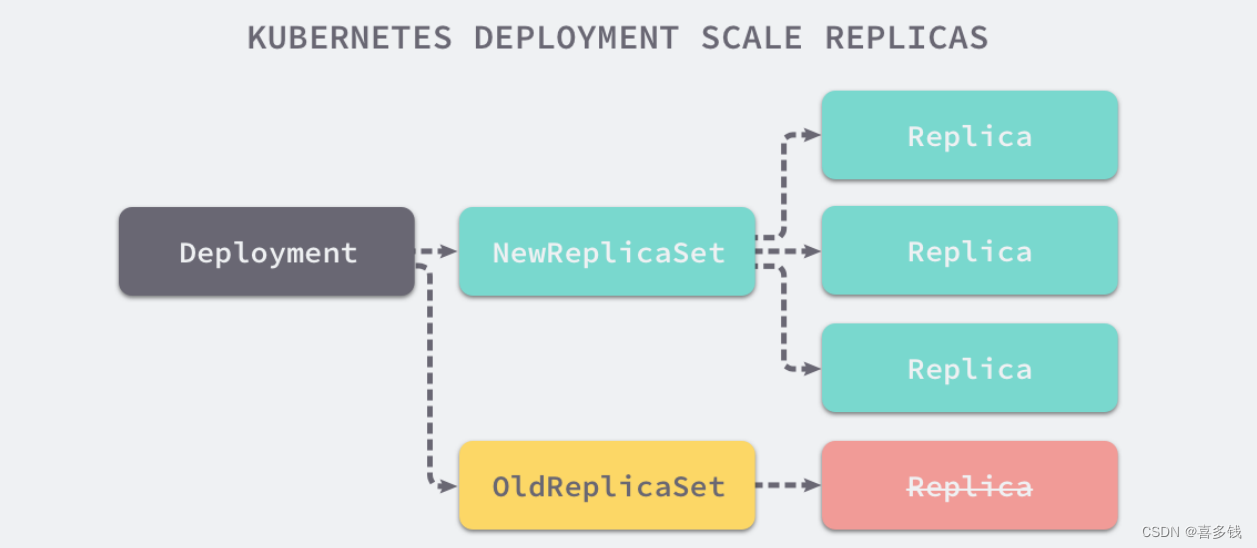
Deployment
为Pod和ReplicaSet提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationController来方便管理应用.
典型的应用场景包括:
1. 定义Deployment来创建Pod和ReplicaSet
2. 滚动升级和回滚应用
3. 扩容和缩容
4. 暂停和继续Deployment
一个简单的Deployment-Nginx配置
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx # RS创建的容器会打上这个标签
spec: # 这下面放的就是普通的pod 参数
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
Deployment会自动创建一个RS来管理Pod
扩容
kubectl scale deployment nginx-deployment --replicas 10
自动扩展
集群支持 horizontal pod autoscaling的话还可以为 deployment设置自动扩展
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
更新镜像
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.7
回滚
kubectl rollout undo deployment/nginx-deployment
Deployment更新策略
Deployment可以保证在升级时只有一定数量的Pod是down的。默认的, 它会确保至少有比期望的Pod数量少 一个是up状态(最多一个不可用)
Deployment同时也可以确保只创建出超过期望数量的一定数量的Pod。默认的, 它会确保最多比期望的Pod数 量多一个的Pod是up的(最多1个surge)
未来的Kuberentes版本中, 将从1-1变成25%-25%
- 先创建新的RS,创建25%的新POD,然后再去旧的RS里面删除25%,最终全部替换掉
kubectl describe deployments
Rollover (多个rollout并行)
假如您创建了一个有5个niginx:1.7.9replica的Deployment,但是当还只有3个nginx:1.7.9的replica创建出来的时候您就开始更新含有5个nginx:1.9.1replica的Deployment。在这种情况下, Deployment会立即杀掉已创建的3个nginx:1.7.9的Pod,并开始创建nginx:1.9.1的Pod。它不会等到所有的5个nginx:1.7.9的Pod都创建完成后才开始改变航道
可以用kubectl rollout status命令查看 deployment是否完成 ,如果roolout成功完成 , kubectl rollout status 将返回一个0值的exit code
kubectl rollout status deployment/deploymentName
echo $?
可以通过设置 .spec.revisionHistoryLimit项来指定deployment最多保留多不revision历史记录.默认的会保留所有的revision,如果将该项设置为0,deployment就不允许回退了
HPA(Horizontal Pod Autoscaling)
仅适用于Deployment和ReplicaSet,在V1版本中仅支持根据Pod的CPU利用率扩缩容,在v1 alpha版本中,支持根据内存和用户自定义的metric扩缩容
StatefullSet
DaemonSet
确保全部(或者一些)Node上运行一个Pod的副本,当有Node加入集群时,也会为他们新增一个Pod.当有Node从集群移除时,这些Pod也会被回收.删除DaemonSet将会删除它创建的所有Pod
使用DaemonSet的一些典型用法:
即: 给每个node节点创建一个且只有一个的pod
1. 运行集群存储daemon,例如在每个Node上运行glusterd,ceph
2. 在每个Node上运行日志收集daemon,例如fluentd,logstash
3. 在每个Node上运行监控daemon,例如Prometheus Node Exporter
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: deamonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: deamonset-example
template:
metadata:
labels:
name: deamonset-example
spec:
containers:
- name: daemonset-example
image: myapp:v1
Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
特殊说明:
- spec.template格式同Pod .
- RestartPolicy仅支持Never或On Failure
- 单个Pod时, 默认Pod成功运行后Job即结束 .
- .spec.completions 标志Job结束需要成功运行的Pod个数, 默认为1
- .spec.parallelism标志并行运行的Pod的个数, 默认为1
- .spec.activeDeadlineSeconds标志失败Pod的重试最大时间, 超过这个时间不会继续重试
Example:
apiVersion: batch/v1
kind: Job
metadata:
name:pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: :["perl", "-M bignum=bpi" , "-wle", "print bpi(2000)"]
restartPolicy: Never
Cronjob
管理基于时间的Job:
1. 在给定时间点只运行一次
2. 周期性地在给定时间点运行
使用条件: k8s集群版本 >=1.8
限制条件: 创建Job的操作应该是 幂等的
典型的用法:
1. 在给定的时间点调度Job运行
2. 创建周期性运行的Job, 例如:数据库备份、发送邮件
CronJob Spec
- .spec.schedule: 调度, 必需字段, 指定任务运行周期, 格式同cron
- .spec.jobTemplate: Job模板, 必需字段, 指定需要运行的任务, 格式同Job
- .spec.startingDeadlineSeconds: 启动Job的期限(秒级别) ),该字段是可选的。如果因为任何原因而错 过了被调度的时间, 那么错过执行时间的Job将被认为是失败的。如果没有指定, 则没有期限
- .spec.concurrencyPolicy: 并发策略, 该字段也是可选的。它指定了如何处理被CronJob创建的Job的 并发执行。只允许指定下面策略中的一种
- Allow (默认) : 允许并发运行Job
- Forbid: 禁止并发运行, 如果前一个还没有完成, 则直接跳过下一个
- Replace: 取消当前正在运行的Job, 用一个新的来替换
注意, 当前策略只能应用于同一个CronJob创建的Job。如果存在多个CronJob, 它们创建的Job之间总 是允许并发运行
- .spec.suspend: 挂起,该字段也是可选的。如果设置为 true ,后续所有执行都会被挂起。它对已经开始执行的Job不起作用。默认值为 false。
- .spec.successfulJobsHistoryLimit和 .spec.failedJobsHistoryLimit: 历史限制, 是可选的字段。它 们指定了可以保留多少完成和失败的Job。默认情况下, 它们分别设置为 3和 1.设置限制的值为0,相关类型的Job完成后将不会被保留。
配置示例Example
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- --C
- -date; echo Hello from the Ku bernetes cluster
restartPolicy: OnFailure
kubectl get cronjob
# NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
# hello */1** * * False 0 <none>
kube ctl get jobs
# NAME DESIRED SUCCESSFUL AGE
# hello -1202039034 49s
pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name}
kubectl logs $pods
# Mon Aug 29 21:34:09 UTC 2016
# Hello from the Ku bernet es cluster
#注意, 删除cronjob的时候不会自动删除job, 这些job可以用kubectl delete job来删除
kubectl delete cronjob hello
# cronjob "hello" deleted