一、简介
离散化是通过创建一组跨越变量值范围的连续区间将连续变量转换为离散变量的过程。
1.1 离散化有助于处理异常值和高度偏斜的变量
离散化通过将这些值 与分布的剩余内点值一起放入较低或较高的区间来帮助处理异常值。因此,这些异常值观察不再与分布尾部的其余值不同,因为它们现在都在同一个区间/桶中。此外,通过创建适当的 bin 或区间,离散化可以帮助将偏斜变量的值分布在具有相同观察数量的一组 bin 中。
1.2 离散化方法
有几种方法可以将连续变量转换为离散变量。这个过程也称为binning,每个 bin 是每个间隔。离散化方法分为两类:有监督的和无监督的。
无监督方法_不使用变量分布以外的任何信息_来创建将放置值的连续箱。
监督方法通常使用目标信息来创建箱或区间。
我们将在本文中仅讨论使用决策树的监督离散化方法
但在进入下一步之前,让我们加载一个我们将在其上执行离散化的数据集。
决策树的离散化
决策树的离散化包括使用决策树来识别确定 bin 或连续间隔的最佳分裂点:
步骤 1:首先,它使用我们想要离散化的变量来训练一个有限深度(2、3 或 4)的决策树来预测目标。
**第 2 步:**然后将原始变量值替换为树返回的概率。单个 bin 内的所有观测值的概率相同,因此用概率替换相当于将决策树决定的截止值内的观测值分组。
好处 :
缺点:
让我们看看如何使用Titanic 数据集对决策树_进行离散化_。
1.导入有用的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
2.加载数据集
data = pd.read_csv('titanic.csv',usecols =['Age','Fare','
Survived ']) data.head()
3.将数据分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data[['Age', 'Fare', 'Survived']],data.Survived, test_size = 0.3)
因此,假设我们在数据集中没有缺失值(或者即使我们在数据集中有可用的缺失数据,我们也已经对它们进行了估算)。我离开这部分是因为我的主要目标是展示离散化是如何工作的。
所以,现在让我们可视化我们的数据,以便我们从中获得一些见解并了解变量
4. 让我们使用**_age_**to predict****构建一个分类树**_Survived_**,以便对变量进行离散化**_age_**。
tree_model = DecisionTreeClassifier(max_depth=2)tree_model.fit(X_train.Age.to_frame(), X_train.Survived)X_train['Age_tree']=tree_model.predict_proba(X_train.Age.to_frame())[:,1] X_train.head(10)
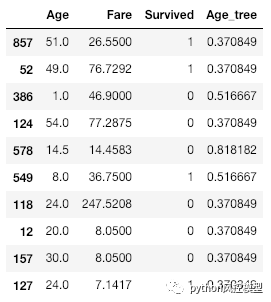
现在我们有了一个使用age变量来预测Survived变量的分类模型。
新创建的变量Age_tree包含数据点属于对应类的概率
5. 检查变量中存在的唯一值的数量**_Age_tree_**
X_train.Age_tree.unique()

为什么只有四个概率对?
在上面的输入四中,我们提到_max_depth = 2._了深度为 2 的树,进行了 2 次拆分,因此生成了 4 个桶,这就是为什么我们在上面的输出中看到 4 个不同的概率。
6. 检查离散化变量**_Age_tree_**与目标****之间的关系**_Survived_**。
fig = plt.figure()
fig = X_train.groupby(['Age_tree'])['Survived'].mean().plot()
fig.set_title('Monotonic relationship between discretised Age and target')
fig.set_ylabel('Survived')
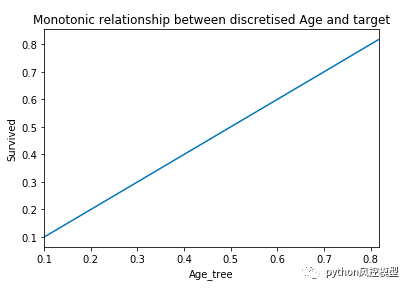
在这里,我们可以看到离散变量和Age_tree目标变量之间的单调关系Survived。该图表明这Age_tree似乎是目标变量的一个很好的预测器Survived。
7. 在离散化变量的分布下检查每个概率桶/箱的乘客数量。
X_train.groupby(['Age_tree'])['Survived'].count().plot.bar()
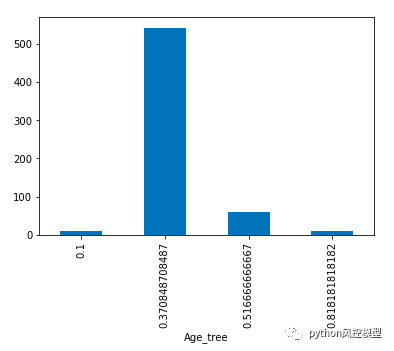
让我们通过捕获每个概率桶的最小和最大年龄来检查树生成的年龄限制桶,以了解桶的截止点。
8.检查树生成的年龄限制桶
pd.concat( [X_train.groupby(['Age_tree'])['Age'].min(),
X_train.groupby(['Age_tree'])['Age'].max()], axis=1)
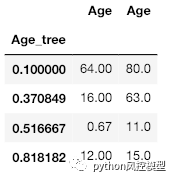
因此,决策树生成的水桶:0–11,12–15,16–63 和
46–80,用的生存概率0.51,0.81,0.37和0.10分别。
9. 可视化树。
with open("tree_model.txt", "w") as f:
f = export_graphviz(tree_model, out_file=f)from IPython.display import Image
from IPython.core.display import HTML
PATH = "tree_visualisation.png"
Image(filename = PATH, width=1000, height=1000)
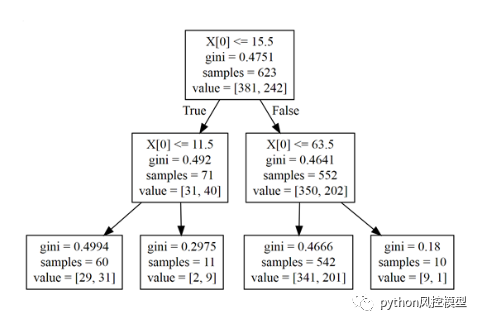
树可视化
从图中可以看出,我们获得了 4 个 bin max_depth=2。
正如我之前提到的,我们可以优化许多参数以使用决策树获得最佳的 bin 分割。下面我将优化树深度进行演示。但请记住,您还可以优化决策树的其余参数。访问sklearn 网站以查看可以优化哪些其他参数。
10.选择树的最佳深度
我将构建不同深度的树,并计算为变量确定的_roc-auc_和每棵树的目标,然后我将选择生成最佳_roc-auc_的深度
score_ls = [] # here I will store the roc auc
score_std_ls = [] # here I will store the standard deviation of the roc_auc
for tree_depth in [1,2,3,4]:
tree_model = DecisionTreeClassifier(max_depth=tree_depth)
scores = cross_val_score(tree_model, X_train.Age.to_frame(),
y_train, cv=3, scoring='roc_auc')
score_ls.append(np.mean(scores))
score_std_ls.append(np.std(scores))
temp = pd.concat([pd.Series([1,2,3,4]), pd.Series(score_ls), pd.Series(score_std_ls)], axis=1)
temp.columns = ['depth', 'roc_auc_mean', 'roc_auc_std']
print(temp)
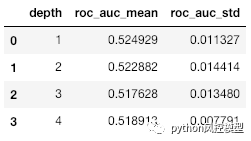
在这里,我们可以很容易地观察到我们使用深度 1 或 2获得了最佳_roc-auc_。我将选择_深度 2_继续。
11.使用树变换**_Age_**变量
tree_model = DecisionTreeClassifier(max_depth=2)
tree_model.fit(X_train.Age.to_frame(), X_train.Survived)
X_train['Age_tree'] = tree_model.predict_proba(X_train.Age.to_frame())[:,1]
X_test['Age_tree'] = tree_model.predict_proba(X_test.Age.to_frame())[:,1]
**12. 检查训练集中变换后的**_age_**变量**
X_train.head()
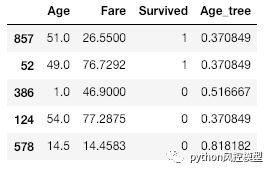
13. 检查训练集中每个 bin 的唯一值
X_train.Age_tree.unique()
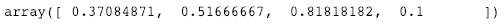
14. 检查测试集中转换后的**_age_**变量
X_test.head()
15. 检查训练集中每个 bin 的唯一值
X_test.Age_tree.unique()
现在,我们已经成功地将Age变量离散为四个离散值,这可能有助于我们的模型做出更好的预测。
如果我们想离散化剩余的变量,如 ,我们也可以执行相同的过程Fare。
决策树分箱就会大家介绍到这里,欢迎各位同学报名<python金融风控评分卡模型和数据分析微专业课>,学习更多相关知识
https://edu.csdn.net/combo/detail/1927

版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。